LLM的 “自信陷阱”:上下文幻覺如何侵蝕 AI 信任?
一、當AI自信地給出錯誤答案
在數字技術飛速發展的今天,大語言模型(LLMs)正以前所未有的速度滲透到我們生活的方方面面。從智能客服到醫療診斷,從金融分析到法律文書,這些模型憑借其強大的語言理解和生成能力,似乎正在重塑人類與信息交互的方式。然而,在其光鮮亮麗的表現背后,一個隱蔽而危險的問題正悄然浮現——上下文幻覺(Contextual Hallucination)。
想象這樣一個場景:一位車主前往車管所辦理車輛異地轉移手續,按照要求需要填寫留置權人(即發放汽車貸款的銀行)的地址。由于手頭沒有現成的信息,他選擇通過谷歌搜索,得到了一個由AI生成的、看起來專業且格式規范的地址。然而,當車管所的工作人員嘗試在系統中驗證該地址時,卻發現它根本不存在。這并非虛構的故事,而是真實發生在現實中的案例。在這個案例中,AI生成的地址雖然看似合理,甚至包含了逼真的郵箱號碼和城市細節,但本質上卻是完全虛構的。這種現象,就是所謂的“上下文幻覺”——AI生成的答案聽起來正確、看起來合理,但卻缺乏真實數據的支撐。
在低風險場景中,這類幻覺可能只是讓人感到些許不便,甚至被輕易忽視。但在供應鏈管理、醫療保健、金融服務等關鍵領域,上下文幻覺可能會引發一系列嚴重后果:它會侵蝕用戶對AI系統的信任,導致決策延遲,甚至引發重大錯誤。當模型虛構業務規則或錯誤報告數據時,人們對整個系統的信心就會開始崩塌,而信任一旦失去,就很難再恢復。因此,解決上下文幻覺問題已不僅僅是一個技術挑戰,更是關乎AI產品完整性和社會公信力的重要議題。
二、上下文幻覺的本質與表現
(一)定義與特征
上下文幻覺是指大語言模型在缺乏真實證據的情況下,生成看似合理但實際錯誤或不存在的信息。這類幻覺具有以下顯著特征:
- 表面合理性幻覺內容通常符合語言邏輯和常識框架,格式規范、表述流暢,甚至包含具體細節(如地址、數據、時間等),極易使人信服。
- 缺乏事實基礎盡管表面上看起來可信,但幻覺內容無法在真實世界的數據源中得到驗證,可能是模型基于訓練數據的統計規律虛構出來的。
- 自信的表述模型在生成幻覺內容時往往表現得非常“自信”,不會主動提示信息的不確定性或潛在錯誤。
(二)典型場景與影響
上下文幻覺的影響范圍廣泛,不同領域的表現和后果也各不相同:
- 金融領域在貸款審批、風險評估等場景中,模型可能虛構客戶信用記錄、偽造金融數據,導致錯誤的貸款決策,引發金融風險。例如,模型可能錯誤地引用某公司的財務指標,誤導投資決策。
- 醫療領域在輔助診斷或藥物推薦環節,幻覺可能導致誤診或錯誤用藥。例如,模型可能虛構某種藥物的適應癥或禁忌癥,威脅患者生命安全。
- 法律領域在合同起草、法律意見生成過程中,模型可能錯誤引用法律條文或虛構司法案例,導致法律糾紛。
- 供應鏈管理模型可能錯誤預測市場需求、虛構供應商信息,導致庫存積壓或供應鏈中斷。
- 公共政策與輿論在信息傳播和政策分析中,幻覺可能生成虛假數據或誤導性結論,影響公眾認知和政策制定。例如,虛構的統計數據可能引發社會恐慌或錯誤的政策導向。
三、上下文幻覺的成因分析
大語言模型之所以會產生上下文幻覺,是其技術特性與運行機制共同作用的結果。以下是幾個關鍵成因:
(一)缺乏事實依據的生成機制
大語言模型本質上是基于海量文本數據訓練的概率模型,其核心目標是預測下一個 token 的概率分布,而非確保生成內容的真實性。當模型無法從外部獲取可靠的上下文信息時,會基于訓練數據中的模式和規律“編造”看似合理的內容。這種生成機制被稱為“缺乏 grounding(接地)”——模型的輸出沒有與真實世界的事實建立有效連接。例如,當用戶詢問一個生僻的專業術語定義時,如果模型的訓練數據中缺乏相關準確信息,就可能生成一個看似合理但錯誤的解釋。
(二)高創造力設置的影響
在模型的生成參數中,“溫度(Temperature)”是一個關鍵指標,用于控制輸出的隨機性和創造性。當溫度設置較高(如超過 0.7)時,模型更傾向于生成多樣化、富有創意的內容,但這也會增加生成 speculative(推測性)或缺乏事實依據內容的風險。例如,在故事創作或詩歌生成場景中,高溫度設置有助于激發創意,但在需要準確信息的場景中,卻可能導致幻覺的產生。
(三)缺乏自動驗證機制
傳統的大語言模型在生成內容時,缺乏一個內置的自動事實核查環節。即使生成的內容存在錯誤,模型也無法自行識別和糾正,往往需要依賴用戶反饋或事后人工核查才能發現問題。這種“無驗證循環”使得幻覺內容能夠輕易地流出系統,進入實際應用場景。例如,在智能客服系統中,模型可能錯誤地回答用戶的問題,而系統無法及時發現并修正錯誤,導致用戶受到誤導。
(四)訓練數據的局限性
大語言模型的訓練數據雖然龐大,但可能存在以下問題:
- 數據偏差訓練數據中可能包含錯誤、過時或偏見性的信息,模型在學習過程中會不自覺地繼承這些缺陷,并在生成內容時表現出來。
- 數據覆蓋不全對于某些專業領域或新興事物,訓練數據可能缺乏足夠的樣本,導致模型無法準確理解和生成相關內容,只能通過推測填補空白。
四、緩解上下文幻覺的策略與實踐
面對上下文幻覺的挑戰,研究者和從業者們提出了一系列有效的緩解策略。這些策略涵蓋了技術架構、模型訓練、應用流程等多個層面,需要結合具體場景綜合運用。
(一)檢索增強生成(RAG:Retrieval-Augmented Generation)
檢索增強生成是一種將大語言模型與外部知識源相結合的技術架構。通過連接向量數據庫、API接口或經過驗證的文檔存儲庫,模型在生成回答之前,首先從外部知識源中檢索相關的事實性信息,確保回答內容基于真實數據,而非單純依賴預訓練知識。
- 工作原理:當用戶提出問題時,系統首先通過檢索模塊從外部知識源中獲取相關上下文信息,然后將這些信息與用戶的問題一起輸入到大語言模型中,引導模型基于真實數據生成回答。
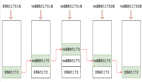
- 典型案例以查詢“第五第三銀行(Fifth Third Bank)的留置權人地址”為例,傳統的大語言模型可能會生成一個虛構的地址(如“P.O. Box 630494, Cincinnati, OH 45263–0494”),而采用RAG架構的系統會先從銀行官網或內部系統中檢索到真實地址(“Fifth Third Bank, P.O. Box 630778, Cincinnati, OH 45263–0778”),然后將其作為上下文提供給模型,確保回答的準確性。
(二)提示工程與驗證邏輯
通過設計合理的提示詞和驗證邏輯,引導模型在生成內容時更加謹慎,并主動識別自身的不確定性。
- 鏈式思維(Chain-of-Thought, CoT) 要求模型在回答問題時,先逐步闡述推理過程,再給出結論。這種方式有助于暴露模型的思維漏洞,減少跳躍性的錯誤推斷。例如,在數學題解答中,模型可以先列出解題步驟,再計算結果,便于發現邏輯錯誤。
- 拒絕機制(Refusal Mechanism) 當模型無法確定答案的準確性時,引導其承認不確定性,而非強行生成一個可能錯誤的回答。例如,當用戶詢問一個超出模型知識范圍的問題時,模型可以回復:“抱歉,我無法確定該信息的準確性,建議查閱相關權威資料。”
(三)生成后事實核查
即使大語言模型表現得非常自信,其生成的內容也可能存在錯誤。因此,在生成回答之后,增加一個自動事實核查環節至關重要。
- 驗證循環(Generate-Verify Loop)將模型生成的內容與原始知識源進行對比,檢查是否存在不一致或錯誤。例如,在生成一個地址后,系統可以自動調用地圖API或企業注冊數據庫進行驗證,確保地址真實存在。
- 示例工作流程
步驟1用戶提問“第五第三銀行的留置權人地址是什么?”模型生成回答“P.O. Box 630494, Cincinnati, OH 45263–0494”。
步驟2系統使用驗證提示詞“請問‘P.O. Box 630494, Cincinnati, OH 45263–0494’是否與以下上下文一致?上下文:‘Fifth Third Bank, P.O. Box 630778, Cincinnati, OH 45263–0778’”,引導模型自我驗證。
步驟3模型識別到地址不一致,返回“不,提供的地址與上下文不匹配”,從而拒絕錯誤輸出。
(四)調整模型生成參數
通過降低“溫度”參數,減少模型輸出的隨機性和創造性,使其更傾向于生成確定性和準確性更高的內容。例如,在需要精確信息的場景中(如金融數據查詢、醫療診斷),將溫度設置為0.1左右,迫使模型從訓練數據中檢索最可能的正確答案,而非進行推測性生成。
(五)人工介入與關鍵數據審核
在高風險場景中,單純依靠技術手段難以完全消除幻覺風險,必須引入人工審核環節。例如,在法律文書生成、醫療處方開具等場景中,AI生成的內容必須經過專業人員的審核和確認,確保其準確性和合規性。人工介入不僅可以識別和糾正模型的錯誤,還能在一定程度上增強用戶對系統的信任。
大語言模型的出現無疑是人工智能領域的一次重大飛躍,其在信息處理和語言生成方面的能力令人驚嘆。然而,上下文幻覺的存在提醒我們,單純追求“智能”是不夠的,AI系統還必須具備“可信”的品質。從車管所的地址錯誤到金融領域的數據分析,從醫療診斷的建議生成到法律文書的條款擬定,上下文幻覺的影響滲透到了各個關鍵領域,威脅著AI技術的應用安全和社會信任。
解決上下文幻覺問題需要技術開發者、企業、政策制定者和用戶的共同努力:技術開發者應致力于改進模型架構和算法,從源頭減少幻覺的產生;企業需在應用過程中建立完善的審核和驗證機制,確保AI輸出的準確性;政策制定者應制定相關標準和規范,引導行業健康發展;用戶則需提高風險意識,理性對待AI提供的信息。