AWS Aurora:云級別的高可用和持久性,同時解決傳統(tǒng)架構(gòu)的性能瓶頸
故事的開始:為什么需要 Aurora?
在云計算的早期,如果你想在云上部署一個數(shù)據(jù)庫,比如 MySQL,通常會怎么做呢?

- EC2 + 本地磁盤 :最直接的方式是在一個 EC2 虛擬機上運行
MySQL,數(shù)據(jù)就存在虛擬機掛載的本地磁盤上。這種方式很簡單,但有個致命缺陷:虛擬機實例是有生命周期的,一旦實例崩潰或其所在的物理機發(fā)生故障,你的數(shù)據(jù)就可能隨之丟失。這對于數(shù)據(jù)庫來說是不可接受的。 - EC2 + EBS :為了解決數(shù)據(jù)持久性問題,Amazon 推出了彈性塊存儲(Elastic Block Store, EBS)。EBS 是一種網(wǎng)絡(luò)附加存儲,它獨立于 EC2 實例的生命周期。即使你的數(shù)據(jù)庫實例崩潰了,你也可以在另一個新的實例上重新掛載同一個 EBS 卷,數(shù)據(jù)安然無恙。為了保證高可用,EBS 內(nèi)部通常會有一主一備兩個副本,但這兩個副本位于同一個 可用區(qū) (Availability Zone, AZ)內(nèi),也就是同一個數(shù)據(jù)中心里,以保證寫入的低延遲。
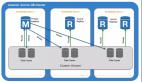
- 多可用區(qū) RDS (Multi-AZ RDS) :雖然 EBS 解決了實例故障問題,但如果整個數(shù)據(jù)中心因為火災(zāi)、洪水或網(wǎng)絡(luò)故障而癱瘓,你的數(shù)據(jù)庫依然會下線。為此,Amazon 推出了跨可用區(qū)的數(shù)據(jù)庫服務(wù)。如論文中的圖 2 所示,它在另一個可用區(qū)建立了一個完整的鏡像。主數(shù)據(jù)庫的每一次寫入,不僅要同步到同區(qū)的 EBS 副本,還要通過網(wǎng)絡(luò)同步到另一個可用區(qū)的鏡像實例及其 EBS 副本上,總共需要等待 4 個副本的寫入確認。這極大地增強了容災(zāi)能力,但也帶來了新的問題: 性能災(zāi)難 。
每一次數(shù)據(jù)庫的修改,哪怕只是幾行數(shù)據(jù),在傳統(tǒng)的數(shù)據(jù)庫架構(gòu)中,不僅要寫日志,還要在未來的某個時刻把被修改的整個“數(shù)據(jù)頁”(通常是 8KB 或 16KB)刷到磁盤上。這種現(xiàn)象被稱為 寫放大 (Write Amplification)。在多可用區(qū) RDS 架構(gòu)下,這些放大了的數(shù)據(jù)(日志 + 數(shù)據(jù)頁)要在網(wǎng)絡(luò)中傳來傳去,導(dǎo)致網(wǎng)絡(luò)不堪重負,數(shù)據(jù)庫吞吐量急劇下降。
正是在這樣的背景下,Aurora 誕生了。它的核心目標是:在提供云級別的高可用和持久性的同時,徹底解決傳統(tǒng)架構(gòu)的性能瓶頸。
核心思想:讓日志成為數(shù)據(jù)庫
Aurora 的設(shè)計者們認為,在現(xiàn)代云環(huán)境中,計算和存儲資源已不再是主要瓶頸,真正的瓶頸在于 網(wǎng)絡(luò) 。既然如此,設(shè)計的核心就應(yīng)該是想盡一切辦法減少網(wǎng)絡(luò)傳輸?shù)臄?shù)據(jù)量。
傳統(tǒng)數(shù)據(jù)庫之所以慢,是因為它把存儲當成一個“笨家伙”,認為它只會讀寫數(shù)據(jù)塊。因此,數(shù)據(jù)庫引擎需要把修改后的、完整的 8KB 數(shù)據(jù)頁通過網(wǎng)絡(luò)發(fā)給存儲層。
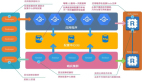
Aurora 的做法則完全不同。它認為,其實只需要把描述“如何修改”的 重做日志 (redo log)發(fā)送給存儲層就足夠了。這些日志記錄通常非常小,只包含被修改的字節(jié)信息。存儲節(jié)點不再是“笨家伙”,而是變得非常“聰明”,它們自己懂得如何解析這些日志,并將修改應(yīng)用到對應(yīng)的數(shù)據(jù)頁上。
這個“將日志處理下推到存儲層”的思路,就是 Aurora 的靈魂。 數(shù)據(jù)庫引擎不再寫入任何數(shù)據(jù)頁,無論是檢查點、緩存淘汰還是后臺寫入,一概沒有。從數(shù)據(jù)庫引擎的視角看, 日志本身就是數(shù)據(jù)庫 (The log is the database)。存儲層物化出的數(shù)據(jù)頁,僅僅是應(yīng)用了日志后的一個緩存而已。
 圖片
圖片
這一改變帶來了驚人的效果。論文的表 1 顯示,在一次 30 分鐘的測試中,Aurora 處理的事務(wù)量是傳統(tǒng)鏡像 MySQL 的 35 倍,而每筆事務(wù)產(chǎn)生的網(wǎng)絡(luò) I/O 卻減少了 7.7 倍。這正是因為它極大地減少了網(wǎng)絡(luò)上的數(shù)據(jù)傳輸量。
堅如磐石:AZ+1 的容災(zāi)與法定人數(shù)模型
解決了性能問題,下一個關(guān)鍵是如何保證高可用和數(shù)據(jù)持久性。Aurora 的目標非常明確:
- 即使一整個可用區(qū)(AZ)掛掉,數(shù)據(jù)庫依然能夠 正常寫入 。
- 即使一整個可用區(qū)(AZ)加上任何另外一個節(jié)點都掛掉,數(shù)據(jù)庫依然能夠 提供讀取 (此時無法寫入)。
這個目標被稱為 “AZ+1” 的容災(zāi)能力。為了實現(xiàn)它,Aurora 使用了 法定人數(shù) (Quorum)模型。
Quorum 的基本思想是,對于 N 個副本,一次寫入操作必須成功寫入 W 個副本,一次讀取操作必須成功讀取 R 個副本。只要滿足 R + W > N,那么你每次讀取的 R 個副本中,必然至少有一個副本包含了最近一次成功寫入的數(shù)據(jù)。
一個簡單的 N=3, W=2, R=2 的 Quorum 系統(tǒng)能容忍單個節(jié)點故障。但它無法滿足 Aurora 的 “AZ+1” 目標。想象一下,3 個副本分布在 3 個 AZ 中,如果一個 AZ 發(fā)生火災(zāi)(這是一個相關(guān)性故障,該 AZ 內(nèi)所有節(jié)點同時失效),此時你只剩下 2 個副本。如果恰好在另一個 AZ 里還有一個節(jié)點因為常規(guī)的硬盤損壞而離線,那么你就只剩 1 個副本了,無法組成讀 Quorum,也就無法確定這最后一份數(shù)據(jù)是不是最新的。
因此,Aurora 采用了更為健壯的方案: 在 3 個不同的 AZ 中,共部署 6 個數(shù)據(jù)副本,每個 AZ 兩個 。
它的 Quorum 配置是:
- 寫入法定人數(shù)
Vw = 4 - 讀取法定人數(shù)
Vr = 3
這個 6-4-3 模型精妙地滿足了 “AZ+1” 的目標:
- 寫可用性 :當一個 AZ(包含 2 個副本)掛掉時,還剩下 4 個副本,正好滿足寫入法定人數(shù)
Vw=4,數(shù)據(jù)庫可以繼續(xù)寫入。 - 讀可用性 :當一個 AZ(2 個副本)和另一個副本掛掉時(共損失 3 個副本),還剩下 3 個副本,正好滿足讀取法定人數(shù)
Vr=3,數(shù)據(jù)庫依然可以讀取數(shù)據(jù),并以此為基礎(chǔ)修復(fù)和重建副本。
秒級恢復(fù):分段存儲與并行修復(fù)
僅僅有強大的 Quorum 模型還不夠。在分布式系統(tǒng)中,故障是常態(tài)。我們需要盡可能縮短從故障中恢復(fù)的時間,也就是降低 平均修復(fù)時間 (Mean Time to Repair, MTTR)。MTTR 越短,系統(tǒng)暴露在風險下的窗口就越小。
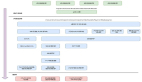
為此,Aurora 引入了 分段存儲 (Segmented Storage)的概念。一個龐大的數(shù)據(jù)庫卷(最大可達 64TB)被切分成很多個固定大小(目前為 10GB)的邏輯塊。每一個 10GB 的塊,連同它的 5 個副本,共同組成一個 保護組 (Protection Group, PG)。每個 PG 的 6 個 10GB 分段 (Segments)同樣遵循 6-4-3 模型,分布在 3 個 AZ 中。
一個數(shù)據(jù)庫卷 (Volume) = [PG 1] + [PG 2] + [PG 3] + ...
PG 1 = [Segment 1.1 (AZ A), Segment 1.2 (AZ A),
Segment 1.3 (AZ B), Segment 1.4 (AZ B),
Segment 1.5 (AZ C), Segment 1.6 (AZ C)]
PG 2 = [Segment 2.1 (AZ A), Segment 2.2 (AZ A),
... ]分段存儲的妙處在于 并行修復(fù) 。假設(shè)一個存儲節(jié)點徹底壞掉了,它上面可能承載著來自上千個不同 PG 的分段。在傳統(tǒng)模式下,你需要從一個備份節(jié)點拷貝海量數(shù)據(jù)(比如 10TB)來恢復(fù),這可能需要數(shù)小時。
但在 Aurora 中,恢復(fù)工作可以完全并行化。PG-1 的分段可以從它的健康副本(比如在節(jié)點 X 上)恢復(fù),PG-2 的分段可以從它的健康副本(比如在節(jié)點 Y 上)恢復(fù)…… 所有這些恢復(fù)任務(wù)可以同時在整個存儲集群中進行。一個 10GB 分段的恢復(fù),在萬兆網(wǎng)絡(luò)下只需要大約 10 秒鐘。這意味著整個故障節(jié)點的恢復(fù)時間被極大地縮短了。
日志的行進:VCL 與 VDL 的精妙設(shè)計
我們已經(jīng)知道 Aurora 的核心是日志。那么,系統(tǒng)是如何精確地管理和使用這些日志的呢?這里有兩個非常關(guān)鍵的概念,它們都與 日志序列號 (Log Sequence Number, LSN)有關(guān),LSN 是一個由數(shù)據(jù)庫引擎生成的、單調(diào)遞增的數(shù)字,用于標識每一條日志記錄的順序。
正常讀寫流程
- 寫入 :客戶端提交一個事務(wù),數(shù)據(jù)庫引擎會為其生成一系列日志記錄。這些日志記錄被發(fā)送給 6 個存儲副本。只有當負責這條事務(wù)的所有日志記錄都得到了至少 4 個副本的持久化確認后,數(shù)據(jù)庫引擎才會認為這次提交是成功的,并向客戶端返回確認。這個過程對客戶端來說是異步的,提交請求的線程不必傻等,可以繼續(xù)處理其他工作,由專門的線程負責返回確認,大大提高了并發(fā)性能。
- 讀取 :當數(shù)據(jù)庫因為緩存未命中而需要從存儲層讀取一個數(shù)據(jù)頁時,它 通常不需要執(zhí)行 Quorum 讀 。因為數(shù)據(jù)庫引擎自己就在追蹤每個存儲分段的日志接收進度,這個進度被稱為 分段完成 LSN (Segment Complete LSN, SCL)。引擎知道哪些節(jié)點的數(shù)據(jù)足夠新,可以直接向其中任何一個節(jié)點發(fā)起讀取請求,非常高效。
崩潰恢復(fù)流程
當數(shù)據(jù)庫主實例崩潰后,一個新的實例會啟動并接管工作。此時,新實例需要確定一個全局一致的、可以從中恢復(fù)的日志點。
- 確定卷完成 LSN (Volume Complete LSN, VCL) :新實例首先會發(fā)起一次 Quorum 讀 (讀取 3 個副本)。它的目標是找出整個存儲卷中,日志記錄保證是連續(xù)且沒有空洞的那個最高的 LSN 。這個點就是 VCL。任何 LSN 大于 VCL 的日志記錄都可能是不完整的(比如,在崩潰前只發(fā)送給了 1、2 個副本),因此必須被截斷和拋棄。
- 確定卷持久 LSN (Volume Durable LSN, VDL) :僅僅保證日志連續(xù)還不夠。數(shù)據(jù)庫內(nèi)部的復(fù)雜操作(比如 B+ 樹的分裂)可能需要多條日志記錄才能完成,這些日志記錄構(gòu)成一個不可分割的原子單元,稱為 迷你事務(wù) (mini-transaction, MTR)。如果只恢復(fù)到 MTR 的中間狀態(tài),數(shù)據(jù)結(jié)構(gòu)就會不一致,導(dǎo)致系統(tǒng)出錯。因此,Aurora 在每個 MTR 的最后一條日志上打上一個標記,稱之為 一致性點 (Consistency Point, CPL)。
VDL 就是在 VCL 之內(nèi)(小于等于 VCL)的那個最高的 CPL 。VDL 確保了數(shù)據(jù)庫從一個絕對安全和數(shù)據(jù)結(jié)構(gòu)完整的點開始恢復(fù)。確定 VDL 后,所有 LSN 高于 VDL 的日志都會被截斷。
最后,數(shù)據(jù)庫會回滾(undo)那些在 VDL 之前開始、但沒有提交記錄的事務(wù)。由于所有繁重的日志重做(redo)工作都由存儲層持續(xù)在后臺進行,Aurora 的崩潰恢復(fù)過程非常快,通常在 10 秒內(nèi)就能完成,無論崩潰前的寫入負載有多大。
走向生產(chǎn):更多實用特性
除了核心架構(gòu)的創(chuàng)新,Aurora 還具備許多為生產(chǎn)環(huán)境量身定制的功能:
- 低成本、低延遲的只讀副本 :Aurora 最多支持 15 個只讀副本。與傳統(tǒng)
MySQL不同,這些副本共享同一份存儲卷,不需要額外的存儲成本。主實例會將日志流實時發(fā)送給只讀副本,副本在內(nèi)存中應(yīng)用這些日志來更新自己的緩存頁。這使得副本的延遲極低(通常在 20 毫秒內(nèi)),遠勝于傳統(tǒng)復(fù)制動輒數(shù)秒甚至數(shù)分鐘的延遲。 - 在線 DDL :現(xiàn)代應(yīng)用開發(fā)中,頻繁修改表結(jié)構(gòu)(Schema)是常態(tài)。
MySQL的很多 DDL 操作會鎖表,甚至拷貝整張表,對生產(chǎn)環(huán)境影響巨大。Aurora 實現(xiàn)了高效的在線 DDL,它通過版本化的 Schema 和寫時修改(modify-on-write)技術(shù),使得大部分結(jié)構(gòu)變更可以平滑進行,不影響業(yè)務(wù)。 - 零停機補丁 (Zero-Downtime Patching, ZDP) :對于云服務(wù),即使是計劃內(nèi)的幾十秒停機更新,也可能讓客戶難以接受。ZDP 技術(shù)可以在一個沒有活動事務(wù)的瞬間,將數(shù)據(jù)庫引擎的狀態(tài)保存下來,快速替換引擎二進制文件,然后恢復(fù)狀態(tài),整個過程對用戶的連接和會話是無感知的。
總結(jié):Aurora 與 Spanner 及未來
與 Google Spanner 的對比 :Aurora 和 Spanner 都強調(diào)跨 AZ 部署和使用 Quorum 模型。但最大的區(qū)別在于,Aurora 是一個 單寫多讀 (single-writer)系統(tǒng),所有寫操作都由一個主實例處理,這極大地簡化了設(shè)計(例如 LSN 的生成)。而 Spanner 是一個真正的多寫(multi-writer)分布式數(shù)據(jù)庫,它通過 Paxos 和兩階段提交來處理分布式事務(wù),擴展性更強,但復(fù)雜性也更高。
- 核心啟示 :Aurora 的成功是一次 跨層優(yōu)化 的典范。它打破了計算與存儲之間的傳統(tǒng)界限,讓存儲變得“智能”,深刻理解數(shù)據(jù)庫的需求。它告訴我們,在設(shè)計云規(guī)模的系統(tǒng)時,必須正視網(wǎng)絡(luò)這一核心瓶頸,并通過精巧的異步化、并行化和定制化設(shè)計來克服它。最終,Aurora 不僅實現(xiàn)了卓越的性能和可用性,還構(gòu)建了一個更簡單、更易于擴展的數(shù)據(jù)庫架構(gòu)基礎(chǔ)。