從RAG到QA-RAG:整合生成式AI以用于藥品監管合規流程
 圖片
圖片
引言
聊天機器人的進步
近期生成式AI的進展顯著增強了聊天機器人的能力。這些由生成式人工智能驅動的聊天機器人在各個行業中的應用正在被探索[Bahrini等人,2023年;Castelvecchi,2023年;Badini等人,2023年],其中制藥行業是一個顯著的關注領域。在藥物發現領域,最近的研究表明,由生成式人工智能驅動的聊天機器人在推進藥物發現方面可以發揮重要作用[Wang等人,2023年;Savage,2023年;Bran等人,2023年]。這樣的進步不僅簡化了發現過程,而且為聊天機器人提出新的研究想法或方法鋪平了道路,增強了研究的協作性。在醫療保健領域,聊天機器人在提供個性化支持方面被證明特別有效,這可以帶來更好的健康結果和更有效的治療管理[Ogilvie等人,2022年;Abbasian等人,2023年]。這些聊天機器人可以提供及時的用藥提醒、傳遞有關潛在副作用的信息,甚至協助安排醫生咨詢。
聊天機器人對藥物監管指導的需求
在制藥行業中,另一個可以充分利用生成式人工智能的關鍵領域是確保符合監管指南的要求。對于行業從業者來說,應對像美國食品藥品監督管理局(FDA)和歐洲藥品管理局(EMA)等機構提供的復雜而廣泛的指南通常是一項令人生畏且耗時的任務。大量的指導方針,加上其復雜的細節,可能使公司難以快速找到并應用相關信息。這通常導致成本增加,因為團隊花費寶貴的時間瀏覽龐大的指導方針資料庫。最近的一項研究強調了遵守監管指導方針的財務影響[Crudeli, 2020]。研究發現,合規工作可能消耗掉中型或大型制藥制造運營預算的25%。鑒于這些挑戰,制藥行業需要一種更高效的方法來導航和解釋監管指導方針。大型語言模型(LLMs)可以有助于解決這個問題。然而,盡管它們經過了廣泛的預訓練,LLMs在獲取未包含在其初始訓練數據中的知識時常常遇到固有的限制。特別是在高度專業化和詳細的制藥監管合規領域,很明顯這種特定領域的知識并未完全包含在訓練材料中。因此,LLMs可能不足以準確回答該領域的問題。
檢索增強生成(RAG)模型作為連接這一差距的橋梁而脫穎而出。它不僅利用了這些模型的內在知識,還從外部來源獲取額外信息以生成響應。如[Wen等人,2023年]和[Yang等人]的工作所示,RAG框架能夠做到這一點。[2023年]的研究展示了如何巧妙地將豐富的背景資料與答案相結合,確保對查詢進行全面準確的回應。這些研究突顯了RAG在多種應用中的多功能性,從復雜故事的生成到定理的證明。
此外,有證據表明,RAG模型在典型的序列到序列模型和某些檢索與提取架構中表現卓越,特別是在知識密集型的自然語言處理任務中。盡管RAG取得了進步,但我們認識到,傳統RAG方法在監管合規領域的準確性可能不足,該領域需要特定領域的、高度專業化的信息。因此,我們引入了問答檢索增強生成(QA-RAG)。QA-RAG模型專為需要專業知識的高度特定領域設計,它精確地將監管指南與實際實施對齊,簡化了制藥行業的合規流程。
核心速覽
研究背景
- 研究問題:這篇文章要解決的問題是如何在制藥行業中利用生成式AI和檢索增強生成(RAG)方法來提高監管合規的效率和準確性。
- 研究難點:該問題的研究難點包括:制藥行業監管指南的復雜性和詳盡性,傳統RAG方法在處理高度專業化信息時的局限性,以及如何在保證準確性的同時提高檢索效率。
- 相關工作:該問題的研究相關工作包括生成式AI在藥物發現和醫療保健中的應用,RAG模型在復雜故事生成和定理證明中的應用,以及在知識密集型NLP任務中的優勢。
研究方法
這篇論文提出了QA-RAG模型用于解決制藥行業監管合規問題。具體來說,
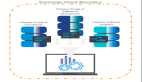
- 整體結構:QA-RAG模型利用微調后的LLM代理提供的答案和原始查詢來檢索文檔。一半的文檔通過微調后的LLM代理提供的答案獲取,另一半通過原始查詢獲取。然后,系統對檢索到的文檔進行重新排序,只保留與問題最相關的文檔。

- 文檔預處理和相似性搜索:使用密集檢索方法(如Facebook AI Similarity Search, FAISS)來提取文檔。文檔通過OCR技術轉換為文本,并分割成多個塊。使用LLM嵌入器對文檔進行嵌入。
- 雙軌檢索:結合微調后的LLM代理的答案和原始查詢進行文檔檢索。這種方法不僅擴大了搜索范圍,還捕捉了更廣泛的相關信息。
- 微調過程:使用FDA的官方問答數據集進行微調。選擇了ChatGPT 3.5- Turbo和Mistral-7B作為基礎LLM模型。微調過程中使用了LoRA技術來高效地調整模型參數。
- 重新排序:使用BGE重新排序器對檢索到的文檔進行重新排序,評估每個文檔與查詢的相關性,并保留相關性最高的文檔。
- 最終答案生成:使用ChatGPT-3.5- Turbo模型作為最終答案代理,通過少樣本提示技術生成最終答案。
實驗設計
- 數據集:使用FDA的官方問答數據集進行微調,共收集到1681個問答對。數據集分為訓練集(85%)、驗證集(10%)和測試集(5%)。
- 實驗設置:在實驗中,固定每次檢索的文檔數量為24個,并在后處理階段篩選出前6個最相關的文檔。比較了不同方法在上下文檢索和答案生成方面的性能。
- 基線選擇:包括僅使用原始查詢的方法、多查詢問題和HyDE方法等。
結果與分析
 圖片
圖片
- 重新排序與評分代理的比較:重新排序器在上下文精度和召回率方面幾乎在所有方法中都優于評分代理,表明重新排序器在準確識別相關文檔方面的優勢。
- 上下文檢索性能評估:QA-RAG模型結合了微調后的LLM代理的答案和原始查詢,實現了最高的上下文精度(0.717)和召回率(0.328)。HyDE方法的性能次之,而僅使用原始查詢的方法表現最差。
- 答案生成性能評估:QA-RAG模型在精度(0.551)、召回率(0.645)和F1分數(0.591)方面均表現出色,接近于上下文檢索性能的前三名。
- 消融研究:僅使用假設答案的方法在上下文精度上略低于完整模型,但顯著高于僅使用原始查詢的方法。這表明假設答案在提高精度方面的關鍵作用。
倫理聲明
在QA-RAG模型的開發和應用中,我們強調其作為醫藥領域專業人士的補充工具的作用。雖然該模型提高了導航復雜指南的效率和準確性,但其設計目的是增強而非取代人類的專業知識和判斷。
用于訓練和評估模型的數據集包括來自美國食品藥品監督管理局(FDA)和國際人用藥品注冊技術協調會(ICH)的公開可訪問文檔,并遵守所有適用的數據隱私和安全協議。
總體結論
這篇論文提出的QA-RAG模型在制藥行業監管合規領域展示了其有效性。通過結合生成式AI和RAG方法,QA-RAG模型能夠高效地檢索相關文檔并生成準確的答案。該模型不僅提高了合規過程的效率和準確性,還減少了對人類專家的依賴,為未來在制藥行業及其他領域的應用奠定了基礎。未來的研究應繼續評估和改進該模型,以應對不斷變化的數據和行業實踐。
論文評價
優點與創新
- 顯著提高了準確性:QA-RAG模型在對比實驗中展示了顯著的準確性提升,超過了所有其他基線方法,包括傳統的RAG方法。
- 結合了生成式AI和RAG方法:該模型巧妙地將生成式AI與檢索增強生成(RAG)方法結合,利用生成式AI的強大生成能力和RAG方法的檢索能力。
- 針對領域高度定制化:QA-RAG模型專為制藥行業的高度專業化領域設計,能夠精確地將監管指南與實際實施對齊,簡化了合規流程。
- 雙重檢索機制:通過結合用戶問題和微調后的LLM生成的假設答案進行文檔檢索,擴大了搜索范圍并捕捉了更廣泛的相關信息。
- 細調后的LLM:使用在特定領域數據上細調的LLM生成假設答案,顯著提高了檢索文檔的精度和準確性。
- 多種評估指標:采用了Ragas框架和BertScore等多種評估指標,全面評估了上下文檢索和答案生成的準確性。
- 公開可用:研究團隊將工作公開發布,以便進一步研究和開發。
不足與反思
- 長期影響需要持續評估:像任何新興技術一樣,QA-RAG模型在各個行業的長期影響需要持續的評估和改進。
- 適應性和魯棒性:需要確保模型在面對數據和行業實踐的變化時保持適應性和魯棒性。
- 模型性能的提升:未來的發展應繼續關注提升模型的性能,確保其與不斷發展的生成式AI技術保持同步。
- 倫理聲明:開發和應用QA-RAG模型時,強調其作為專業人員的補充工具的角色,旨在增強而非取代人類的專業知識和判斷。
關鍵問題及回答
問題1:QA-RAG模型在文檔檢索過程中如何利用生成式AI和RAG方法?
QA-RAG模型采用了雙軌檢索策略,結合了生成式AI和RAG方法。具體步驟如下:
- 文檔預處理和相似性搜索:使用密集檢索方法(如Facebook AI Similarity Search, FAISS)來提取文檔。文檔通過OCR技術轉換為文本,并分割成多個塊。使用LLM嵌入器對文檔進行嵌入。
- 雙軌檢索:結合微調后的LLM代理的答案和原始查詢進行文檔檢索。一半的文檔通過微調后的LLM代理提供的答案獲取,另一半通過原始查詢獲取。這種方法不僅擴大了搜索范圍,還捕捉了更廣泛的相關信息。
- 重新排序:系統對檢索到的文檔進行重新排序,只保留與問題最相關的文檔。使用BGE重新排序器對檢索到的文檔進行重新排序,評估每個文檔與查詢的相關性,并保留相關性最高的文檔。
問題2:在QA-RAG模型中,微調后的LLM代理在文檔檢索和答案生成中的作用是什么?
- 文檔檢索:微調后的LLM代理生成的假設答案被用于檢索文檔。具體來說,一半的文檔通過微調后的LLM代理提供的答案獲取,另一半通過原始查詢獲取。這種方法不僅擴大了搜索范圍,還捕捉了更廣泛的相關信息。
- 答案生成:最終答案通過少樣本提示技術生成,使用ChatGPT-3.5- Turbo模型作為最終答案代理。微調后的LLM代理在生成假設答案時,能夠提供與制藥監管指南高度相關的信息,從而指導后續的文檔檢索和最終答案的生成。
問題3:QA-RAG模型在實驗中表現如何,與其他基線方法相比有哪些優勢?
- 上下文檢索性能:QA-RAG模型結合了微調后的LLM代理的答案和原始查詢,實現了最高的上下文精度(0.717)和召回率(0.328)。相比之下,HyDE方法的性能次之,而僅使用原始查詢的方法表現最差。
- 答案生成性能:QA-RAG模型在精度(0.551)、召回率(0.645)和F1分數(0.591)方面均表現出色,接近于上下文檢索性能的前三名。
- 重新排序與評分代理的比較:重新排序器在上下文精度和召回率方面幾乎在所有方法中都優于評分代理,表明重新排序器在準確識別相關文檔方面的優勢。
- 消融研究:僅使用假設答案的方法在上下文精度上略低于完整模型,但顯著高于僅使用原始查詢的方法。這表明假設答案在提高精度方面的關鍵作用。
總體而言,QA-RAG模型通過結合生成式AI和RAG方法,顯著提高了制藥行業監管合規的效率和準確性,減少了對人類專家的依賴。