海量數據存儲之新存儲設備性能優化
本文主要講述NoSQL在Flash設備上的可以選擇的其中一種優化策略,并粗略提了一下SSD設備的特性。
對Flash設備的性能優化,微軟曾經做過一份paper,但是里面很多東西比較局限:比如paper中將SSD作為了寫入的buffer,而眾所周知,寫性能不會是任何一款NoSQL的瓶頸;比如SSD的索引采用了Hash的數據結構,這樣在進行cache evict的時候,粒度的控制也很有問題。本文對其進行了改進,羅列如下:
Features of SSD
SSD對于傳統硬盤的優勢在于它沒有機械裝置,介質也由磁介質變為了電介質,因此它具備直接按地址讀取數據的能力,沒有了尋道時間,這也是為什么SSD的IOPS可以達到數萬的原因。
而SSD的寫操作比較特殊,其最小寫入單元是4K,當寫入空白位置的時候可以直接寫入,但是當需要改寫某個單元時,則需要一個額外的擦出操作,擦除的操作一般是128個page,每個擦出的單元稱為一個塊。
Wear Leveling
因為SSD的存儲單元壽命有限,因此,當某個特定的部位被頻繁擦寫,不僅會造成性能問題,而且使得SSD壽命大幅降低,所以SSD做了Wear Leveling,即損耗均衡算法。這樣,當需要改寫某個page時,并不寫入原有位置,而是讀取現有塊,合并需要改寫的數據,然后一起寫入新的空閑塊,原有的塊被標記為invalid,等待被擦除回收。這樣做的好處在于,一是不會反復擦寫同一個block,二是寫入的速度會比較快(省略了擦除的動作)。
Write amplification
因為SSD的erase-before-write的特性,所以就出現了一個寫入放大的概念,比如你想改寫4K的數據,必須首先將整個擦除塊(512KB)中的數據讀出到緩存中,改寫后,將整個塊一起寫入,這時你實際寫入了512KB的數據,寫入放大系數是128。寫入放大最好的情況是1,就是不存在放大的情況。
Conclustion
綜合SSD的特性,我們需要做到以下兩點來合理使用SSD并且提高其使用壽命:
1. 盡量避免隨機寫。由于損害均衡算法的存在,隨機寫特定page將造成寫入放大。
2. 避免每次寫入過少的數據。如果每次寫入的數據不足SSD的一個page大,那么當前寫入的數據將導致該page有浪費,并且接下來對該文件邏輯上的append將導致,之前寫的不足一個page的數據被讀取出來,并合并到新的page中去。
3. 不要使用完全部的空間。SSD的損耗均衡算法雖然一定程度上減少了對特定部位的頻繁擦寫,但是如果空間不夠,這個還是很難避免,因此,最好預留至少50%的空間。
可以看到,不得不說,絕大部分的NoSQL產品都做到了上述兩個特性。因此,在新型存儲設備上的嘗試將是NoSQL時代的主題。
SSD as Level2 Cache
雖然當前SSD相比內存便宜了很多,但目前SSD每存儲單元在價格上仍然比普通硬盤要貴很多,因此,在這個過渡時期,普遍的想法是把SSD當做二級Cache。像Flashcache這樣利用Linux Device Mapper,將SSD等設備當做Write Back block cache。關于其詳細介紹,這里就不多說了,可以去https://github.com/facebook/flashcache 看看官方的介紹。這里講述另外一種可能比較簡單易實現的方式。
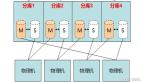
根據上面描述的SSD的性能特點,可以采用下面的設計:

上圖是邏輯上的結構,物理的實現已經把很多東西都合并了,比如讀cache和寫buffer,以及SSD的索引B-tree,都可以進行合并成為一顆B-tree(Berkeley Db的方式),另外,我需要強調的一點是,這里的SSD索引使用了B-Tree,相比于Hash是為了提供更粗粒度的SSD Cache失效機制,這一點的原因在上面的SSD特性中已經講過了,下面講述get以及set操作的流程。
Get
首先,邏輯上先查詢內存中的Read Cache,如果不存在,則查詢Write Buffer,然后是SSD Cache的B-Tree Index,然后是Bloom Filter確認key的確在硬盤存在,最后查詢到硬盤。
Set
插入的時候,先寫到write buffer里面,當buffer到達一個臨界值的時候將其刷到SSD上,當SSD到達一個臨界值的時候,將其踢出并移到硬盤,當然整個過程Bloom Filter也要保持一致。
Delete
刪除操作首先檢查內存中的各buffer和cache有沒有該值,如果有,直接在內存中刪除其父節點對它的引用,隨后直接返回;如果沒有,那么先查看Bloom Filter是否該key存在,如果存在則去硬盤上刪掉。
這里需要強調的是,刪除操作只是一個標記刪除,物理文件上的刪除會有后臺線程定時掃描,這樣能夠保證每次SSD的擦除操作能更加有效。
Evict strategy
既然SSD做為了二級Cache,那么其必然存在一個evict操作,evict操作的憑據是每個節點的generation,generation會在每次節點被訪問的時候+1,這里的+1是一個全局的+1,即整顆樹維護一個long型的generation,A節點被訪問一次則其generation為1,那么過一會B節點被訪問那么generation為2,以此類推。
Evict的時候將較小的generation的節點刪除,將其踢到硬盤,這里需要注意,這里的節點我指的是非頁節點,因此,一般情況下,每次evict至少有默認128個葉節點被踢出,即使這128個節點物理上的位置不連續,由于我們有后臺的clean線程(參加海量數據存儲之Key-value存儲簡介的過期數據清理一章)的參與,因此,我們總能保證,每次SSD的擦除操作都是連續并且是大塊的。
最后,很顯然,這樣的設計L1 Cache、L2 Cache以及Disk組成了一套完整的數據,因此,在掉電的時候,SSD的cache無需失效,當然,前提是由于我們的系統有Write-ahead-log保證了內存中的數據掉電不丟失。
References
http://www.hellodba.net/2010/10/ssd-database-2.html
http://research.microsoft.com/apps/pubs/default.aspx?id=131572
【編輯推薦】