













使用Oracle數據庫實現Python數據持久
盡管Python 很快在開發人員之中普及,但長久以來 Oracle 數據庫一直是最出色的企業級數據庫。采用有效的方式將這兩者結合在一起是比較令人感興趣的主題,但這實際上是真正的挑戰,因為二者都要付出很多。
盡管受到警告,但本文并不會對最杰出的 Python 和 Oracle 數據庫特性進行概述,而是提供一系列獨立的示例。本文借助一個示例讓您了解如何采用互補的方法嘗試將這兩種技術結合使用。尤其是,本文將指導您利用 PL/SQL 存儲過程(在 Python 腳本中編排其調用)創建 Oracle 支持的 Python 應用程序,該應用程序在 Python 和數據庫中實施業務邏輯。
正如您將在本文中學習到的,即使是輕型的 Oracle 數據庫 10g 快捷版 (XE) 也可以得到有效利用,作為數據驅動的 Web 應用程序的數據庫后端,其前端層使用 Python 構建。特別是,Oracle 數據庫 XE 支持 Oracle XML DB,這是構建 Web 應用程序時通常需要的一組 Oracle 數據庫 XML 技術。
示例應用程序
在用戶使用您的應用程序時收集有關用戶執行操作的信息成為一種比較流行的接收用戶反饋的機制。通常,相對于讓用戶明確表達偏好的任何調查來說,并入在線應用程序中的點擊跟蹤工具可以為您提供有關用戶偏好的大量信息。
舉一個簡單的例子,假設您想從“OTN — 新文章 RSS”頁面中選取三個最新的 Oracle 技術網 (OTN) 文章標題,并將這些鏈接放到您的站點上。然后,您希望收集有關用戶在您的站點上跟隨這些鏈接中的每個鏈接的次數的信息。這就是我們的示例將要做的。現在,讓我們試著弄清如何實現所有這些功能。首先,必須決定如何在應用程序層之間分發業務邏輯。實際上,決定如何在應用程序層之間分發業務邏輯可能是規劃數據庫驅動的應用程序最具挑戰性的部分。盡管執行業務邏輯通常有多種方法,但是您的工作是找到最有效的方法。作為一般的經驗,當規劃數據庫驅動的應用程序時,您應該認真考慮數據庫中關鍵數據處理邏輯的實現。這種方法可以幫助您削減與在 Web 服務器和數據庫之間發送數據相關的網絡開銷,并且可以減輕 Web 服務器的負擔。
將所有這些理論應用到我們的示例上,例如,將獲得插入到數據庫中的文章詳細信息的負擔放到在數據庫中創建的存儲過程上,這樣 Web 服務器不必再處理與維護數據完整性有關的任務。這在實踐中的意義是您不必編寫特定 Python 代碼,這些代碼負責跟蹤數據庫中是否存在與其鏈接被點擊的文章有關的記錄,如果不存在,則插入該記錄,然后從“OTN — 新文章 RSS”頁面中獲取所需的所有詳細信息。通過讓數據庫自己跟蹤此類事情,您可以獲得具有更高可擴展性且更不易出錯的解決方案。在本例中,Python 代碼將只負責從 RSS 頁面獲取文章鏈接,并在用戶單擊某個文章鏈接時向數據庫發送一條消息。
圖 1 給出了示例組件如何彼此交互以及如何與外部源交互的圖形描述。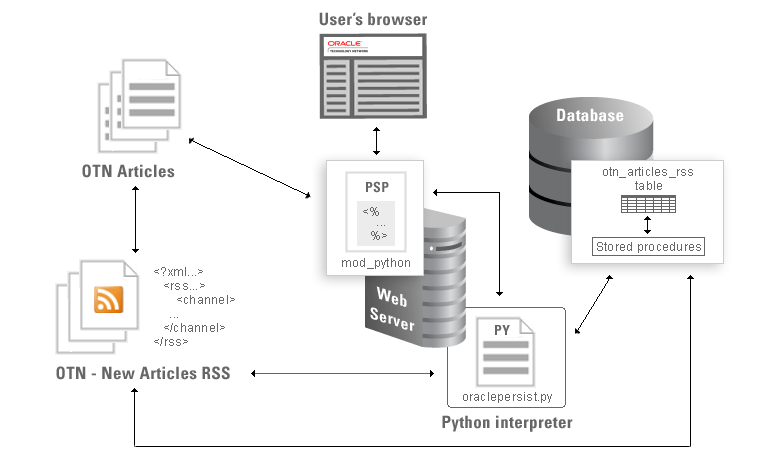
圖 1:示例應用程序工作原理的高級視圖。
本文的其余部分介紹如何實現此示例應用程序。有關如何設置和啟動此示例的簡要描述,可以參考示例代碼根目錄下的 readme.txt 文件。
準備工作環境
要構建此處討論的示例,您需要安裝以下軟件組件(參見 Downloads portlet)并使其在您的系統中正常工作:
Apache HTTP Server 2.x
Oracle 數據庫 10g 快捷版
Python 2.5 或更高版本
mod_python 模塊
cx_Oracle 模塊
有關如何安裝上述組件的詳細說明,可以參考另一篇 OTN 文章“為 Python Server Pages 和 Oracle 構建快速 Web 開發環境”(作者:Przemyslaw Piotrowski)。
#p#
設計基礎數據庫
一般來說,最好從設計基礎數據庫開始。假設您創建了一個用戶模式并授予其創建和操作模式對象所需的所有權限,那么第一步就是創建基礎表。在這種特殊情況下,您將需要一個唯一的名為 otn_articles_rss 的表,創建該表的方式如下:
CREATE TABLE otn_articles_rss ( |
下一步是設計一個將在 Python 代碼中調用的名為 count_clicks 的存儲過程,它更新 otn_articles_rss 表中的數據。繼續 count_clicks 過程之前,您必須先回答以下問題:當 count_clicks 嘗試更新尚未插入到 otn_articles_rss 表中的文章記錄的 clicks 字段時,會發生什么情況呢?假設一個新項目剛剛添加到 RSS 頁面,然后指向該項目的鏈接出現在您的站點上。當有人單擊該鏈接時,系統將從負責處理指向 OTN 文章的鏈接上執行的單擊次數的 Python 代碼中調用 count_clicks PL/SQL 過程。顯然,處理第一次單擊時,在 count_clicks 過程中發出的 UPDATE 語句將失敗,因為現在還沒有要更新的行。
要適應此類情況,您可以在 count_clicks 過程中實現一個 IF 塊,如果由于 UPDATE 找不到指定的記錄而將 SQL%NOTFOUND 屬性設置為 TRUE 時,該塊會發揮作用。在該 IF 塊中,只要指定了 guid 和單擊次數,您就可以先將一個新行插入到 otn_articles_rss 表中。之后,您應該提交這些更改,以便這些更改立即可用于其他用戶會話,這些會話可能也需要更新新插入的文章記錄的 clicks 字段。最后,您應該更新該記錄,設置其 title、pubDate 和 link 字段。該邏輯可以作為一個單獨的過程(比如 add_article_details)來實現,該過程的創建方式如下:
CREATE OR REPLACE PROCEDURE add_article_details (gid VARCHAR2, clks NUMBER) AS 'http://feeds.delicious.com/v2/rss/OracleTechnologyNetwork/otntecharticle').getXML(), |
正如您所見,該過程接受兩個參數。gid 是其鏈接受到單擊的文章的 guid。clks 是文章查看總次數的增量。在該過程主體中,您獲得 RSS 文檔的所需部分作為 XMLType 實例,然后提取信息,之后該信息將立即用于填充 otn_articles_rss 中與正在處理的 RSS 項目關聯的記錄。
借助 add_article_details,您可以繼續下一環節,按照如下方式創建 count_clicks 過程:
CREATE OR REPLACE PROCEDURE count_clicks (gid VARCHAR2, clks NUMBER) AS BEGIN |
事務考慮事項
在上面清單中所示的 count_clicks 存儲過程中,注意 COMMIT 的使用要緊跟在 INSERT 語句之后。最重要的是,之后要調用 add_article_details,其執行時間可能較長。通過在這個階段提交,新插入的文章記錄立即用于其他可能的更新,否則要等待 add_article_details 完成。
考慮以下示例。假設 RSS 頁面剛剛更新并且一個全新的文章鏈接變為可用。接下來,兩個不同的用戶加載您的頁面并幾乎同時單擊這個新鏈接。因此,將進行兩個對 count_clicks 的同時調用。在本例中,首先發生的調用將一條新記錄插入到 otn_articles_rss 表中,然后它將調用 add_article_details。雖然正在執行 add_article_details,但對 count_clicks 的另一個調用可以成功執行更新操作,增加總單擊次數。但是,如果此處忽略了 COMMIT,那么第二個調用將找不到用于更新的行,因此嘗試執行另一個插入。事實上,這將導致不可預測的結果。它將導致獨特的違反約束的錯誤,并且會丟失將第二次 count_clicks 調用進行的更新。
此處最令人感興趣的部分是在 count_clicks 過程主體結尾處執行另一個 COMMIT 操作。正如您所猜測的,需要在這個階段提交以便從更新的記錄中去除鎖定,從而使該記錄立即可用于其他會話執行的更新。有些人可能會說這個方法降低了靈活性,使客戶端無法根據自己的判斷提交或回滾事務。但是,在這種特殊的情況下,這并不是一個大問題,因為無論如何從調用 count_clicks 開始的事務都應該立即提交。這是因為當用戶單擊某個文章鏈接以離開您的頁面時,始終會調用 count_clicks。
構建前端層
既然已經創建了存儲過程并且準備好在應用程序中使用,那么您必須弄清如何從前端層編排在數據庫中實現的所有這些應用程序邏輯片段所執行的整個操作流。這就是 Python 派上用場的地方了。
我們先來看一個簡單的實現。為了開始,您必須編寫一些 Python 代碼,這些代碼將負責從“OTN — 新文章 RSS”頁面獲取數據。然后,您將需要開發一些代碼,這些代碼將處理在 Web 頁面中的 OTN 文章鏈接上執行的單擊。最后,您將需要構建該 Web 頁面本身。為此,您可能會使用 Python 的一種服務器端技術,比如 Python Server Pages (PSP),這使得將 Python 代碼嵌入到 HTML 中成為可能。
為了編寫 Python 代碼,您可以使用您喜歡的文本編輯器,如 vi 或記事本。創建一個名為 oraclepersist.py 的文件,然后在其中插入以下代碼,將該文件保存到 Python 解釋器可以找到的位置:
import cx_Oracle import urllib2 latest.append(dict(zip(inxs,[item.getElementsByTagName(inx)[0].firstChild.data for inx in inxs]))) |
正如您所猜測的,上面所示的 getRSS 函數將用來從 RSS 頁面獲取數據,并將該數據作為一個 DOM 對象返回。getLatestItems 專門用來處理該 DOM 文檔,將該文檔轉換為 Python dictionary 對象。
在 getLatestItems 函數中,注意列表內涵(一個新的 Python 語言特性)的使用,它提供了一種出色的方法,可顯著簡化數據處理任務的編碼。
下一步涉及一些代碼的創建,這些代碼將處理在指向 OTN 文章的鏈接上執行的單擊,這些鏈接是從“OTN — 新文章 RSS”頁面中獲取并放置到 Web 頁面上的。為此,您可以開發另一個自定義 Python 函數(比如說 processClick),每次用戶單擊您 Web 頁面上的 OTN 文章鏈接時都會調用該函數。要實現 processClick,將以下代碼添加到 oraclepersist.py:
def processClick(guid, clks = 1): db = cx_Oracle.connect('usr', 'pswd', '127.0.0.1/XE') |
以上代碼提供了實際運行的 cx_Oracle 的一個簡單示例。它首先連接到基礎數據庫。然后,它獲得一個 Cursor 對象,之后使用該對象的 execute 方法調用在之前的“設計基礎數據庫”部分討論的 count_clicks 存儲過程。
現在,您可以繼續下一環節,構建 Web 頁面。由于這是僅用于演示的應用程序,因此該頁面可能非常簡單,只包含從 RSS 頁面獲得的鏈接。在 APACHE_HOME/htdocs 目錄中,創建一個名為 clicktrack.psp 的文件,然后在其中插入以下代碼:
﹤html﹥ |
正如您所見,以上文檔包含幾個嵌入的 Python 代碼塊。在第一個塊中,您從之前按照該部分所述創建的 oraclepersist 模塊調用函數,獲得列表的一個實例,該列表的項目代表三篇最新的 OTN 文章。然后,在 for 循環中循環該列表,為該列表中存在的每個文章項目生成一個鏈接。令人感興趣的是,盡管這些鏈接中的每個鏈接都引用相應的 OTN 文章地址,但是鏈接的 onclick 處理程序將動態修改鏈接到 dispatcher.psp 頁面的目標,該目標需要在 APACHE_HOME/htdocs 目錄中創建。將兩個參數(即 guid 和 url)附加到每個動態生成的鏈接,向 dispatcher.psp 提供有關正在加載的文章的信息。
以下是 dispatcher.psp 的代碼:
﹤html﹥ |
在以上代碼中,借助 FieldStorage 類的幫助訪問了附加到 URL 的參數,該類來自 mod_python 網頁上提供的 Mod_python 手冊中描述的 util 模塊。然后,從我們的 oraclepersist 自定義模塊中調用 processClick 函數,將從 URL 中提取的 guid 作為第一個參數傳遞,將 1(意味著一次單擊)作為第二個參數傳遞。最后,將您的瀏覽器重定向到要加載的文章的位置。
現在,可以測試這個應用程序了。由于您處理的是實時數據,因此您必須連接到互聯網。建立連接之后,將瀏覽器指向 http://localhost/clicktrack.psp。因此,應該出現一個包含指向 OTN 最新文章的三個鏈接的簡單 Web 頁面。如圖 2 所示。
圖 2:這是加載時的應用程序頁面。

單擊任一文章鏈接并查看所發生的情況。從用戶的角度,您將只看到文章正加載到瀏覽器中,如圖 3 所示。
圖 3:當跟隨應用程序頁面上的文章鏈接時,用戶只能看到文章本身。
負責收集有關單擊信息的代碼將在后臺運行。為了確保該代碼已經這樣操作,您可以連接到基礎數據庫并發出以下查詢:
SELECT * FROM otn_articles_rss;
甚至在完全加載文章文檔之前,上述代碼應該輸出一個包含有關正在加載的文章信息的行,在 clicks 字段中顯示 1。隨后對此鏈接進行的每個單擊將使 clicks 字段的值增加 1。
#p#
采用Pythonic 方法
在前面部分中編寫的代碼結構與采用 Pythonic 方法實現的代碼看起來不太相同。尤其是,您按照一定的順序實現了一組將從在 HTML 中嵌入的代碼調用的函數,將一個函數返回的結果用作另一個函數的參數。實際上,這是采用任何其他腳本語言(比如說 PHP)結構化您的代碼的方式。
盡管 Python 的真正功能在于它能夠隱藏令人厭煩的實現詳細信息,從而提供一個簡單、優美而有效的編碼解決方案。字典、列表和列表內涵是常用的 Python 內置類型,在處理結構化數據時可以顯著簡化您的代碼。返回在前面部分中討論的 oraclepersist.py 腳本,對其進行升級,以便最大程度地利用這些杰出的 Python 語言工具。為了避免混淆,您可以將修訂保存在一個單獨的名為 oraclepersist_list.py 的文件中:
import cx_Oracle import urllib2 |
從以上代碼可以看出,利用列表內涵(一種非常有效的結構化應用程序數據的機制)可以顯著減少代碼總量。此外,客戶端也不必顯式調用模塊函數。因此,您現在可以重新編寫按照前面部分所述嵌入在 clicktrack.psp 中的 Python 代碼塊,如下所示:
... |
盡管現在它更為簡潔,但用戶不需要進行任何更改。
但是,有人可能會說將 PSP 頁面中的代碼與其后端連接實在不是一個靈活的方法。例如,將要顯示的鏈接數量以及要使用的 RSS 地址硬編碼到 oraclepersist_list.py 腳本中,借助這個新的語法,您無法根據需要動態更改這些參數。要解決此問題,可以將列表內涵封裝在 oraclepersist_list.py 腳本中的某個函數中,如下所示:
... |
正如您所見,以上代碼仍然利用了基于使用列表內涵、列表和字典的高級語法,從而允許在 clicktrack.psp 頁面中動態更改參數。以下代碼片段將闡釋現在如何顯式指定要顯示的文章鏈接數量:
... |
使用面向對象的方法
盡管 Python 中的面向對象編程 (OOP) 是完全可選的,但利用該范例可以最大程度地減少冗余,高效地自定義現有代碼。與其他現代語言一樣,Python 允許您使用類封裝邏輯和數據,簡化了數據定義和數據操作。
回到在前面部分中討論的 oraclepersist_list.py 腳本,將 processClick 函數替換為如下所示的 HandleClick 類:
... |
假設您將修訂保存在 oraclepersist_class.py 文件中,更新后的 dispatcher.psp 現在可能如下所示:
... |
下面您創建 HandleClick 類的一個實例,然后調用它的 processClick 方法,正確傳遞參數,就像您之前所做的那樣。
在此處所討論的 HandleClick 類中,特別令人感興趣的是特殊類方法 methods __init__ 和 __del__ 的使用。與其他特殊方法一樣,您從不直接調用它們。相反,Python 隱式調用它們以響應在實例生命周期期間發生的某些事件。因此在創建實例時調用 __init__ 構造函數,在銷毀實例之前調用 __del__ 析構函數。
在上面的示例中,您在構造函數中連接到數據庫并在析構函數中關閉該連接。但在某些情況下,采用這些方法實現更多操作可能是非常令人感興趣的。例如,您可能希望在銷毀實例之前從析構函數中發出 SQL 語句。以下代碼片段將闡釋如何重新編寫 HandleClick 類,以便從析構函數中而不是從某個顯式調用的類方法中調用 count_clicks 存儲過程:
... class HandleClick: |
正如您所見,更新的 HandleClick 類中不再有 processClick。相反,客戶端代碼應調用 addArticleClick,該函數用要傳遞給 count_clicks 存儲過程的參數填充該類的屬性 params dictionary,將從析構函數中調用 count_clicks 存儲過程。因此,現在您可以重新編寫嵌入在 dispatcher.psp 頁面中的 Python 代碼塊,如下所示:
... |
注意,此處使用 del 語句取消包含綁定對 HandleClick 類的某個實例的引用的 h 變量。由于這是對該實例的唯一引用,因此之后 Python 將使用一種名為垃圾回收的機制隱式刪除該實例。刪除后,將自動觸發 __del__ 析構函數,執行 SQL 語句,然后關閉連接。
上面的示例極好地說明了采用 Python 開發面向對象的代碼時使用特殊方法可以獲取的優勢。在這個特殊示例中,客戶端代碼只負責為要針對數據庫發出的查詢設置參數,而 Python 隱式執行其余操作。
結論
正如您在本文中所學到的,開發一個可擴展的數據庫驅動的 Web 應用程序需要進行較良好的規劃。繼續構建應用程序組件和編寫代碼之前,您必須首先決定可以在數據庫中實現的應用程序邏輯的數量以及可以在前端層實現的操作。
設計文章示例時,將一些數據處理邏輯放到數據庫中,實現幾個 PL/SQL 存儲過程。在這里您學習了如何使用 Oracle XML DB 特性從網頁中獲取 XML 數據,然后從獲取的 XML 文檔中提取所需的信息。然后,構建一些 Python 代碼,用以編排存儲過程所執行的完整操作流。依次從構建的 PSP 頁面中調用這些 Python 代碼,以實現應用程序的前端層。因此,您獲得了相應的應用程序,該應用程序從網頁中獲取某些實時數據,并跟蹤用戶在您站點上的活動,將該信息存儲在數據庫中。在 Python 端,您看到了如何使用 Python 語言的內置工具獲取、保留以及操作結構化數據,這些工具包括:列表、字典和列表內涵。您還了解了在將應用程序邏輯和數據封裝到類中時如何利用 Python 的面向對象的特性。
【編輯推薦】











