DeepSeek 3FS 架構(gòu)分析和思考(上篇)
2025 年 2 月28 日,DeepSeek 在其開源周最后一天壓軸發(fā)布了自研的并行文件系統(tǒng) Fire-Flyer File System,簡稱 3FS。該系統(tǒng)支撐了 DeepSeek V3&R1 模型訓(xùn)練、推理的全流程,在數(shù)據(jù)預(yù)處理、數(shù)據(jù)集加載、CheckPoint、KVCache 等場景發(fā)揮了重要作用。
項目一經(jīng)發(fā)布,就獲得了存儲領(lǐng)域的廣泛關(guān)注。大家迫切地想一探究竟,看看 3FS 到底有哪些壓箱底的獨門秘籍。火山引擎文件存儲團(tuán)隊閱讀和分析了 3FS 的設(shè)計文檔和源代碼,總結(jié)出這篇文章,在介紹了 3FS 關(guān)鍵設(shè)計的同時,嘗試從存儲專業(yè)的視角挖掘出 3FS 團(tuán)隊在這些設(shè)計背后的考量。
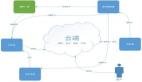
一、3FS 整體架構(gòu)
 圖片
圖片
與業(yè)界很多分布式文件系統(tǒng)架構(gòu)類似,3FS 整個系統(tǒng)由四個部分組成,分別是 Cluster Manager、Client、Meta Service、Storage Service。所有組件均接入 RDMA 網(wǎng)絡(luò)實現(xiàn)高速互聯(lián),DeepSeek 內(nèi)部實際使用的是 InfiniBand。
Cluster Manager 是整個集群的中控,承擔(dān)節(jié)點管理的職責(zé):
- Cluster Manager 采用多節(jié)點熱備的方式解決自身的高可用問題,選主機(jī)制復(fù)用 Meta Service 依賴的 FoundationDB 實現(xiàn);
- Meta Service 和 Storage Service 的所有節(jié)點,均通過周期性心跳機(jī)制維持在線狀態(tài),一旦這些節(jié)點狀態(tài)有變化,由 Cluster Manager 負(fù)責(zé)通知到整個集群;
- Client 同樣通過心跳向 Cluster Manager 匯報在線狀態(tài),如果失聯(lián),由 Cluster Manager 幫助回收該 Client 上的文件寫打開狀態(tài)。
Client 提供兩種客戶端接入方案:
- FUSE 客戶端 hf3fs_fuse 方便易用,提供了對常見 POSIX 接口的支持,可快速對接各類應(yīng)用,但性能不是最優(yōu)的;
- 原生客戶端 USRBIO 提供的是 SDK 接入方式,應(yīng)用需要改造代碼才能使用,但性能相比 FUSE 客戶端可提升 3-5 倍。
Meta Service 提供元數(shù)據(jù)服務(wù),采用存算分離設(shè)計:
- 元數(shù)據(jù)持久化存儲到 FoundationDB 中,F(xiàn)oundationDB 同時提供事務(wù)機(jī)制支撐上層實現(xiàn)文件系統(tǒng)目錄樹語義;
- Meta Service 的節(jié)點本身是無狀態(tài)、可橫向擴(kuò)展的,負(fù)責(zé)將 POSIX 定義的目錄樹操作翻譯成 FoundationDB 的讀寫事務(wù)來執(zhí)行。
Storage Service 提供數(shù)據(jù)存儲服務(wù),采用存算一體設(shè)計:
- 每個存儲節(jié)點管理本地 SSD 存儲資源,提供讀寫能力;
- 每份數(shù)據(jù) 3 副本存儲,采用的鏈?zhǔn)綇?fù)制協(xié)議 CRAQ(Chain Replication with Apportioned Queries)提供 write-all-read-any 語義,對讀更友好;
- 系統(tǒng)將數(shù)據(jù)進(jìn)行分塊,盡可能打散到多個節(jié)點的 SSD 上進(jìn)行數(shù)據(jù)和負(fù)載均攤。
二、3FS 架構(gòu)詳解
1.集群管理
整體架構(gòu)
一個 3FS 集群可以部署單個或多個管理服務(wù)節(jié)點 mgmtd。這些 mgmtd 中只有一個主節(jié)點,承接所有的集群管理響應(yīng)訴求,其它均為備節(jié)點僅對外提供查詢主的響應(yīng)。其它角色節(jié)點都需要定期向主 mgmtd 匯報心跳保持在線狀態(tài)才能提供服務(wù)。

節(jié)點管理
每個節(jié)點啟動后,需要向主 mgmtd 上報必要的信息建立租約。mgmtd 將收到的節(jié)點信息持久化到 FoundationDB 中,以保證切主后這些信息不會丟失。節(jié)點信息包括節(jié)點 ID、主機(jī)名、服務(wù)地址、節(jié)點類別、節(jié)點狀態(tài)、最后心跳的時間戳、配置信息、標(biāo)簽、軟件版本等。
租約建立之后,節(jié)點需要向主 mgmtd 周期發(fā)送心跳對租約進(jìn)行續(xù)租。租約雙方根據(jù)以下規(guī)則判斷租約是否有效:
- 如果節(jié)點超過 T 秒(可配置,默認(rèn) 60s)沒有上報心跳,主 mgmtd 判斷節(jié)點租約失效;
- 如果節(jié)點與主 mgmtd 超過 T/2 秒未能續(xù)上租約,本節(jié)點自動退出。
對于元數(shù)據(jù)節(jié)點和客戶端,租約有效意味著服務(wù)是可用的。但對于存儲服務(wù)節(jié)點,情況要復(fù)雜一些。一個存儲節(jié)點上會有多個 CRAQ 的 Target,每個 Target 是否可服務(wù)的狀態(tài)是不一致的,節(jié)點可服務(wù)不能代表一個 Target 可服務(wù)。因此,Target 的服務(wù)狀態(tài)會進(jìn)一步細(xì)分為以下幾種:

元數(shù)據(jù)和存儲節(jié)點(包括其上的 Target)的信息,以及下文會描述的 CRAQ 復(fù)制鏈表信息,共同組成了集群的路由信息(RoutingInfo)。路由信息由主 mgmtd 廣播到所有的節(jié)點,每個節(jié)點在需要的時候通過它找到其它節(jié)點。
選主機(jī)制
mgmtd 的選主機(jī)制基于租約和 FoundationDB 讀寫事務(wù)實現(xiàn)。租約信息 LeaseInfo 記錄在 FoundationDB 中,包括節(jié)點 ID、租約失效時間、軟件版本信息。如果租約有效,節(jié)點 ID 記錄的節(jié)點即是當(dāng)前的主。每個 mgmtd 每 10s 執(zhí)行一次 FoundationDB 讀寫事務(wù)進(jìn)行租約檢查,具體流程如下圖所示。
 圖片
圖片
上述流程通過以下幾點保證了選主機(jī)制的正確性:
- LeaseInfo 的讀取和寫入在同一個 FoundationDB 讀寫事務(wù)里完成,F(xiàn)oundationDB 讀寫事務(wù)確保了即使多個 mgmtd 并發(fā)進(jìn)行租約檢查,執(zhí)行過程也是串行一個一個的,避免了多個 mgmtd 交織處理分別認(rèn)為自己成為主的情況。
- 發(fā)生切主之后新主會靜默 120s 才提供服務(wù),遠(yuǎn)大于租約有效時長 60s,這個時間差可以保證老主上的在飛任務(wù)有充足的時間處理完,避免出現(xiàn)新主、老主并發(fā)處理的情況。
2.客戶端
整體架構(gòu)
 圖片
圖片
3FS 提供了兩種形態(tài)的客戶端,F(xiàn)USE 客戶端 hf3fs_fuse 和原生客戶端 USRBIO:
- FUSE 客戶端適配門檻較低,開箱即用。在 FUSE 客戶端中,用戶進(jìn)程每個請求都需要經(jīng)過內(nèi)核 VFS、FUSE 轉(zhuǎn)發(fā)給用戶態(tài) FUSE Daemon 進(jìn)行處理,存在 4 次“內(nèi)核-用戶態(tài)”上下文切換,數(shù)據(jù)經(jīng)過 1-2 次拷貝。這些上下文切換和數(shù)據(jù)拷貝開銷導(dǎo)致 FUSE 客戶端的性能存在瓶頸;
- USRBIO 是一套用戶態(tài)、異步、零拷貝 API,使用時需要業(yè)務(wù)修改源代碼來適配,使用門檻高。每個讀寫請求直接從用戶進(jìn)程發(fā)送給 FUSE Daemon,消除了上下文切換和數(shù)據(jù)拷貝開銷,從而實現(xiàn)了極致的性能。
FUSE 客戶端
FUSE 客戶端基于 libfuse lowlevel api 實現(xiàn),要求 libfuse 3.16.1 及以上版本。和其它業(yè)界實現(xiàn)相比,最大的特色是使用了 C++20 協(xié)程,其它方面大同小異。本文僅列舉一些實現(xiàn)上值得注意的點:

USRBIO
基于共享內(nèi)存 RingBuffer 的通信機(jī)制被廣泛應(yīng)用在高性能存儲、網(wǎng)絡(luò)領(lǐng)域,在 DPDK、io_uring 中均有相關(guān)實現(xiàn),一般采用無鎖、零拷貝設(shè)計,相比其它通信的機(jī)制有明顯的性能提升。3FS 借鑒了這個思路實現(xiàn)了 USRBIO,和原有的 FUSE 實現(xiàn)相比,有以下特點:
- 整個執(zhí)行路徑非常精簡,完全在用戶態(tài)實現(xiàn),不再需要陷入內(nèi)核經(jīng)過 VFS、FUSE 內(nèi)核模塊的處理
- 讀寫數(shù)據(jù)的 buffer 和 RDMA 打通,整個處理過程沒有拷貝開銷
- 只加速最關(guān)鍵的讀寫操作,其它操作復(fù)用 FUSE 現(xiàn)有邏輯,在效率和兼容性之間取得了極佳的平衡。這一點和 GPU Direct Storage 的設(shè)計思路有異曲同工之處
USRBIO 的使用說明可以參考 3FS 代碼庫 USRBIO API Reference 文檔:
https://github.com/deepseek-ai/3FS/blob/main/src/lib/api/UsrbIo.md
 圖片
圖片
在實現(xiàn)上,USRBIO 使用了很多共享內(nèi)存文件:
1.每個 USRBIO 實例使用一個 Iov 文件和一個 Ior 文件
- Iov 文件用來作為讀寫數(shù)據(jù)的 buffer
a.用戶提前規(guī)劃好需要使用的總?cè)萘?/p>
b.文件創(chuàng)建之后 FUSE Daemon 將該其注冊成 RDMA memory buffer,進(jìn)而實現(xiàn)整個鏈路的零拷貝
- Ior 文件用來實現(xiàn) IoRing
a.用戶提前規(guī)劃好并發(fā)度
b.在整個文件上抽象出了提交隊列和完成隊列,具體布局參考上圖
c.文件的尾部是提交完成隊列的信號量,F(xiàn)USE Daemon 在處理完 IO 后通過這個信號量通知到用戶進(jìn)程
2.一個掛載點的所有 USRBIO 共享 3 個 submit sem 文件
- 這三個文件作為 IO 提交事件的信號量(submit sem),每一個文件代表一個優(yōu)先級
- 一旦某個 USRBIO 實例有 IO 需要提交,會通過該信號量通知到 FUSE Daemon
3.所有的共享內(nèi)存文件在掛載點 3fs-virt/iovs/ 目錄下均建有 symlink,指向 /dev/shm 下的對應(yīng)文件
Iov、Ior 共享內(nèi)存文件通過 symlink 注冊給 FUSE Daemon,這也是 3FS FUSE 實現(xiàn)上有意思的一個點,下一章節(jié)還會有進(jìn)一步的描述。
symlink 黑魔法
通常一個文件系統(tǒng)如果想實現(xiàn)一些非標(biāo)能力,在 ioctl 接口上集成是一個相對標(biāo)準(zhǔn)的做法。3FS 里除了使用了這種方式外,對于 USRBIO、遞歸刪除目錄、禁用回收站的 rename、修改 conf 等功能,采用了集成到 symlink 接口的非常規(guī)做法。
3FS 采用這種做法可能基于兩個原因:
- ioctl 需要提供專門的工具或?qū)懘a來使用,但 symlink 只要有掛載點就可以直接用。
- 和其它接口相比,symlink 相對低頻、可傳遞的參數(shù)更多。
symlink 的完整處理邏輯如下:
- 當(dāng)目標(biāo)目錄為掛載點 3fs-virt 下的 rm-rf、iovs、set-conf 目錄時:
- rm-rf:將 link 路徑遞歸刪除,請求發(fā)送給元數(shù)據(jù)服務(wù)處理;
- iovs:建 Iov 或者 Ior,根據(jù) target 文件后綴判定是否 ior;
- set-conf:設(shè)置 config 為 target 文件中的配置。
- 當(dāng) link 路徑以 mv: 開頭,rename 緊跟其后的 link 文件路徑到 target 路徑,禁用回收站。
- 其它 symlink 請求 Meta Service 進(jìn)行處理。
FFRecord
3FS 沒有對小文件做調(diào)優(yōu),直接存取大量小文件性能會比較差。為了彌補這個短板,3FS 專門設(shè)計了 FFRecord (Fire Flyer Record)文件格式來充分發(fā)揮系統(tǒng)的大 IO 讀寫能力。
FFRecord 文件格式具有以下特點:
- 合并多個小文件,減少了訓(xùn)練時打開大量小文件的開銷;
- 支持隨機(jī)批量讀取,提升讀取速度;
- 包含數(shù)據(jù)校驗,保證讀取的數(shù)據(jù)完整可靠。
以下是 FFRecord 文件格式的存儲 layout:
 圖片
圖片
在 FFRecord 文件格式中,每一條樣本的數(shù)據(jù)會做序列化按順序?qū)懭耄瑫r文件頭部包含了每一條樣本在文件中的偏移量和 crc32 校驗和,方便做隨機(jī)讀取和數(shù)據(jù)校驗。
3.存儲服務(wù)
整體架構(gòu)
3FS 面向高吞吐能力而設(shè)計,系統(tǒng)吞吐能力跟隨 SSD 和網(wǎng)絡(luò)帶寬線性擴(kuò)展,即使發(fā)生個別 SSD 介質(zhì)故障,也能依然提供很高的吞吐能力。3FS 采用分?jǐn)偛樵兊逆準(zhǔn)綇?fù)制 CRAQ 來保證數(shù)據(jù)可靠性,CRAQ 的 write-all-read-any 特性對重讀場景非常友好。
 圖片
圖片
每個數(shù)據(jù)節(jié)點通過 Ext4 或者 XFS 文件系統(tǒng)管理其上的多塊 NVME DISK,對內(nèi)部模塊提供標(biāo)準(zhǔn)的 POSIX 文件接口。數(shù)據(jù)節(jié)點包含幾個關(guān)鍵模塊:Chunk Engine 提供 chunk 分配管理;MetaStore 負(fù)責(zé)記錄分配管理信息,并持久化到 RocksDB 中;主 IO handle 提供正常的讀寫操作。各個數(shù)據(jù)節(jié)點間組成不同的鏈?zhǔn)綇?fù)制組,節(jié)點之間有復(fù)制鏈間寫 IO、數(shù)據(jù)恢復(fù) sync 寫 IO。
CRAQ
鏈?zhǔn)綇?fù)制是將多個數(shù)據(jù)節(jié)點組成一條鏈 chain,寫從鏈?zhǔn)组_始,傳播到鏈尾,鏈尾寫完后,逐級向前發(fā)送確認(rèn)信息。標(biāo)準(zhǔn) CRAQ 的讀全部由鏈尾處理,因為尾部才是完全寫完的數(shù)據(jù)。
多條鏈組成 chain table,存放在元數(shù)據(jù)節(jié)點,Client 和數(shù)據(jù)節(jié)點通過心跳,從元數(shù)據(jù)節(jié)點獲取 chain table 并緩存。一個集群可有多個 chain table,用于隔離故障域,以及隔離不同類型(例如離線或在線)的任務(wù)。
3FS 的寫采用全鏈路 RDMA,鏈的后繼節(jié)點采用單邊 RDMA 從前序節(jié)點讀取數(shù)據(jù),相比前序節(jié)點通過 RDMA 發(fā)送數(shù)據(jù),少了數(shù)據(jù)切包等操作,性能更高。而 3FS 的讀,可以向多個數(shù)據(jù)節(jié)點同時發(fā)送讀請求,數(shù)據(jù)節(jié)點通過比較 commit version 和 update version 來讀取已經(jīng)提交數(shù)據(jù),多節(jié)點的讀相比標(biāo)準(zhǔn) CRAQ 的尾節(jié)點讀,顯著提高吞吐。
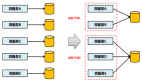
1)數(shù)據(jù)打散
傳統(tǒng)的鏈?zhǔn)綇?fù)制以固定的節(jié)點形成 chain table。如圖所示節(jié)點 NodeA 只與 NodeB、C 節(jié)點形成 chain。若NodeA 故障,只能 NodeB 和 C 分擔(dān)讀壓力。
3FS 采用了分?jǐn)偸降拇蛏⒎椒ǎ粋€ Node 承擔(dān)多個 chain,多個 chain 的數(shù)據(jù)在集群內(nèi)多個節(jié)點進(jìn)行數(shù)據(jù)均攤。如圖所示,節(jié)點 NodeA 可與 Node B-F 節(jié)點組成多個chain。若 NodeA 產(chǎn)生故障,NodeB-F 更多節(jié)點分擔(dān)讀壓力,從而可以避免 NodeA 節(jié)點故障的情況下,產(chǎn)生節(jié)點讀瓶頸。

2)文件創(chuàng)建流程
- 步驟 1:分配 FoundationDB 讀寫事務(wù);
- 步驟 2:事務(wù)內(nèi)寫目標(biāo)文件的 dentry、inode;創(chuàng)建文件是繼承父目錄 layout,根據(jù) stripe size 選取多條 chain,并記錄在 inode 中;寫打開創(chuàng)建場景,還會寫入對應(yīng) file session;
- 步驟 3:事務(wù)內(nèi)將父目錄inode、 目標(biāo) dentry 加入讀沖突列表。保證父目錄未被刪除,及檢查目標(biāo)文件已存在場景;
- 步驟 4:提交讀寫事務(wù)。
3)讀寫流程
寫數(shù)據(jù)流程:
- 步驟 1:Client 獲取數(shù)據(jù)的目標(biāo) chain,并向 chain 首節(jié)點 NodeA 發(fā)送寫請求;
- 步驟 2:NodeA 檢查 chain version 并鎖住 chunk,保證對同一 chunk 的串行寫,再用單邊 RDMA 從 client 讀取數(shù)據(jù),寫入本地 chunk,記錄 updateVer;
- 步驟 3:NodeA 將寫請求傳播到 NodeB 和 NodeC,NodeB 和 NodeC 處理邏輯和NodeA相同;
- 步驟 4:chain 尾節(jié)點 NodeC 寫完數(shù)據(jù)后,將回復(fù)傳播到 NodeB,NodeB 更新 commitVer 為 updateVer;
- 步驟 5:NodeB 將回復(fù)傳播到 NodeA,NodeA處理同NodeB;
- 步驟 6:NodeA 回復(fù) Client 寫完成。
 圖片
圖片
讀數(shù)據(jù)流程:
- 步驟1:Client 獲取數(shù)據(jù)所在的 chain,并向 chain 某個節(jié)點 NodeX 發(fā)讀請求;
- 步驟2:NodeX 檢查本地 commitVer 和 updateVer 是否相等;
a.步驟 2.1:如果不等,說明有其它 flying 的寫請求,通知 Client 重試;
b.步驟 2.2:如果相等,則從本地 chunk 讀取數(shù)據(jù),并通過 RDMA 寫給 Client;
 圖片
圖片
文件布局
一個文件在創(chuàng)建時,會按照父目錄配置的 layout 規(guī)則,包括 chain table 以及 stripe size,從對應(yīng)的 chain table中選擇多個 chain 來存儲和并行寫入文件數(shù)據(jù)。chain range 的信息會記錄到 inode 元數(shù)據(jù)中,包括起始 chain id 以及 seed 信息(用來做隨機(jī)打散)等。在這個基礎(chǔ)之上,文件數(shù)據(jù)被進(jìn)一步按照父目錄 layout 中配置的 chunk size 均分成固定大小的 chunk(官方推薦 64KB、512KB、4MB 3 個設(shè)置,默認(rèn) 512KB),每個 chunk 根據(jù) index 被分配到文件的一個 chain上,chunk id 由 inode id + track + chunk index 構(gòu)成。當(dāng)前 track 始終為 0,猜測是預(yù)留給未來實現(xiàn) chain 動態(tài)擴(kuò)展用的。

訪問數(shù)據(jù)時用戶只需要訪問 Meta Service 一次獲得 chain 信息和文件長度,之后根據(jù)讀寫的字節(jié)范圍就可以計算出由哪些 chain 進(jìn)行處理。
假設(shè)一個文件的 chunk size 是 512KB,stripe size 是200,對應(yīng)的會從 chain table 里分配 200 個 chain 用來存儲這個文件的所有 chunk。在文件寫滿 100MB(512KB * 200)之前,其實并不是所有的 chain 都會有 chunk 存儲。在一些需要和 Storage Service 交互的操作中,比如計算文件長度(需要獲得所有chain上最后一個chunk的長度)、或者 Trucate 操作,需要向所有潛在可能存放 chunk 的 Storage Service 發(fā)起請求。但是對不滿 100MB(不滿stripe size個chunk)的小文件來說,向 200 個 chain 的 Storage Service 都發(fā)起網(wǎng)絡(luò)請求無疑帶來無謂的延時增加。
為了優(yōu)化這種場景,3FS 引入了 Dynamic Stripe Size 的機(jī)制。這個的作用就是維護(hù)了一個可能存放有 chunk 的chain數(shù)量,這個值類似 C++ vector 的擴(kuò)容策略,每次 x2 來擴(kuò)容,在達(dá)到 stripe size 之后就不再擴(kuò)了。這個值的作用是針對小文件,縮小存放有這個文件數(shù)據(jù)的 chain 范圍,減少需要和 Storage Service 通信的數(shù)量。
通過固定切分 chunk 的方式,能夠有效的規(guī)避數(shù)據(jù)讀寫過程中與 Meta Service 的交互次數(shù),降低元數(shù)據(jù)服務(wù)的壓力,但是也引入另外一個弊端,即對寫容錯不夠友好,當(dāng)前寫入過程中,如果一個 chunk 寫失敗,是不支持切下一個 chunk 繼續(xù)寫入的,只能在失敗的 chunk 上反復(fù)重試直到成功或者超時失敗。
單機(jī)引擎
Chunk Engine 由 chunk data file、Allocator、LevelDB/RocksDB 組成。其中 chunk data file 為數(shù)據(jù)文件;Allocator 負(fù)責(zé) chunk 分配;LevelDB/RocksDB 主要記錄本地元數(shù)據(jù)信息,默認(rèn)使用 LevelDB。
為確保查詢性能高效,內(nèi)存中全量保留一份元數(shù)據(jù),同時提供線程級安全的訪問機(jī)制,API 包括:

Chunk
Chunk 大小范圍 64KiB-64MiB,按照 2 的冪次遞增,共 11 種,Allocator 會選擇最接近實際空間大小的物理塊進(jìn)行分配。
對于每種物理塊大小,以 256 個物理塊組成一個 Resource Pool,通過 Bitmap 標(biāo)識空間狀態(tài),為 0 代表空閑可回收狀態(tài),分配的時候優(yōu)先分配空閑可回收的物理塊。
寫入流程
- 修改寫:采用 COW 的方式,Allocator優(yōu)先分配新的物理塊,系統(tǒng)讀取已經(jīng)存在的 Chunk Data 到內(nèi)存,然后填充 update 數(shù)據(jù),拼裝完成后寫入新分配的物理塊;
- 尾部 Append 寫:數(shù)據(jù)直接寫入已存在 block,會新生成一份元數(shù)據(jù)包括新寫入的 location 信息和已經(jīng)存在的 chunk meta 信息,原子性寫入到 LevelDB 或 RocksDB 中,以避免覆蓋寫帶來的寫放大。
數(shù)據(jù)恢復(fù)
存儲服務(wù)崩潰、重啟、介質(zhì)故障,對應(yīng)的存儲 Target 不參與數(shù)據(jù)寫操作,會被移動到 chain 的末尾。當(dāng)服務(wù)重新啟動的時候,offline 節(jié)點上對應(yīng)存儲 Target的數(shù)據(jù)為老數(shù)據(jù),需要與正常節(jié)點的數(shù)據(jù)進(jìn)行補齊,才能保證數(shù)據(jù)一致性。offline 的節(jié)點周期性的從 cluster manager 拉取最新的 chain table 信息,直到該節(jié)點上所有的存儲Target 在 chain table 中都被標(biāo)記為 offline 以后,才開始發(fā)送心跳。這樣可以保證該節(jié)點上的所有存儲 Target 各自獨立進(jìn)入恢復(fù)流程。數(shù)據(jù)恢復(fù)采用了一種 full-chunk-replace 寫的方式,支持邊寫邊恢復(fù),即上游節(jié)點發(fā)現(xiàn)下游的 offline 節(jié)點恢復(fù),開始通過鏈?zhǔn)綇?fù)制把寫請求轉(zhuǎn)發(fā)給下游節(jié)點,此時,哪怕 Client 只是寫了部分?jǐn)?shù)據(jù),也會直接把完整的 chunk 復(fù)制給下游,實現(xiàn) chunk 數(shù)據(jù)的恢復(fù)。
數(shù)據(jù)恢復(fù)過程整體分成為兩個大步驟:Fetch Remote Meta、Sync Data。其中 Local node代表前繼正常節(jié)點,Remote node為恢復(fù)節(jié)點。
1)數(shù)據(jù)恢復(fù)流程
- 步驟 1:Local Node 向 Remote Node 發(fā)起 meta 獲取,Remote Node 讀取本地 meta;
- 步驟 2:Remote Node 向 Local Node 返回元數(shù)據(jù)信息,Local Node 比對數(shù)據(jù)差異;
- 步驟 3:若數(shù)據(jù)有差異,Local Node 讀取本地 chunk 數(shù)據(jù)到內(nèi)存;
- 步驟 4:Remote Node 單邊讀取 Local Node chunk 內(nèi)存數(shù)據(jù);
- 步驟 5:Remote Node 申請新 chunk,并把數(shù)據(jù)寫入新 chunk。
 圖片
圖片
2)Sync Data 原則
- 如果 chunk Local Node 存在 Remote Node 不存在,需要同步;
- 如果 Remote Node 存在 Local Node不存在,需要刪除;
- 如果 Local Node 的 chain version 大于Remote Node,需要同步;
- 如果 Local Node 和Remote Node chain version 一樣大,但是 commit version 不同,需要同步;
- 其他情況,包括完全相同的數(shù)據(jù),或者正在寫入的請求數(shù)據(jù),不需要同步。
3.元數(shù)據(jù)服務(wù)
整體架構(gòu)
業(yè)界基于分布式高性能 KV 存儲系統(tǒng),構(gòu)建大規(guī)模文件系統(tǒng)元數(shù)據(jù)組件已成共識,如 Google Colossus、Microsoft ADLS 等。3FS 元數(shù)據(jù)服務(wù)使用相同設(shè)計思路,底層基于支持事務(wù)的分布式 KV 存儲系統(tǒng),上層元數(shù)據(jù)代理負(fù)責(zé)對外提供 POSIX 語義接口。總體來說,支持了大部分 POSIX 接口,并提供通用元數(shù)據(jù)處理能力:inode、dentry 元數(shù)據(jù)管理,支持按目錄繼承 chain 策略、后臺數(shù)據(jù) GC 等特性。
 圖片
圖片
3FS 選擇使用 FoundationDB 作為底層的 KV 存儲系統(tǒng)。FoundationDB 是一個具有事務(wù)語義的分布式 KV 存儲,提供了 NoSQL 的高擴(kuò)展,高可用和靈活性,同時保證了serializable 的強 ACID 語義。該架構(gòu)簡化了元數(shù)據(jù)整體設(shè)計,將可靠性、擴(kuò)展性等分布式系統(tǒng)通用能力下沉到分布式 KV 存儲,Meta Service 節(jié)點只是充當(dāng)文件存儲元數(shù)據(jù)的 Proxy,負(fù)責(zé)語義解析。
利用 FoundationDB SSI 隔離級別的事務(wù)能力,目錄樹操作串行化,沖突處理、一致性問題等都交由 FoundationDB 解決。Meta Service 只用在事務(wù)內(nèi)實現(xiàn)元數(shù)據(jù)操作語義到 KV 操作的轉(zhuǎn)換,降低了語義實現(xiàn)復(fù)雜度。
存算分離架構(gòu)下,各 MetaData Service 節(jié)點無狀態(tài),Client 請求可打到任意節(jié)點。但 Metadata Service 內(nèi)部有通過 inode id hash,保證同目錄下創(chuàng)建、同一文件更新等請求轉(zhuǎn)發(fā)到固定元數(shù)據(jù)節(jié)點上攢 Batch,以減少事務(wù)沖突,提升吞吐。計算、存儲具備獨立 scale-out 能力。
數(shù)據(jù)模型
Metadata Service 采用 inode 和 dentry 分離的設(shè)計思路,兩種數(shù)據(jù)結(jié)構(gòu)有不同的 schema 定義。具體實現(xiàn)時,采用了“將主鍵編碼成 key,并添加不同前綴”的方式模擬出兩張邏輯表,除主鍵外的其它的字段存放到 value 中。
 圖片
圖片
語義實現(xiàn)
在定義好的 inode、entry 結(jié)構(gòu)之上,如何通過 FoundationDB 的讀寫事務(wù)正確實現(xiàn)各類 POSIX 元數(shù)據(jù)操作,是 Meta Service 中最重要的問題。但 POSIX 元數(shù)據(jù)操作有很多種,窮舉說明會導(dǎo)致文章篇幅過長。本章節(jié)我們從這些操作中抽取了幾種比較有代表性的常見操作來展開說明。
 圖片
圖片
三、結(jié)語
本文帶著讀者深入到了 3FS 系統(tǒng)內(nèi)部去了解其各個組成部分的關(guān)鍵設(shè)計。在這個過程中,我們可以看到 3FS 的很多設(shè)計都經(jīng)過了深思熟慮,不可否認(rèn)這是一個設(shè)計優(yōu)秀的作品。但是,我們也注意到這些設(shè)計和目前文件存儲領(lǐng)域的一些主流做法存在差異。
本文是系列文章的上篇,在下篇文章中我們將進(jìn)一步將 3FS 和業(yè)界的一些知名的文件系統(tǒng)進(jìn)行對比,希望能夠從整個文件存儲領(lǐng)域的角度為讀者分析清楚 3FS 的優(yōu)點和局限性,并總結(jié)出我們從 3FS 得到的啟示,以及我們是如何看待這些啟示的。