零基礎(chǔ)也能看懂的 ChatGPT 等大模型入門解析!
近兩年,大語言模型LLM(Large Language Model)越來越受到各行各業(yè)的廣泛應(yīng)用及關(guān)注。對(duì)于非相關(guān)領(lǐng)域研發(fā)人員,雖然不需要深入掌握每一個(gè)細(xì)節(jié),但了解其基本運(yùn)作原理是必備的技術(shù)素養(yǎng)。本文筆者結(jié)合自己的理解,用通俗易懂的語言對(duì)復(fù)雜的概念進(jìn)行了總結(jié),與大家分享~

一、什么是ChatGPT?
GPT 對(duì)應(yīng)的是三個(gè)關(guān)鍵概念:生成式(Generative)、預(yù)訓(xùn)練(Pre-Training)和Transformer。
生成式(Generative):是指通過學(xué)習(xí)歷史數(shù)據(jù)來生成全新的數(shù)據(jù)。當(dāng)使用ChatGPT回答問題時(shí),是逐字(或三四個(gè)字符一起)生成的。在生成過程中,每一個(gè)字(或詞,在英文中可能是詞根)都可以被稱作一個(gè) token。
預(yù)訓(xùn)練(Pre-Training):是指預(yù)先訓(xùn)練模型。舉個(gè)簡單的例子,我們想讓一個(gè)對(duì)英語一竅不通的同學(xué)去翻譯并總結(jié)一篇英語技術(shù)文章,首先需要教會(huì)這個(gè)同學(xué)英語的26個(gè)字母、以及單詞語法等基礎(chǔ)知識(shí),然后讓他了解文章相關(guān)的技術(shù)內(nèi)容,最后才能完成任務(wù)。相比之下,如果讓一個(gè)精通英語的同學(xué)來做這個(gè)任務(wù)就簡單多了,他只需要大致了解文章的技術(shù)內(nèi)容,就能很好地總結(jié)出來。「這就是預(yù)訓(xùn)練的作用——提前訓(xùn)練出一些通用能力。在人工智能中,預(yù)訓(xùn)練是通過不斷調(diào)整參數(shù)來實(shí)現(xiàn)的。」如果我們可以提前將這些通用能力相關(guān)的參數(shù)訓(xùn)練好,那么在特定場景中,只需要進(jìn)行簡單的參數(shù)微調(diào)即可,從而大幅減少每個(gè)獨(dú)立訓(xùn)練任務(wù)的計(jì)算成本。
Transformer:這是ChatGPT的核心架構(gòu),是一種神經(jīng)網(wǎng)絡(luò)模型。后文將對(duì)其進(jìn)行詳細(xì)的說明。
綜上,ChatGPT就是一個(gè)采用了預(yù)訓(xùn)練的生成式神經(jīng)網(wǎng)絡(luò)模型,能夠模擬人類的對(duì)話。
二、ChatGPT核心任務(wù)
ChatGPT核心任務(wù)就是生成一個(gè)符合人類書寫習(xí)慣的下一個(gè)合理的內(nèi)容。具體實(shí)現(xiàn)邏輯就是:根據(jù)大量的網(wǎng)頁、數(shù)字化書籍等人類撰寫內(nèi)容的統(tǒng)計(jì)規(guī)律,推測接下來可能出現(xiàn)的內(nèi)容。
1. 逐字/逐詞推測
在使用ChatGPT時(shí),如果細(xì)心觀察會(huì)發(fā)現(xiàn)它回答問題時(shí)是逐字或逐詞進(jìn)行的。這正是ChatGPT的本質(zhì):根據(jù)上下文對(duì)下一個(gè)要出現(xiàn)的字或詞進(jìn)行推測。例如,假設(shè)我們要讓ChatGPT預(yù)測“今天天氣真好”,它的運(yùn)行步驟如下:
- 輸入“今”這個(gè)字,輸出可能是“天”,“日”,“明”這三個(gè)字,其中結(jié)合上下文概率最高的是“天”字。
- 輸入“今天”這兩個(gè)字,輸出可能是“天”,“好”,“氣”這三個(gè)字,其中結(jié)合上下文概率最高的是“氣”字。
- 輸入“今天天”這三個(gè)字,輸出可能是“氣”,“好”,“熱”這三個(gè)字,其中結(jié)合上下文概率最高的是“氣”字。
- 輸入“今天天氣”這四個(gè)字,輸出可能是“真”,“好”,“熱”這三個(gè)字,其中結(jié)合上下文概率最高的是“真”字。
- 輸入“今天天氣真”這五個(gè)字,輸出可能是“好”,“熱”,“美”這三個(gè)字,其中結(jié)合上下文概率最高的是“好”字。
由于ChatGPT學(xué)習(xí)了大量人類現(xiàn)有的各種知識(shí),它可以進(jìn)行各種各樣的預(yù)測。這就是Transformer模型最終做的事情,但實(shí)際原理要復(fù)雜得多。
三、AI基礎(chǔ)知識(shí)
在介紹 ChatGPT 的原理之前,先學(xué)習(xí)一下人工智能的一些基礎(chǔ)知識(shí):
1. 機(jī)器學(xué)習(xí) (Machine Learning, ML)
機(jī)器學(xué)習(xí)是指從有限的觀測數(shù)據(jù)中學(xué)習(xí)(或“猜測”)出具有一般性的規(guī)律,并將這些規(guī)律應(yīng)用到未觀測數(shù)據(jù)樣本上的方法。主要研究內(nèi)容是學(xué)習(xí)算法。基本流程是基于數(shù)據(jù)產(chǎn)生模型,利用模型預(yù)測輸出。目標(biāo)是讓模型具有較好的泛化能力。
舉一個(gè)經(jīng)典的例子,我們挑西瓜的時(shí)候是如何判斷一個(gè)西瓜是否成熟的呢?每個(gè)人一開始都是不會(huì)挑選的,但是隨著我們耳濡目染,看了很多挑西瓜能手是怎么做的,發(fā)現(xiàn)可以通過西瓜的顏色、大小、產(chǎn)地、紋路、敲擊聲等因素來判斷,這就是一個(gè)學(xué)習(xí)的過程。
2. 神經(jīng)網(wǎng)絡(luò)
(1) 與人腦的類比
神經(jīng)網(wǎng)絡(luò)的設(shè)計(jì)靈感來源于人腦的工作方式。當(dāng)信息進(jìn)入大腦時(shí),神經(jīng)元的每一層或每一級(jí)都會(huì)完成其特殊的工作,即處理傳入的信息,獲得洞見,然后將它們傳遞到下一個(gè)更高級(jí)的層。神經(jīng)網(wǎng)絡(luò)模仿了這一過程,通過多層結(jié)構(gòu)來處理和轉(zhuǎn)換輸入數(shù)據(jù)。
(2) 基本形式的人工神經(jīng)網(wǎng)絡(luò)
最基本形式的人工神經(jīng)網(wǎng)絡(luò)通常由三層組成:
- 輸入層:這是數(shù)據(jù)進(jìn)入系統(tǒng)的入口點(diǎn)。每個(gè)節(jié)點(diǎn)代表一個(gè)特征或?qū)傩裕缭陬A(yù)測房價(jià)的例子中,輸入層可能包含房屋面積、臥室數(shù)量、浴室數(shù)量等特征。
- 隱藏層:這是處理信息的地方。隱藏層可以有多個(gè),每一層中的節(jié)點(diǎn)會(huì)對(duì)來自前一層的數(shù)據(jù)進(jìn)行加權(quán)求和,并通過激活函數(shù)(如 ReLU、Sigmoid 或 Tanh)進(jìn)行非線性變換。隱藏層的數(shù)量和每層的節(jié)點(diǎn)數(shù)可以根據(jù)任務(wù)復(fù)雜度進(jìn)行調(diào)整。
- 輸出層:這是系統(tǒng)根據(jù)數(shù)據(jù)決定如何繼續(xù)操作的位置。輸出層的節(jié)點(diǎn)數(shù)量取決于任務(wù)類型。例如,在分類任務(wù)中,輸出層可能對(duì)應(yīng)于不同類別的概率分布;在回歸任務(wù)中,輸出層可能直接給出預(yù)測值。

每一層的每一個(gè)節(jié)點(diǎn)都會(huì)對(duì)模型的某個(gè)參數(shù)進(jìn)行調(diào)整計(jì)算。在大部分情況下,每個(gè)當(dāng)前節(jié)點(diǎn)與上層的所有節(jié)點(diǎn)都是相連的,這種連接方式被稱為全連接(fully connected)。然而,在某些特定的應(yīng)用場景下,完全連接的網(wǎng)絡(luò)可能會(huì)顯得過于復(fù)雜,因此需要采用更高效的網(wǎng)絡(luò)結(jié)構(gòu)。
(3) 卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks, CNNs)
在處理圖像等具有特定已知結(jié)構(gòu)的數(shù)據(jù)時(shí),使用卷積神經(jīng)網(wǎng)絡(luò)(CNN)會(huì)更加高效。CNN 的設(shè)計(jì)是為了捕捉局部模式和空間關(guān)系,其特點(diǎn)包括:
- 卷積層:卷積層中的神經(jīng)元布置在類似于圖像像素的網(wǎng)格上,并且僅與網(wǎng)格附近的神經(jīng)元相連。這種方式減少了參數(shù)數(shù)量,同時(shí)保留了重要的局部信息。
- 池化層:用于降低特征圖的空間維度,減少計(jì)算量并防止過擬合。常見的池化方法包括最大池化(Max Pooling)和平均池化(Average Pooling)。
- 全連接層:通常位于網(wǎng)絡(luò)的末端,用于將提取到的特征映射到最終的輸出類別或預(yù)測值。
4. 參數(shù)/權(quán)重
所有的AI都有一個(gè)模型,這個(gè)模型可以簡單地被理解為我們數(shù)學(xué)里的一個(gè)公式,比如一個(gè)線性公式:。參數(shù)(權(quán)重)就是 和 。在 ChatGPT 中,3.0 版本已經(jīng)有了 1750 億個(gè)參數(shù),4.0 的參數(shù)規(guī)模未公布,但可以猜測只會(huì)比 3.0 版本更多。因此,在這樣巨大的參數(shù)規(guī)模中進(jìn)行調(diào)參訓(xùn)練是一個(gè)非常耗費(fèi)計(jì)算資源(如 GPU)的工作,所以需要大量的資金和機(jī)房支持。
5. 監(jiān)督學(xué)習(xí) / 無監(jiān)督學(xué)習(xí)
「監(jiān)督學(xué)習(xí)」:簡單的理解就是給算法模型一批已經(jīng)標(biāo)記好的數(shù)據(jù)。例如,我們提前給模型提供 1000 個(gè)西瓜,并且標(biāo)記好這 1000 個(gè)西瓜是否已經(jīng)成熟,然后由模型自己不斷去學(xué)習(xí)調(diào)整,計(jì)算出一組最擬合這些數(shù)據(jù)的函數(shù)參數(shù)。這樣我們?cè)谀玫揭粋€(gè)全新的西瓜時(shí),就可以根據(jù)這組參數(shù)來進(jìn)行比較準(zhǔn)確的預(yù)測。
「無監(jiān)督學(xué)習(xí)」:就是我們?nèi)咏o模型 1000 個(gè)西瓜,由算法自己去學(xué)習(xí)它們的特征,然后把相似的類逐漸聚合在一起。在理想情況下,我們希望聚合出 2 個(gè)類(成熟和不成熟)。
6. 過擬合 / 欠擬合
在模型進(jìn)行訓(xùn)練時(shí),最終的目的就是訓(xùn)練出一組參數(shù)來最大限度地?cái)M合訓(xùn)練數(shù)據(jù)的特征。但是訓(xùn)練的過程總會(huì)出現(xiàn)各種問題,比較經(jīng)典的就是過擬合和欠擬合。其中,
直接舉例說明更直接一點(diǎn),如下圖,我們希望模型能盡量好的來匹配我們的訓(xùn)練數(shù)據(jù),理想狀態(tài)下模型的表現(xiàn)應(yīng)當(dāng)和中間的圖一致,但實(shí)際訓(xùn)練中可能就會(huì)出現(xiàn)左右兩種情況。左邊的欠擬合并并沒有很好的擬合數(shù)據(jù),預(yù)測一個(gè)新數(shù)據(jù)的時(shí)候準(zhǔn)確率會(huì)比較低,而右側(cè)看起來非常好,把所有的數(shù)據(jù)都成功擬合了進(jìn)去,但是模型不具有泛化性,也沒有辦法對(duì)新的數(shù)據(jù)進(jìn)行準(zhǔn)確預(yù)測。
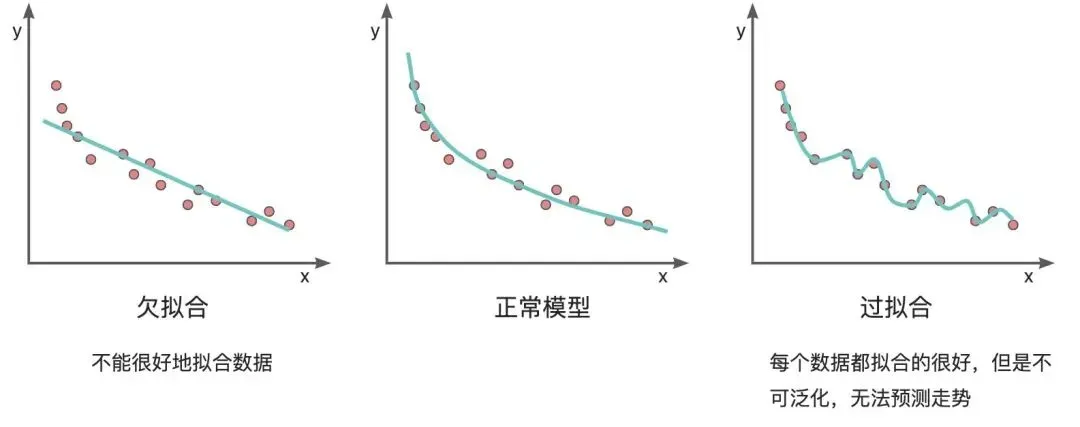
那么怎么解決過擬合和欠擬合的問題呢?可以根據(jù)模型訓(xùn)練中的實(shí)際表現(xiàn)情況來進(jìn)行正則化處理、降低復(fù)雜度處理等方法,這一點(diǎn)可以自行查閱相關(guān)資料。
四、有監(jiān)督微調(diào)(Supervised Fine-Tuning, SFT)
有監(jiān)督微調(diào)是一種用于機(jī)器學(xué)習(xí)的超參數(shù)調(diào)整方法,它可以使用從未見過的數(shù)據(jù)來快速準(zhǔn)確地調(diào)整神經(jīng)網(wǎng)絡(luò)的權(quán)重參數(shù),以獲得最佳的性能。它可以幫助機(jī)器學(xué)習(xí)模型快速地從訓(xùn)練數(shù)據(jù)中學(xué)習(xí),而不需要重新訓(xùn)練整個(gè)網(wǎng)絡(luò)。
五、強(qiáng)化學(xué)習(xí)模型(Proximal Policy Optimization, PPO)
強(qiáng)化學(xué)習(xí)模型(PPO)是一種強(qiáng)化學(xué)習(xí)算法,可以使智能體通過最大化獎(jiǎng)勵(lì)信號(hào)來學(xué)習(xí)如何與環(huán)境進(jìn)行交互。它使用剪裁目標(biāo)函數(shù)和自適應(yīng)學(xué)習(xí)率來避免大的策略更新。PPO 還具有學(xué)習(xí)可能不完全獨(dú)立和等分布數(shù)據(jù)的優(yōu)勢。
六、人類反饋強(qiáng)化學(xué)習(xí)(Reinforcement Learning with Human Feedback, RLHF)
人類反饋強(qiáng)化學(xué)習(xí)(RLHF)是訓(xùn)練 GPT-3.5 系列模型而創(chuàng)建的一種方法。主要包括三個(gè)步驟,旨在通過人類反饋來優(yōu)化語言模型的輸出質(zhì)量。
- 使用監(jiān)督學(xué)習(xí)訓(xùn)練語言模型:首先通過大量標(biāo)記數(shù)據(jù)訓(xùn)練一個(gè)基礎(chǔ)語言模型。
- 根據(jù)人類偏好收集比較數(shù)據(jù)并訓(xùn)練獎(jiǎng)勵(lì)模型:生成多個(gè)輸出并讓人類評(píng)估其質(zhì)量,訓(xùn)練一個(gè)獎(jiǎng)勵(lì)模型來預(yù)測這些輸出的質(zhì)量分?jǐn)?shù)。
- 使用強(qiáng)化學(xué)習(xí)針對(duì)獎(jiǎng)勵(lì)模型優(yōu)化語言模型:通過獎(jiǎng)勵(lì)模型優(yōu)化語言模型,使其生成更符合人類偏好的輸出。
舉個(gè)例子,假設(shè)我們要訓(xùn)練一個(gè)能夠生成高質(zhì)量對(duì)話的LLM,RLHF具體步驟如下:
(1) 預(yù)訓(xùn)練和微調(diào):使用大量的對(duì)話數(shù)據(jù)對(duì) LLM 進(jìn)行預(yù)訓(xùn)練和微調(diào),使其能夠生成連貫的對(duì)話文本。
(2) 生成多個(gè)輸出:
① 給 LLM 提供一個(gè)提示,例如:“今天天氣怎么樣?”
② LLM 生成多個(gè)響應(yīng),例如:
- 響應(yīng)1:今天天氣真好。
- 響應(yīng)2:不知道,我沒有查看天氣預(yù)報(bào)。
- 響應(yīng)3:今天天氣晴朗,適合外出。
③ 人工評(píng)估:讓人類評(píng)估這些響應(yīng)的質(zhì)量,并為每個(gè)響應(yīng)分配一個(gè)分?jǐn)?shù)。
- 響應(yīng)1:3
- 響應(yīng)2:1
- 響應(yīng)3:4
④ 訓(xùn)練獎(jiǎng)勵(lì)模型:使用這些人工評(píng)估的數(shù)據(jù)來訓(xùn)練一個(gè)獎(jiǎng)勵(lì)模型。獎(jiǎng)勵(lì)模型學(xué)習(xí)如何預(yù)測 LLM 生成文本的質(zhì)量分?jǐn)?shù)。
⑤ 強(qiáng)化學(xué)習(xí)循環(huán):
- 創(chuàng)建一個(gè)強(qiáng)化學(xué)習(xí)循環(huán),LLM 的副本成為 RL 代理。
- 在每個(gè)訓(xùn)練集中,LLM 從訓(xùn)練數(shù)據(jù)集中獲取多個(gè)提示并生成文本。
- 將生成的文本傳遞給獎(jiǎng)勵(lì)模型,獎(jiǎng)勵(lì)模型提供一個(gè)分?jǐn)?shù)來評(píng)估其與人類偏好的一致性。
- 根據(jù)獎(jiǎng)勵(lì)模型的評(píng)分,更新 LLM 的參數(shù),使其生成的文本在獎(jiǎng)勵(lì)模型上的得分更高。
通過這種方式,RLHF 能夠顯著提高 LLM 的輸出質(zhì)量,使其生成的文本更符合人類的偏好和期望。
七、Transformer架構(gòu)
對(duì)于像ChatGPT這樣的大語言模型,Transformer架構(gòu)是其核心。與傳統(tǒng)的RNN和LSTM不同,Transformer完全依賴于自注意力機(jī)制(self-attention mechanism),允許模型并行處理長序列數(shù)據(jù),而不需要逐個(gè)處理時(shí)間步。Transformer的主要組成部分包括:
- 編碼器(Encoder):負(fù)責(zé)將輸入序列轉(zhuǎn)換為上下文表示。每個(gè)編碼器層包含一個(gè)多頭自注意力機(jī)制(Multi-Head Self-Attention Mechanism)和一個(gè)前饋神經(jīng)網(wǎng)絡(luò)(Feed-Forward Neural Network),兩者之間通過殘差連接(Residual Connection)和層歸一化(Layer Normalization)連接。
- 解碼器(Decoder):負(fù)責(zé)生成輸出序列。解碼器層不僅包含自注意力機(jī)制和前饋神經(jīng)網(wǎng)絡(luò),還包括一個(gè)編碼器-解碼器注意力機(jī)制(Encoder-Decoder Attention Mechanism),用于關(guān)注輸入序列中的相關(guān)信息。
- 位置編碼(Positional Encoding):由于Transformer沒有內(nèi)在的時(shí)間/順序概念,位置編碼被添加到輸入嵌入中,以提供關(guān)于單詞相對(duì)位置的信息。
八、Transformer基本原理
第一步:Embedding
在Transformer架構(gòu)中,embedding的過程可以簡單理解為將輸入的詞(token)映射成向量表示。這是因?yàn)樯窠?jīng)網(wǎng)絡(luò)處理的是數(shù)值型數(shù)據(jù),而文本是由離散的符號(hào)組成的。因此,需要一種方法將這些符號(hào)轉(zhuǎn)換為模型能夠理解和處理的連續(xù)向量形式。
(1) Token Embedding
每個(gè)輸入的token通過一個(gè)查找表(lookup table)被映射到一個(gè)固定維度的稠密向量空間中。這個(gè)查找表實(shí)際上是一個(gè)可訓(xùn)練的參數(shù)矩陣,其中每一行對(duì)應(yīng)于詞匯表中的一個(gè)token。例如,在GPT-2中,每個(gè)token會(huì)被轉(zhuǎn)化為長度為768的embedding向量;而在更大型的模型如ChatGPT所基于的GPT-3中,embedding向量的長度可能達(dá)到12288維。
(2) Positional Encoding
由于Transformer沒有像RNN那樣的內(nèi)在順序處理機(jī)制,它無法直接感知序列中元素的位置信息。為了彌補(bǔ)這一點(diǎn),引入了位置編碼(positional encoding),它為每個(gè)位置添加了一個(gè)唯一的標(biāo)識(shí)符,使得模型能夠在處理過程中考慮到token的相對(duì)或絕對(duì)位置。位置編碼通常也是通過一個(gè)固定的函數(shù)生成,或者是作為額外的可學(xué)習(xí)參數(shù)加入到模型中。
(3) Token和Position Embedding的結(jié)合
最終的embedding是通過將token embedding和position embedding相加得到的。具體來說:
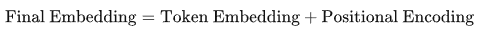
這種相加的方式并不是隨意選擇的,而是經(jīng)過大量實(shí)驗(yàn)驗(yàn)證后被認(rèn)為有效的方法之一。其背后的原因在于:
- 保持原始信息:通過簡單地相加,既保留了token本身的語義信息,又引入了位置信息。
- 允許自適應(yīng)調(diào)整:即使初始設(shè)置不是最優(yōu)的,隨著訓(xùn)練的進(jìn)行,模型可以通過梯度下降等優(yōu)化算法自動(dòng)調(diào)整這些embedding,以更好地捕捉數(shù)據(jù)中的模式。
- 簡化計(jì)算:相比于其他復(fù)雜的組合方式,簡單的相加操作更加高效,并且不會(huì)增加太多額外的計(jì)算負(fù)擔(dān)。
以字符串“天氣”為例,假設(shè)我們使用GPT-2模型來處理:
- Token Embedding:首先,“天”和“氣”這兩個(gè)字符分別被映射到它們對(duì)應(yīng)的768維向量。
- Positional Encoding:然后,根據(jù)它們?cè)诰渥又械奈恢茫ǖ谝粋€(gè)位置和第二個(gè)位置),分別為這兩個(gè)字符生成相應(yīng)的位置編碼向量。
- 相加生成最終的embedding:最后,將上述兩個(gè)步驟得到的向量相加以形成最終的embedding向量序列。
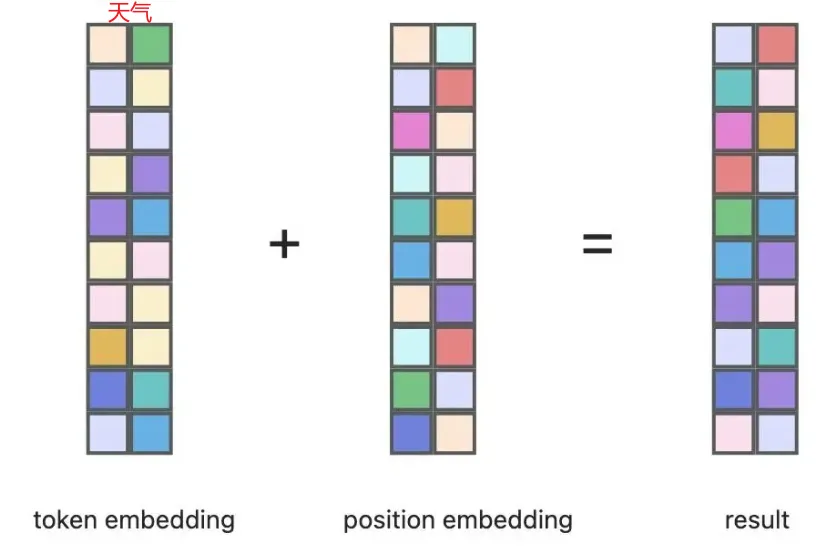
如上圖,第一張圖中展示了token embedding,其中縱向一列表示一個(gè)向量,依次排列的是“天”和“氣”的embedding向量。第二張圖則顯示了位置的embedding,反映了這兩個(gè)字符的位置信息。將這兩者相加后,我們就得到了包含語義和位置信息的完整embedding序列。
第二步:Attention
在Transformer架構(gòu)中,Attention機(jī)制是核心組件之一,它使得模型能夠并行處理長序列數(shù)據(jù),并且有效地捕捉輸入序列中的依賴關(guān)系。Attention機(jī)制的核心思想是讓模型關(guān)注輸入序列的不同部分,從而更好地理解上下文信息。
(1) 自注意力(Self-Attention)
自注意力(也稱為內(nèi)部注意力)是Transformer中的一種特殊形式的Attention,它允許每個(gè)位置的token與序列中的所有其他位置進(jìn)行交互。這意味著每個(gè)token都可以根據(jù)整個(gè)序列的信息來調(diào)整自己的表示,而不僅僅是依賴于前一個(gè)或后一個(gè)token。
(2) Attention Head
每個(gè)“注意力塊”(Attention Block)包含多個(gè)獨(dú)立的Attention Heads,這些Head可以看作是不同視角下的Attention計(jì)算。每個(gè)Head都會(huì)獨(dú)立地作用于embedding向量的不同子空間,這樣可以捕捉到更多樣化的信息。例如,在GPT-3中有96個(gè)這樣的注意力塊,每個(gè)塊中又包含多個(gè)Attention Heads。
(3) Q、K、V 的生成
對(duì)于每個(gè)token的embedding向量,我們通過線性變換(即乘以三個(gè)不同的可訓(xùn)練矩陣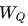 、
、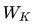 和
和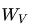 )將其轉(zhuǎn)換為三個(gè)向量:Query (Q)、Key (K) 和 Value (V)。這三個(gè)向量分別代表查詢、鍵和值。具體來說:
)將其轉(zhuǎn)換為三個(gè)向量:Query (Q)、Key (K) 和 Value (V)。這三個(gè)向量分別代表查詢、鍵和值。具體來說:
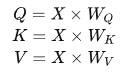
其中,X是輸入的embedding向量,、和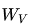 是隨機(jī)初始化并在訓(xùn)練過程中學(xué)習(xí)得到的權(quán)重矩陣。
是隨機(jī)初始化并在訓(xùn)練過程中學(xué)習(xí)得到的權(quán)重矩陣。
(4) Attention分?jǐn)?shù)的計(jì)算
接下來,我們需要計(jì)算每個(gè)token與其他所有token之間的Attention分?jǐn)?shù)。這一步驟使用了Scaled Dot-Product Attention公式:
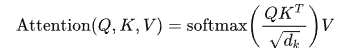
這里,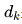 是Key向量的維度大小,用于縮放點(diǎn)積結(jié)果以穩(wěn)定梯度。Softmax函數(shù)確保輸出的概率分布加起來等于1,這樣可以突出最重要的部分。
是Key向量的維度大小,用于縮放點(diǎn)積結(jié)果以穩(wěn)定梯度。Softmax函數(shù)確保輸出的概率分布加起來等于1,這樣可以突出最重要的部分。
以上就是 Transformer 的大致原理,用一張圖來表示上面的步驟,如下所示。