恰到好處:全新GPU已正式上線
AI技術快速發展,我們已經可以輕而易舉地在云端訪問到功能強大的GPU。不過任何搞AI的開發者,如果真的嘗試過云端GPU,不可避免都會遇到一個嚴峻問題:如何選擇適合自己的云服務商以及適合自己需求的GPU,同時又不會亂花冤枉錢,只為自己真正需要并且實際消耗的硬件資源支付合理費用,而不需要支付一大筆預付款或簽訂其他苛刻的合同。

延伸閱讀,點擊鏈接了解 Akamai Cloud Computing
其實這挺難的,不過Akamai就是樂于迎接挑戰。
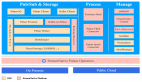
經過嚴格測試和優化,Akamai的新型GPU現已面向所有客戶推出。這些GPU由NVIDIA RTX 4000 Ada Generation提供支持,針對媒體用例進行了優化,規模非常適合各種工作負載和應用。RTX 4000 Ada Generation相關方案的起始價格為每小時0.52美元(該費率包含1 GPU、4 CPU和16 GB RAM),可在下列6個核心計算區域使用:
- 芝加哥:Chicago, IL
- 西雅圖:Seattle, WA
- 法蘭克福:Frankfurt, DE Expansion
- 巴黎:Paris, FR
- 大阪:Osaka, JP
- 新加坡:Singapore, SG Expansion
- 孟買:Mumbai, IN Expansion(即將上線)
特色用例
Akamai提供了Beta測試計劃,客戶和獨立軟件供應商(ISV)合作伙伴可以借此對此次新發布的GPU進行測試,進而評估媒體轉碼和輕量級AI等特色的關鍵用例能從中獲得怎樣的收益。
例如,Capella Systems在云端提供的托管式編碼器Cambria Stream,可以為要求最嚴苛的直播活動處理直播編碼、廣告插入、加密和打包等工作負載。在該服務的幫助下,只需要提供正確的技術和后臺配置,最終用戶即可從各種不同設備上跨越網絡基礎設施觀看直播流媒體事件。
根據Capella Systems的測試,在使用Akamai最新的NVIDIA RTX 4000 Ada Generation Dual GPU后,一個Cambria Stream實例可同時處理多達25個通道的多層編碼,與CPU編碼相比,這大幅降低了總體計算成本。
除了媒體客戶,我們還與Neural Magic合作,使用該公司的企業級LLM(大語言模型)服務引擎nm-vllm,對新GPU的AI功能進行了基準測試。他們利用LLM開源壓縮工具包LLM Compressor實現了更高效的部署,準確率保持在99.9%。在測試最新的Llama 3.1模型時,Neural Magic通過優化相關軟件,使用RTX 4000 GPU實現了每千次“摘要創建”請求的平均處理成本低至0.27美元,與參考系統相比降低了60%。

上手使用
如果你已經是Akamai Connected Cloud用戶,即可立即開始使用。只需選擇一個受支持的區域,然后打開計算實例方案表上的GPU選項卡,即可選擇要使用的實例。

如果尚未注冊,也可以通過下列方式創建自己的賬號并獲得免費額度。
注意:使用Akamai GPU實例要求賬戶有著良好的歷史使用記錄,賬戶中不能包含促銷代碼。如果無法正常部署GPU實例,請聯系技術支持。
—————————————————————————————————————————————————
如您所在的企業也在考慮采購云服務或進行云遷移,
點擊鏈接了解Akamai Linode的解決方案