













ICLR 2025 Spotlight | 讓城市「動」起來!DynamicCity突破4D大場景生成技術邊界
過去一年,3D 生成技術迎來爆發式增長。在大場景生成領域,涌現出一批 “靜態大場景生成” 工作,如 SemCity [1]、PDD [2]、XCube [3] 等。這些研究推動了 AI 利用擴散模型的強大學習能力來解構和創造物理世界的趨勢。
盡管這些方法在生成復雜且稀疏的三維環境方面表現出色,現有技術仍面臨一個核心挑戰:在生成大型 3D 場景時,它們將環境視為靜止的 “快照”—— 道路凝固、行人懸停、車輛靜止不動。這種靜態生成方式缺乏真實世界瞬息萬變的交通流,難以反映復雜多變的交通場景,限制了實際應用。
那么,如何讓生成的 3D 場景突破靜態單幀的限制,真正捕捉動態世界的時空演化規律?
對此,上海人工智能實驗室、卡耐基梅隆大學、新加坡國立大學和新加坡南洋理工大學團隊提出DynamicCity,給出了突破性的解答。這項創新性工作以4D 到 2D 的特征降維為核心突破點,首次實現了高質量、高效的 4D 場景建模,并在生成質量、訓練速度和內存消耗三大關鍵維度上取得跨越式進展。

DynamicCity已被 ICLR 2025 接收為Spotlight論文,項目主頁和代碼均已公開。

- 論文:https://arxiv.org/abs/2410.18084
- 主頁:https://dynamic-city.github.io
- 代碼:https://github.com/3DTopia/DynamicCity
引言
3D 大型場景生成技術旨在利用深度學習模型,如擴散模型,構建高保真、可擴展的場景。該技術有望為智能系統的訓練與驗證提供近乎無限的虛擬試驗場。然而,現有方法大多還在探索靜態場景的單幀生成(如 XCube [1]、PDD [2]、SemCity [3] 等),難以捕捉真實駕駛環境中交通流、行人運動等動態要素的時空演化規律。這種靜態與動態的割裂,嚴重制約了生成場景在復雜任務中的應用價值。
主流的靜態場景生成方法 [1, 2, 3] 主要依賴體素超分或 TriPlane 壓縮,以實現大規模靜態場景的高效生成,其本質仍是對單幀 3D 場景的 “快照式” 建模。盡管近期研究嘗試將生成范圍擴展至動態(如 OccSora [4], DOME [5]),4D 場景的復雜性 —— 包含數十個移動物體、百米級空間跨度及時序關聯 —— 仍導致生成質量與效率的嚴重失衡。例如 OccSora 無法在大壓縮率的情況保證較好的重建效果,以及擴散模型生成的結果也較為粗糙。
針對這一難題,上海人工智能實驗室等提出DynamicCity—— 面向 4D 場景的生成框架。核心思想是,通過在潛空間顯式建模場景的空間布局與動態變化,并借助擴散模型,直接生成高質量的動態場景。具體而言,DynamicCity 采用以下兩步方法:1) 通過變分自編碼器(Variational Autoencoder, VAE)將復雜的 4D 場景壓縮為緊湊的 2D HexPlane [5][6] 特征表示,避免高維潛空間過于復雜導致生成模型難以學習;2) 采用 Padded Rollout Operation (PRO) 使潛空間捕捉到更多時空結構,幫助擴散模型(Diffusion Transformer, DiT [7])更好生成場景的空間結構與動態演化。
DynamicCity 的主要貢獻如下:
1. 時空特征壓縮:提出基于 Transformer 的投影模塊(Projection Module),將 4D 點云序列壓縮為六個 2D 特征平面(HexPlane),相較于傳統平均池化方法,mIoU 提升 12.56%。結合 Expansion and Squeeze Strategy (ESS),在提升 7.05% 重建精度的同時,將內存消耗降低 70.84%。
2. 特征重組:提出 Padded Rollout 操作,將 HexPlane 特征重組為適配 DiT 框架的特征圖,最大程度保留 HexPlane 結構化信息,幫助生成 DiT 更好的學習潛空間。
3. 可控生成:支持軌跡引導生成、指令驅動生成、4D 場景修改、布局條件生成等功能,并可輕松擴展至更多應用,實現更可控的生成。
DynamicCity:基于 HexPlane 的動態場景擴散模型
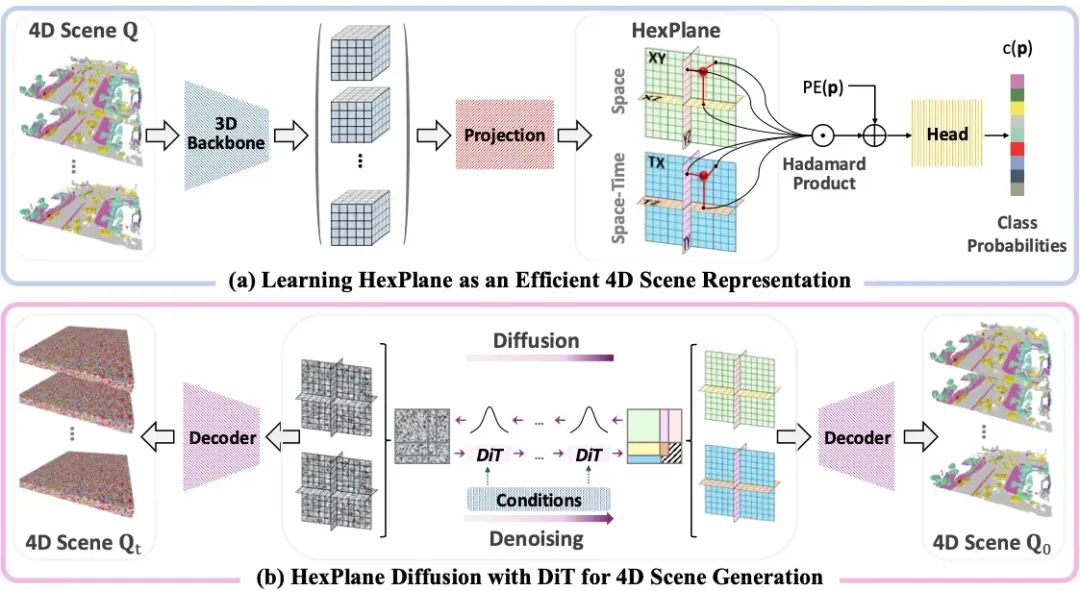
DynamicCity 采用HexPlane 表征和DiT構建了一個高效的4D 場景生成框架 。核心思想通過特征降維的方式,將 4D 場景映射到緊湊的 2D HexPlane,并在此基礎上訓練 DiT 進行場景生成。如圖所示,DynamicCity 主要由以下兩個核心模塊構成:
1. 基于 HexPlane 表征的 VAE:利用投影模塊 (HexPlane Projection Module),將 4D 場景壓縮到六個互相正交的2D 特征平面,并通過 Expansion & Squeeze Strategy (ESS) 進行解碼,以高效恢復原始時空信息。
2. 在重組 HexPlane 上訓練的擴散模型:基于Padded Rollout Operation (PRO),對 HexPlane 進行結構化展開,并在此潛空間訓練DiT進行采樣,以生成新的 4D 動態場景。
DynamicCity 通過這兩個核心模塊,解決了現有 4D 生成模型重建效果和生成結果差的問題,提供了更緊湊的表征、更高效的訓練、更高質量的動態場景合成。
基于 HexPlane 表征的 VAE
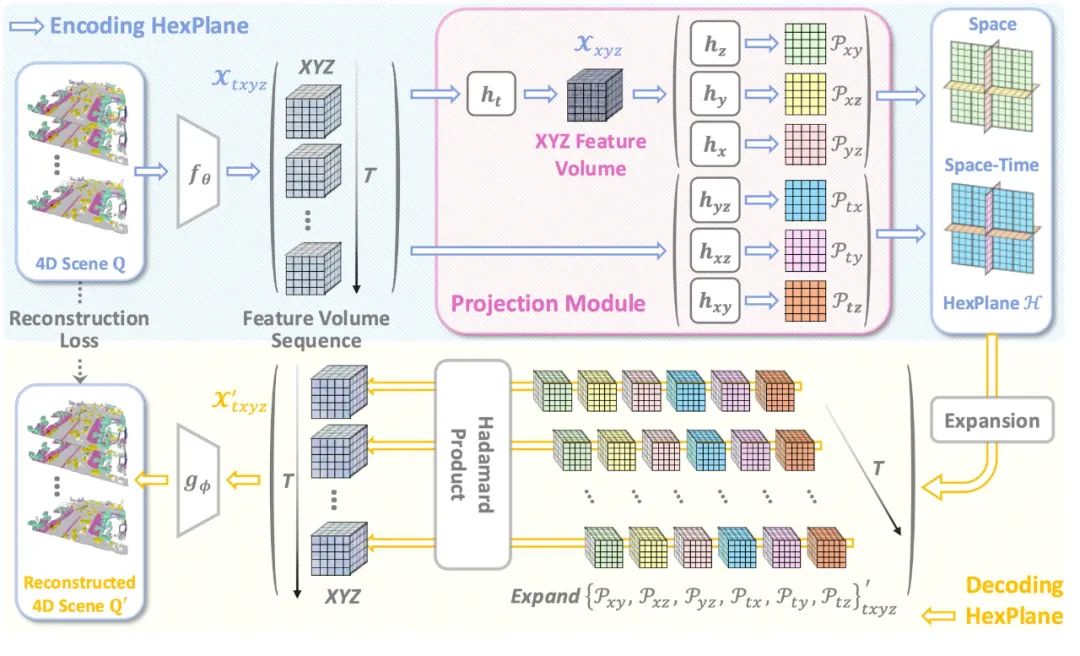
DynamicCity 使用 VAE 將 4D 點云轉換為緊湊的 HexPlane 表征。一個 4D 場景被表示為時空體素數據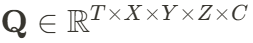 ,其中
,其中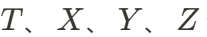 分別表示時間、空間維度,而
分別表示時間、空間維度,而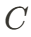 代表特征通道數。VAE 將 4D 數據進行降維成 HexPlane:
代表特征通道數。VAE 將 4D 數據進行降維成 HexPlane:
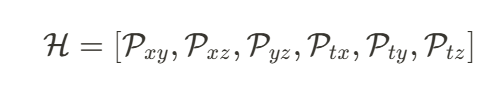
其中,下標表示每個平面保留的維度。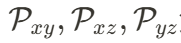 負責建模空間維度信息,
負責建模空間維度信息,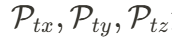 負責建模時空關聯。這一映射成功將 4D 表達壓縮至 2D 空間,使得后續的生成任務更高效。
負責建模時空關聯。這一映射成功將 4D 表達壓縮至 2D 空間,使得后續的生成任務更高效。
投影模塊(Projection Module)
為了高效獲取 HexPlane,作者設計了投影模塊 (Projection Module),用于將高維特征映射至 HexPlane。在通過共享 3D 卷積特征提取器提取初步的時空 4D 特征后,作者使用多個投影網絡 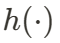 ,將 4D 特征投影到 2D 平面,每一個投影網絡會壓縮一個或兩個維度。
,將 4D 特征投影到 2D 平面,每一個投影網絡會壓縮一個或兩個維度。
投影模塊由 7 個小型的投影網絡組成,其中 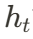 首先進行時間維度壓縮,而后三個小型網絡分別提取空間特征平面
首先進行時間維度壓縮,而后三個小型網絡分別提取空間特征平面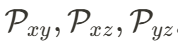 。而時空特征平面
。而時空特征平面 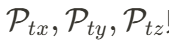 則是通過三個小型網絡直接從 4D 特征中提取得到。
則是通過三個小型網絡直接從 4D 特征中提取得到。
Expansion & Squeeze Strategy (ESS) 解碼
在動態 NeRF 等領域中,HexPlane 常用一個多層感知機(MLP)進行逐點解碼。然而在 4D 場景中,點的數量非常多,導致模型速度慢,顯存占用大。DynamicCity 提出 ESS 解碼策略,用卷積神經網絡代 MLP,減少顯存占用,加速訓練,同時顯著提升重建效果。
首先,對每個 2D 特征平面進行擴展和重復,使其匹配 4D 體素特征;然后,利用 Hadamard 乘積進行信息融合:

最終,通過卷積解碼器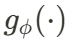 生成完整 4D 語義場景。
生成完整 4D 語義場景。
在重組 HexPlane 上訓練的擴散模型
在 VAE 編碼器學習到 4D 場景的 HexPlane 表征之后,DynamicCity 使用 DiT在學習 HexPlane 空間的分布,并生成時空一致的動態場景。
HexPlane 的六個特征平面共享部分空間維度或時間維度。作者希望能夠用一種簡單有效的方式,在訓練擴散模型時,六個平面并非互相獨立,而是共享部分時空信息。Padded Rollout Operation (PRO)將六個特征平面排列成單個統一的 2D 矩陣,并在未對齊的區域填充零值,以最大程度地保留 HexPlane 的結構化信息 。
具體而言,PRO 將六個 2D 特征平面轉換為一個方形特征矩陣,通過將空間維度和時間維度盡可能的對齊,PRO 能夠最小化填充區域的大小,并確保空間與時間維度之間的信息一致性。
隨后,Patch Embedding將該 2D 特征矩陣劃分為小塊,并將其轉換為 token 序列。在訓練過程中,作者為所有 token 添加位置嵌入,并將填充區域對應的 token排除在擴散過程之外,從而保證生成過程中時空信息的完整性。
可控生成與應用
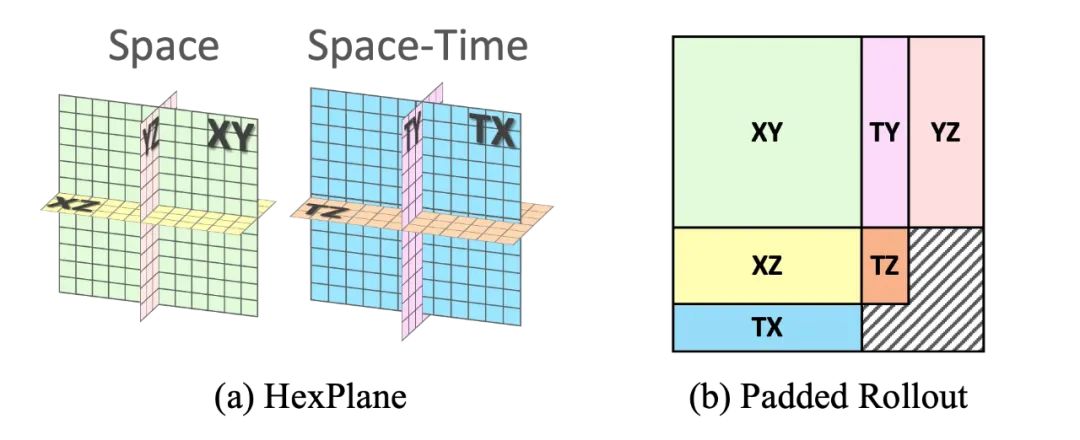
為了讓 HexPlane 生成過程具備可控性,作者引入 Classifier-Free Guidance (CFG)[8]機制,以支持不同條件約束下的場景生成。
對于任意輸入條件,作者采用AdaLN-Zero技術來調整 DiT 模型內部的歸一化參數,從而引導模型生成符合特定約束的場景。此外,對于圖像條件 (Image-based Condition),作者額外添加跨模態注意力模塊 (Cross-Attention Block),以增強 HexPlane 與外部視覺信息的交互能力。
通過 CFG 和 HexPlane Manipulation,DynamicCity 支持以下的應用,且可以輕松拓展到其他的條件:
1. HexPlane 續生成 (Long-term Prediction):通過自回歸方式擴展 HexPlane,實現 4D 場景未來預測,長序列 4D 場景生成等任務。
2. 布局控制 (Layout-conditioned Generation):根據鳥瞰 (BEV) 視角語義圖,生成符合交通布局的動態場景。
3. 車輛軌跡控制 (Trajectory-conditioned Generation):通過輸入目標軌跡,引導場景中車輛的運動。
4. 自車運動控制 (Ego-motion Conditioned Generation):允許用戶輸入特定指令,引導自車在合成場景中的運動路徑。
5. 4D 場景修改 (4D Scene Inpainting):通過掩膜 HexPlane 中的局部區域,并利用 DiT 進行局部補全,實現 4D 動態場景的高質量修復。
結果
下面展示了一些 DynamicCity 的結果,包括無條件生成的結果,布局控制生成結果等。
無條件生成(左:OccSora [4]; 右:DynamicCity)
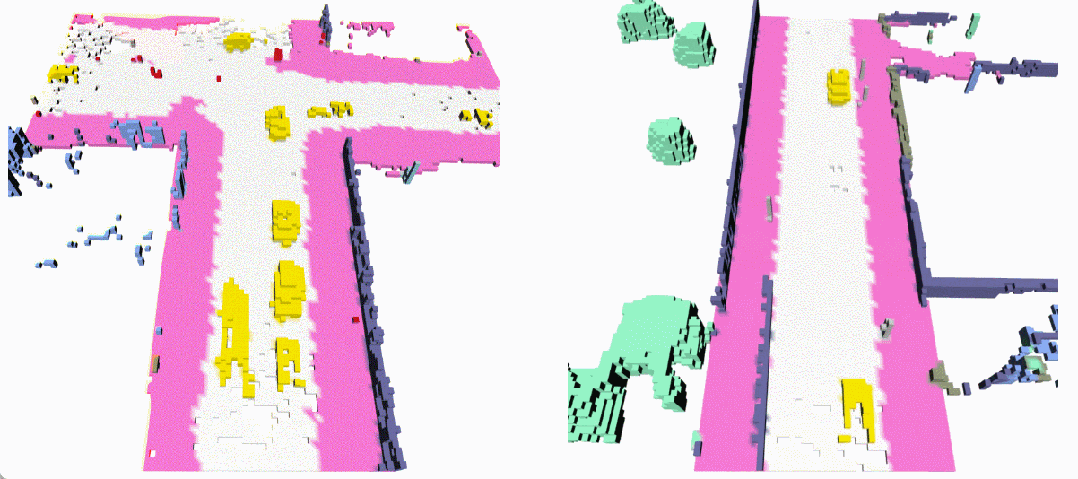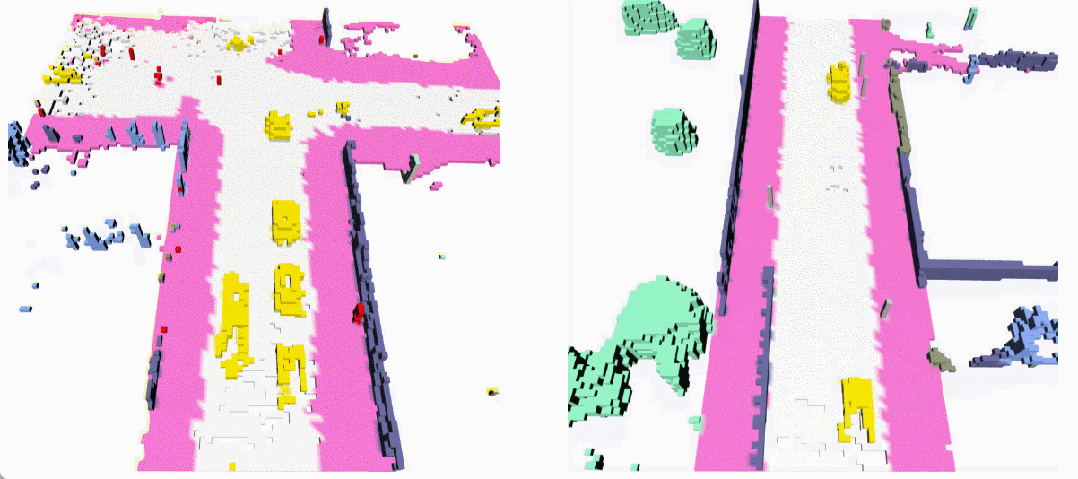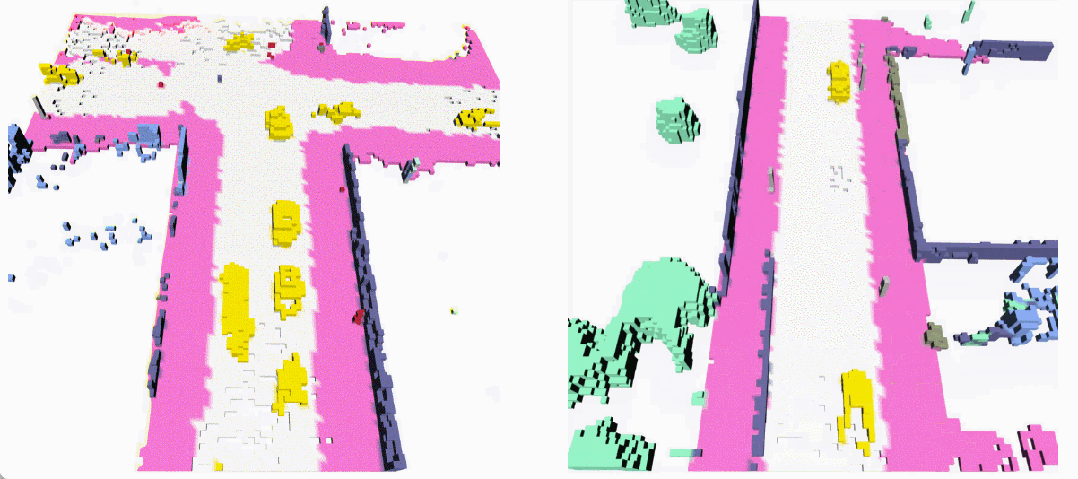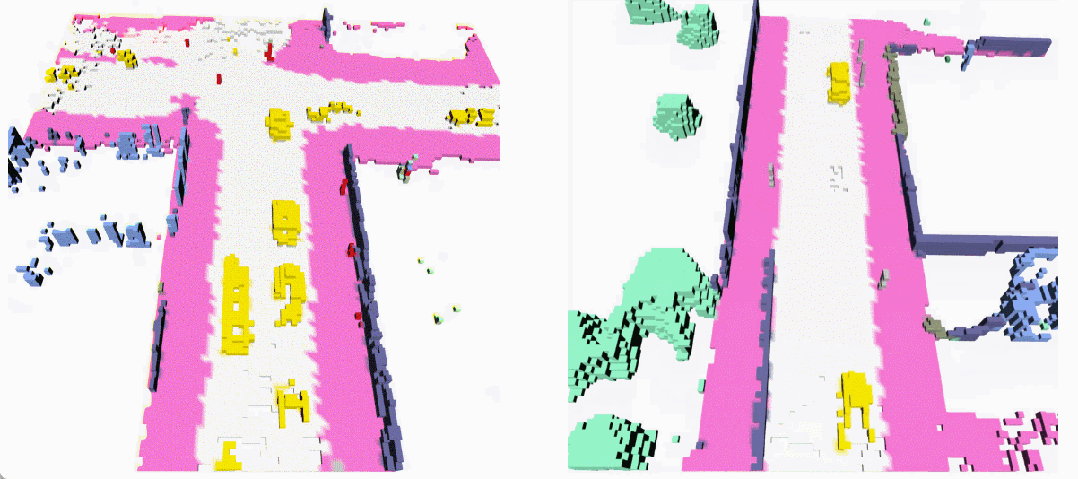

長序列生成

布局控制生成

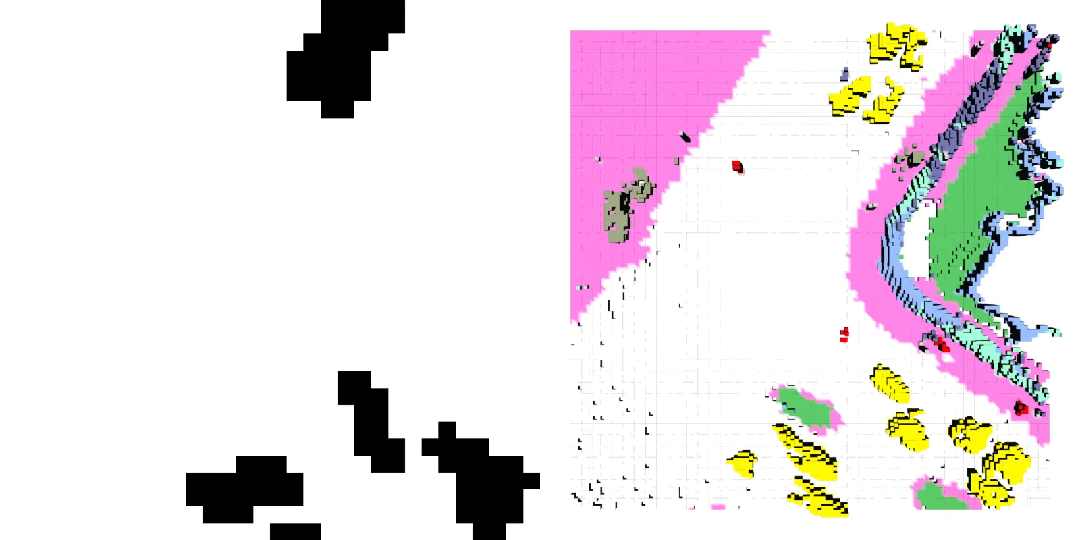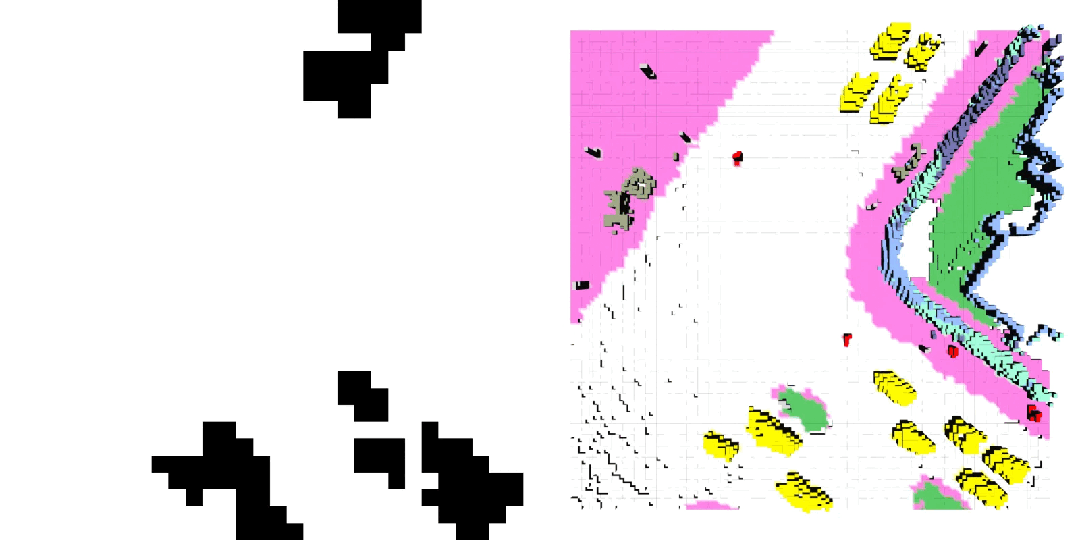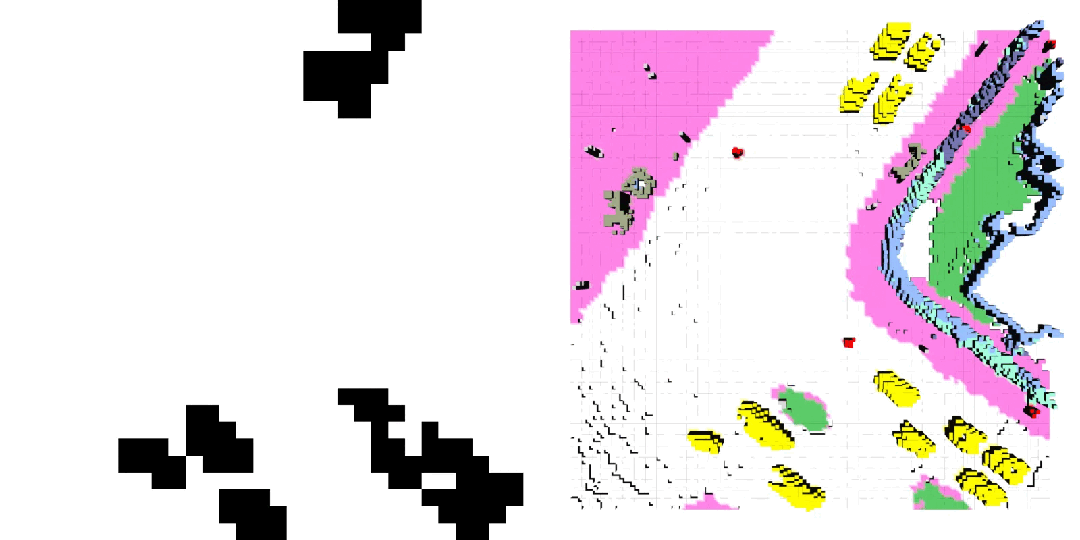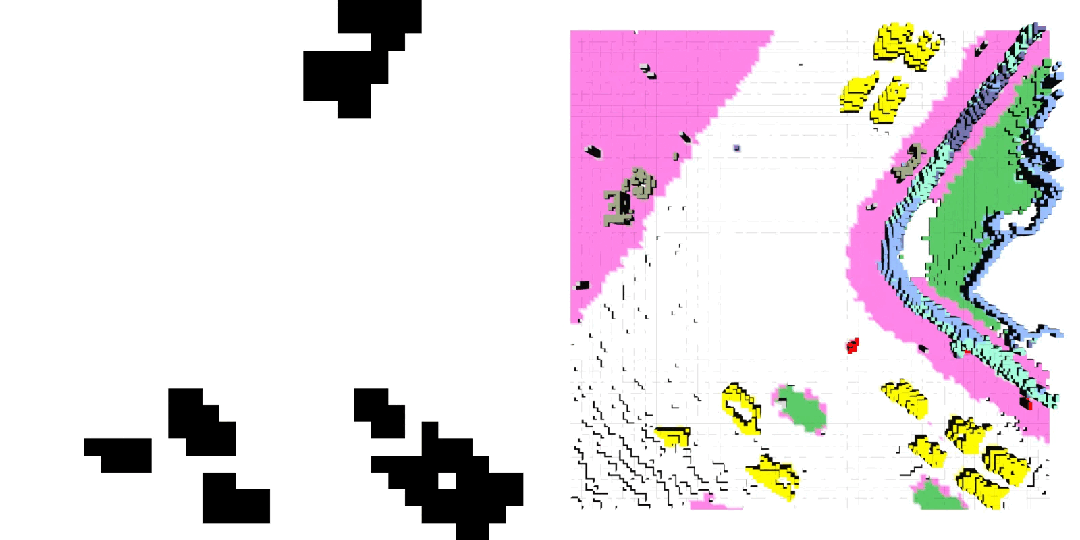
車輛軌跡 / 自車運動生成

4D 場景編輯

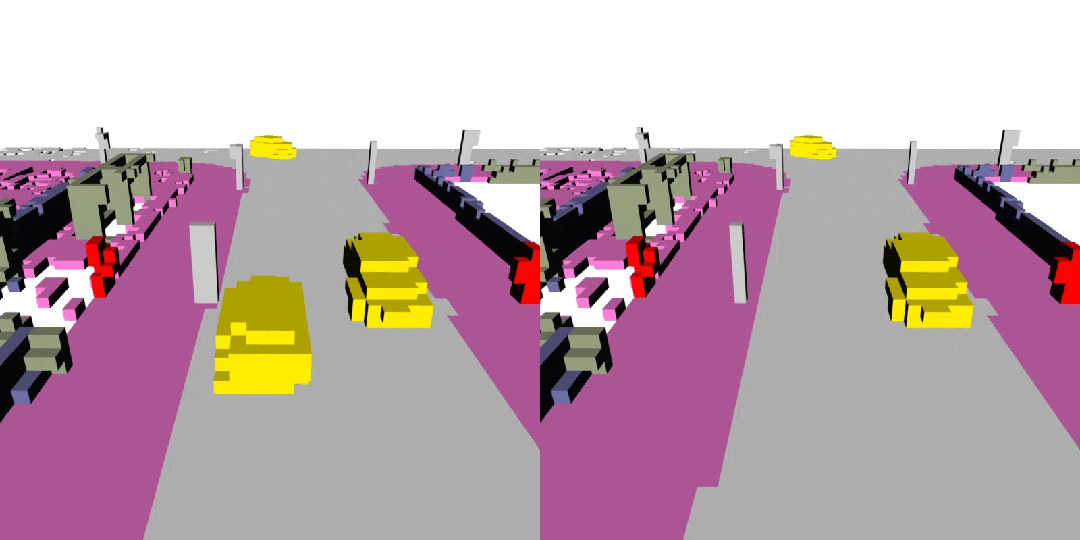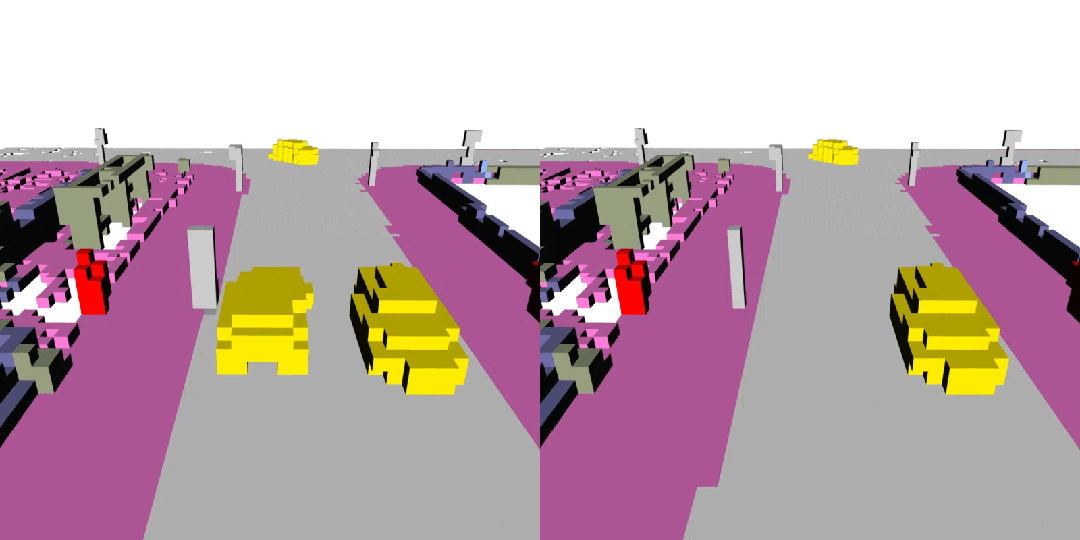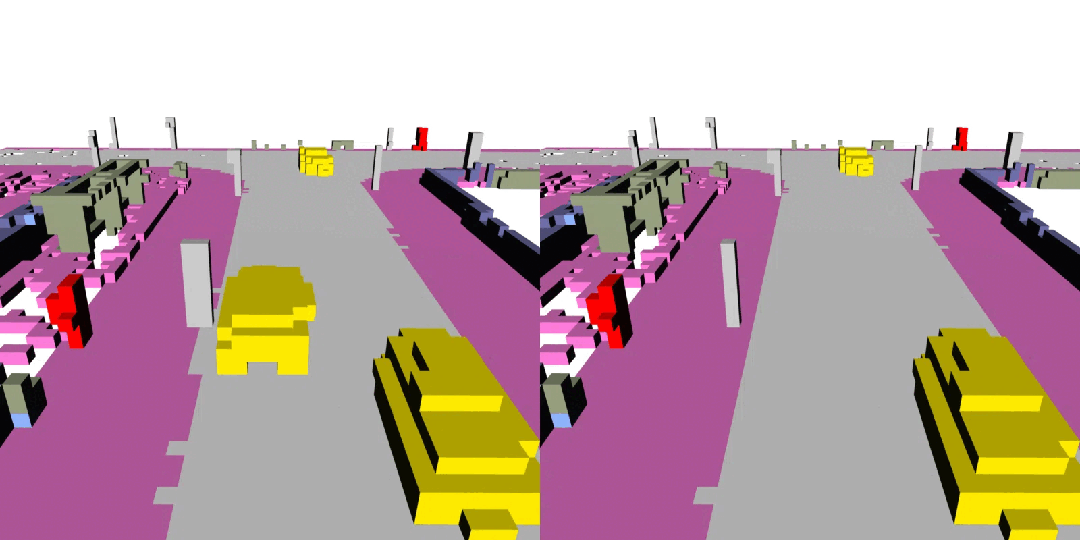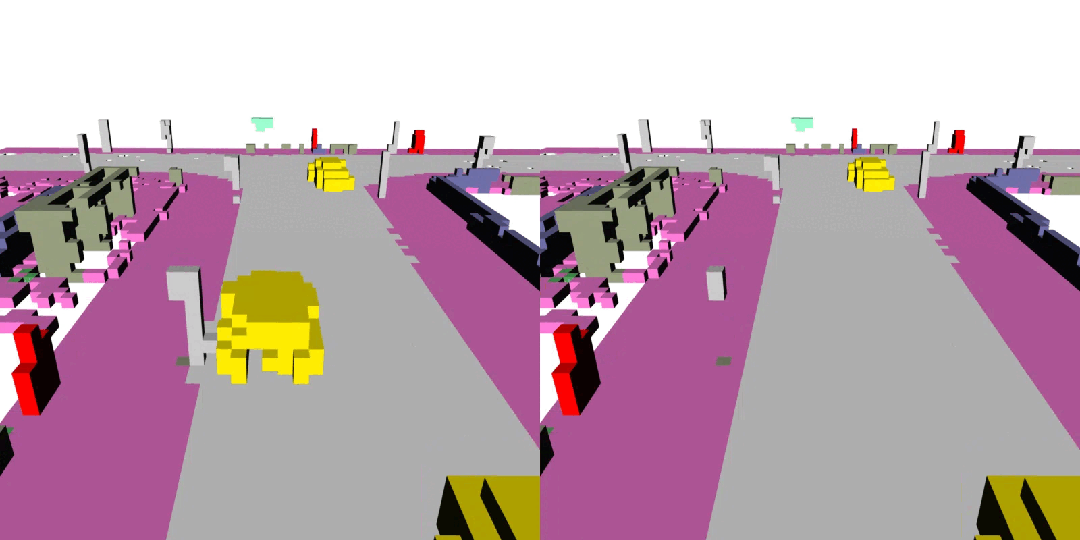
總結
DynamicCity 提出了基于 HexPlane 的 4D 場景擴散生成模型,通過 HexPlane 表征、Projection Module、Expansion & Squeeze Strategy、Padded Rollout Operation (PRO),以及Diffusion Transformer 擴散采樣,實現了高效、可控且高質量的 4D 場景生成。此外,DynamicCity 還支持多種可控生成方式,并可應用于軌跡預測、布局控制、自車運動控制及場景修改等多個自動駕駛任務。
作者介紹
DynamicCity是上海人工智能實驗室、卡耐基梅隆大學、新加坡國立大學和新加坡南洋理工大學團隊的合作項目。
本文第一作者卞恒瑋,系卡耐基梅隆大學碩士研究生,工作完成于其在上海人工智能實驗室實習期間,通訊作者為上海人工智能實驗室青年科學家潘亮博士。
其余作者分別為新加坡國立大學計算機系博士生孔令東,新加坡南洋理工大學謝浩哲博士、劉子緯教授,以及上海人工智能實驗室喬宇教授。


























