Hadoop是什么,架構(gòu)是怎么樣的?
你是一個(gè)程序員,你做了一個(gè)商城網(wǎng)站,里面的東西賣的太好了,每天都會(huì)產(chǎn)生巨量的用戶行為和訂單數(shù)據(jù),通過(guò)分析海量的數(shù)據(jù),老板得出一個(gè)驚人結(jié)論:程序員消費(fèi)力不如狗。
從技術(shù)的角度看,這是一個(gè)將海量數(shù)據(jù)先存起來(lái),再將數(shù)據(jù)拿出來(lái)進(jìn)行計(jì)算,并得到結(jié)果的過(guò)程。
如果使用 mysql 數(shù)據(jù)庫(kù)將這海量數(shù)據(jù)存起來(lái),再執(zhí)行 sql 進(jìn)行統(tǒng)計(jì),大概率直接卡死。
那么問(wèn)題來(lái)了,怎么讀寫(xiě)這類海量數(shù)據(jù)場(chǎng)景呢?
沒(méi)有什么是加一層中間層不能解決的,如果有,那就再加一層。
這次我們要加的是 Hadoop 全家桶和它的朋友們。
 圖片
圖片
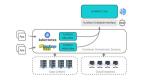
Hadoop 是什么?
像我們平時(shí)用的 mysql,處理個(gè)幾百 GB 數(shù)據(jù)就已經(jīng)比較極限了。如果數(shù)據(jù)再大點(diǎn),比如 TB,PB 這樣的規(guī)模,我們就稱它為大數(shù)據(jù)。
它不僅數(shù)據(jù)規(guī)模大,增長(zhǎng)速度也非常快。mysql根本扛不住。
所以需要有專門的工具做處理。Hadoop 就是一套專門用于大數(shù)據(jù)處理的工具, 內(nèi)部由多個(gè)組件構(gòu)成。
你可以將它理解為應(yīng)用和大數(shù)據(jù)之間的一個(gè)中間層。
以前數(shù)據(jù)量小的時(shí)候,應(yīng)用程序讀寫(xiě) mysql,現(xiàn)在數(shù)據(jù)量大了,應(yīng)用程序就改為讀寫(xiě) Hadoop全家桶。
Hadoop 為應(yīng)用程序屏蔽了大數(shù)據(jù)的一些處理細(xì)節(jié),對(duì)外提供一系列的讀寫(xiě) API, 應(yīng)用通過(guò)調(diào)用 API,實(shí)現(xiàn)對(duì)大數(shù)據(jù)的處理。
 圖片
圖片
我們來(lái)看下它是怎么做到的。
大數(shù)據(jù)怎么處理
大數(shù)據(jù)之所以難處理,本質(zhì)原因在于它大。所以解決思路也很簡(jiǎn)單,核心只有一個(gè)字,那就是"切", 將處理不過(guò)來(lái)的大數(shù)據(jù),切分成一份份處理得過(guò)來(lái)的小數(shù)據(jù)。
 圖片
圖片
對(duì)小份數(shù)據(jù)進(jìn)行存儲(chǔ),計(jì)算等一系列操作。
所以 Hadoop 要解決的核心問(wèn)題有兩個(gè),一個(gè)是怎么存,另一個(gè)是怎么算?
 圖片
圖片
怎么存
對(duì)于 TB,PB 級(jí)別的大數(shù)據(jù),一臺(tái)服務(wù)器的硬盤(pán)裝不下,我們就用多臺(tái)服務(wù)器的硬盤(pán)來(lái)裝。
文件太大,那就切。我們可以將大文件切分成一個(gè)個(gè) 128MB 的數(shù)據(jù)塊,也就是block。
 圖片
圖片
放到多臺(tái)服務(wù)器硬盤(pán)上,怕一臺(tái)數(shù)據(jù)崩了影響數(shù)據(jù)完整性,那就多復(fù)制幾份數(shù)據(jù)在多臺(tái)服務(wù)器備份著。這些存放數(shù)據(jù)的服務(wù)器,就叫 datanode.
 圖片
圖片
以前我們只需要從一臺(tái)服務(wù)器里讀寫(xiě)數(shù)據(jù),現(xiàn)在就變成了需要在多臺(tái)服務(wù)器里讀寫(xiě)數(shù)據(jù),因此需要有一個(gè)軟件為我們屏蔽多臺(tái)服務(wù)器的讀寫(xiě)復(fù)雜性,這個(gè)負(fù)責(zé)切分和存儲(chǔ)數(shù)據(jù)的分布式軟件,就叫 HDFS,全名 Hadoop Distributed File System,也就是 Hadoop 的分布式文件系統(tǒng)。
 圖片
圖片
怎么算
大數(shù)據(jù)的存儲(chǔ)問(wèn)題是解決了,那怎么對(duì)大數(shù)據(jù)進(jìn)行計(jì)算呢?
比如,我們需要統(tǒng)計(jì)商城所有用戶訂單的性別和消費(fèi)金額。
假設(shè)商城的全部訂單數(shù)據(jù)共1280G,想從HDFS全部加載到內(nèi)存中做計(jì)算,沒(méi)有一臺(tái)服務(wù)器扛得住,有解法嗎?
有!跟存儲(chǔ)類似,也將數(shù)據(jù)切分為很多份,每份叫一個(gè)分片,也就是 split, 分給多個(gè)服務(wù)器做計(jì)算,然后再將結(jié)果聚合起來(lái)就好啦。
 圖片
圖片
但每個(gè)服務(wù)器怎么知道該怎么計(jì)算分片數(shù)據(jù)呢?
當(dāng)然是由我們來(lái)告訴它們!
我們需要定義一個(gè) map 函數(shù),告訴計(jì)算機(jī),每個(gè)分片數(shù)據(jù)里的每行訂單數(shù)據(jù)該怎么算。
 圖片
圖片
再定義一個(gè) reduce 函數(shù),告訴計(jì)算機(jī) map 函數(shù)算好的結(jié)果怎么匯總起來(lái)計(jì)算最終結(jié)果。
 圖片
圖片
這個(gè)從hdfs中獲取數(shù)據(jù),再切分?jǐn)?shù)據(jù)為多個(gè)分片,執(zhí)行計(jì)算任務(wù)并匯總的過(guò)程非常通用,用戶只需要自定義里面的 map 和 reduce 函數(shù)就能滿足各種定制化需求,所以我們可以抽象為一個(gè)通用的代碼庫(kù),說(shuō)好聽(tīng)點(diǎn),又叫框架,它就是所謂的 MapReduce。
 圖片
圖片
Yarn 是什么
看到這里問(wèn)題又來(lái)了,MapReduce 的計(jì)算任務(wù)的數(shù)量都這么多,每個(gè)任務(wù)都需要cpu和內(nèi)存等服務(wù)器計(jì)算資源,怎么管理和安排這些計(jì)算任務(wù),到哪些服務(wù)器節(jié)點(diǎn)跑數(shù)據(jù)呢?
很容易想到,我們可以在計(jì)算任務(wù)和服務(wù)器之間,加一個(gè)中間層。
也就是大名鼎鼎的 yarn, 全名 Yet Another Resource Negotiator, 讓它來(lái)負(fù)責(zé)資源的管理。
 圖片
圖片
它將每個(gè)計(jì)算任務(wù)所需要的資源抽象為容器,Container,它本質(zhì)上其實(shí)就是個(gè)被限制了 cpu 和內(nèi)存等計(jì)算資源的 jvm 虛擬機(jī)進(jìn)程,容器內(nèi)運(yùn)行計(jì)算任務(wù)代碼。
 圖片
圖片
yarn 的容器跟 docker/k8s 的容器概念上有點(diǎn)像,但終究不是一回事。具體區(qū)別是什么,評(píng)論區(qū)告訴我。
 圖片
圖片

yarn會(huì)根據(jù)MapReduce這類計(jì)算框架的需求,分配容器資源,再由計(jì)算框架將計(jì)算任務(wù)調(diào)度到,已分配的服務(wù)器容器上運(yùn)行。通過(guò)一系列的資源申請(qǐng)+協(xié)調(diào)調(diào)度,完成 map 和 reduce 的計(jì)算任務(wù)并最終得到計(jì)算結(jié)果。
 圖片
圖片
yarn 和 之前視頻里介紹的k8s 做的事情有點(diǎn)像,它們的區(qū)別是什么,看爽了就評(píng)論區(qū)告訴我。
Hadoop 是什么
到這里,我們用 hdfs 解決了大數(shù)據(jù)的存儲(chǔ)問(wèn)題,用 mapreduce 解決了大數(shù)據(jù)計(jì)算問(wèn)題,用 yarn 解決了 mapreduce 的計(jì)算資源管理問(wèn)題,它們?nèi)齻€(gè)核心組件,共同構(gòu)成了 Hadoop 大數(shù)據(jù)處理框架。
Hive 是什么
到這里問(wèn)題又又來(lái)了,以前數(shù)據(jù)存在 mysql 的時(shí)候,我想統(tǒng)計(jì)下數(shù)據(jù),做下數(shù)據(jù)分析,只需要寫(xiě)點(diǎn) sql。
 圖片
圖片
而現(xiàn)在,在大數(shù)據(jù)場(chǎng)景下,卻要我寫(xiě)那么多 map 和 reduce 函數(shù)。
你擱這跟我開(kāi)玩笑呢?這不變相逼著產(chǎn)品運(yùn)營(yíng) BI 天天按著我寫(xiě) mapreduce 代碼嗎?
我能寫(xiě)代碼,不代表我喜歡寫(xiě)代碼!
我自嘲是牛馬可以,你不能真把我當(dāng)牛馬吧,那該怎么辦呢?
 圖片
圖片
為了讓數(shù)據(jù)分析人員能夠像使用 SQL 一樣方便地查詢大數(shù)據(jù),我們需要一個(gè)工具來(lái)簡(jiǎn)化這個(gè)過(guò)程。
它就是 Hive。你可以將它理解為 sql 和 mapreduce 的一個(gè)中間層。
 圖片
圖片
它可以將用戶輸入的類似 SQL 的查詢語(yǔ)言解析轉(zhuǎn)換成一個(gè)個(gè)復(fù)雜的 mapreduce 任務(wù),運(yùn)行并最終輸出計(jì)算結(jié)果。
 圖片
圖片
這樣,不會(huì)寫(xiě)代碼的人也可以通過(guò)寫(xiě) sql 讀寫(xiě)大數(shù)據(jù)。
 圖片
圖片
Spark和Flink 是什么
現(xiàn)在做一次數(shù)據(jù)分析,Hadoop就得用Hive解析sql,跑mapreduce任務(wù)。一不小心半小時(shí)就過(guò)去了。有辦法更快嗎?
有!MapReduce 會(huì)把計(jì)算過(guò)程中產(chǎn)生的中間結(jié)果放在磁盤(pán)中,這就導(dǎo)致需要頻繁讀寫(xiě)磁盤(pán)文件,略慢。
為了提升性能,可以將中間結(jié)果放在內(nèi)存中,內(nèi)存放不下才放磁盤(pán),那處理速度不就上來(lái)了嗎,基于這個(gè)思路,大佬們?cè)O(shè)計(jì)了Spark, 你可以將它簡(jiǎn)單理解為是通過(guò)內(nèi)存強(qiáng)化性能的 MapReduce。
 圖片
圖片
以前 Hive 可以將 sql 轉(zhuǎn)化為 Mapreduce 的任務(wù),現(xiàn)在同樣也可以通過(guò)一個(gè)叫 Hive on Spark 的適配層接入 Spark ,將 sql 轉(zhuǎn)化為 spark 任務(wù). 這樣 sql 查詢的性能也能得到提升。
 圖片
圖片
但畢竟 hive 本身不是為 spark 設(shè)計(jì)的,所以大佬們又設(shè)計(jì)了 spark sql。它跟 hive 是類似的東西,但跟 spark 搭配起來(lái),性能更好。
 圖片
圖片
但不管是mapreduce還是 Spark, 都是為離線數(shù)據(jù)處理設(shè)計(jì)的,說(shuō)白了就是數(shù)據(jù)是一批一批處理的,一條數(shù)據(jù)來(lái)了,得攢夠一批才會(huì)被處理. 攢的過(guò)程會(huì)浪費(fèi)一些時(shí)間,所以為了更高的實(shí)時(shí)性,大佬們又又設(shè)計(jì)了 flink, 數(shù)據(jù)來(lái)一條就處理一條,完美應(yīng)對(duì)了實(shí)時(shí)性要求較高的在線數(shù)據(jù)處理場(chǎng)景。
 圖片
圖片
Hbase是什么
雖然現(xiàn)在大數(shù)據(jù)存算問(wèn)題及處理問(wèn)題都解決了。但用hive從海量數(shù)據(jù)里讀寫(xiě)一兩條數(shù)據(jù),依然是接近分鐘級(jí)別的操作, flink雖然實(shí)時(shí)性高,但一般面向數(shù)據(jù)處理,而不是在線讀寫(xiě)場(chǎng)景。有辦法像mysql那樣,在毫秒級(jí)別完成實(shí)時(shí)在線讀寫(xiě)嗎?
基于這個(gè)痛點(diǎn),大佬們又設(shè)計(jì)了分布式數(shù)據(jù)庫(kù)Hbase,用于在海量數(shù)據(jù)中高并發(fā)讀寫(xiě)數(shù)據(jù)的場(chǎng)景。
 圖片
圖片
最后我們用一個(gè)例子將它們串起來(lái)。
寫(xiě)數(shù)據(jù)
在大數(shù)據(jù)場(chǎng)景下,我們將數(shù)據(jù)寫(xiě)入到 hdfs 中的多個(gè) datanode 中。
 圖片
圖片
讀數(shù)據(jù)
 圖片
圖片
在數(shù)據(jù)分析場(chǎng)景,用戶將寫(xiě)好的 sql,輸入到 hive 中,hive 會(huì)將 sql 解析為多個(gè) mapreduce 計(jì)算任務(wù),配合 yarn的資源調(diào)度,mapreduce這類計(jì)算框架,將這些計(jì)算任務(wù)分發(fā)到多個(gè)服務(wù)器上,再將計(jì)算好的結(jié)果匯總后,得到最終結(jié)果,最后返回給用戶。完成讀數(shù)據(jù)。
 圖片
圖片
當(dāng)然如果追求性能,也可以將 hive 換成 spark sql,將 mapreduce 換成 spark,通過(guò)內(nèi)存加速整個(gè)讀數(shù)據(jù)的過(guò)程。對(duì)于實(shí)時(shí)性要求高的場(chǎng)景,可以使用flink。
 圖片
圖片
對(duì)于在線實(shí)時(shí)查詢場(chǎng)景,可以通過(guò)hbase,實(shí)現(xiàn)海量數(shù)據(jù)的毫秒級(jí)查詢。
 圖片
圖片
現(xiàn)在大家通了嗎?
好啦,如果你覺(jué)得這期視頻對(duì)你有幫助,記得轉(zhuǎn)發(fā)給你那不成器的兄弟。文字版的筆記,見(jiàn)評(píng)論區(qū)。
最后遺留一個(gè)問(wèn)題,你聽(tīng)說(shuō)過(guò)Mongodb嗎?你知道它是怎么被設(shè)計(jì)出來(lái)的嗎?有Mysql為什么還要有Mongodb?
視頻點(diǎn)贊超過(guò) 1w,下期聊聊這個(gè)話題。如果你感興趣,記得關(guān)注!我們下期見(jiàn)!
總結(jié)
? Hadoop 是一個(gè)開(kāi)源的大數(shù)據(jù)處理框架,主要用于存儲(chǔ)和處理大數(shù)據(jù)。它要解決的核心問(wèn)題有兩個(gè),一個(gè)是怎么存,另一個(gè)是怎么算
? 大數(shù)據(jù)之所以難處理,本質(zhì)原因在于它大。所以解決思路也很簡(jiǎn)單,核心只有一個(gè)字,那就是"切",
? Hdfs 將處理不過(guò)來(lái)的大數(shù)據(jù)切分成一份份處理得過(guò)來(lái)的小數(shù)據(jù)塊。每個(gè) 128MB,存到多個(gè) DataNode 中,解決了存儲(chǔ)的問(wèn)題。
? MapReduce 則通過(guò)一套代碼框架,將數(shù)據(jù)處理抽象為 map 和 reduce 兩個(gè)階段,用戶只要實(shí)現(xiàn)這兩個(gè)函數(shù),框架就會(huì)將大數(shù)據(jù)的處理切分成一個(gè)個(gè)小任務(wù),完成計(jì)算。
? yarn 本質(zhì)上是計(jì)算任務(wù)和服務(wù)器之間的一個(gè)中間層,通過(guò)一系列協(xié)調(diào)調(diào)度,將計(jì)算任務(wù)調(diào)度到合適的服務(wù)器上運(yùn)行,完成 map 和 reduce 的計(jì)算任務(wù)并最終得到最終計(jì)算結(jié)果。