這篇文章把 Paimon 和 Fluss 的關系給徹底說清楚了
在大數(shù)據(jù)處理領域,實時數(shù)據(jù)分析和處理的需求日益增長。傳統(tǒng)的數(shù)據(jù)處理架構在面對實時性要求較高的場景時,往往顯得力不從心。為了滿足企業(yè)對實時數(shù)據(jù)的高效處理和分析需求,Apache Paimon和Fluss這兩種技術應運而生。Apache Paimon是一個開源的數(shù)據(jù)存儲和查詢分析引擎,旨在支持海量數(shù)據(jù)的高效存儲和實時分析;而Fluss則是一款面向?qū)崟r分析設計的流存儲引擎,深度融合了Lakehouse架構。
本文將詳細探討Paimon和Fluss的集成,介紹它們的基本概念、集成的意義、具體的集成方法以及相關代碼示例,尤其會深入解釋它們之間的聯(lián)系。

一、Paimon和Fluss的基本概念
1. Apache Paimon
(1) 誕生背景
在大數(shù)據(jù)處理領域,傳統(tǒng)的數(shù)據(jù)倉庫和數(shù)據(jù)湖解決方案在處理實時數(shù)據(jù)和大規(guī)模數(shù)據(jù)時面臨諸多挑戰(zhàn),如數(shù)據(jù)一致性、高性能查詢、實時更新等。隨著實時數(shù)據(jù)分析需求的不斷增加,業(yè)界迫切需要一種能夠高效處理大規(guī)模流式數(shù)據(jù)的存儲系統(tǒng)。Paimon最初名為Flink Table Store,是在Apache Flink社區(qū)內(nèi)部于2022年1月啟動的一個項目,目標是開發(fā)一個高性能的流式數(shù)據(jù)湖存儲系統(tǒng),支持高吞吐、低延遲的數(shù)據(jù)攝入、流式訂閱以及實時查詢能力,并于2024年4月16號畢業(yè)成為Apache的頂級項目。
(2) 系統(tǒng)架構
- 存儲層:Paimon使用列式存儲格式(如Parquet、ORC),采用LSM (Log-Structured Merge)樹結構,支持數(shù)據(jù)分區(qū),這種結構支持高效的寫入操作和合并機制,確保數(shù)據(jù)的高吞吐和低延遲。
- 元數(shù)據(jù)管理:使用一個獨立的元數(shù)據(jù)存儲系統(tǒng)來管理表結構、分區(qū)信息、事務日志等元數(shù)據(jù),常見的元數(shù)據(jù)存儲系統(tǒng)包括MySQL、Hive Metastore等。同時,Paimon提供ACID事務支持,確保數(shù)據(jù)操作的一致性和可靠性,事務管理模塊負責記錄和管理事務日志,支持多版本并發(fā)控制(MVCC)。
- 計算層:提供了一個SQL引擎,支持標準的SQL查詢,用戶可以通過SQL語句進行數(shù)據(jù)查詢、插入、更新和刪除操作。此外,Paimon可以與多種計算引擎(如Apache Flink、Apache Spark、Trino)集成,提供豐富的數(shù)據(jù)處理和分析能力。
- 數(shù)據(jù)攝入和輸出:支持多種數(shù)據(jù)攝入方式,包括批量加載、流式攝入和事務性寫入;也支持將數(shù)據(jù)導出到其他系統(tǒng),如數(shù)據(jù)倉庫、數(shù)據(jù)湖、消息隊列等。
- 查詢優(yōu)化:支持多種索引類型,如B-Tree索引、Bitmap索引等,用于加速查詢性能;內(nèi)置了一個查詢優(yōu)化器,可以根據(jù)查詢條件和數(shù)據(jù)分布自動選擇最優(yōu)的查詢計劃,提高查詢效率。
- 擴展性和可靠性:設計為分布式系統(tǒng),支持水平擴展,可以通過增加更多的節(jié)點來提升系統(tǒng)的處理能力和存儲容量;提供了多種容錯機制,如數(shù)據(jù)復制、故障恢復等,確保系統(tǒng)的高可用性和數(shù)據(jù)的可靠性。
(3) 核心概念
- 表(Table):是最基本的數(shù)據(jù)組織單元,每個表都有一個定義好的模式(Schema),包括列名、數(shù)據(jù)類型和主鍵。表可以是非分區(qū)表,也可以是分區(qū)表,后者通過將數(shù)據(jù)按照特定列的值進行劃分,以提高查詢性能。
- 模式(Schema):定義了表的結構,包括列名、數(shù)據(jù)類型和主鍵等信息。
- 分區(qū)(Partition):采用與Apache Hive相同的分區(qū)概念來分離數(shù)據(jù),是一種可選方法,可根據(jù)日期、城市和部門等特定列的值將表劃分為相關部分,每個表可以有一個或多個分區(qū)鍵來標識特定分區(qū),通過分區(qū),用戶可以高效地操作表中的一片記錄。
- 快照(Snapshot):捕獲表在某個時間點的狀態(tài),用戶可以通過最新的快照來訪問表的最新數(shù)據(jù),也可以通過較早的快照訪問表的先前狀態(tài)。
- 清單文件(Manifest File):包含有關LSM數(shù)據(jù)文件和更改日志文件的文件信息,例如對應快照中創(chuàng)建了哪個LSM數(shù)據(jù)文件、刪除了哪個文件。
- 數(shù)據(jù)文件(Data File):按分區(qū)和存儲桶分組,每個存儲桶目錄都包含一個LSM樹及其變更日志文件,目前支持使用orc(默認)、parquet和avro作為數(shù)據(jù)文件格式。
- 事務(Transaction):支持ACID事務,確保數(shù)據(jù)的寫入和讀取具有高度一致性,特別是在分布式環(huán)境中。
- 增量更新(Incremental Updates):支持高效的數(shù)據(jù)更新操作,適用于實時數(shù)據(jù)變更頻繁的場景。
- 變更日志(Change Log):可以從任何數(shù)據(jù)源生成正確且完整的變更日志,從而簡化流分析。
- 統(tǒng)一存儲(Unified Storage):支持流處理和批處理的無縫切換,使得同一份存儲可以同時服務于流處理和批處理作業(yè),降低了開發(fā)和運維的復雜度。
- 生態(tài)系統(tǒng)集成(Ecosystem Integration):提供了多種數(shù)據(jù)連接器,可以與不同的數(shù)據(jù)源和目標系統(tǒng)進行集成,如Kafka、HDFS、S3、數(shù)據(jù)庫等;還提供了豐富的工具和庫,幫助用戶進行數(shù)據(jù)遷移、備份、恢復等操作。
2. Fluss
(1) 誕生背景
當前業(yè)界大數(shù)據(jù)的處理正在從離線模式轉(zhuǎn)向?qū)崟r化,多個行業(yè)和應用場景都在進行實時化的演進。然而,傳統(tǒng)的流存儲工具如Kafka在實時分析場景中存在一些顯著的問題,如不支持數(shù)據(jù)更新、缺乏高效的查詢功能、數(shù)據(jù)難以復用、回溯歷史數(shù)據(jù)困難以及高昂的網(wǎng)絡成本等。為了解決這些問題,阿里巴巴研發(fā)了Fluss項目,旨在為Apache Flink提供實時流存儲底座,進一步提升Flink實時流計算的能力。
(2) 核心特性
- 實時讀寫:支持毫秒級的流式讀寫能力,能夠滿足實時數(shù)據(jù)處理的需求。
- 列式裁剪:以列存格式存儲實時流數(shù)據(jù),通過列裁剪可提升10倍讀取性能并降低網(wǎng)絡成本。例如,在處理大規(guī)模數(shù)據(jù)時,只讀取需要的列,避免了不必要的數(shù)據(jù)傳輸,提高了讀取效率。
- 流式更新:支持大規(guī)模數(shù)據(jù)的實時流式更新,支持部分列更新,實現(xiàn)低成本寬表拼接。在實際應用中,可以對數(shù)據(jù)進行實時更新,而無需重新寫入整個數(shù)據(jù)集。
- CDC訂閱:更新會生成完整的變更日志(CDC),通過Flink流式消費CDC,可實現(xiàn)數(shù)倉全鏈路數(shù)據(jù)實時流動。這使得數(shù)據(jù)的變更能夠及時被捕獲和處理,保證了數(shù)據(jù)的實時性。
- 實時點查:支持高性能主鍵點查,可作為實時加工鏈路的維表關聯(lián)。在需要快速查找特定數(shù)據(jù)時,能夠高效地定位和獲取數(shù)據(jù)。
- 湖流一體:無縫集成Lakehouse,并為Lakehouse提供實時數(shù)據(jù)層。這不僅為Lakehouse分析帶來了低延時的數(shù)據(jù),更為流存儲帶來了強大的分析能力。例如,最新的數(shù)據(jù)在Fluss中,歷史數(shù)據(jù)在Paimon中,F(xiàn)link可以支持Union Read,將Fluss和Paimon中的數(shù)據(jù)Union起來實現(xiàn)秒級新鮮度的分析。
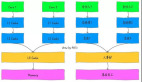
(3) 基礎架構
- Fluss Cluster:由Coordinator Server和Tablet Server組成。Coordinator Server作為集群的中心控制節(jié)點,負責元數(shù)據(jù)管理、Leader分配和權限管理;Tablet Server是數(shù)據(jù)存儲節(jié)點,包含Log Store和KV Store。KV Store支持更新和點查操作,Log Store存儲更新產(chǎn)生的Change Logs。
- Fluss Client:客戶端組件,用于與Fluss集群交互。
- ZK(ZooKeeper):用于集群協(xié)調(diào)和元數(shù)據(jù)管理。
- Remote Storage:遠程存儲,用于冷數(shù)據(jù)的歸檔。熱數(shù)據(jù)存儲在本地服務器上,并持續(xù)同步到遠程存儲;通過一個Compaction Service將冷數(shù)據(jù)歸檔至數(shù)據(jù)湖中。
二、Paimon和Fluss之間的緊密聯(lián)系
1. 功能互補
Paimon側重于數(shù)據(jù)的長期存儲和高效查詢,它采用的列式存儲和LSM樹結構使得數(shù)據(jù)的存儲和查詢更加高效,并且支持ACID事務,保證了數(shù)據(jù)的一致性和可靠性。而Fluss則專注于實時數(shù)據(jù)的處理,具備實時讀寫、流式更新和CDC訂閱等功能,能夠滿足實時性要求較高的場景。兩者結合起來,Paimon可以作為Fluss的長期數(shù)據(jù)存儲倉庫,而Fluss則為Paimon提供實時數(shù)據(jù)的補充,實現(xiàn)了實時數(shù)據(jù)和歷史數(shù)據(jù)的統(tǒng)一管理。例如,在電商平臺的訂單處理系統(tǒng)中,F(xiàn)luss可以實時處理用戶的下單數(shù)據(jù),而Paimon則可以存儲歷史訂單數(shù)據(jù),用于后續(xù)的統(tǒng)計分析和報表生成。
2. 架構融合
Fluss深度融合了Lakehouse架構,而Paimon本身就是一種流式湖倉架構。在集成過程中,F(xiàn)luss的Compaction Service會將實時數(shù)據(jù)定期整理為Paimon格式(如Parquet文件),并存儲在遠程存儲(如S3或HDFS)中,方便后續(xù)批量分析。同時,F(xiàn)link可以支持Union Read,將Fluss和Paimon中的數(shù)據(jù)聯(lián)合起來進行查詢,實現(xiàn)了流存儲和數(shù)據(jù)湖存儲的無縫對接。這種架構融合使得數(shù)據(jù)的存儲和處理更加高效,減少了數(shù)據(jù)冗余和系統(tǒng)復雜度。例如,在構建實時數(shù)據(jù)倉庫時,F(xiàn)luss負責實時數(shù)據(jù)的攝入和處理,Paimon負責歷史數(shù)據(jù)的存儲和管理,兩者共同構成了一個完整的實時數(shù)據(jù)處理架構。
3. 數(shù)據(jù)流動與同步
Fluss的CDC訂閱功能可以生成完整的變更日志,這些變更日志可以實時同步到Paimon中,保證了Paimon中的數(shù)據(jù)與Fluss中的數(shù)據(jù)保持一致。同時,Paimon的事務支持和版本管理功能可以確保數(shù)據(jù)的變更被完整記錄和追溯。在數(shù)據(jù)流動方面,當有新的數(shù)據(jù)寫入Fluss時,F(xiàn)luss會將數(shù)據(jù)同步到Paimon中;而在查詢數(shù)據(jù)時,用戶可以根據(jù)需求選擇從Fluss或Paimon中讀取數(shù)據(jù),或者同時讀取兩者的數(shù)據(jù)進行聯(lián)合查詢。例如,在實時監(jiān)控系統(tǒng)中,F(xiàn)luss實時接收傳感器數(shù)據(jù)并進行處理,同時將數(shù)據(jù)變更同步到Paimon中,用戶可以通過查詢Paimon中的歷史數(shù)據(jù)和Fluss中的實時數(shù)據(jù),實現(xiàn)對系統(tǒng)狀態(tài)的實時監(jiān)控和分析。
4. 共同支持流批一體
Paimon本身支持流批一體的處理模式,而Fluss的實時數(shù)據(jù)處理能力與Paimon的結合,可以更好地實現(xiàn)流批一體的架構。在這種架構下,用戶可以使用相同的代碼和工具處理實時數(shù)據(jù)和批量數(shù)據(jù),提高了開發(fā)效率和數(shù)據(jù)處理的一致性。例如,在處理用戶行為數(shù)據(jù)時,既可以使用Fluss實時處理用戶的當前行為,也可以使用Paimon對歷史行為數(shù)據(jù)進行批量分析,而不需要分別開發(fā)不同的處理邏輯。
三、Paimon和Fluss集成的意義
1. 提升實時數(shù)據(jù)處理能力
Paimon和Fluss的集成可以將Fluss的實時讀寫和更新能力與Paimon的高效存儲和查詢能力相結合,實現(xiàn)對實時數(shù)據(jù)的高效處理和分析。例如,在電商平臺的實時推薦系統(tǒng)中,F(xiàn)luss可以實時處理用戶的行為數(shù)據(jù),而Paimon則可以存儲和管理歷史數(shù)據(jù),兩者結合可以為用戶提供更精準的個性化推薦。
2. 簡化架構和降低成本
傳統(tǒng)的實時數(shù)倉架構可能需要多個組件來實現(xiàn)數(shù)據(jù)的存儲、處理和分析,架構復雜且成本較高。而Paimon和Fluss的集成可以將流存儲和數(shù)據(jù)湖存儲統(tǒng)一管理,減少了系統(tǒng)組件的數(shù)量,簡化了架構,降低了開發(fā)和運維成本。同時,F(xiàn)luss的列式裁剪和實時更新能力可以降低網(wǎng)絡成本和存儲成本。
3. 實現(xiàn)流批一體
Paimon本身支持流批一體的處理模式,而Fluss的實時數(shù)據(jù)處理能力與Paimon的結合,可以更好地實現(xiàn)流批一體的架構。在這種架構下,用戶可以使用相同的代碼和工具處理實時數(shù)據(jù)和批量數(shù)據(jù),提高了開發(fā)效率和數(shù)據(jù)處理的一致性。
4. 增強數(shù)據(jù)的可復用性和可追溯性
Fluss的CDC訂閱功能可以生成完整的變更日志,結合Paimon的事務支持和版本管理,使得數(shù)據(jù)的變更可以被完整記錄和追溯。這不僅方便了數(shù)據(jù)的審計和調(diào)試,還提高了數(shù)據(jù)的可復用性,用戶可以根據(jù)需要隨時獲取歷史數(shù)據(jù)進行分析。
四、Paimon和Fluss的集成方法
1. 環(huán)境準備
(1) 安裝Flink
首先需要安裝Apache Flink,確保其版本與Paimon和Fluss兼容。可以從Apache Flink的官方網(wǎng)站下載相應的版本,并按照官方文檔進行安裝和配置。
(2) 安裝Paimon
將Paimon的相關JAR包添加到Flink的lib目錄下。可以從Maven倉庫下載Paimon的JAR包,例如:
wget https://repo.maven.apache.org/maven2/org/apache/paimon/paimon-flink-1.19/0.9.0/paimon-flink-1.19-0.9.0.jar
cp paimon-flink-1.19-0.9.0.jar /opt/module/bigdata/flink/lib(3) 安裝Fluss
可以從GitHub上克隆Fluss的項目倉庫,并進行編譯和安裝:
git clone https://github.com/alibaba/fluss.git
cd fluss
./mvnw clean package -DskipTests編譯完成后,將生成的相關JAR包添加到Flink的lib目錄下。
2. 配置Fluss和Paimon
(1) 配置Fluss
在Flink里創(chuàng)建一個Fluss表,并加上'table.datalake.enabled' = 'true'這個配置,就可以實現(xiàn)數(shù)據(jù)湖模式。例如:
CREATETABLE fluss_table (
id INT,
name STRING,
age INT,
PRIMARYKEY(id)NOT ENFORCED
)WITH(
'type'='fluss',
'bootstrap.servers'='10.255.10.1:9123',
'table.datalake.enabled'='true'
);(2) 配置Paimon
創(chuàng)建Paimon的Catalog,并指定倉庫路徑:
CREATE CATALOG paimon_catalog WITH(
'type'='paimon',
'warehouse'='hdfs://mycluster/tmp/paimon'
);
USE CATALOG paimon_catalog;3. 啟動Fluss的compact service服務
使用命令./bin/lakehouse.sh -D flink.rest.address=localhost -D flink.rest.port=8081 -D database=fluss_\w+啟動Fluss的compact service服務。有了這個服務支持,當往Fluss表中寫入數(shù)據(jù)時,這些數(shù)據(jù)會自動同步到配置的Paimon數(shù)據(jù)湖。
4. 數(shù)據(jù)查詢
(1) 查詢Paimon數(shù)據(jù)湖中的數(shù)據(jù)
-- read from paimon
SELECTCOUNT(*)FROM orders$lake;
-- we can also query the system tables
SELECT*FROM orders$lake$snapshots;(2) 查詢Fluss和Paimon數(shù)據(jù)的“聯(lián)合視圖”
-- query will union data of Fluss and Paimon
SELECTSUM(order_count)as total_orders FROM ads_nation_purchase_power;(3) 只查詢Fluss中的數(shù)據(jù)
SELECT*FROM orders$lake$snapshots;五、代碼示例
(1) 使用Flink SQL實現(xiàn)數(shù)據(jù)寫入和查詢
-- 創(chuàng)建Fluss表
CREATETABLE fluss_orders (
order_id STRING,
customer_id STRING,
order_amount DOUBLE,
order_time TIMESTAMP(3),
PRIMARYKEY(order_id)NOT ENFORCED
)WITH(
'type'='fluss',
'bootstrap.servers'='10.255.10.1:9123',
'table.datalake.enabled'='true'
);
-- 向Fluss表中寫入數(shù)據(jù)
INSERTINTO fluss_orders
VALUES('001','C001',100.0,TIMESTAMP'2024-12-25 10:00:00'),
('002','C002',200.0,TIMESTAMP'2024-12-25 10:00:30');
-- 查詢Fluss和Paimon數(shù)據(jù)的聯(lián)合視圖
SELECTSUM(order_amount)as total_amount
FROM fluss_orders;(2) 使用Java代碼實現(xiàn)數(shù)據(jù)寫入和查詢
importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
importorg.apache.flink.table.api.bridge.java.StreamTableEnvironment;
importorg.apache.flink.table.api.Table;
importorg.apache.flink.table.api.TableResult;
publicclassPaimonFlussIntegrationExample{
publicstaticvoidmain(String[] args)throwsException{
// 創(chuàng)建流執(zhí)行環(huán)境
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env);
// 創(chuàng)建Fluss表
tableEnv.executeSql("CREATE TABLE fluss_orders (
" +
" order_id STRING,
" +
" customer_id STRING,
" +
" order_amount DOUBLE,
" +
" order_time TIMESTAMP(3),
" +
" PRIMARY KEY (order_id) NOT ENFORCED
" +
") WITH (
" +
" 'type'='fluss',
" +
" 'bootstrap.servers' = '10.255.10.1:9123',
" +
" 'table.datalake.enabled' = 'true'
" +
")");
// 向Fluss表中寫入數(shù)據(jù)
tableEnv.executeSql("INSERT INTO fluss_orders
" +
"VALUES ('001','C001',100.0, TIMESTAMP '2024-12-2510:00:00'),
" +
" ('002', 'C002', 200.0, TIMESTAMP '2024-12-25 10:00:30')");
// 查詢Fluss和Paimon數(shù)據(jù)的聯(lián)合視圖
Table resultTable = tableEnv.sqlQuery("SELECTSUM(order_amount) as total_amount
" +
"FROM fluss_orders");
// 執(zhí)行查詢并打印結果
TableResult result = tableEnv.executeSql("SELECT SUM(order_amount) as total_amount FROM fluss_orders");
result.print();
}
}Paimon和Fluss的集成是大數(shù)據(jù)處理領域的一次重要嘗試,它將流存儲和數(shù)據(jù)湖存儲的優(yōu)勢相結合,為企業(yè)提供了一種高效、低成本的實時數(shù)據(jù)處理解決方案。通過深入分析它們之間的聯(lián)系,我們可以看到兩者在功能、架構、數(shù)據(jù)流動等方面相互補充、相互協(xié)作,實現(xiàn)了實時數(shù)據(jù)和歷史數(shù)據(jù)的統(tǒng)一管理。