ICCV2025 | 多視圖生成新范式-利用自回歸模型探索多視圖生成
本文第一作者包括北京大學(xué)博士生胡珈魁與清華大學(xué)碩士生楊羽霄;通訊作者為北京大學(xué)助理教授盧閆曄與(前)百度視覺技術(shù)部劉家倫。
本文介紹并開發(fā)了一種自回歸生成多視圖圖像的方法 MVAR 。其目的是確保在生成當(dāng)前視圖的過程中,模型能夠從所有先前的視圖中提取有效的引導(dǎo)信息,從而增強(qiáng)多視圖的一致性。
MVAR 拉近了純自回歸方法與最先進(jìn)的基于擴(kuò)散的多視圖圖像生成方法的生成圖像質(zhì)量,并成為能夠處理同時(shí)多模態(tài)條件的多視圖圖像生成模型。

- 論文地址:https://arxiv.org/pdf/2506.18527
- 代碼地址:https://github.com/MILab-PKU/MVAR/
推理代碼、權(quán)重、渲染的 GSO 及其配套的 Prompt 已全部開源。
背景與動(dòng)機(jī)
根據(jù)人工指令生成多視圖圖像對于 3D 內(nèi)容創(chuàng)作至關(guān)重要。主要挑戰(zhàn)在于如何在多視圖之間保持一致性,以及如何在不同條件下有效地合成形狀和紋理。此前的工作主要使用 Diffusion 模型中自帶的多視角一致性先驗(yàn),促進(jìn)多視角一致圖像生成。但是 Diffusion 模型存在一些先天劣勢:
- 絕大多數(shù) Diffusion 模型同時(shí)多個(gè)視角;
- 單一 Diffusion 模型難以接受多模態(tài)控制條件;

如上圖左所示,當(dāng)使用 Diffusion 模型從相隔較遠(yuǎn)的視角合成圖像時(shí),參考圖像和目標(biāo)圖像之間的重疊度會(huì)顯著降低,從而削弱了參考引導(dǎo)的有效性。
在極端情況下,例如從前視角生成后視角圖像,由于重疊紋理極少,視覺參考信息幾乎可以忽略不計(jì)。這種有限的參考信息可能會(huì)導(dǎo)致模型生成的多視角圖像不夠一致。
為了解決這一局限性,我們提出采用自回歸 (AutoRegressive, AR) 生成方法進(jìn)行多視圖圖像生成。
如上圖右所示,在基于 AR 的生成中,模型利用前 n-1 個(gè)視圖的信息作為生成第 n 個(gè)視圖的條件,從而允許模型利用先前生成的視圖的信息。在從前視圖參考生成后視圖的場景中,AR 生成模型會(huì)從先前的視圖中提取足夠且相關(guān)的參考。
值得注意的是,AR 生成過程與人類觀察 3D 物體的方式高度一致。人類也是按照一個(gè)特定且連續(xù)的路徑觀察物體的多個(gè)視角,而非如 Diffusion 一樣同時(shí)觀察多個(gè)視角。
受此概念的啟發(fā),我們提出了多視圖自回歸 (MVAR) 模型。
MVAR
MVAR 的主要目的是探究 AR 形式(此處的 AR 是狹義上的 AR 模型,僅僅指代 next token prediction 這一范式)的生成方法在多視角生成問題中的優(yōu)勢、劣勢(及其對應(yīng)的解決方案)。
我們將首先簡單介紹什么是基于自回歸的圖像生成。
前置知識:什么是 AR 生成?
給定一個(gè)長度為 T 的序列 x,AR 模型試圖根據(jù)以下公式推導(dǎo)其分布:

其中, x_i 表示序列 x 中的第 i 個(gè)數(shù)據(jù)點(diǎn), 表示索引小于 t 的向量。訓(xùn)練 AR 模型 p_θ 意味著該模型將在大規(guī)模圖像序列上學(xué)習(xí)如何優(yōu)化
表示索引小于 t 的向量。訓(xùn)練 AR 模型 p_θ 意味著該模型將在大規(guī)模圖像序列上學(xué)習(xí)如何優(yōu)化 。
。
在一般的圖像生成任務(wù)中,x 來源于視角編碼器 ε(?) ,如:VQGAN、量化器 Q 、及其碼本 Z 。從圖像 I 到序列 x 的公式如下:

其中, lookup (Z,v) 表示從碼本 Z 中檢索第 v 個(gè)向量。 x 的上標(biāo) (i-1)*w+j 表示 x 被展平,即原本位于二維坐標(biāo) (i,j) 的數(shù)據(jù)被變換到其一維對應(yīng)位置 (i-1)*w+j 。
多視角圖像生成中的AR
多視角情況下,由于存在多張圖象,其相對于一般的 2D 圖像多出了一個(gè)維度,這一維度可以被簡單的理解成「時(shí)間」維度。
與視頻不同,視頻的不同幀之間有固定的時(shí)序關(guān)系,多視角圖像之間并沒有固定的時(shí)序關(guān)系,我們可以從很多條不同的時(shí)序軌跡去合成多視角圖像。這一問題我們將在后續(xù)討論。
于是,我們可將上式進(jìn)行簡單的擴(kuò)展,使得 AR 能夠適配多視角圖像生成:

其中, n 代表第 n 個(gè)視角。
AR模型生成多視角圖像有何問題
多視圖生成的多條件控制、有限的訓(xùn)練數(shù)據(jù),為 AR 在多視角圖像任務(wù)的應(yīng)用帶來了許多阻礙。本博文簡要介紹了其中兩點(diǎn):
- 多模態(tài)條件控制。生成多視圖圖像的任務(wù)需要模型能夠熟練地從各種條件中提取特征,并生成與給定條件保持一致的多視圖圖像。AR 模型中條件注入的方法尚未得到廣泛研究,如:相機(jī)姿態(tài)、參考圖像和幾何形狀。
- 有限的高質(zhì)量數(shù)據(jù)。經(jīng)驗(yàn)表明,AR 模型需要大量高質(zhì)量數(shù)據(jù)(例如數(shù)十億條文本)才能實(shí)現(xiàn)飽和的模型訓(xùn)練。然而,3D 物體與高質(zhì)量多視圖圖像的樣本匱乏,嚴(yán)重阻礙了 MVAR 模型訓(xùn)練的充分性。
MVAR給出的解決方案
我們分別針對這些問題給出了特定的解決方案。
多模態(tài)條件嵌入網(wǎng)絡(luò)架構(gòu):文本、相機(jī)位姿、圖像、幾何。

我們通過一些架構(gòu)設(shè)計(jì)解決多模態(tài)條件嵌入,并試圖避免簡單的 in-context 條件注入形式可能帶來的多模態(tài)塌縮問題。MVAR 的具體的網(wǎng)絡(luò)架構(gòu)如上圖所示,其基礎(chǔ)模型架構(gòu)參考了 LLaMa;對于不同的模態(tài),我們使用的條件注入方法整理如下:
- 文本:分離式自注意力機(jī)制 (SSA);
- 相機(jī)位姿:位置編碼(將相機(jī)位姿進(jìn)行普朗克編碼后);
- 參考圖像:圖像變換與逐 token 加法;
- 幾何:in-context.
以上條件注入結(jié)構(gòu)設(shè)計(jì)遵從以下核心原則:
- 與輸出能大致逐像素匹配的(如:普朗克編碼后的相機(jī)位姿、參考圖像、深度圖),使用逐像素加法進(jìn)行條件注入;
- 完全不能逐像素匹配的(如:文本、幾何),使用 in-context 條件注入。
具體來說,對于文本和幾何,我們主要基于 in-context 條件注入形式,并引入了條件與內(nèi)容分離的自注意力形式,公式如下:

其中 是文本特征,
是文本特征, 是圖像特征。 Concat(?) 在 token 維度上連接特征,而 Chunk(?) 是 Concat(?) 的逆運(yùn)算。SSA 的宗旨是在引入條件的同時(shí),不改變條件在 token 維度的分布。
是圖像特征。 Concat(?) 在 token 維度上連接特征,而 Chunk(?) 是 Concat(?) 的逆運(yùn)算。SSA 的宗旨是在引入條件的同時(shí),不改變條件在 token 維度的分布。
對于相機(jī)位姿和參考圖像,我們主要基于逐像素加法這一條件注入形式。
對于參考圖像,其特征 在傳入 MVAR 前,需要與相機(jī)位姿
在傳入 MVAR 前,需要與相機(jī)位姿  進(jìn)行交叉注意力,從而將第 n 個(gè)視角的參考圖像特征圖初步變換到第 m 個(gè)視角。
進(jìn)行交叉注意力,從而將第 n 個(gè)視角的參考圖像特征圖初步變換到第 m 個(gè)視角。
值得注意的是,相機(jī)位姿與參考圖像的條件在 token 維度存在錯(cuò)位:
- 相機(jī)位姿用于提示 MVAR ,下一 token 應(yīng)當(dāng)生成何種視角下哪一 patch 的圖像內(nèi)容,所以其相對于生成的 token 需要進(jìn)行錯(cuò)位。(類似 RAR 一文中的 target-aware position embedding)
- 參考圖像用于告知 MVAR ,當(dāng)前 token 的生成應(yīng)當(dāng)與給定的條件特征逐像素的對應(yīng),所以其與生成 token 并無錯(cuò)位。
數(shù)據(jù)增強(qiáng)
我們主要提出了適配自回歸式生成的 Shuffle View (ShufV) 數(shù)據(jù)增強(qiáng)策略,他的動(dòng)機(jī)在于通過使用不同 order 的相機(jī)路徑作為訓(xùn)練從而增廣有限的高質(zhì)量數(shù)據(jù)。其公式如下:

其中 S 表示隨機(jī)序列。 表示第 n 個(gè)視圖的圖像現(xiàn)在被用作訓(xùn)練序列 x 中的第
表示第 n 個(gè)視圖的圖像現(xiàn)在被用作訓(xùn)練序列 x 中的第  個(gè)視圖。
個(gè)視圖。
由于 self attention 和 FFN 都具有置換等變性。因此,輸入序列順序的變化將導(dǎo)致模型中間特征序列順序的相應(yīng)變化。為了確保輔助條件(例如相機(jī)姿態(tài)和參考圖像)能夠有效地引導(dǎo)模型按照預(yù)定順序生成圖像,必須重新排列這些條件。這種重新排序?qū)⒋_保條件序列與輸入序列的序列對齊。
我們認(rèn)為 ShufV 在增廣有限的高質(zhì)量數(shù)據(jù)問題的同時(shí),有助于緩解多模態(tài)條件控制中的部分問題:
AR 模型難以利用連續(xù)視圖和當(dāng)前視圖之間的重疊條件。
使用 ShufV 進(jìn)行數(shù)據(jù)增強(qiáng)時(shí),視圖的順序不是固定的。假設(shè)輸入序列 x 中存在兩個(gè)視圖 A 和 B。ShufV 使 MVAR 能夠在訓(xùn)練階段獲得從視圖 A 到視圖 B 以及 視圖 B 到視圖 A 的轉(zhuǎn)換。這允許模型利用當(dāng)前視圖和其他視圖之間的重疊條件并有效地使用它們。
漸進(jìn)式學(xué)習(xí)
最后,我們使用漸進(jìn)式學(xué)習(xí),將模型從僅接受文本條件的 text to multi-view image (t2mv) 模型泛化到 any to multi-view image (x2mv) 模型。
在 x2mv 模型的訓(xùn)練過程中,文本條件會(huì)被隨機(jī)丟棄,而其他條件則會(huì)隨機(jī)組合。當(dāng)文本提示被丟棄時(shí),它會(huì)被替換為與目標(biāo)圖像無關(guān)的語句。例如,可以使用諸如 「Generate multi-view images of the following <img>」 之類的 prompt 。在這種情況下,「<img>」 表示將在文本之后組合參考圖像。如果后續(xù)元素是幾何形狀,則將 「<img>」 替換為 「<shape>」。這種漸進(jìn)式學(xué)習(xí)使模型能夠受到訓(xùn)練期間引入的新條件的影響,同時(shí)保持對文本提示的一定程度的遵循。
實(shí)驗(yàn)結(jié)果
MVAR 拉近了基于 AR 的多視角生成模型與現(xiàn)有的 Diffusion 模型的差距,并展示出更強(qiáng)的指令遵從與多視角一致性。

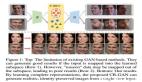
圖生多視角圖像
與一些先進(jìn)的基于 Diffusion 的方法的數(shù)值指標(biāo)比較如下:

其中,紅色表示最優(yōu)、藍(lán)色表示次優(yōu)。
MVAR 的表現(xiàn)上有著最高的PSNR、次優(yōu)的SSIM,但在LPIPS這一感知指標(biāo)上仍有些遜色。更高的PSNR意味著生成的視角與對應(yīng)的GT能更好的進(jìn)行顏色、形狀、物體位置上的對齊;略低的 LPIPS 意味著 MVAR 在實(shí)際圖像質(zhì)量上可能相對于Diffusion略遜一籌。
我認(rèn)為 MVAR 生成的圖像感知質(zhì)量較差的原因是因?yàn)?nbsp;MVAR 使用的基礎(chǔ)模型 LLamaGen 相比 Diffusion-based 方法使用的基礎(chǔ)模型 SD 系列要差一些。不過隨著現(xiàn)有基于 AR 的圖像生成基礎(chǔ)模型的發(fā)展,我相信基于 AR 的多視角生成的感知質(zhì)量將會(huì)很快追上并超過已有 Diffusion-based 方法。

文生多視角圖像

文+幾何生多視角圖像(紋理生成)
更多結(jié)果歡迎大家在 arxiv 查看,或在 github 上下載代碼與權(quán)重自行生成。
未來工作
- 更優(yōu)的標(biāo)記器。本文未使用 3D VAE 的原因是:其編碼過程中視圖之間會(huì)進(jìn)行信息交換,這與我們研究的核心動(dòng)機(jī)相悖。我們將在未來專注于通過使用連續(xù)的因果 3D VAE 對多視圖圖像進(jìn)行分詞來提升性能。
- 統(tǒng)一生成和理解。本研究使用增強(qiáng)現(xiàn)實(shí) (AR) 模型來完成多視圖圖像生成任務(wù)。在未來的工作中,我們希望利用自回歸模型的通用學(xué)習(xí)能力來統(tǒng)一多視圖生成和理解任務(wù),尤其是在難以獲得高精度 3D 數(shù)據(jù)的場景理解生成任務(wù)上。