DeepSeek會說話了!只要2行代碼,這家公司讓任意大模型秒開口
就在最近,生成式AI行業,誕生了一個新賽道——所有文本模型,可以立刻秒變多模態了!
如今的大模型混戰局勢,情況已經很明顯,去一味卷大模型供應商,投入產出比已經不高。
此時,這個產品的另辟蹊徑,就格外顯得獨樹一幟——他們要做的,是讓任意大模型開口說話,甚至是DeepSeek!
DeepSeek,能說會道
你有沒有想過,DeepSeek如此好用的深度思考+聯網模式,如果能用更具真實感的語音對話,會是什么樣的體驗?
現在,聲網的對話式AI引擎,立刻就能實現你的愿望。

傳送門:https://www.shengwang.cn/ConversationalAI/v2/
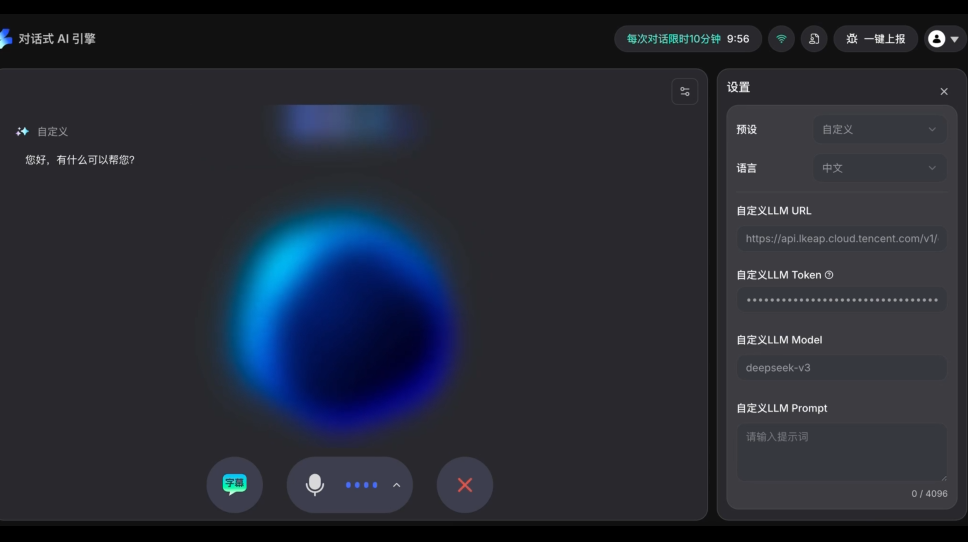
接入DeepSeek V3模型的第一問,那便是自我介紹了——你知道自己很火嗎?
DeepSeek非常謙遜地回答道,「我的火與不火,并不是我關注的重點,我的目標是通過高效準確的信息檢索和友好的交互體驗來幫助用戶」。

這個高情商的回復,著實有兩把刷子。
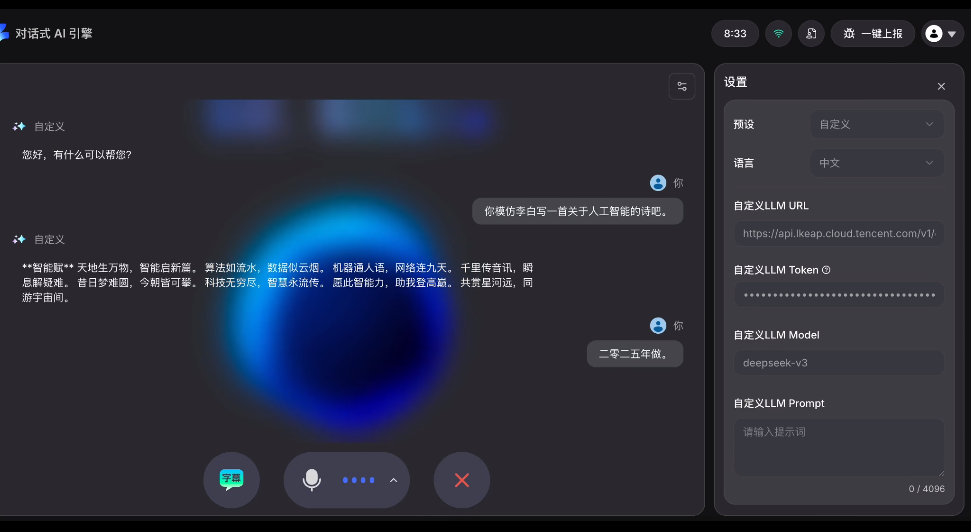
再讓它模仿李白風格寫一首關于人工智能的詩。
《智能賦》
天地生萬物,智能啟新篇。算法如流水,數據似云煙。
機器通人語,網絡連九天。千里傳音訊,瞬息解疑難。
昔日夢難圓,今朝皆可攀。科技無窮盡,智慧永流傳。
愿此智能力,助我登高巔。共賞星河遠,同游宇宙間。
DeepSeek完全復現了詩仙的「五言絕句」的風格。
不僅如此,V3回答的速度飛快,中間也幾乎沒有卡頓。怎么樣,是不是還挺像那么回事的。
讓它預測下,2025年最賺錢行業。
人工智能與機器學習領域,位列首位,其次便是綠色能源與可持續發展了。
接下來,測測DeepSeek能不能做自己的「樹洞」——我有些生氣,你該怎么哄好我?
沒想到,它具備了超強的共情能力,「生氣會讓小仙女掉仙氣哦,別擔心給你講幾個段子吧」。
并且,還主動給出建議,「深呼吸,聽一首最喜歡的歌或者看喜歡的電視劇吧,再給你來一個大大的抱抱。」
不僅如此,中間打斷讓它說幾個有意思的事情,它馬上就會做出調整,說幾個好玩的事兒逗你開心。比如,「公企鵝會用心形石頭向母企鵝求婚,甜蜜爆表!」
怎么樣,還挺好玩兒的吧。
接下來,我們換一個模型,使用對話式AI引擎自帶的“智能助手”效果,感受下它能夠接受被不停打斷的壓力測試嗎?
可以這么說,毫無壓力。
我們連問了三個問題:有的人不喜歡吃香菜,從科學角度上分析原因;如何和不吃香菜的人共處;榴蓮為什么聞著臭,吃著香。
在每次被打斷之際,AI同樣能夠接上話,回答超絲滑。
一波實測下來,長嘴的DeepSeek V3實屬不凡。而這背后,對話式AI引擎功不可沒。
2行代碼,15分鐘,讓任意模型說話
對于開發者來說,調用聲網的對話式AI引擎也非常簡單。
只需2行代碼、15分鐘即可完成接入,大幅降低開發成本,同時保持高度靈活性和可定制性。
不論是DeepSeek,還是豆包、千問、MiniMax,任意文本模型快速轉變為對話式多模態大模型,一下子能說會道了起來。
此外,對話式AI引擎也無需綁定公有云,或是自由云模型,讓用戶有充分的選擇自由。
值得一提的是,為了讓開發者能夠方便地根據自身的喜好或者業務場景選擇不同的組件搭配AI Agent,對話式AI引擎采用了靈活可擴展的架構,兼容市場主流的ASR、LLM和TTS技術,并具備工作流編排能力。

根據聲網對話式AI引擎的官方文檔,搭建一個智能體非常簡便。
從登錄聲網控制臺,創建一個項目,到獲取App ID、開通對話式AI引擎,整個流程高效順暢,無需復雜配置,幾分鐘即可完成。

文檔地址:https://doc.shengwang.cn/doc/convoai/restful/landing-page
在聲網控制臺開通服務,獲取到必要的ID和密鑰后,就可以在應用中加入一個RTC頻道,然后調用聲網的 「創建對話式智能體」接口API創建一個智能體實例,讓其加入同一頻道。
這樣就可以與智能體實時語音互動啦!
最關鍵的是, 在這個智能體中,不論是大語言模型(LLM)還是文本轉語音(TTS)服務,都可以根據你的需求靈活的配置,DeepSeek、千問、豆包、MiniMax,想選哪個選哪個。
停止與智能體實時互動同樣簡單,只需向聲網對話式AI引擎的「停止對話式智能體」接口POST一個請求,調用成功后智能體將離開RTC頻道,互動對話就結束了。
實現與智能體語音互動的流程如下圖所示:

服務器繁忙?不存在的
現在使用DeepSeek,遇到最多的情況就是「服務器繁忙,請稍后再試」。
聲網對話式AI引擎,會不會也出現類似問題?問題不大,因為我們還可以調用阿里云或騰訊云的滿血版DeepSeek。

比ChatGPT還流暢?
如此簡單的搭建方式,對于開發者來說,人均手里一個Her即將成為現實。
最關鍵的是,這個Agent具備五大超能力,比ChatGPT更會聊。

首先,它能做到AI語音秒回。因為語音對話延遲低至650ms,全鏈路的深度優化,讓對話無比流暢自然。
其次,它還能鎖定對話人聲,屏蔽95%的環境人聲、噪聲干擾。
要知道,環境噪音干擾是一個非常常見的問題,一般LLM會在語音對話中誤觸打斷機制,停止了交互。
對此,聲網針對當前LLM語音技術特性,結合多年積累的AI降噪等音頻對話處理能力,可以智能屏蔽背景人聲、環境噪音等。即便是在地鐵、車庫等弱網環境下,人與AI也能流暢對話。
值得一提的是,對話式AI引擎誤打斷較ChatGPT大幅降低50%。
另外,你在和它對話的過程中,會感覺對話節奏仿佛真人一般,可以隨時打斷,響應已經低至340ms。
就算被打斷,對話式AI引擎也能快速接上,這背后是聲網自研的AI VAD技術。
就像人類對話中停頓、語氣、對話節奏等,在聲網真實語音對話中,AI卡殼是幾乎不存在的。
此外,對話式AI引擎即便是在80%丟包情況下,依然能穩定交流。
這是因為聲網全球首創的軟件定義實時網,已在全球200+國家和地區鋪開,確保能夠絲滑實時交互。
還有聲網RTC SDK已經支持30多個平臺開發框架,能夠適配30000+終端,而且中低端機型覆蓋廣泛,不存在無法兼容的問題。
基于這些優勢,未來語言模型不再是冰冷的AI系統,而會成為每個人生活中的「智能伙伴」。
它不僅能執行指令,還能理解情感、預測需求,甚至在某些場景中成為用戶情感價值的寄托。
想象一下,當你感到低落時,虛擬陪伴助手會主動播放舒緩的音樂,模擬真實對話講述故事,緩解你的孤獨。
它還可以成為孩子「口語外教」,糾正發音,營造練習口語氛圍的環境。
它還可以是7x24小時最強打工人——智能客服,代替人工坐席,自動受理客戶咨詢和投訴。
它還可以是.......任何你想要的那個智能AI。
大模型混戰,缺的是「交互基建」
當前大模型領域的競爭,已經進入了白熱化階段。
從DeepSeek R1、到Gemini 2.0 Flah Thinking、o3-mini,再到最新的Grok 3出世,科技巨頭們不斷更迭自家的大模型,試圖在追逐AI智能的賽道中拉開差距。
這一領域看似熱鬧,但他們忽視了一個關鍵事實:
LLM的能力再強,如果無法建立起與人類之間的交互橋梁,終究難以真正落地應用。
當前市場格局下,頭部廠商專注于卷參數規模,中小玩家則聚焦于垂類賽道。
而且,LLM大多還停留在「文本生成」單一維度,他們均普遍缺乏實時語音交互的能力。
這種局限不僅僅影響用戶體驗,更是制約了AI在多個場景中的滲透。
實際上,99%的企業真正的需求并不是自研大模型,而是一個能聽、會說的AI。
這些痛點本質,便在于行業過度關注模型「智能」維度,而忽視了「交互」這個關鍵基建。
正如移動互聯網時代,智能手機的普及不僅僅依賴于處理器性能,還需要觸控屏、傳感器等交互技術的突破。
從技術趨勢演進來看,大模型都在朝著多模態方向遞進,與之同時,多模態大模型也將經歷從「生成」到「交互」的必然演進。
早期以GPT-3為代表的語言模型,專注于文本的生成。隨后,以GPT-4o為代表的多模態大模型,具備了理解、生成圖像的能力。
下一個關鍵演進方向,就是實時交互能力的普及。
要知道,只有專業交互能力的供應商,能以遠超自研的效率解決LLM「失語癥」的痛點。
產業鏈重構:多模態交互層崛起
傳統AI產業鏈相對簡單:模型供應商提供基礎模型能力,算力供應商負責部署,應用開發商構建最終落地產品。
這種模式下,存在著明顯的斷層,即模型與應用之間的缺少必要的交互層。
聲網的創新在于,在模型與應用之間插入一個「多模態交互層」,使得任何文本模型都能迅獲得過實時語音對話的多模態能力。
這不僅僅是簡單的模型部署,更是能力的質變與升級。
這一創新意味著什么?
對于企業來說,無需再為獲得多模態能力,而被迫選擇特定的頭部模型;對于開發者而言,同樣可以靈活選擇最適合業務場景的基礎模型,還能獲得頂級交互的體驗。
聲網技術解決方案,恰好順應了多模態模型演進的趨勢,即為任何模型提供實時語音交互能力。
原本只會「吐字」的大模型轉變為「能說會道」的小助手,這不是簡單語音合成,而是真正實時雙向溝通。
上面案例中不難看出,在隨時打斷、噪聲過濾、弱網適應等方面,「對話式AI引擎」全部精準拿捏。

GPT-4o發布會上,為了保證演示暢通性,手機還插上了網線
在去年十月RTE2024第十屆實時互聯網大會上,聲網首席科學家鐘聲現場演示了一個由STT、LLM、TTS 、RTC四個模塊組成的端邊結合實時對話AI智能體,這也是全球首次有廠商在比日常實際場景更具挑戰的環境下展示實時AI 對話能力。
現場觀眾規模超過千人,面臨復雜的噪聲、回聲、麥克風延遲等困難,但智能體與鐘聲的互動仍然表現出了優秀的對話能力。
在普通5G網絡環境下,實現了流暢、自然、有趣的雙向實時對話,對話模型的極快響應速度、及時打斷與被打斷的自然程度、對抗噪聲能力、遵循語音指令做等待能力都非常突出。

RTC市場份額第一
在這個交互基建賽道中,作為實時互動(RTE)領域的領軍企業,聲網積累了深厚的技術底蘊。
IDC數據顯示,其在RTC市場份額位居中國市場第一。
他們創造了全球首個、迄今為止規模最大的實時音視頻網絡——軟件定義實時網SD-RTN?。
它具備了毫秒級響應、超低延遲,和極致抗弱網的能力,能夠確保高質量的實時交互體驗。

不僅如此,憑借深厚技術積累和全球化服務能力,聲網還贏得了國內外頭部大模型廠商的高度認可。
在海外,其兄弟公司Agora已成為OpenAI官方合作伙伴,共同推動在實時API的落地應用。

在國內,MiniMax、通義千問等頂尖大模型公司也與聲網建立了緊密合作關系。
這些合作不僅彰顯了聲網在實時語音技術上領先地位,也進一步鞏固了其在全球市場的領導地位。
成立十年來,幾乎每一個行業風口都有其身影。有人說,它是科技淘金時代的「賣水者」。
從陌陌、斗魚、虎牙到Bilibli,這些直播行業的巨頭都曾選擇聲網作為技術合作伙伴。它提供的技術不僅保障直播流暢性和穩定性,更在用戶體驗上梳理了行業標桿。
在新東方、好未來、VIPKID等教育巨頭背后,聲網也提供了強大得技術支持。
無論是大規模在線課堂,還是一對一個性化教學,它都能確保師生之間實時互動,提升教學效果。
此外,在全球化布局方面,聲網也取得了重要的成果,全球超60%泛娛樂APP都是其客戶。這些基礎也為聲網積累了豐富的客戶服務經驗。
眼光放長遠來看,聲網的創新將為整個行業帶去更深遠的影響和價值。
通過提供標準化的交互能力,它能解決中小廠商被頭部玩家「功能碾壓」的焦慮。
即便是資源有限的創業團隊,也能通過接入專業交互層,提供與科技巨頭相媲美的用戶體驗。
不僅如此,由于降低多模態交互技術門檻,更多開發者能夠專注于場景創新、業務模式探索,而不必陷入底層交互技術的泥潭。
此外,AI在多場景落地也會得到加速。AI智能助手、情感陪伴、AI口語陪練等應用場景,因獲得高質量交互能力的支持,可以更快速地規模化部署。
這種價值創造,正是AI普惠化的關鍵所在。
隨著交互基建的鋪開,我們將看到更多AI應用從實驗室走向生活,從冰冷的文本界面,演進為溫暖自然的對話伙伴。
在AI競爭下半場,語音交互也將成為一決勝負的關鍵砝碼。