













視頻版IC-Light來了!Light-A-Video提出漸進式光照融合,免訓練一鍵視頻重打光
本文作者來自于上海交通大學,中國科學技術大學以及上海人工智能實驗室等。其中第一作者周彧杰為上海交通大學二年級博士生,師從牛力副教授。

數字化時代,視頻內容的創作與編輯需求日益增長。從電影制作到社交媒體,高質量的視頻編輯技術成為了行業的核心競爭力之一。然而,視頻重打光(video relighting)—— 即對視頻中的光照條件進行調整和優化,一直是這一領域的技術瓶頸。傳統的視頻重打光方法面臨著高昂的訓練成本和數據稀缺的雙重挑戰,導致其難以廣泛應用。
如今,這一難題終于迎來了突破 —— 由上海交通大學以及上海人工智能實驗室聯合研發的 Light-A-Video 技術,為視頻重打光帶來了全新的解決方案。

- 論文地址:https://arxiv.org/abs/2502.08590
- 項目主頁:https://bujiazi.github.io/light-a-video.github.io/
- 代碼地址:https://github.com/bcmi/Light-A-Video
無需訓練,零樣本實現視頻重打光
Light-A-Video 是一種無需訓練的視頻重打光方法,能夠在沒有任何訓練或優化的情況下,生成高質量、時序一致的重打光視頻。這一技術的核心在于充分利用預訓練的圖像重打光模型(如 IC-Light)和視頻擴散模型(如 AnimateDiff 和 CogVideoX),通過創新的 Consistent Light Attention(CLA)模塊和 Progressive Light Fusion(PLF)策略,針對視頻內容的光照變化進行了一致性的優化,實現了對視頻序列的零樣本(zero-shot)光照控制。
其優勢在于:
1. 無需訓練,高效實現視頻重打光:Light-A-Video 是首個無需訓練的視頻重打光模型,能夠直接利用預訓練的圖像重打光模型(如 IC-Light)的能力,生成高質量且時間連貫的重打光視頻。這種方法避免了傳統視頻重打光方法中高昂的訓練成本和數據稀缺的問題,顯著提高了視頻重打光的效率和擴展性。
2. 創新的端到端流程,確保光照穩定性與時序一致性:CLA 模塊通過增強跨幀交互,穩定背景光源的生成,減少因光照不一致導致的閃爍問題。PLF 通過漸進式光照融合策略,逐步注入光照信息,確保生成視頻外觀的時間連貫性。
3. 廣泛的適用性與靈活性:Light-A-Video 不僅支持對完整輸入視頻的重打光,還可以對輸入的前景序列進行重打光,并生成與文字描述相符的背景。而且不依賴于特定的視頻擴散模型,因此與多種流行的視頻生成框架(如 AnimateDiff、CogVideoX 和 LTX-Video)具有高度的兼容性。
CLA + PLF
確保光照一致性與穩定性
Light-A-Video 核心技術包括兩個關鍵模塊:Consistent Light Attention 和 Progressive Light Fusion。CLA 模塊通過增強自注意力層中的跨幀交互,穩定背景光照源的生成。它引入了一種雙重注意力融合策略,一方面保留原始幀的高頻細節,另一方面通過時間維度的平均處理,減少光照源的高頻抖動,從而實現穩定的光照效果。實驗表明,CLA 模塊顯著提高了視頻重打光的穩定性,減少了因光照不一致導致的閃爍問題。
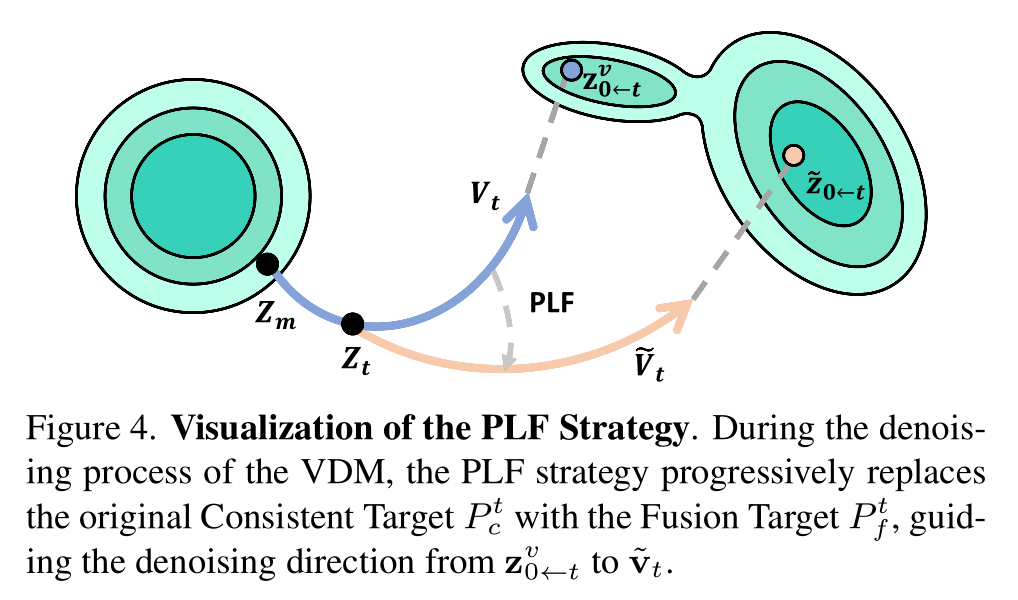
PLF 策略則進一步提升了視頻外觀的穩定性。它基于光傳輸理論的光照線性融合特性,通過逐步混合的方式,將重打光外觀與原始視頻外觀進行融合。在視頻擴散模型的去噪過程中,PLF 策略逐步引導視頻向目標光照方向過渡,確保了時間連貫性。這種漸進式的光照融合方法不僅保留了原始視頻的細節,還實現了平滑的光照過渡。
Light-A-Video 整體架構設計
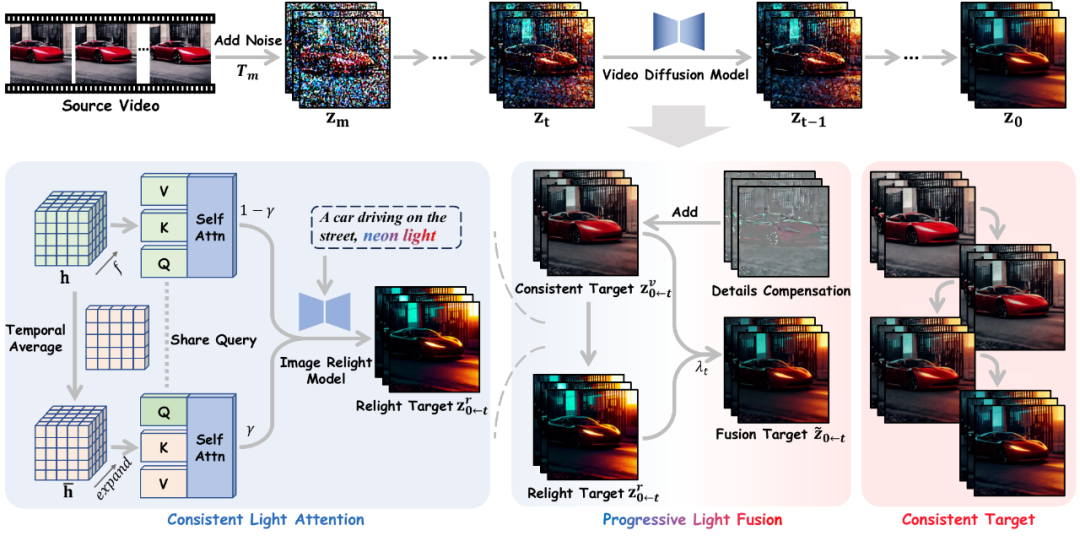
1. 利用視頻擴散模型的時序先驗,將原始視頻加噪到對應的步數后進行去噪。在每一步的去噪過程中,提取其預測的原始去噪目標 并添加上對應的視頻細節補償項作為當前步的一致性目標
并添加上對應的視頻細節補償項作為當前步的一致性目標 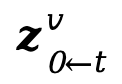
2. 將 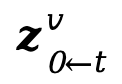 輸入圖片重打光模型(IC-Light),并利用 CLA 的雙流注意力模塊進行逐幀重打光,實現穩定的背景光源生成,作為當前步的重打光的目標
輸入圖片重打光模型(IC-Light),并利用 CLA 的雙流注意力模塊進行逐幀重打光,實現穩定的背景光源生成,作為當前步的重打光的目標 。
。
3. 在預測下一步的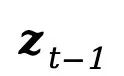 時,先利用 VAE 編解碼器將
時,先利用 VAE 編解碼器將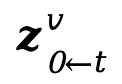 和
和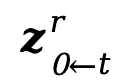 從潛層編碼空間解碼到視頻像素層面。然后通過引入一個漸進式隨時間步下降的參數
從潛層編碼空間解碼到視頻像素層面。然后通過引入一個漸進式隨時間步下降的參數 將兩個目標進行線性外觀混合后,重新編碼到潛層編碼空間獲取混合目標
將兩個目標進行線性外觀混合后,重新編碼到潛層編碼空間獲取混合目標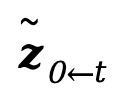 。即 PLF 策略利用混合目標
。即 PLF 策略利用混合目標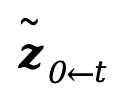 引導生成單步的重打光結果
引導生成單步的重打光結果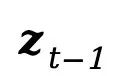 。
。
當視頻完全去噪后,Light-A-Video 能夠獲得時序穩定且光照一致的重打光視頻。
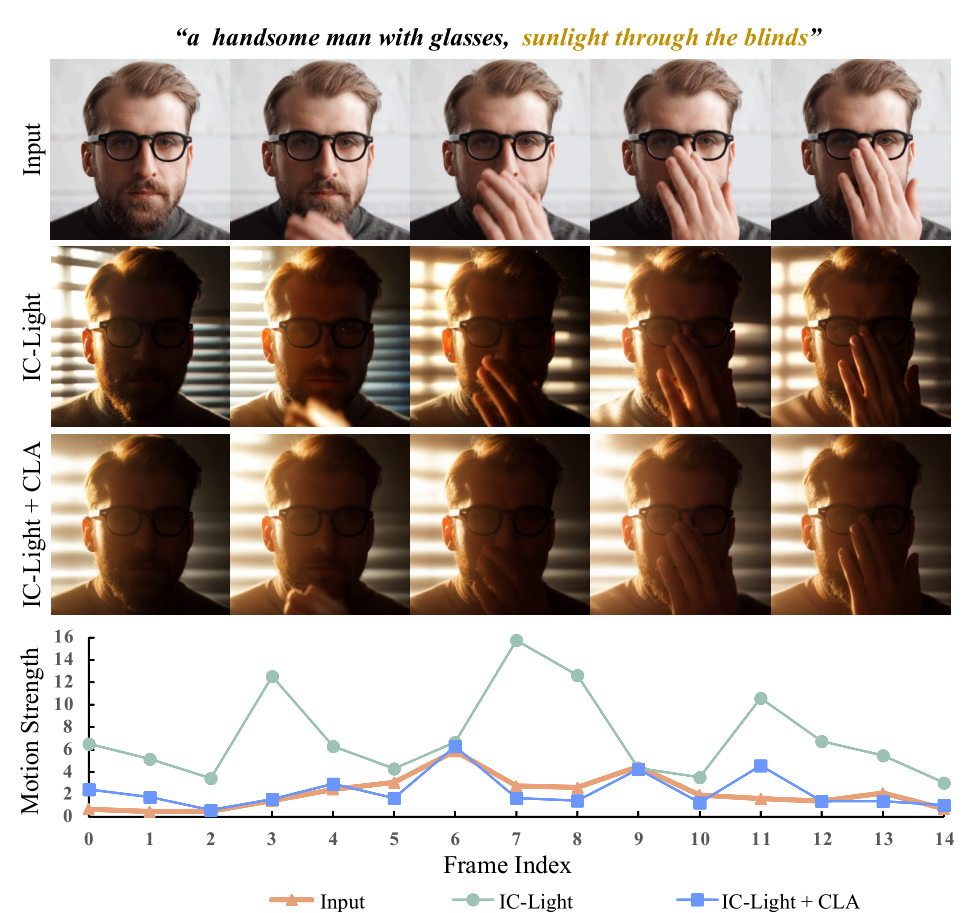
高質量、時間連貫的重光照效果
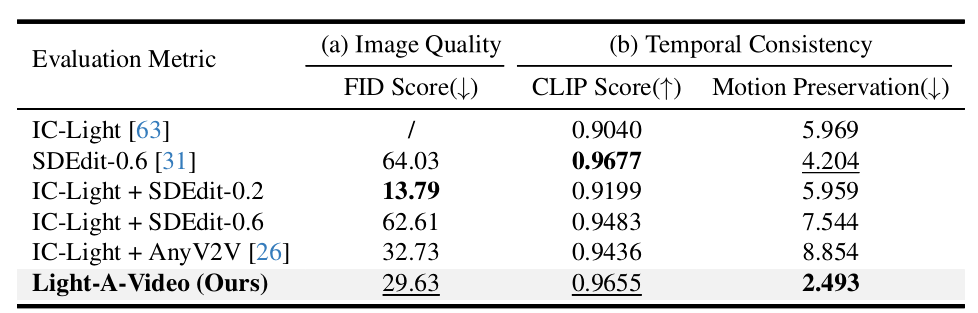
為了驗證 Light-A-Video 的有效性,研究團隊基于 DAVIS 和 Pixabay 公開數據集上構建了其測試數據集。實驗結果表明,Light-A-Video 在多個評估指標上均優于現有的基準方法,尤其在動作保留方面,該方法在保證原視頻外觀內容的基礎上實現了高質量的重打光效果。

另外,Light-A-Video 能夠在僅提供前景序列的情況下,實現背景生成和重打光的并行處理。
未來展望:動態光照與更廣泛應用
之后,Light-A-Video 將致力于有效地處理動態光照條件,進一步提升視頻重打光的靈活性與適應性。這一創新技術的出現,已然為視頻編輯領域注入了全新思路。隨著技術的持續發展與優化,我們有理由相信,Light-A-Video 必將在更廣泛的領域大放異彩,為視頻內容創作開辟更多可能性。





















