













譯者 | 朱先忠
審校 | 重樓
為什么要定制LLM?
大型語言模型是基于自監督學習預訓練的深度學習模型,需要大量的訓練數據資源、訓練時間并保存大量參數。尤其是在過去2年里,LLM徹底改變了自然語言處理,在理解和生成類似人類的文本方面表現出色。然而,這些通用模型的開箱即用性能可能并不總是能滿足特定的業務需求或領域要求。LLM本身無法回答依賴于專有公司數據或閉卷設置的問題;因此,LLM當前主要應用在一些相對通用的領域。
由于需要大量的訓練數據和資源;所以,從頭開始訓練LLM模型對于中小型團隊來說基本上是不可行的。因此,近年來開發了各種各樣的LLM定制策略,以針對需要專業知識的各種場景調整模型。
定制策略大致可以分為兩種類型:
- 使用凍結模型:這些技術不需要更新模型參數,通常通過情境學習或提示工程來實現。這樣的定制策略具有明顯的成本效益,因為它們可以改變模型的行為而無需大量的訓練成本,因此在行業和學術界都得到了廣泛的探索,每天都會發表新的研究論文。
- 更新模型參數:這是一種相對資源密集型的方法,需要使用為預期目的設計的自定義數據集來調整預訓練的LLM。這包括微調和從人類反饋中進行強化學習(RLHF)等流行技術。這兩種廣泛的定制范式分支出各種專門的技術,包括LoRA微調、思想鏈、檢索增強生成、ReAct和代理框架。每種技術在計算資源、實施復雜性和性能改進方面都有獨特的優勢和權衡。
如何選擇LLM?
定制LLM的第一步是選擇合適的基礎模型作為基準。社區平臺(例如“Huggingface”)提供了由頂級公司或社區貢獻的各種開源預訓練模型,例如Meta的Llama系列和Google的Gemini。Huggingface還提供排行榜,例如“Open LLM Leaderboard”,用于根據行業標準指標和任務(例如MMLU)比較LLM。云提供商(例如AWS)和AI公司(例如OpenAI和Anthropic)也提供對專有模型的訪問權限,這些模型通常是付費服務且訪問權限受限。以下因素是選擇LLM時需要考慮的要點。
- 開源或專有模型:開源模型允許完全定制和自托管,但需要技術專長,而專有模型提供即時訪問,并且通常提供更好的質量響應,但成本更高。
- 任務和指標:模型擅長于不同的任務,包括問答、總結、代碼生成等。比較基準指標并在特定領域的任務上進行測試以確定合適的模型。
- 架構:一般來說,僅使用解碼器的模型(GPT系列)在文本生成方面表現更好,而使用編碼器-解碼器的模型(T5)在翻譯方面表現良好。越來越多的架構涌現并顯示出頗有希望的結果,例如混合專家(MoE)模型“DeepSeek”。
- 參數數量和大小:較大的模型(70B-175B個參數)性能更好,但需要更多的計算能力。較小的模型(7B-13B)運行速度更快且更便宜,但功能可能會有所降低。確定基礎LLM后,讓我們來探索6種最常見的LLM定制策略,按資源消耗從少到多的順序排列依次是:
- 提示工程
- 解碼和采樣策略
- 檢索增強生成
- 代理
- 微調
- 根據人類反饋進行強化學習如果你更喜歡通過視頻了解上述這些概念,請查看我的視頻“簡要解釋6種常見的LLM定制策略”。
LLM定制技巧
1. 提示工程
提示是發送給LLM以引出AI生成的響應的輸入文本,它可以由指令、上下文、輸入數據和輸出指示組成。
- 指令:這提供了模型應如何執行的任務描述或說明。
- 上下文:這是指導模型在一定范圍內做出反應的外部信息。
- 輸入數據:這是你想要響應的輸入。
- 輸出指示器:指定輸出類型或格式。提示工程涉及戰略性地設計這些提示組件以塑造和控制模型的響應。基本提示工程技術包括零次提示、一次提示和少量提示三種類型。用戶可以在與LLM交互時直接實施基本提示工程技術,使其成為一種將模型行為與新目標對齊的有效方法。
由于提示工程的效率和有效性,人們探索和開發了更復雜的方法來推進提示的邏輯結構。 - 思維鏈(CoT):要求LLM將復雜的推理任務分解為逐步的思維過程,以提高解決多步驟問題的能力。每一步都明確地揭示其推理結果,作為其后續步驟的先導背景,直至得出答案。
- 思維樹:從CoT延伸而來,通過考慮多個不同的推理分支和自我評估選擇來決定下一步最佳行動。它對于涉及初步決策、未來戰略和多種解決方案探索的任務更為有效。
- 自動推理和工具使用(ART):建立在CoT流程之上,它解構復雜的任務并允許模型使用預定義的外部工具(如搜索和代碼生成)從任務庫中選擇少量樣本。
- 協同推理和行動(ReAct):將推理軌跡與行動空間相結合,其中模型搜索行動空間并根據環境觀察確定下一個最佳行動。CoT和ReAct等技術通常與Agentic工作流結合使用以增強其功能。這些技術將在下面的“代理”部分更詳細地介紹。
2. 解碼與采樣策略
解碼策略可以在模型推理時通過推理參數(例如溫度、top p、top k)進行控制,從而確定模型響應的隨機性和多樣性。貪婪搜索、波束搜索和采樣是自回歸模型生成的三種常見解碼策略。
在自回歸生成過程中,LLM根據前一個符號所決定的候選符號的概率分布,一次輸出一個符號。默認情況下,會應用貪婪搜索來生成具有最高概率的下一個符號。
相比之下,波束搜索解碼會考慮次優標記的多個假設,并選擇文本序列中所有標記中組合概率最高的假設。下面的代碼片段使用轉換庫在模型生成過程中指定波束路徑的數量(例如,num_beams=5考慮5個不同的假設)。
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_name)
outputs = model.generate(**inputs, num_beams=5)采樣策略是通過調整這些推理參數來控制模型響應隨機性的第三種方法:
- 溫度:降低溫度可增加生成高概率單詞的可能性并降低生成低概率單詞的可能性,從而使概率分布更加清晰。當溫度等于0時,它相當于貪婪搜索(最沒有創造力);當溫度等于1時,它會產生最具創造力的輸出。
- 前K個采樣:此方法篩選出K個最有可能的下一個標記,并在這些標記之間重新分配概率。然后,模型從這組篩選出的標記中進行采樣。
- 前P采樣:前P采樣不是從K個最可能的標記中采樣,而是從累積概率超過閾值p的最小可能標記集中進行選擇。
下面的示例代碼片段從前50個最可能的標記(top_k=50)中抽樣,累積概率高于0.95(top_p=0.95):
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
) 3. RAG
檢索增強生成(RAG)最初在論文《知識密集型NLP任務的檢索增強生成》中提出,已被證明是一種有前途的解決方案,它整合了外部知識,并在處理特定領域或專業查詢時減少了常見的LLM“幻覺”問題。RAG允許從知識領域動態提取相關信息,并且通常不需要大量訓練來更新LLM參數;因此,它是一種經濟高效的策略,可將通用LLM應用于專業領域。
RAG系統可分解為檢索和生成階段。檢索過程的目標是通過對外部知識進行分塊、創建嵌入、索引和相似性搜索,在知識庫中找到與用戶查詢密切相關的內容。
- 分塊:將文檔分成幾個較小的段,每個段包含不同的信息單元。
- 創建嵌入:嵌入模型將每個信息塊壓縮為向量表示。用戶查詢也通過相同的向量化過程轉換為其向量表示,以便可以在同一維空間中比較用戶查詢。
- 索引:此過程將這些文本塊及其向量嵌入存儲為鍵值對,從而實現高效且可擴展的搜索功能。對于超出內存容量的大型外部知識庫,向量數據庫可提供高效的長期存儲。
- 相似性搜索:計算查詢嵌入和文本塊嵌入之間的相似度分數,用于搜索與用戶查詢高度相關的信息。
然后,RAG系統的生成過程將檢索到的信息與用戶查詢相結合,形成增強查詢,該查詢被解析到LLM以生成上下文豐富的響應。
關鍵代碼片斷
在基于RAG系統的關鍵實現代碼中,首先指定LLM和嵌入模型,然后執行將外部知識庫分塊為文檔的集合的步驟。然后,從文檔創建索引,基于索引定義查詢引擎,并使用用戶提示查詢查詢引擎。
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import VectorStoreIndex
Settings.llm = OpenAI(model="gpt-3.5-turbo")
Settings.embed_model="BAAI/bge-small-en-v1.5"
document = Document(text="\\n\\n".join([doc.text for doc in documents]))
index = VectorStoreIndex.from_documents([document])
query_engine = index.as_query_engine()
response = query_engine.query(
"Tell me about LLM customization strategies."
)- 上面的例子展示了一個簡單的RAG系統。高級RAG在此基礎上進行了改進,引入了預檢索和后檢索策略,以減少諸如檢索和生成過程之間協同作用有限等缺陷。例如,重新排序技術使用能夠理解雙向上下文的模型對檢索到的信息進行重新排序,并與知識圖譜集成以實現高級查詢路由。
4. 代理

LLM代理(Agent)是2024年的熱門話題,并且很可能在2025年繼續成為GenAI領域的主要焦點。與RAG相比,Agent擅長創建查詢路線和規劃基于LLM的工作流程,具有以下優勢:
- 維護先前模型生成的響應的記憶和狀態。
- 根據特定標準利用各種工具。此工具使用功能使得代理有別于基本RAG系統,因為它賦予LLM對工具選擇的獨立控制權。
- 將復雜的任務分解為較小的步驟并規劃一系列操作。
- 與其他代理協作以形成協調系統。
多種情境學習技術(例如CoT、ReAct)可通過Agentic框架實現,接下來我們將更詳細地討論ReAct。ReAct代表“語言模型中的協同推理和行動”,由三個關鍵元素組成——行動、想法和觀察。該框架由普林斯頓大學的谷歌研究中心推出,建立在思想鏈的基礎上,將推理步驟與行動空間相結合,從而實現工具使用和函數調用。此外,ReAct框架強調根據環境觀察確定下一個最佳行動。
原始論文中的舉例展示了ReAct的內部工作過程,其中LLM生成第一個想法并通過調用函數“Search [Apple Remote]”來采取行動,然后觀察其第一個輸出的反饋。第二個想法基于之前的觀察,因此導致不同的動作“Search [Front Row]”。這個過程不斷迭代直到達到目標。研究表明,ReAct通過與簡單的維系百科API交互,克服了在思維鏈推理中經常觀察到的幻覺和錯誤傳播問題。此外,通過實施決策跟蹤,ReAct框架還提高了模型的可解釋性、可信度和可診斷性。
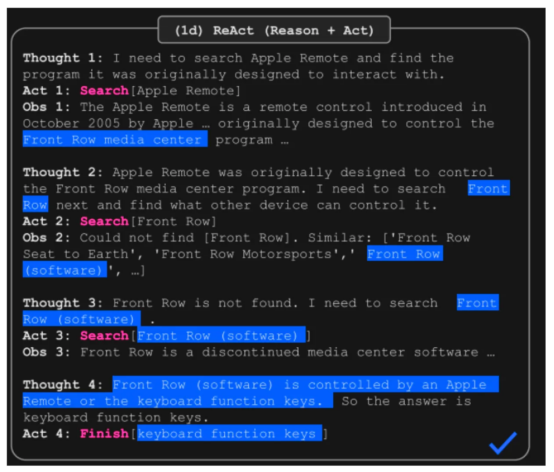
本示例來自論文《ReAct:語言模型中的協同推理和行動》(Yu等人,2022年)
關鍵代碼片段
接下來的代碼將演示使用基于ReAct的代理llamaindex的關鍵代碼片段。首先,它定義了兩個函數(multiply和add)。其次,將這兩個函數封裝為FunctionTool,形成代理的動作空間并根據其推理執行。
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import FunctionTool
# 創建基本函數工具
def multiply(a: float, b: float) -> float:
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
def add(a: float, b: float) -> float:
return a + b
add_tool = FunctionTool.from_defaults(fn=add)
agent = ReActAgent.from_tools([multiply_tool, add_tool], llm=llm, verbose=True)代理工作流與自我反思或自我糾正相結合時,其優勢更為顯著。這是一個日益發展的領域,人們正在探索各種代理架構。例如,Reflexion框架通過提供來自環境的口頭反饋摘要并將反饋存儲在模型的內存中來促進迭代學習;CRITIC框架使凍結的LLM能夠通過與外部工具(如代碼解釋器和API調用)交互來進行自我驗證。
5. 微調
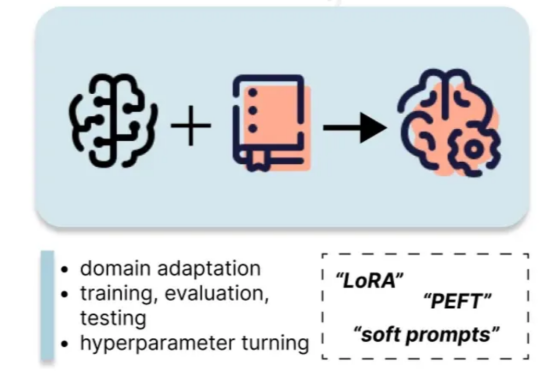
微調是輸入小眾和專業數據集來修改LLM,使其更符合某個目標的過程。它不同于提示工程和RAG,因為它可以更新LLM權重和參數。完全微調是指通過反向傳播更新預訓練LLM的所有權重,這需要大量內存來存儲所有權重和參數,并且可能會顯著降低其他任務的能力(即災難性遺忘)。因此,PEFT(或參數高效微調)被更廣泛地用于緩解這些問題,同時節省模型訓練的時間和成本。PEFT方法有三類:
- 選擇性:選擇初始LLM參數的子集進行微調,與其他PEFT方法相比,這可能需要更多的計算。
- 重新參數化:通過訓練低秩表示的權重來調整模型權重。例如,低秩自適應(LoRA)就屬于此類,它通過使用兩個較小的矩陣表示權重更新來加速微調。
- 附加:向模型添加額外的可訓練層,包括適配器和軟提示等技術。微調過程與深度學習訓練過程類似,需要以下輸入內容:
- 訓練和評估數據集
- 訓練參數定義超參數,例如學習率、優化器
- 預訓練的LLM模型
- 計算算法應該優化的指標和目標函數
關鍵代碼片段
下面是使用轉換器Trainer實現微調的關鍵代碼片段示例。
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir=output_dir,
learning_rate=1e-5,
eval_strategy="epoch"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()微調具有廣泛的使用場景。例如,指令微調通過對提示完成對進行訓練來優化LLM的對話和遵循指令的能力。另一個例子是領域自適應,這是一種無監督微調方法,可幫助LLM專注于特定的知識領域。
6. RLHF
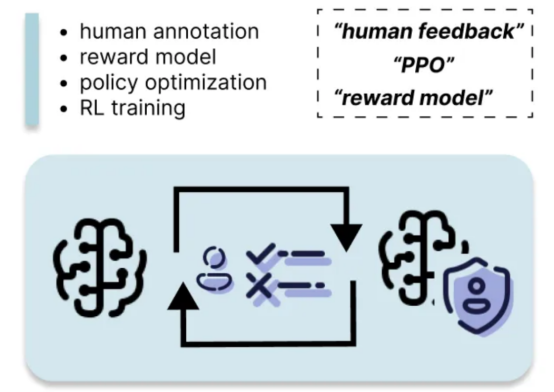
基于人類反饋的強化學習(RLHF)是一種基于人類偏好對LLM進行微調的強化學習技術。RLHF通過基于人類反饋訓練獎勵模型來運行,并使用該模型作為獎勵函數通過PPO(近端策略優化)優化強化學習策略。該過程需要兩組訓練數據:用于訓練獎勵模型的偏好數據集和用于強化學習循環的提示數據集。
讓我們將其分解為如下幾個步驟:
- 收集由人工標注者標注的偏好數據集,人工標注者根據人類偏好對模型生成的不同完成情況進行評分。偏好數據集的一個示例格式為{input_text,candidate1,candidate2,human_preference},表示哪個候選答案是首選。
- 使用偏好數據集訓練獎勵模型,獎勵模型本質上是一個回歸模型,它輸出一個標量,表示模型生成的響應的質量。獎勵模型的目標是最大化獲勝候選人和失敗候選人之間的分數。
- 在強化學習循環中使用獎勵模型來微調LLM。目標是更新策略,以便LLM可以生成響應,從而最大化獎勵模型產生的獎勵。此過程利用提示數據集,該數據集是格式為{prompt,response,rewards}的提示的集合。
關鍵代碼片段
開源庫Trlx在實現RLHF中被廣泛應用,它們提供了一個展示基本RLHF設置的模板代碼:
- 從預訓練檢查點初始化基礎模型和標記器
- 配置PPO超參數PPOConfig,如學習率、時期和批次大小
- PPOTrainer通過組合模型、標記器和訓練數據來創建PPO訓練器
- 訓練循環使用step()方法迭代更新模型,以優化從查詢和模型響應計算出的回報:
# trl: 轉換器強化學習庫
from trl import PPOTrainer, PPOConfig, AutoModelForSeq2SeqLMWithValueHead
from trl import create_reference_model
from trl.core import LengthSampler
#啟動預先訓練好的模型和標記器
model = AutoModelForCausalLMWithValueHead.from_pretrained(config.model_name)
tokenizer = AutoTokenizer.from_pretrained(config.model_name)
#定義PPO算法的超參數
config = PPOConfig(
model_name=model_name,
learning_rate=learning_rate,
ppo_epochs=max_ppo_epochs,
mini_batch_size=mini_batch_size,
batch_size=batch_size
)
# 根據模型啟動PPO訓練師
ppo_trainer = PPOTrainer(
cnotallow=config,
model=ppo_model,
tokenizer=tokenizer,
dataset=dataset["train"],
data_collator=collator
)
# ppo_訓練器通過獎勵進行迭代更新
ppo_trainer.step(query_tensors, response_tensors, rewards)RLHF被廣泛用于將模型響應與人類偏好對齊。常見使用場景包括減少響應毒性和模型幻覺。然而,它的缺點是需要大量人工注釋的數據以及與策略優化相關的計算成本。因此,引入了諸如AI反饋強化學習和直接偏好優化(DPO)之類的替代方案來緩解這些限制。
總結
本文簡單介紹了六種基本的LLM定制策略,包括提示工程、解碼策略、RAG、Agent、微調和RLHF。希望這對你理解每種策略的優缺點以及如何根據實際應用場景實施這些策略有所幫助。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:6 Common LLM Customization Strategies Briefly Explained,作者:Destin Gong


























