加速 MySQL 主從同步,核心架構設計思路!
作者:架構師之路
MySQL并行復制、縮短主從同步時延的核心架構思路無非兩點:單線程回放,升級為多線程并發回放和確保并發回放冪等性。
MySQL主從同步為什么這么慢?
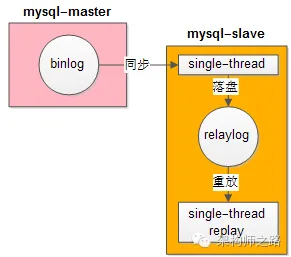
如上所示,主庫binlog同步到從庫,從庫單線程落盤relaylog,單線程重放relaylog,在數據量大并發量大的時候,就會很慢。
如何來進行優化?
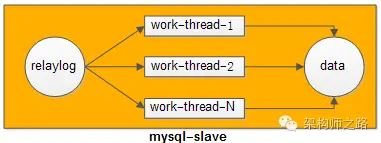
可以多線程并行重放relaylog來縮短同步時間。
多線程并行重放能否保證與主庫數據的一致性?
例如:三個set語句,分在三個線程重放,不能保障與主庫執行序列的一致性。
update X set money=100 where uid=58;
update X set money=150 where uid=58;
update X set money=200 where uid=58;隨機分配肯定不行,但可以按庫來分配:
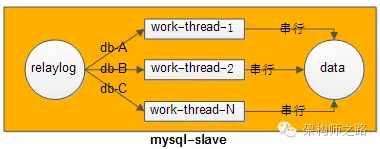
- 同一個MySQL實例中的同一個DB庫,由一個線程來重放;
- 不同的DB庫,由不同的線程來并行重放;
以此來夠縮短同步時間。
為什么很多公司還是同步很慢呢?
這個鍋DBA不背。
大概是架構師在數據庫架構設計時,MySQL使用了單庫多表模式,升級為多庫多表模式即可。
畫外音:單庫多表模式,還是一個線程重放。
數據庫架構,多庫多表模式有什么好處?
- 主從同步快;
- 邏輯上還能按照業務子業務進行庫隔離;
- 擴容方便,性能出現瓶頸時,加實例就能拆庫擴容;
架構師說拆不開怎么辦?
要么是架構師不懂,要么是把業務實現在SQL語句里了,導致拆不開。
如果已經是單庫多表模式,庫無法拆分開,還有其它方法縮短主從同步時間嗎?
可以進一步優化:將主庫上同時并行執行的事務,分為一組,編一個號,這些事務在從庫上的回放也可以并行執行。
畫外音:事務在主庫上的執行同時進入到prepare階段,說明事務之間沒有沖突,否則就不可能提交。
簡言之:同一組提交的事務,沒有鎖沖突,可以并行重放。
MySQL將組提交的信息存放在GTID中,使用mysqlbinlog工具,可以看到組提交內部的內部信息:
14:15 XXX GTID last_committed=0 sequence_numer=1
14:15 XXX GTID last_committed=0 sequence_numer=2
14:15 XXX GTID last_committed=0 sequence_numer=3
14:15 XXX GTID last_committed=0 sequence_numer=4如果具備相同的last_committed,說明它們在一個組內,可以并發回放執行。
總結
mysql并行復制,縮短主從同步時延的核心架構思路無非兩點:
- 單線程回放,升級為多線程并發回放;
- 確保并發回放冪等性:“按照庫冪等”,“按照組冪等”是兩種不同顆粒度的實現方式;
更具體的:
- mysql5.5 -> 不支持并行復制,趕緊升級mysql;
- mysql5.6 -> 支持按照庫并行復制,趕緊升級“多庫”架構;
- mysql5.7 -> 支持按照GTID并行復制;
知其然,知其所以然。
思路比結論更重要。
責任編輯:趙寧寧
來源:
架構師之路