來聊聊大廠常用的分布式 ID 生成方案
隨著數據日益增加,項目需要進行分庫分表來分攤壓力,為了保證數據ID唯一,必須有一套適配當前分庫分表的分布式ID生成方案,而這套方案必須具備以下條件:
- 全局唯一:分布式ID必須全局唯一,確保數據可以被唯一確定。
- 高性能:高并發場景下分布式ID必須快速響應生成。
- 高并發:分庫分表數據存儲大概率會出現高并發量的請求,所以這套方案必須在高并發場景下快速生成id。
- 高可用: 需要無限接近百分百的可用,避免因為因為分布式ID生成影響其他業務運行。
- 易用:方案必須易于使用,不大量侵入業務代碼。
- 遞增:盡可能保證遞增,確保ID有序插入以保證插入性能和索引維護開銷。
所以本文就基于上述要求針對市面主流的幾種分布式ID算法的特點和適用場景展開深入探討。

1. 詳解UUID
UUID有著全球唯一的特性,只需一行簡單的代碼,即可快速生成一個UUID:
public static void main(String[] args) {
log.info("uuid:{}", UUID.randomUUID());
}輸出結果:
uuid:9fea8ab3-0789-4719-aa70-8849cbc59916符合全局唯一、高性能、高并發、高可用、易用的特性。但是它卻有以下缺點:
- 字符串類型:因為是字符類型,占用大量存儲空間。
- 無序:因為生成的無規律,因為大量的隨機添加勢必導致MySQL底層大量的B+ tree的節點分裂,耗費大量計算資源,嚴重影響數據庫性能,進而導致查詢耗時增加。
所以UUID雖在性能、唯一性、可用性上有著保證,但其生成結果會加劇數據庫的負擔,所以不是很推薦用作分布式ID。
2. 利用數據庫主鍵自增
我們也可以專門使用一張數據表生成唯一自增的id,通過數據庫auto_increment特性自增唯一且有序的分布式ID:
CREATE TABLE id_allocation (
id INT AUTO_INCREMENT PRIMARY KEY
);這種做法優點就是實現簡單且單調遞增,ID也是數值類型,所以查詢速度很快,但它也有以下缺點:
- 單點性能瓶頸:所有的ID都需要依賴這張數據表生成,如果出現單點故障,很可能導致服務癱瘓。
- 性能瓶頸:單個數據庫一下子接收大量請求連接接入(經過壓測8C16G在數據表設計良好的情況下TPS大約在2500~3000左右),可能會導致數據庫服務癱瘓:

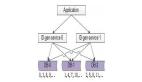
3. 分庫分表主鍵自增
針對上述問題,我們提出使用多庫多表生成分布式ID以保證高可用,例如我們現在就使用雙主模式,每個庫分別存放一張id分配表(id_allocation ),表1的id從1開始,表2的id從2開始,各自的步長都為2:
-- ID分配表1,從1開始自增,步長為2
CREATE TABLE db1.id_allocation (
id INT AUTO_INCREMENT PRIMARY KEY
) AUTO_INCREMENT=1;
-- ID分配表2,從2開始自增,步長為2
CREATE TABLE db2.id_allocation (
id INT AUTO_INCREMENT PRIMARY KEY
) AUTO_INCREMENT=2;為了保證壓力均攤,我們可以針對服務采用輪詢或者哈希算法請求不同的數據庫獲取唯一ID:

該方案很好的解決的DB單點問題,但是僅僅為了全局id而徒增這么多的硬件服務器確實是有些許浪費。
4. 號段式id分配策略
號段式分布式ID生成是當下比較主流的實現方案之一,它的整體思路是在專門建立一張數據表劃分當前業務的ID分配段,每次加載一批號段到內存中,然后所有的服務都從這個號碼段中獲取ID,直至這個號碼段用完,然后再到數據庫中再劃動一批到內存中使用,對應的建表SQL如下所示:
CREATE TABLE id_allocation (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT '當前已用最大id',
step int(20) NOT NULL COMMENT '號段分配步長',
biz_type int(20) NOT NULL COMMENT '業務類型',
version int(20) NOT NULL COMMENT '版本號',
PRIMARY KEY (`id`)
)我們假設現在有一個訂單服務要采用號段式進行ID分配,我們在這張表中初始化訂單服務的數據,可以看到訂單服務初始化的數據,max_id為0,即表示當前這個業務還未分配任何id,業務類型為1,step為1000,即代表每次有服務來請求時就分配1000個id段給請求服務,而version則是保證多服務請求數據一致性的樂觀鎖版本號:
INSERT INTO id_allocation (id, max_id, step, biz_type, version) VALUES (1, 0, 1000, 1, 0);到數據查詢當前業務的號碼段,查詢數據庫得到結果是max_id為0以及step為1000,這意味著當前這個業務的id已經用到了0(還未使用過),而可用范圍為1000,所以號碼段為[max_id+1,max_id+step]即1~1000,將數據庫加載到數據庫之后,攜帶版本號將數據的max_id更新為max_id+step,如此一來下次id分配就從1000開始:
update table set max_id=max_id+step
為了避免因為服務崩潰等情況導致內存中的號碼段丟失,我們需要如下兩個步驟的處理避免ID沖突:
- 每一次服務重啟時,先加載一批號碼段到內存中,然后更新數據庫中的max_id,盡管這么做可能導致一部分的id浪費,但是這種即用即更新很好的解決的id沖突的問題。

- 編寫AOP切面或者其他任何方式,當捕獲到ID沖突異常后,直接更新內存中的號碼段,在業務上盡可能直接解決意外沖突。
可以說這種方案通過數據庫結合內存緩沖了數據庫的壓力,既保證的唯一性,又能夠抗住高并發,對于擴容,我們也可以通過在數據庫中增加配置,以調整id范圍。而它的缺點也很明顯,它很可能因為服務宕機或者內存丟失的原因,導致一段id全部丟棄導致一定的號碼段浪費。
5. 基于redis原子自增指令INCR
按照redis官方的說法,redis單機qps為8~10w(8C16G服務器)并且因為單線程的緣故,redis也能很好的保證id自增的原子性:

所以我們也可以嘗試通過redis原子操作獲取唯一id:
127.0.0.1:6379> set seq_id 1
OK
127.0.0.1:6379> INCR seq_id
(integer) 2
127.0.0.1:6379> INCR seq_id
(integer) 3
127.0.0.1:6379> INCR seq_id
(integer) 4
127.0.0.1:6379>當然這種方案也有著一定的缺點:
- 若我們使用rdb持久化機制,一旦redis宕機等原因導致緩存丟失,再次從redis中獲取的id很可能出現沖突。
- 若使用aof會導致每一條命令都會進行持久化,但也會導致重啟數據恢復時間過長。

所以我們建議通過redis混合持久化機制結合redis高可用架構保證分布式id生成的可靠性,并在業務處理上對這類id沖突進行一定的兜底處理。
6. 雪花算法
(1) 雪花id算法介紹
雪花算法是twitter開發是一中id生成算法,它是由如下幾個因子構成:
- 1位正數位,即高位為0。
- 41位時間戳
- 5位workerid記錄用戶維護當前服務器的id號。
- 5位的服務id
- 12位的自增序列
對應結構圖如下所示:

通過雪花算法在毫秒級情況下可以生成大量id,性能出色,且是有序自增的,類型也是long類型,且包含日期和workerid等具備基因特性的因子,可以滿足大部分業務場景的需求,只不過雪花算法也有一些考慮的問題:
- 時鐘回撥問題:我們都知道雪花算法有41位是時間戳組成,在高并發場景下回撥時間很可能出現相同的時間戳,很可能造成id沖突的場景。
- 無法滿足多分片鍵場景,雪花算法雖能保證id唯一,對于單一條件綽綽有余,一旦遇到多分片鍵依賴單id的場景就顯得力不從心了。
舉個例子:在商城下單后,我們通過雪花算法生成唯一訂單號,根據hash算法id%table 得到分表名稱。這樣的話,我們通過訂單號可以快速定位到分表并查詢到數據。但是從用戶角度來說,他希望通過自己的uid定位到訂單號就無跡可尋了,所以針對多分片鍵的場景使用雪花算法可以需要結合基因法進行一番改造。
(2) 使用示例
以下是開源工具類hutool提供的雪花工具類,只需兩行代碼即可生成唯一鍵。
@Slf4j
public class Main {
public static void main(String[] args) {
Snowflake snowflake = new Snowflake();
log.info("snowflake:{}", snowflake.nextId());
}
}輸出結果如下:
12:23:24.412 [main] INFO com.sharkchili.distIdFactory.Main - snowflake:1740226920726044672為了驗證唯一性,筆者在單位時間內連續生成100w的雪花id:
@Slf4j
public class Main {
public static void main(String[] args) {
Set<Long> idSet = new HashSet<>();
Snowflake snowflake = new Snowflake();
for (int i = 0; i < 100_0000; i++) {
idSet.add(snowflake.nextId());
}
log.info("idSe sizet:{}", idSet.size());
}
}從輸出結果來看,常規用法下沒有出現id碰撞:
12:35:27.167 [main] INFO com.sharkchili.distIdFactory.Main - idSe sizet:1000000(3) 雪花id與時鐘回撥問題
我們都知道雪花id是通過時間戳結合自增序列等方式保證分布式id的唯一性,但是這種方案其實也存在一定的缺陷。
我們假設這樣一個場景,我們現在的雪花id工具類在服務器1上,所以在這臺服務器上的id對應的機器id和服務id都是相等的。唯一性都是通過時間戳+自增序列來保證,試想一下如果我們在雪花id工具工作期間,將操作系統時間回撥,這就可能出現之前用過時間戳+自增序列重復,進而導致數據入庫失敗:

對此著名的java工具類庫hutool就做的很好,它會在每次生成雪花id時,維護一下生成的時間戳,每次生成時通過比對本次時間戳和上次時間戳的差值判斷是否出現時鐘回撥:
public synchronized long nextId() {
long timestamp = genTime();
//判斷本次回撥的時間是否大于timeOffset(默認2s),即回撥超過2s就報錯
if (timestamp < this.lastTimestamp) {
if (this.lastTimestamp - timestamp < timeOffset) {
// 容忍指定的回撥,避免NTP校時造成的異常
timestamp = lastTimestamp;
} else {
// 如果服務器時間有問題(時鐘后退) 報錯。
throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", lastTimestamp - timestamp));
}
}
//......
//維護本次使用的時間戳
lastTimestamp = timestamp;
return ((timestamp - twepoch) << TIMESTAMP_LEFT_SHIFT)
| (dataCenterId << DATA_CENTER_ID_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}(4) 基于雪花算法下的帶有基因的分布式ID
如上所說,雪花算法中時間戳和workerId這幾個字段都算是有跡可循的因子,作為特定基因可以保證分庫分表不同維度的查詢需求,例如我們現在有這樣一個場景:
- 按照業務評估我們需要分出3個庫。
- 每個庫12張表,每張表代表存儲對應月份的數據。
- 插入時按照月份決定插入的分表,并且數據要盡可能均攤分散到不同的庫中。
- 查詢時能夠基于id定位到庫源并將數據查詢出來。
由上文提及雪花算法有41位代表生成id的時間戳,所以針對時間分表讀寫都是可以實現的。而上述需求中有3個庫,按照雪花算法的規則,它有5位的workerid,我們完全可以用這幾個bit存儲當前數據所存儲的庫源信息。
我們都知道分庫分表主要是為了解決并發請求和海量數據,所以針對這樣的業務場景,我們勢必會針對該場景設計出相應的集群節點,我們假設當前集群有3個節點,按照分庫分表的設計,我們可以將分庫分表業務對應的服務程序各自初始化一個雪花id生成器,服務的workerId分別對應1、2、3。
假設某用戶請求到的服務1且日期是2025.1.25,由于服務器的workerId為1,所以雪花id的機器id就標記為1,同時基于當前時間點得出41位的時間戳為2025.1.25也就是分表-1,所以我們數據就會寫入到庫1的分表1中:

因為id藏有庫源信息和日期信息,后續定位也非常方便,就像下面這段代碼示例:
//指明workerId為1,即當表當前服務的數據全部存入庫1
Snowflake snowflake = new Snowflake(1);
long id = snowflake.nextId();
//后續數據讀寫都可以基于id定位到
DateTime date = DateUtil.date(snowflake.getGenerateDateTime(id));
log.info("分布式id對應的庫源:{} 日期:{}", snowflake.getWorkerId(id), date);對應的我們也給出這段代碼的輸出結果:
01:13:43.446 [main] INFO com.sharkChili.runner.ESRunner - 分布式id對應的庫源:1 日期:2025-01-25 01:13:43