剛剛,OpenAI開啟語音智能體時代,API價格低至每分鐘0.015美元
今天凌晨,OpenAI 突然開啟了新產品發布直播,這次新發布的內容全是音頻模型。

據介紹,它們實現了新的 SOTA 水平,在準確性和可靠性方面優于現有解決方案——尤其是在涉及口音、嘈雜環境和不同語速的復雜場景中。這些改進提高了語音 / 文本轉錄應用的可靠性,新模型特別適合客戶呼叫中心、會議記錄轉錄等用例。
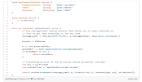
基于新的 API,開發人員第一次可以指示文本轉語音模型以特定方式說話,例如讓 AI「像富有同情心的客戶服務人員一樣說話」,從而為語音智能體開啟新的定制化維度,可以實現各種定制應用程序。
OpenAI 還開放了一個網站,讓你可以直接測試音頻大模型的能力:https://www.openai.fm/

OpenAI 于 2022 年推出了第一個音頻模型,并一直致力于提高這些模型的智能性、準確性和可靠性。借助新的音頻模型及 API,開發人員可以構建更準確、更強大的語音轉文本系統以及富有表現力、個性十足的文本轉語音聲音。
具體來說,新的 gpt-4o-transcribe 和 gpt-4o-mini-transcribe 模型與原始 Whisper 模型相比改進了單詞錯誤率,提高了語言識別和準確性。
gpt-4o-transcribe 在多個既定基準中展示了比現有 Whisper 模型更好的單詞錯誤率 (WER) 性能,實現了語音轉文本技術的重大進步。這些進步源于強化學習創新以及使用多樣化、高質量音頻數據集進行的大量中期訓練。
這些新的語音-文本模型可以更好地捕捉語音的細微差別,減少誤認,并提高轉錄可靠性,尤其是在涉及口音、嘈雜環境和不同語速的具有挑戰性的場景中。

幾種模型的單詞錯誤率(越低越好)。

在 FLEURS 上,OpenAI 的模型實現了更低的 WER 和強大的多語言性能。WER 越低越好,錯誤越少。
OpenAI 還推出了一個可操縱性更好的新 gpt-4o-mini-tts 模型。在其之上,開發人員第一次可以「指導」模型,不僅可以指導模型說什么,還可以指導模型如何說,從而為大量用例提供更加定制化的體驗。該模型可在 text-to-speech API 中使用。不過目前,這些文本轉語音模型僅限于人工預設的聲音,且受到 OpenAI 的監控。
就在昨天,OpenAI 推出的「最貴大模型 API」o1-pro API 還因為每百萬 token 收費 600 美元而遭到了 AI 社區的廣泛吐槽。今天 OpenAI 推出的三款語音 API 價格倒是保持了業界平均水準:gpt-4o-mini-tts 的百萬 token 文本輸入價格是 $0.60,音頻輸出價格為 $12.00;gpt-4o-transcrib 文本輸入價格是 $2.50,音頻輸入價格 $10.00,音頻輸出價格 $6.00;gpt-4o-mini-transcribe 的文本輸入價格是 $1.25,音頻輸入價格 $5.00,音頻輸出價格 $3.00。
因此今天的發布也受到了人們的歡迎。

OpenAI 的新音頻模型基于 GPT?4o 和 GPT?4o-mini 架構,并在專門的以音頻為中心的數據集上進行了廣泛的預訓練,這對于優化模型性能至關重要。這種有針對性的方法可以更深入地了解語音細微差別,并在與音頻相關的任務中實現出色的性能。
在模型訓練中,OpenAI 增強了提煉技術,使知識從最大的音頻模型轉移到了更小、更高效的模型上。利用先進的自我博弈方法,OpenAI 的提煉數據集有效地捕捉了真實的對話動態,復制了真正的用戶助手交互,這有助于小型模型提供出色的對話質量和響應能力。
OpenAI 的語音轉文本模型集成了大量強化學習,將轉錄準確性推向了最先進的水平。據稱,這種方法大大提高了精度并減少了幻覺,使語音轉文本解決方案在復雜的語音識別場景中具有極強的競爭力
這些發展代表了音頻建模領域的進步,將創新方法與實用增強功能相結合,以增強語音應用程序的性能。
這些新的音頻模型現在可供所有開發人員使用:https://platform.openai.com/docs/guides/audio

對于已經使用基于文本的模型構建對話體驗的開發人員,添加 OpenAI 語音轉文本和文本轉語音模型是構建語音智能體的最簡單方法。OpenAI 發布了與 Agents SDK 的集成以簡化此開發過程。對于希望構建低延遲語音轉語音體驗的開發人員,OpenAI 建議使用 Realtime API 中的語音轉語音模型進行構建。
在未來,OpenAI 計劃繼續提升音頻模型的智能性和準確性,并探索允許開發人員使用自定義聲音構建更加個性化體驗的方法。包括視頻等更多模態的能力也在研發過程當中。