MiniMax開源首個視覺RL統(tǒng)一框架,閆俊杰領(lǐng)銜!推理感知兩手抓,性能橫掃MEGA-Bench
僅需一個強化學(xué)習(xí)(RL)框架,就能實現(xiàn)視覺任務(wù)大統(tǒng)一?
現(xiàn)有RL對推理和感知任務(wù)只能二選一,但“大模型六小強”之一MiniMax表示:我全都要!
最新開源V-Triune(視覺三重統(tǒng)一強化學(xué)習(xí)系統(tǒng))框架,使VLM首次能夠在單個后訓(xùn)練流程中,聯(lián)合學(xué)習(xí)和掌握視覺推理和感知任務(wù)。
通過三層組件設(shè)計和基于動態(tài)交并比(IoU)的獎勵機制,彌補了傳統(tǒng)RL方法無法兼顧多重任務(wù)的空白。

甚至基于V-Triune,MiniMax還一步到位,貼心地給大家開發(fā)了全新的Orsta(One RL to See Them All)模型系列(7B至32B),在MEGA-Bench Core基準(zhǔn)測試中從+2.1%顯著提升至+14.1%。

值得注意的是,在論文的作者一欄,MiniMax創(chuàng)始人兼CEO閆俊杰也參與了這項研究。

目前V-Triune框架和Orsta模型都在GitHub上實現(xiàn)全面開源,點擊文末鏈接即可跳轉(zhuǎn)一鍵獲取。
那話不多說,咱們直接上細節(jié)。
推理感知“兩手抓”
視覺任務(wù)可以分為推理和感知兩類,在當(dāng)前,RL研究主要集中于數(shù)學(xué)QA和科學(xué)QA等視覺推理任務(wù)。
而目標(biāo)檢測和定位等視覺感知任務(wù),因亟需獨特的獎勵設(shè)計和訓(xùn)練穩(wěn)定性保障,還沒有得到一個很好的解決方案……

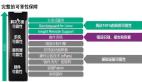
針對上述問題,MiniMax針對性地提出了新框架V-Triune,作為首個面向VLM后訓(xùn)練的統(tǒng)一RL系統(tǒng),通過三個互補組件核心巧妙實現(xiàn)二者的平衡。
樣本級數(shù)據(jù)格式化
讓每個樣本自定義其獎勵設(shè)置和驗證器,支持動態(tài)路由和權(quán)重調(diào)整,以處理多種任務(wù)需求。
數(shù)據(jù)模式基于HuggingFace數(shù)據(jù)集實現(xiàn),包含以下三個字段:
- reward_model:樣本級定義獎勵類型、權(quán)重。
- verifier:指定驗證器及其參數(shù)。
- data_source:標(biāo)識樣本來源。
最終實現(xiàn)了多樣化數(shù)據(jù)集的無縫集成,同時支持高度靈活的獎勵控制。
驗證器級獎勵計算
采用異步客戶端-服務(wù)器架構(gòu),將獎勵計算與主訓(xùn)練循環(huán)解耦。

客戶端通過代理工作器異步發(fā)送請求,而服務(wù)器則根據(jù)”verifier”字段路由至專用驗證器。
主要使用兩類驗證器:
- MathVerifyVerifierr:處理推理、OCR和計數(shù)任務(wù)。
- DetectionVerifier:處理檢測和定位任務(wù),應(yīng)用動態(tài)IoU獎勵。
從而實現(xiàn)在無需修改核心訓(xùn)練流程的情況下,靈活擴展新任務(wù)或更新獎勵邏輯。
數(shù)據(jù)源級指標(biāo)監(jiān)控
在多任務(wù)多源訓(xùn)練中,按數(shù)據(jù)源記錄以下指標(biāo):
- 獎勵值:追蹤數(shù)據(jù)集特定穩(wěn)定性。
- IoU和mAP(感知任務(wù)):記錄不同閾值下的IoU和mAP。
- 響應(yīng)長度和反思率:跟蹤響應(yīng)長度分布、截斷率,以及15個預(yù)定義反思詞(如“re-check”)的出現(xiàn)比例。
該監(jiān)控機制幫助診斷模型行為(如過度思考或膚淺響應(yīng)),并確保學(xué)習(xí)的穩(wěn)定性。

動態(tài)IoU獎勵
此外針對監(jiān)測和定位任務(wù),團隊還創(chuàng)新性地提出了動態(tài)IoU獎勵,分階段調(diào)整閾值,以緩解冷啟動問題,同時引導(dǎo)模型逐步提升定位精度:
- 初始10%訓(xùn)練步驟:
- 10%-25%訓(xùn)練步驟:
- 剩余訓(xùn)練步驟:

雖然V-Triune提供了可擴展的數(shù)據(jù)、任務(wù)和指標(biāo)框架,但早期實驗顯示,聯(lián)合訓(xùn)練可能會導(dǎo)致評估性能下降、梯度范數(shù)突增等不穩(wěn)定現(xiàn)象,于是團隊又通過以下調(diào)整逐步解決:
- 凍結(jié)ViT參數(shù),防止梯度爆炸。
- 過濾偽圖像特殊詞元,確保輸入特征對齊,提升訓(xùn)練穩(wěn)定性。
- 構(gòu)建隨機化CoT提示池,降低提示依賴性。
- 由于V-Triune基于Verl框架實現(xiàn),主節(jié)點內(nèi)存壓力較大,需解耦測試階段與主訓(xùn)練循環(huán)以管理內(nèi)存。
Orsta模型
另外值得一提的是,基于開源的Qwen2.5-VL模型,團隊還訓(xùn)練出7B和32B的Orsta模型。

依據(jù)4類推理任務(wù)(數(shù)學(xué)、謎題、科學(xué)、圖表分析)和4類感知任務(wù)(物體檢測、目標(biāo)定位、計數(shù)、OCR)的訓(xùn)練數(shù)據(jù),進行規(guī)則和難度的兩階段過濾和訓(xùn)練優(yōu)化。
最終實現(xiàn)在MEGA-Bench Core基準(zhǔn)測試中,Orsta相比原始模型提升至+14.1%,尤其是在感知任務(wù)中,mAP指標(biāo)顯著提高,證明了該統(tǒng)一方法的有效性和可擴展性。

MiniMax布局多模態(tài)領(lǐng)域
MiniMax作為商湯背景出身的AI六小龍之一,近期在多模態(tài)領(lǐng)域可謂動作頻頻,模型橫跨語言、音頻、視頻。

例如MiniMax的S2V-01視頻模型、MiniMax-VL-01視覺多模態(tài)模型以及MiniMax-T2A-01系列語言模型等。
尤其是廣受好評的MiniMax-01系列,包含基礎(chǔ)語言模型和視覺多模態(tài)模型兩種,性能上比肩DeepSeek-V3、GPT-4o等國內(nèi)外頂尖模型的同時,還首次創(chuàng)新性實現(xiàn)了對新型Lightning Attention架構(gòu)的大規(guī)模擴展。
最新發(fā)布的Speech-02,在AI語言生成上也是一騎絕塵,直接刷新全球權(quán)威語音基準(zhǔn)測試榜單第一,一舉打破OpenAI、ElevenLabs的行業(yè)壟斷。

同時,據(jù)MiniMax高級研究總監(jiān)鐘怡然同量子位訪談時所說:
MiniMax將會進一步探索多模態(tài)架構(gòu)創(chuàng)新,即原生的生成理解統(tǒng)一大模型的架構(gòu)。
而今天這個統(tǒng)一視覺任務(wù)的RL架構(gòu)也許僅僅是一個開始。
論文鏈接:https://arxiv.org/abs/2505.18129代碼鏈接:https://github.com/MiniMax-AI/One-RL-to-See-Them-All