得物 iOS 啟動優化之 Building Closure
一、神秘的 BuildingClosure
1. dyld && BuildingClosure
2. BuildingClosure 非常耗時
3. BuildingClosure 文件解析
二、離奇的啟動耗時暴增事件
1. 啟動耗時暴增 200ms
2. BuildingClosure 耗時異常變化定位
三、啟動優化新秘境
1. Perfect Hash
2. 向前一步
四、總結
得物一直重視用戶體驗,尤其是啟動時長這一重要指標。在近期的啟動時長跟進中,我們發現了在BuildingClosure 階段的一個優化方式,成功的幫助我們降低了 1/5 的 BuildingClosure 階段的啟動耗時。Building Closure 并非工程的編譯階段(雖然它有一個building),Building Closure 是應用初次啟動時會經歷的階段,因此它會影響應用的啟動時長。
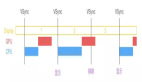
單就BuildingClosure階段而言,我們觀察到該階段其中一個函數從 480ms 暴增到 1200ms 左右(PC 電腦端運行 dyld 調試統計耗時數據),我們通過優化,將耗時從1200ms降低到110ms。即使相比最開始的情況,也相當于從480ms降低到了110ms,由此可見Building Closure 優化是應用進行啟動優化必不可少的一個重要手段。因此在這里我們也和各位讀者進行分享,期望能夠對各自項目有所幫助。
一、神秘的 BuildingClosure
啟動優化的技術、實現方案業界有不少的文章可以參考學習,這里不再額外贅述。我們來探索下啟動過程中非常神秘的 BuildingClosure。
BuildingClosure 是在 System Interface Initialization 階段 dyld 生成的,并且我們也無法做任何的干預,另外相關的剖析文章相對較少,所以說 BuildingClosure 較為神秘,也是實至名歸。
BuildingClosure 是由 dyld 在應用啟動階段執行的,所以想要了解 BuildingClosure 還是要從 dyld 開始了解。
dyld && BuildingClosure
Dyld 源碼可以在 Apple GitHub 上查閱 https://github.com/apple-oss-distributions/dyld
相信大家都應該了解過,BuildingClosure 是在 iOS 13 引入進來的,對應的 dyld 為 dyld3,目的是為了減少啟動環節符號查找、Rebase、Bind 的耗時。
核心技術邏輯是將重復的啟動工作只做一次,在 App 首次啟動、版本更新、手機重啟之后的這次啟動過程中,將相關信息緩存到 Library/Caches/com.app.dyld/xx.dyld 文件中,App 在下次啟動時直接使用緩存好的信息,進而優化二次啟動的速度。
在 iOS 15 Dyld4 中更是引入了 SwiftConformance,進一步解決了運行時 Swift 中的類型、協議檢查的耗時。
 圖片
圖片
以上優化,我們都無需做任何工作即可享受 dyld 帶來的啟動速度的優化,可以感受到 Apple 的開發人員也在關心啟動速度并為之做了大量的工作。
BuildingClosure 非常耗時
我們通過 instrument 觀測到 BuildingClosure 的耗時占據了啟動耗時將近 1/3 的時間。
雖然說,BuildingClosure 只會在首次啟動、版本更新、手機重啟的第一次啟動生成和耗時,但是對用戶的體驗影響是非常之大的。
 圖片
圖片
BuildingClosure 文件解析
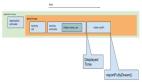
我們通過對 dyld 的編譯和搭建模擬手機環境,成功模擬器了 dyld 加載可執行文件的過程,也就成功解析了 BuildingClosure 文件。BuildingClosure 文件數據格式如下(數據格式、注釋僅供參考,并非全部的數據格式):
") BuildingClosure 文件內部結構(數據格式、注釋僅供參考)
BuildingClosure 文件內部結構(數據格式、注釋僅供參考)
其中占用比較大的部分主要為 Loader-selectorReferencesFixupsSize SwiftTypeConformance objcSelector objcClass
二、離奇的啟動耗時暴增事件
如上,我們已經對 BuildingClosure 有了基本的了解和對 dyld 的執行過程有了一定的了解。但是這份寧靜在某一天突然被打破。
啟動耗時暴增 200ms
在我們一個新版本開發過程中,例行對啟動耗時進行跟蹤測試,但是發現新版本啟動耗時暴增 200ms,可以說是災難級別的事情。
我們開始對最近的出包做了基本的耗時統計,方式為基于 instrument,統計出來啟動各個階段的耗時數據。經過對比,可以明顯觀測到,200ms 耗時的增加表現在 BuildingClosure 這個環節。
但是 BuildingClosure 耗時的增加既不是階梯式增加,也不是線性增加,并且只在新版本有增加。在排除相關因素(動態庫、工程配置、打包腳本、編譯環境)之后,仍然沒有定位明確的原因。
在以上定位工作之后,最終確定耗時確實在 dyld 的 BuildingClosure 階段耗時,并且懷疑可能是某些代碼觸發了 Dyld 的隱藏彩蛋。所以我們開始了對 BuildingClosure 更深一步的研究。
BuildingClosure 耗時異常變化定位
通過使用 Instrument 對 System Interface Initialization 階段進行堆棧分析,最終發現了耗時最高的函數:dyld4::PrebuiltObjC::generateHashTables(dyld4::RuntimeState&)
在對比了新老版本數據,耗時變化差異的函數也是此函數,我們簡稱為 generateHashTables。這樣使得我們更加確定耗時為 dyld 過程中的 BuildingClosure 階段。

使用 Instrument 分析 BuildingClosure 階段耗時
三、啟動優化新秘境
在發現 BuildingClosure 生成過程中耗時占比非常大,并且有異常時,起初并沒有意識到有什么問題,因為這是 dyld 內的代碼,并未感覺會有什么問題。但是一切都指向了該函數,于是開始擼起袖子看代碼。
從代碼中可以看到,此處是為了生成 BuildingClosure 中 objcSelector objcClass objcProtocol 這三個部分的 HashTable(可以參考上面的 【BuildingClosure 文件解析】部分)。
拿起 dyld 開始對耗時異常版本的可執行文件進行調試,通過對該函數和內部實現的代碼邏輯閱讀,以及增加耗時信息打印。最終確定,耗時的代碼在 make_perfect 這個函數中,這個函數是對【輸入的字符串列表】生成一個【完美 Hash 表】。
void PrebuiltObjC::generateHashTables(RuntimeState& state)
{
// Write out the class table
writeObjCDataStructHashTable(state, PrebuiltObjC::ObjCStructKind::classes, objcImages, classesHashTable, duplicateSharedCacheClassMap, classMap);
// Write out the protocol table
writeObjCDataStructHashTable(state, PrebuiltObjC::ObjCStructKind::protocols, objcImages, protocolsHashTable, duplicateSharedCacheClassMap, protocolMap);
// If we have closure selectors, we need to make a hash table for them.
if ( !closureSelectorStrings.empty() ) {
objc::PerfectHash phash;
objc::PerfectHash::make_perfect(closureSelectorStrings, phash);
size_t size = ObjCStringTable::size(phash);
selectorsHashTable.resize(size);
//printf("Selector table size: %lld\n", size);
selectorStringTable = (ObjCStringTable*)selectorsHashTable.begin();
selectorStringTable->write(phash, closureSelectorMap.array());
}
}繼續深入了解 make_perfect 這個函數的實現。
Perfect Hash
通過對研讀代碼邏輯和耗時分析,最終定位到耗時代碼部分為PerfectHash.cpp 中 findhash 函數,這個函數也是 完美散列函數 的核心邏輯。
這里涉及到了一個概念PerfectHash,PerfectHash 的核心是完美散列函數,我們看下維基百科的解釋:
https://zh.wikipedia.org/wiki/%E5%AE%8C%E7%BE%8E%E6%95%A3%E5%88%97
對集合S的完美散列函數是一個將S的每個元素映射到一系列無沖突的整數的哈希函數
簡單來講 完美散列函數 是【對輸入的字符串列表】【為每個字符串生成一個唯一整數】。
for (si=1; ; ++si)
{
ub4 rslinit;
/* Try to find distinct (A,B) for all keys */
*salt = si * 0x9e3779b97f4a7c13LL; /* golden ratio (arbitrary value) */
initnorm(keys, *alen, blen, smax, *salt);
rslinit = inittab(tabb, keys, FALSE);
if (rslinit == 0)
{
/* didn't find distinct (a,b) */
if (++bad_initkey >= RETRY_INITKEY)
{
/* Try to put more bits in (A,B) to make distinct (A,B) more likely */
if (*alen < maxalen)
{
*alen *= 2;
}
else if (blen < smax)
{
blen *= 2;
tabb.resize(blen);
tabq.resize(blen+1);
}
bad_initkey = 0;
bad_perfect = 0;
}
continue; /* two keys have same (a,b) pair */
}
/* Given distinct (A,B) for all keys, build a perfect hash */
if (!perfect(tabb, tabh, tabq, smax, scramble, (ub4)keys.count()))
{
if (++bad_perfect >= RETRY_PERFECT)
{
if (blen < smax)
{
blen *= 2;
tabb.resize(blen);
tabq.resize(blen+1);
--si; /* we know this salt got distinct (A,B) */
}
else
{
return false;
}
bad_perfect = 0;
}
continue;
}
break;
}此時通過對比新老版本的數據(使用 dyld 分別運行新老版本的可執行文件對比打印的日志),發現:
- 老版本循環了 31 次成功生成 HashTable
- 新版本循環了 92 次成功生成 HashTable
至此,我們距離成功已經非常接近了,于是進一步研讀 dyld 源碼和增加了更多打印信息代碼,最終找到了相互沖突的函數字符串名稱。
/*
* put keys in tabb according to key->b_k
* check if the initial hash might work
*/
static int inittab_ts(dyld3::OverflowSafeArray<bstuff>& tabb, dyld3::OverflowSafeArray<key>& keys, int complete, int si)
// bstuff *tabb; /* output, list of keys with b for (a,b) */
// ub4 blen; /* length of tabb */
// key *keys; /* list of keys already hashed */
// int complete; /* TRUE means to complete init despite collisions */
{
int nocollision = TRUE;
ub4 i;
memset((void *)tabb.begin(), 0, (size_t)(sizeof(bstuff)*tabb.maxCount()));
/* Two keys with the same (a,b) guarantees a collision */
for (i = 0; i < keys.count(); i++) {
key *mykey = &keys[i];
key *otherkey;
for (otherkey=tabb[mykey->b_k].list_b;
otherkey;
otherkey=otherkey->nextb_k)
{
if (mykey->a_k == otherkey->a_k)
{
// 打印沖突的字符串
std::cout << mykey->name_k << " and " << otherkey->name_k << " has the same ak " << otherkey->a_k << " si is " << si << std::endl;
nocollision = FALSE;
/* 屏蔽此處代碼,有沖突的情況下,繼續執行,便于打印所有的沖突
if (!complete)
return FALSE;
*/
}
}
++tabb[mykey->b_k].listlen_b;
mykey->nextb_k = tabb[mykey->b_k].list_b;
tabb[mykey->b_k].list_b = mykey;
}
/* no two keys have the same (a,b) pair */
return nocollision;
}根據以上信息,我們已經了解到在Building Closure階段中,可能存在字符串的 Hash 碰撞 引發循環次數大幅增加,進而引發了啟動耗時暴增。
在經過 dyld 調試的耗時數據、構建出包后驗證的數據驗證后,通過避免 Hash 碰撞,我們完成了啟動時長的優化。
向前一步
其實從打印的沖突函數名稱來看,歷史代碼中已經存在了 Hash 碰撞 的現象。
猜想,如果我們解決了所有的字符串的 Hash 碰撞,豈不是不僅可以修復啟動耗時異常上升的問題,還可以進一步降低啟動耗時,提高啟動速度?
于是我們對每個有碰撞的函數名稱進行修改,經過出包驗證,結果與我們猜測的一致,啟動耗時有明顯的下降。
 數據為 PC 電腦端運行 dyld 生成 BuildingClosure 的耗時數據,非手機端數據
數據為 PC 電腦端運行 dyld 生成 BuildingClosure 的耗時數據,非手機端數據
四、總結
我們探索了 BuildingClosure 的生成過程,發現在Building Closure階段中,可能存在字符串的 Hash 碰撞 引發循環次數大幅增加,進而引發了啟動耗時暴增,進而導致啟動耗時的大幅增加。
我們也發現,Building Closure Hash碰撞相關的啟動耗時,其實與項目配置、編譯環境、打包腳本等均無任何關系,就只是存在了字符串的Hash 碰撞 ,才引發循環次數大幅增加,進而導致啟動時長增加。