Hadoop分布式文件系統(tǒng)詳解
在學(xué)習(xí)Hadoop的過程中,你可能遇到Hadoop分布式文件系統(tǒng)方面的內(nèi)容,本節(jié)就向大家介紹一下,歡迎大家一起來學(xué)習(xí)Hadoop分布式文件系統(tǒng)方面的知識。下面是具體介紹。
Hadoop分布式文件系統(tǒng)
Hadoop分布式文件系統(tǒng)(HDFS)被設(shè)計成適合運行在通用硬件(commodityhardware)上的分布式文件系統(tǒng)。它和現(xiàn)有的分布式文件系統(tǒng)有很多共同點。但同時,它和其他的分布式文件系統(tǒng)的區(qū)別也是很明顯的。HDFS是一個高度容錯性的系統(tǒng),適合部署在廉價的機(jī)器上。HDFS能提供高吞吐量的數(shù)據(jù)訪問,非常適合大規(guī)模數(shù)據(jù)集上的應(yīng)用。HDFS放寬了一部分POSIX約束,來實現(xiàn)流式讀取文件系統(tǒng)數(shù)據(jù)的目的。HDFS在最開始是作為ApacheNutch搜索引擎項目的基礎(chǔ)架構(gòu)而開發(fā)的。HDFS是ApacheHadoopCore項目的一部分。這個項目的地址是http://hadoop.apache.org/core/。
前提和設(shè)計目標(biāo)
硬件錯誤
硬件錯誤是常態(tài)而不是異常。HDFS可能由成百上千的服務(wù)器所構(gòu)成,每個服務(wù)器上存儲著文件系統(tǒng)的部分?jǐn)?shù)據(jù)。我們面對的現(xiàn)實是構(gòu)成系統(tǒng)的組件數(shù)目是巨大的,而且任一組件都有可能失效,這意味著總是有一部分HDFS的組件是不工作的。因此錯誤檢測和快速、自動的恢復(fù)是HDFS最核心的架構(gòu)目標(biāo)。
流式數(shù)據(jù)訪問
運行在HDFS上的應(yīng)用和普通的應(yīng)用不同,需要流式訪問它們的數(shù)據(jù)集。HDFS的設(shè)計中更多的考慮到了數(shù)據(jù)批處理,而不是用戶交互處理。比之?dāng)?shù)據(jù)訪問的低延遲問題,更關(guān)鍵的在于數(shù)據(jù)訪問的高吞吐量。POSIX標(biāo)準(zhǔn)設(shè)置的很多硬性約束對HDFS應(yīng)用系統(tǒng)不是必需的。為了提高數(shù)據(jù)的吞吐量,在一些關(guān)鍵方面對POSIX的語義做了一些修改。
大規(guī)模數(shù)據(jù)集
運行在Hadoop分布式文件系統(tǒng)HDFS上的應(yīng)用具有很大的數(shù)據(jù)集。HDFS上的一個典型文件大小一般都在G字節(jié)至T字節(jié)。因此,HDFS被調(diào)節(jié)以支持大文件存儲。它應(yīng)該能提供整體上高的數(shù)據(jù)傳輸帶寬,能在一個集群里擴(kuò)展到數(shù)百個節(jié)點。一個單一的HDFS實例應(yīng)該能支撐數(shù)以千萬計的文件。
簡單的一致性模型
HDFS應(yīng)用需要一個“一次寫入多次讀取”的文件訪問模型。一個文件經(jīng)過創(chuàng)建、寫入和關(guān)閉之后就不需要改變。這一假設(shè)簡化了數(shù)據(jù)一致性問題,并且使高吞吐量的數(shù)據(jù)訪問成為可能。Map/Reduce應(yīng)用或者網(wǎng)絡(luò)爬蟲應(yīng)用都非常適合這個模型。目前還有計劃在將來擴(kuò)充這個模型,使之支持文件的附加寫操作。
“移動計算比移動數(shù)據(jù)更劃算”
一個應(yīng)用請求的計算,離它操作的數(shù)據(jù)越近就越高效,在數(shù)據(jù)達(dá)到海量級別的時候更是如此。因為這樣就能降低網(wǎng)絡(luò)阻塞的影響,提高系統(tǒng)數(shù)據(jù)的吞吐量。將計算移動到數(shù)據(jù)附近,比之將數(shù)據(jù)移動到應(yīng)用所在顯然更好。HDFS為應(yīng)用提供了將它們自己移動到數(shù)據(jù)附近的接口。
異構(gòu)軟硬件平臺間的可移植性
HDFS在設(shè)計的時候就考慮到平臺的可移植性。這種特性方便了HDFS作為大規(guī)模數(shù)據(jù)應(yīng)用平臺的推廣。
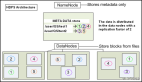
Namenode和Datanode
Hadoop分布式文件系統(tǒng)HDFS采用master/slave架構(gòu)。一個HDFS集群是由一個Namenode和一定數(shù)目的Datanodes組成。Namenode是一個中心服務(wù)器,負(fù)責(zé)管理文件系統(tǒng)的名字空間(namespace)以及客戶端對文件的訪問。集群中的Datanode一般是一個節(jié)點一個,負(fù)責(zé)管理它所在節(jié)點上的存儲。HDFS暴露了文件系統(tǒng)的名字空間,用戶能夠以文件的形式在上面存儲數(shù)據(jù)。從內(nèi)部看,一個文件其實被分成一個或多個數(shù)據(jù)塊,這些塊存儲在一組Datanode上。Namenode執(zhí)行文件系統(tǒng)的名字空間操作,比如打開、關(guān)閉、重命名文件或目錄。它也負(fù)責(zé)確定數(shù)據(jù)塊到具體Datanode節(jié)點的映射。Datanode負(fù)責(zé)處理文件系統(tǒng)客戶端的讀寫請求。在Namenode的統(tǒng)一調(diào)度下進(jìn)行數(shù)據(jù)塊的創(chuàng)建、刪除和復(fù)制。
Namenode和Datanode被設(shè)計成可以在普通的商用機(jī)器上運行。這些機(jī)器一般運行著GNU/Linux操作系統(tǒng)(OS)。HDFS采用Java語言開發(fā),因此任何支持Java的機(jī)器都可以部署Namenode或Datanode。由于采用了可移植性極強(qiáng)的Java語言,使得HDFS可以部署到多種類型的機(jī)器上。一個典型的部署場景是一臺機(jī)器上只運行一個Namenode實例,而集群中的其它機(jī)器分別運行一個Datanode實例。這種架構(gòu)并不排斥在一臺機(jī)器上運行多個Datanode,只不過這樣的情況比較少見。
集群中單一Namenode的結(jié)構(gòu)大大簡化了系統(tǒng)的架構(gòu)。Namenode是所有HDFS元數(shù)據(jù)的仲裁者和管理者,這樣,用戶數(shù)據(jù)永遠(yuǎn)不會流過Namenode。本節(jié)關(guān)于Hadoop分布式文件系統(tǒng)方面的介紹到這里。
【編輯推薦】
- Hadoop集群搭建過程中相關(guān)環(huán)境配置詳解
- Hadoop完全分布模式安裝實現(xiàn)詳解
- 專家講解 Hadoop:HBASE松散數(shù)據(jù)存儲設(shè)計
- 兩種模式運行Hadoop分布式并行程序
- Hadoop應(yīng)用之Hadoop安裝篇