













生成與理解相互促進!華科字節提出Liquid,揭示統一多模態模型尺度規律!
近年來大語言模型(LLM)的迅猛發展正推動人工智能邁向多模態融合的新紀元。然而,現有主流多模態大模型(MLLM)依賴復雜的外部視覺模塊(如 CLIP 或擴散模型),導致系統臃腫、擴展受限,成為跨模態智能進化的核心瓶頸。
為此,華中科技大學、字節跳動與香港大學聯合團隊提出了極簡的統一多模態生成框架 ——Liquid。Liquid 摒棄了傳統的外部視覺模塊,轉而采用 VQGAN 作為圖像分詞器,將圖像編碼為離散的視覺 token,使其與文本 token 共享同一詞表空間,使 LLM 無需任何結構修改即可 “原生” 掌握視覺生成與理解能力,徹底擺脫對外部視覺組件的依賴。研究團隊首次揭示了統一表征下的多模態能力遵循 LLM 的尺度定律,且視覺生成與理解任務可雙向互促,這一發現為通用多模態智能的架構設計提供了新的范式。

- 論文標題:Liquid: Language Models are Scalable and Unified Multi-modal Generators
- 論文鏈接:https://arxiv.org/abs/2412.04332
- 主頁鏈接:https://foundationvision.github.io/Liquid/
背景與貢獻
傳統多模態大模型(MLLM)普遍依賴外部視覺模塊(如 CLIP、擴散模型)作為編碼器或解碼器,需通過特征投影層對齊視覺與文本特征,導致架構復雜化。近期一些研究嘗試采用 VQVAE 替代傳統模塊,通過將原始像素映射為離散編碼,實現圖像與文本的統一表征。離散視覺 token 可視為一種新 “語言”,將其擴展至 LLM 的詞表中,使得視覺與文本能夠以相同的 “下一 token 預測” 范式聯合建模,無縫融合多模態信息。盡管早期工作(如 LWM、Chameleon)驗證了該范式的潛力,但其從頭訓練的方式計算成本高昂,而后續工作引入擴散模型(如 Transfusion、Show-o)又導致訓練目標割裂,制約了模型效率與靈活性。
本文提出 Liquid,一種將現有 LLM 直接擴展為統一多模態大模型的框架。Liquid 通過 VQVAE 將圖像編碼為離散視覺 token,使圖像與文本共享同一詞匯空間,無需修改 LLM 結構即可實現視覺理解與生成。研究發現,現有 LLM 因其強大的語義理解與生成能力,是理想的多模態擴展起點。相比從頭訓練的 Chameleon,Liquid 節省 100 倍訓練成本,同時實現更強的多模態能力。團隊進一步探索了從 0.5B 到 32B 六種不同規模 LLM 的擴展性能,覆蓋多種模型家族,并揭示三大核心特性:
a. 尺度規律統一性:視覺生成任務中驗證損失與生成質量遵循與語言任務一致的縮放規律;
b. 規模化解耦效應:多模態訓練下受損的語言能力隨模型規模擴大而逐漸恢復,表明大模型具備多任務無縫處理能力;
c. 跨任務互惠性:視覺理解與生成任務通過共享表征空間實現雙向促進,驗證統一建模的聯合優化優勢。
極簡多模態架構 Liquid
Liquid 采用了將圖像與文本以完全相同的方式對待的一致處理框架。基于 VQVAE 的圖像分詞器將輸入圖像轉換為離散編碼,這些編碼與文本編碼共享相同的詞匯表和嵌入空間。圖像 token 與文本 token 混合后,輸入到 LLM 中,并以 “next token prediction” 的形式進行訓練。

圖像分詞器:對于圖像分詞器采用與 Chameleon 相同的 VQGAN 作為圖像分詞器,將 512×512 的圖像編碼為 1024 個離散 token,嵌入到大小為 8192 的碼本中。這些離散圖像 token 被附加到 BPE 分詞器生成的文本碼本中,擴展了 LLM 的詞表,使其語言空間升級為包含視覺與語言元素的多模態空間。
架構設計:Liquid 基于現有 LLM 構建,本文以 GEMMA-7B 為基礎模型,驗證其在多模態理解、圖像生成及純文本任務中的性能。通過對 LLAMA-3、GEMMA-2 和 Qwen2.5 系列模型(規模從 0.5B 到 32B)的縮放實驗,全面研究了其多模態擴展行為。Liquid 未對 LLM 結構進行任何修改,僅添加了 8192 個可學習的圖像 token 嵌入,保留了原始的 “下一 token 預測” 訓練目標及交叉熵損失。
數據準備:為保留現有 LLM 的語言能力,從公開數據集中采樣了 30M 文本數據(包括 DCLM、SlimPajama 和 Starcoderdata),總計約 600 億文本 token。對于圖文對數據,使用 JourneyDB 和內部圖文數據,構建了 30M 高質量圖像數據,總計 300 億圖像 token。所有數據用于混合多模態預訓練,使模型快速獲得圖像生成能力的同時保留語言能力。此外,其中 20% 的圖文數據用于訓練圖像描述任務,以增強視覺理解能力。
訓練流程:使用總計 60M 數據進行繼續訓練。對于多模態訓練數據,輸入格式定義為:[bos] {text token} [boi] {image token} [eoi][eos] ,其中 [bos] 和 [eos] 為原始文本分詞器的序列開始與結束標記,[boi] 和 [eoi] 為新增的圖像 token 起始與結束標記。在縮放實驗中,針對每個模型規模,分別使用 30M 純文本數據、30M 文本到圖像數據及 60M 混合數據訓練三個獨立版本,并評估其在一系列任務中的性能。
統一多模態模型尺度規律探索
文章探索了規模從 0.5B 到 32B 的 6 種 LLM 在混合模態訓練后的視覺生成性能。隨著模型規模和訓練迭代次數的增加,驗證損失平穩下降,而 token 準確率和 VQA 分數持續上升。在相同的訓練 FLOPs 下,較小模型能夠更快地達到較低的驗證損失和較高的 VQA 分數,但較大模型最終能夠實現更高的評估指標。這可能是因為較小模型能夠快速完成更多訓練步驟,從而更快地適應視覺信息,但其上限較低,難以實現高質量的視覺生成結果。

為了探究視覺生成能力是否影響語言能力,文章比較了在不同規模下,使用 30M 純語言數據訓練和 60M 多模態混合數據訓練的模型在語言任務上的表現。較小模型在混合任務訓練時存在權衡現象:多模態混合訓練后 1B 模型語言任務下降 8.8%,7B 模型下降 1.9%。然而,隨著模型規模的增加,這種權衡逐漸消失,32B 模型實現幾乎零沖突共生(語言能力保留率 99.2%),這表明較大模型具備足夠的能力,能夠同時處理視覺和語言空間的生成任務。

理解與生成相互促進
為探究 Liquid 統一范式中理解與生成任務的交互關系,研究團隊設計了一組消融實驗:以 10M 純文本 + 10M 視覺生成 + 10M 視覺理解數據(總計 30M)作為基線,分別額外增加 10M 生成或理解數據進行對比訓練。實驗發現,增加理解數據可使生成任務性能顯著提升,反之增加生成數據亦能增強理解能力。這一突破性現象表明,當視覺理解與生成共享統一模態空間時,兩者的優化目標具備同源性 —— 均依賴語言與視覺信息的深度對齊與交互,從而形成跨任務協同效應。該發現不僅驗證了多模態任務聯合優化的可行性,更揭示了 LLM 作為通用生成器的本質潛力:單一模態空間下的跨任務互惠可大幅降低訓練成本,推動多模態能力高效進化。

模型性能
視覺生成實驗效果
在 GenAI-Bench 評測中,Liquid 在基礎與高級文本提示下的綜合得分均超越所有自回歸模型,其生成的圖像與文本語義一致性顯著領先。更值得關注的是,Liquid 以遠少于擴散模型的數據量(如 SD v2.1、SD-XL),實現了與之匹敵甚至更優的性能,驗證了基于 LLM 的跨模態學習在語義關聯捕捉與訓練效率上的雙重優勢。
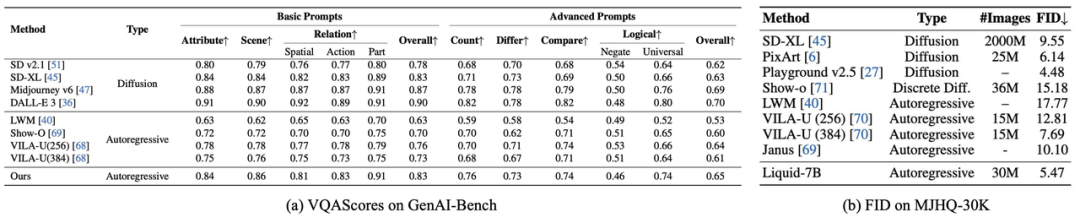
在 MJHQ-30K 評測中,Liquid 以 FID=5.47 刷新自回歸模型上限,不僅大幅領先同類方法,更超越多數知名擴散模型(僅次 Playground v2.5),證明 LLM 在圖像美學質量上可與頂尖生成模型抗衡。
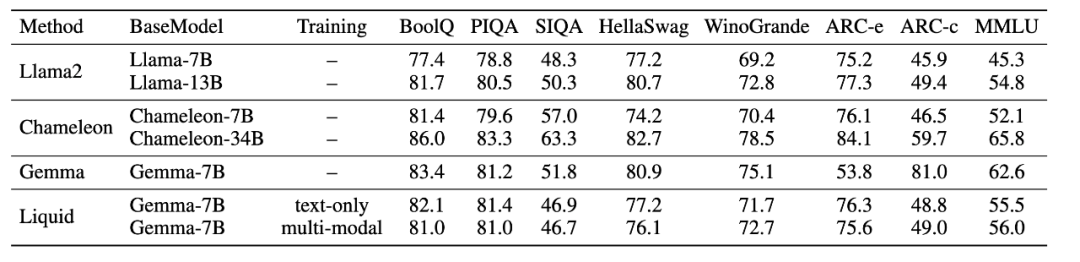
語言能力保留
在一些經典的語言能力評估 benchmark 上,Liquid 在大多數任務中超越了成熟的 LLAMA2 和經過大規模混合預訓練的多模態語言模型 Chameleon,展示了其未退化的語言能力。與 Chameleon 相比,Liquid 基于已具備優秀語言能力的豐富現有 LLM 進行訓練,在擴展視覺生成與理解能力的同時,成功保留了語言能力,證明 Liquid 可以將視覺生成與理解能力擴展到任何結構和規模的 LLM 中。
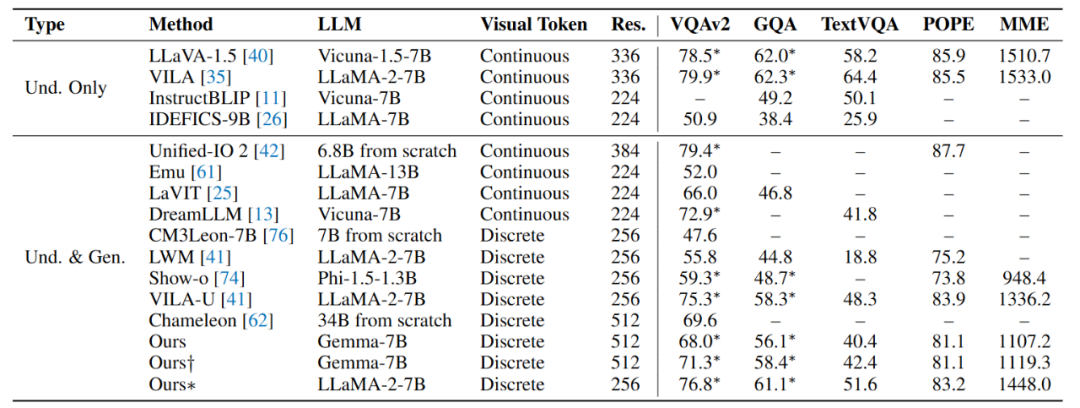
視覺理解能力
在視覺理解任務中,Liquid 性能顯著超越采用標準 VQVAE 的同類模型(如 LWM、Chameleon、Show-o)。盡管其表現仍略遜于依賴連續視覺 token 的主流模型(如 LLaVA),但研究團隊通過引入 Unitok 圖像分詞器(融入圖文特征對齊訓練,* 標結果),使模型理解能力大幅提升,逼近 LLaVA 水平。這驗證了基于離散編碼的多模態大模型具有擺脫 CLIP 編碼器的潛力。
總結
綜上所述,本文提出了 Liquid,一種極簡的統一多模態生成與理解任務框架。與依賴外部視覺模塊的傳統方法相比,Liquid 通過視覺離散編碼直接復用現有大語言模型處理視覺信息,實現了圖像生成與理解的無縫融合。實驗驗證了語言模型在視覺生成任務中可以在保留語言能力的情況下媲美主流擴散模型,并且發現多模態任務的統一帶來的語言和視覺能力的削弱,會隨著模型規模的增加而逐漸消失。此外,原文還揭示了多模態任務間的互惠關系和更多的尺度現象,為大規模預訓練提供了新的思路。






























