谷歌發布首個嵌入模型:MTEB排行榜第一,超過OpenAI
今天凌晨1點,谷歌發布了首個Gemini嵌入模型刷新了MTEB榜單記錄成為第一,并且價格很便宜每100萬token只要0.15美元,已經開放API。
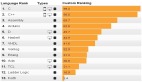
根據谷歌在多文本嵌入基準測試平臺MTEB上的測試結果顯示,Gemini嵌入模型平均分達到了68.37,大幅度超過了OpenAI文本嵌入模型的58.93分。
在雙語挖掘、分類、聚類、指令檢索、多標簽分類、配對分類、重排、檢索、語義文本相似性等測試中,全部都非常出色成為目前最強嵌入模型。

免費體驗地址:https://aistudio.google.com/prompts/new_chat
對于谷歌的新模型,網友表示,大多數人都低估了嵌入技術的強大之處,但它們卻是更智能的人工智能工作流程的核心支柱。
搜索、聚類、個性化推薦,甚至將博客內容與用戶意圖進行匹配,所有這些應用都會因嵌入技術而得到改進。
憑借每100萬token 0.15美元的價格,獨立創作者和自由職業者終于也能使用這項技術了。這是一項重大舉措。

這太棒了!我的很多學生都問過我最好的嵌入模型是什么,所以很高興看到 Gemini 有了自己的嵌入模型。Gemini 模型很可能與這些嵌入模型配合得很好,而且成本也還不錯。

多語言能力對于在全球范圍內的應用至關重要,因為有大量人口的母語并非英語。我一直認為谷歌在最先進的自然語言處理方面具有優勢。很高興看到 Gemini 在 MTEB中也位居榜首,而且其成本效益也不錯。

Gemini嵌入模型簡單介紹
Gemini嵌入模型的架構設計基于 Gemini的雙向Transformer 編碼器。這種設計保留了Gemini的雙向注意力機制,使得模型能夠充分利用其預訓練的語言理解能力。
Gemini嵌入模型以Gemini的底層32層Transformer為基礎,這些層被凍結,以確保模型能夠繼承 Gemini 的強大語言理解能力在這些凍結的層之上,模型添加了一個池化層,用于將輸入序列的每個token嵌入進行聚合,生成一個能夠代表整個輸入的單一嵌入向量。

為了實現這一點,模型采用了簡單的均值池化策略,即對輸入序列的所有 token 嵌入沿序列軸進行平均處理。這種池化方法不僅簡單高效,而且在模型適應性方面表現出了良好的效果。
在池化層之后,模型通過一個隨機初始化的線性投影層,將嵌入向量的維度調整為目標維度。這一設計使得模型能夠靈活地輸出不同維度的嵌入,例如,768 維、1536 維或 3072 維。為了支持這種多維度的嵌入輸出,Gemini嵌入模型引入了MRL技術。
MRL 技術允許模型在訓練過程中同時優化多個子維度的嵌入,例如,先優化前 768 維,再優化前 1536 維,最終優化完整的 3072 維。這種多維度訓練策略不僅提高了模型的靈活性,還增強了其在不同任務中的適應性。
在訓練過程中,Gemini 嵌入模型采用了噪聲對比估計(NCE)損失函數,這是一種廣泛應用于嵌入模型訓練的技術。NCE 損失函數的核心思想是通過對比正樣本和負樣本來優化嵌入空間,使得語義相似的文本在嵌入空間中彼此接近,而語義不同的文本則彼此遠離。

每個訓練樣本包括一個查詢、一個正樣本以及一個可選的硬負樣本。模型通過計算查詢向量與正樣本向量之間的相似度,并將其與負樣本向量的相似度進行對比,從而優化嵌入空間。
為了進一步提升模型的性能,Gemini 嵌入模型在訓練過程中采用了多維度的 NCE 損失函數。通過 MRL 技術,模型能夠同時優化多個子維度的嵌入,例如 768 維、1536 維和 3072 維。這種多維度訓練策略不僅提高了模型的靈活性,還增強了其在不同任務中的適應性。
此外,Gemini 嵌入模型 在損失函數中引入了一個掩碼機制,用于處理分類任務中目標數量較少的情況。這種掩碼機制能夠有效避免在計算損失時出現重復計算的問題,從而提高模型的訓練效率。
訓練數據
研究團隊針對檢索任務和分類任務分別設計了不同的合成數據生成策略。對于檢索任務,團隊擴展了先前的工作,采用 Gemini 生成合成查詢,并通過 Gemini 自動評分器過濾低質量的示例。
首先利用 Gemini 生成與給定段落相關的查詢,然后通過另一個 Gemini 模型對生成的查詢進行評分,以確保其質量和相關性。通過這種方式,團隊能夠生成大量高質量的檢索任務數據,從而提升模型在檢索任務中的表現。
對于分類任務,團隊則采用了更為復雜的多階段提示策略。他們首先生成合成的用戶畫像、產品信息或電影評論等數據,然后在此基礎上生成具體的分類任務數據。
例如,在生成情感分類數據時,團隊會先生成一系列帶有情感傾向的用戶評論,再從中篩選出符合特定情感標簽的樣本。這種多階段的生成策略不僅增加了數據的多樣性,還能夠根據需要調整數據的分布,從而更好地適應不同的分類任務。
為了提高訓練數據的質量,研究團隊利用 Gemini 對訓練數據進行過濾。通過基于少數樣本提示的數據質量評估,識別并移除低質量的樣本。主要利用 Gemini 的語言理解能力,對數據集中的樣本進行逐個評估,判斷其是否符合預期的質量標準。
例如,在檢索任務中Gemini 會評估查詢與正樣本之間的相關性,以及查詢與負樣本之間的不相關性。
如果某個樣本的質量不符合要求,例如,查詢與正樣本之間的相關性過低,或者查詢與負樣本之間的不相關性過高,那么這個樣本就會被標記為低質量樣本并從訓練數據中移除。
訓練方法
Gemini嵌入模型的訓練流程主要分為預微調和精調兩大階段。在預微調階段,模型使用大量潛在噪聲的對進行訓練。這些數據對來自一個大規模的 Web 語料庫,通過標題和段落對的形式作為輸入和正樣本對。
預微調階段的主要目標是將 Gemini 的參數從自回歸生成任務適應到編碼任務。因此,這一階段采用了較大的批量大小(如 8192),以提供更穩定的梯度,減少噪聲的影響。預微調階段的訓練步數較多,通常達到100 萬步。
在精調階段,模型進一步在包含查詢,目標,硬負樣本三元組的多種任務特定數據集上進行訓練。這些數據集涵蓋了檢索、分類、聚類、重排、語義文本相似性等多種任務類型。
精調階段采用了較小的批量大小(如256),并且限制每個批次只包含來自同一任務的數據。這種策略使得模型能夠更好地專注于特定任務的優化,從而提高其在不同任務中的性能。
為了進一步提升模型的泛化能力,Gemini嵌入模型還采用了 Model Soup 技術。Model Soup 是一種簡單的參數平均技術,通過對多個不同超參數訓練得到的模型檢查點進行參數平均,能夠顯著提升模型的性能。