Flink SQL × Paimon 構建實時數倉優秀實踐
作者:甜獲師兄
Paimon與Apache Flink的集成為用戶提供了強大的實時數據處理和分析能力,使企業能夠構建高性能、高可靠性的實時數據倉庫。
Apache Paimon是一個開源的流式數據湖格式,專為構建實時數據湖架構而設計。它創新地結合了數據湖格式和LSM(日志結構合并樹)結構,將實時流式更新引入數據湖架構。Paimon與Apache Flink的集成為用戶提供了強大的實時數據處理和分析能力,使企業能夠構建高性能、高可靠性的實時數據倉庫。

一、Flink SQL中使用Paimon
1. 創建Paimon Catalog
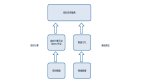
Paimon支持三種類型的元數據存儲:
(1) filesystem
元數據存儲(默認):將元數據和表文件都存儲在文件系統中
(2) hive
元數據存儲:額外將元數據存儲在Hive元數據存儲中,用戶可以直接從Hive訪問表
(3) jdbc
元數據存儲:額外將元數據存儲在關系型數據庫中,如MySQL、PostgreSQL等
- 創建文件系統Catalog:
CREATE CATALOG my_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///path/to/warehouse'
);
USE CATALOG my_catalog;- 創建Hive Catalog:
CREATE CATALOG my_hive WITH (
'type' = 'paimon',
'metastore' = 'hive',
-- 'uri' = 'thrift://<hive-metastore-host-name>:<port>', 默認使用HiveConf中的'hive.metastore.uris'
-- 'hive-conf-dir' = '...', 在kerberos環境中推薦使用
-- 'hadoop-conf-dir' = '...', 在kerberos環境中推薦使用
-- 'warehouse' = 'hdfs:///path/to/warehouse', 默認使用HiveConf中的'hive.metastore.warehouse.dir'
);
USE CATALOG my_hive;2. 創建Paimon表
在Paimon中創建表的示例:
-- 創建一個簡單的表
CREATE TABLE word_count (
word STRING PRIMARY KEY NOT ENFORCED,
cnt BIGINT
);二、流式寫入和實時數據處理
Paimon支持流式寫入和實時數據處理,可以通過Flink SQL或DataStream API實現。
- 使用Flink SQL進行流式寫入:
-- 創建一個Kafka源表
CREATE TABLE kafka_source (
id BIGINT,
name STRING,
age INT,
ts TIMESTAMP(3),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'properties.bootstrap.servers' = 'kafka:9092',
'properties.group.id' = 'testGroup',
'format' = 'json',
'scan.startup.mode' = 'latest-offset'
);
-- 將數據從Kafka寫入Paimon表
INSERT INTO my_paimon_table
SELECT id, name, age, ts
FROM kafka_source;- 使用DataStream API進行流式寫入:
import org.apache.paimon.catalog.CatalogLoader;
import org.apache.paimon.flink.FlinkCatalogFactory;
import org.apache.paimon.catalog.Identifier;
import org.apache.paimon.flink.sink.cdc.RichCdcRecord;
import org.apache.paimon.flink.sink.cdc.RichCdcSinkBuilder;
import org.apache.paimon.options.Options;
import org.apache.paimon.table.Table;
import org.apache.paimon.types.DataTypes;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import static org.apache.paimon.types.RowKind.INSERT;
public class WriteCdcToTable {
public static void writeTo() throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 對于CONTINUOUS_UNBOUNDED源,設置檢查點間隔
// env.enableCheckpointing(60_000);
DataStream<RichCdcRecord> dataStream =
env.fromElements(
RichCdcRecord.builder(INSERT)
.field("order_id", DataTypes.BIGINT(), "123")
.field("price", DataTypes.DOUBLE(), "62.2")
.build()
);
// 獲取Paimon表
Options catalogOptions = new Options();
catalogOptions.set("warehouse", "hdfs:///path/to/warehouse");
Table table = CatalogLoader.load(catalogOptions)
.getTable(Identifier.create("default", "my_table"));
// 構建CDC Sink
RichCdcSinkBuilder.builder(table)
.env(env)
.dataStream(dataStream)
.build();
env.execute("Write CDC to Paimon");
}
}三、CDC變更數據捕獲實現
Paimon支持多種CDC(變更數據捕獲)實現,可以從各種數據源捕獲變更并寫入Paimon表。
1. MySQL CDC實現
使用MySqlSyncTableAction同步MySQL表到Paimon:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-{{version}}.jar \
mysql_sync_table \
--warehouse hdfs:///path/to/warehouse \
--database test_db \
--table test_table \
--partition_keys pt \
--primary_keys pt,uid \
--computed_column '_year=year(age)' \
--mysql_conf hostname=127.0.0.1 \
--mysql_conf username=root \
--mysql_conf password=123456 \
--mysql_conf database-name='source_db' \
--mysql_conf table-name='source_table1|source_table2' \
--catalog_conf metastore=hive \
--catalog_conf uri=thrift://hive-metastore:9083 \
--table_conf bucket=4 \
--table_conf changelog-producer=input \
--table_conf sink.parallelism=42. Kafka CDC實現
Paimon支持多種Kafka CDC格式:Canal Json、Debezium Json、Debezium Avro、Ogg Json、Maxwell Json和Normal Json。
使用KafkaSyncTableAction同步Kafka數據到Paimon:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-{{version}}.jar \
kafka_sync_table \
--warehouse hdfs:///path/to/warehouse \
--database test_db \
--table test_table \
--partition_keys pt \
--primary_keys pt,uid \
--computed_column '_year=year(age)' \
--kafka_conf properties.bootstrap.servers=127.0.0.1:9020 \
--kafka_conf topic=order \
--kafka_conf properties.group.id=123456 \
--kafka_conf value.format=canal-json \
--catalog_conf metastore=hive \
--catalog_conf uri=thrift://hive-metastore:9083 \
--table_conf bucket=4 \
--table_conf changelog-producer=input \
--table_conf sink.parallelism=43. MongoDB CDC實現
使用MongoDBSyncTableAction同步MongoDB集合到Paimon:
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-{{version}}.jar \
mongodb_sync_table \
--warehouse hdfs:///path/to/warehouse \
--database test_db \
--table test_table \
--partition_keys pt \
--computed_column '_year=year(age)' \
--mongodb_conf hosts=127.0.0.1:27017 \
--mongodb_conf username=root \
--mongodb_conf password=123456 \
--mongodb_conf database=source_db \
--mongodb_conf collection=source_table1 \
--catalog_conf metastore=hive \
--catalog_conf uri=thrift://hive-metastore:9083 \
--table_conf bucket=4 \
--table_conf changelog-producer=input \
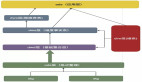
--table_conf sink.parallelism=44. CDC數據流程圖

四、Flink作業性能優化
在使用Paimon與Flink集成時,可以通過以下方式優化性能:
1. 分區和分桶優化
合理設置分區和分桶可以提高查詢性能:
CREATE TABLE orders (
order_id BIGINT,
user_id BIGINT,
product_id BIGINT,
order_time TIMESTAMP(3),
amount DECIMAL(10, 2),
PRIMARY KEY (order_id) NOT ENFORCED
) PARTITIONED BY (DATE_FORMAT(order_time, 'yyyy-MM-dd')) WITH (
'bucket' = '4', -- 設置分桶數
'changelog-producer' = 'input' -- 使用輸入作為變更日志生產者
);2. 并行度優化
設置適當的并行度可以提高寫入和讀取性能:
CREATE TABLE orders (
-- 表結構
) WITH (
'sink.parallelism' = '4', -- 設置Sink并行度
'scan.parallelism' = '4' -- 設置掃描并行度
);3. 檢查點和提交優化
CREATE TABLE orders (
-- 表結構
) WITH (
'commit.force-wait-commit-actions' = 'true', -- 強制等待提交動作完成
'commit.wait-commit-actions-timeout' = '10 min' -- 設置等待提交動作的超時時間
);4. 內存和緩沖區優化
CREATE TABLE orders (
-- 表結構
) WITH (
'write-buffer-size' = '256 MB', -- 設置寫緩沖區大小
'page-size' = '64 KB', -- 設置頁面大小
'target-file-size' = '128 MB' -- 設置目標文件大小
);五、實時數倉構建優秀實踐
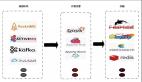
1. 分層架構設計
實時數倉通常采用ODS、DWD、DWS、ADS分層架構:

2. ODS層實現示例
-- 創建ODS層表
CREATE TABLE ods_orders (
order_id BIGINT,
user_id BIGINT,
product_id BIGINT,
order_time TIMESTAMP(3),
amount DECIMAL(10, 2),
order_status STRING,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'changelog-producer' = 'input'
);
-- 從MySQL CDC同步數據
INSERT INTO ods_orders
SELECT order_id, user_id, product_id, order_time, amount, order_status
FROM mysql_cdc_source;3. DWD層實現示例
-- 創建DWD層表
CREATE TABLE dwd_orders (
order_id BIGINT,
user_id BIGINT,
product_id BIGINT,
order_date DATE,
amount DECIMAL(10, 2),
order_status STRING,
PRIMARY KEY (order_id) NOT ENFORCED
) PARTITIONED BY (order_date) WITH (
'bucket' = '4'
);
-- 從ODS層加工數據
INSERT INTO dwd_orders
SELECT
order_id,
user_id,
product_id,
DATE(order_time) AS order_date,
amount,
order_status
FROM ods_orders;4. DWS層實現示例
-- 創建DWS層表
CREATE TABLE dws_daily_sales (
product_id BIGINT,
order_date DATE,
total_amount DECIMAL(20, 2),
order_count BIGINT,
PRIMARY KEY (product_id, order_date) NOT ENFORCED
) PARTITIONED BY (order_date);
-- 從DWD層聚合數據
INSERT INTO dws_daily_sales
SELECT
product_id,
order_date,
SUM(amount) AS total_amount,
COUNT(DISTINCT order_id) AS order_count
FROM dwd_orders
WHERE order_status = 'COMPLETED'
GROUP BY product_id, order_date;5. 實時數倉整體架構

責任編輯:趙寧寧
來源:
大數據技能圈