o3斬獲IOI金牌沖榜全球TOP 18,自學(xué)碾壓頂尖程序員!48頁技術(shù)報(bào)告公布
幾天前,谷歌AlphaGeometry 2拿下IMO金牌,震驚了所有人。
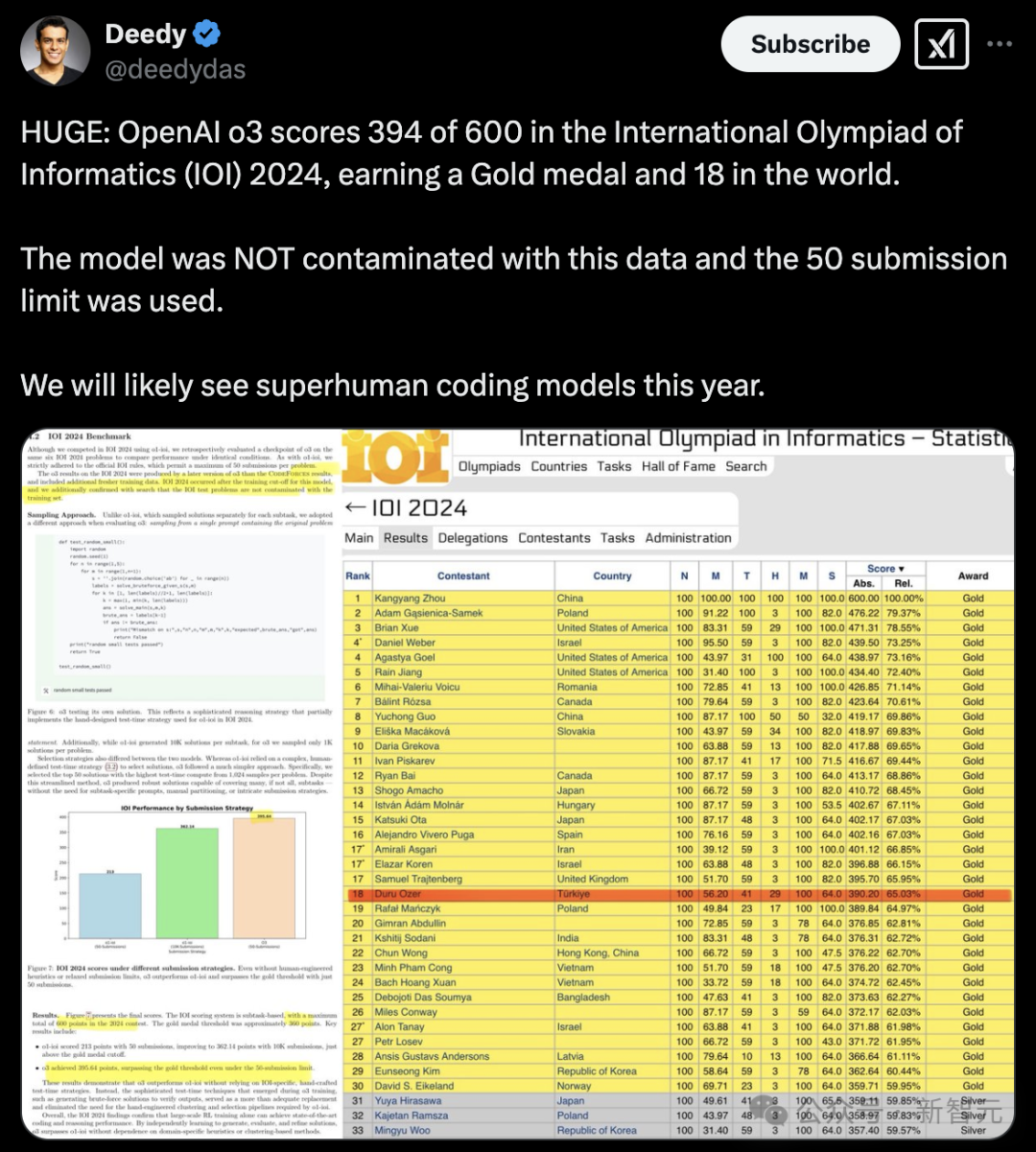
這次,o3在IOI 2024競賽中取得驚人的394分(滿分600),一舉奪得金牌,實(shí)力相當(dāng)于全球第18名賽級(jí)選手。
不僅如此,在世界級(jí)編程競賽CodeForces上,o3位居全球Top 200之列,堪比人類頂尖程序員。
早在去年8月,OpenAI團(tuán)隊(duì)便開始全力準(zhǔn)備讓o系模型參賽IOI 2024,o1作為第一個(gè)代表上陣。
為了提升AI性能,他們當(dāng)時(shí)用盡了幾乎所有的技巧——微調(diào)、基于測試用例進(jìn)行過濾、提示模型生成額外的測試用例、基于相似度對解決方案進(jìn)行聚類、對聚類進(jìn)行排序等等。
誰曾想,那個(gè)「苦澀的教訓(xùn)」依然和往常一樣苦澀......
而o3卻在無人啟發(fā)的情況下,通過強(qiáng)化學(xué)習(xí)中自己摸索出了一些技巧,就比如,用隨機(jī)測試用例對比暴力解來測試代碼。
o3通過「思維鏈」來scaling測試時(shí)計(jì)算的能力是多么強(qiáng)大。
當(dāng)我們檢查思維鏈過程時(shí),我們發(fā)現(xiàn)模型自主發(fā)展出了自己的測試時(shí)策略。其中一個(gè)有趣的策略是:模型會(huì) 1)先寫一個(gè)簡單的暴力解決方案,然后 2)用它來驗(yàn)證一個(gè)更復(fù)雜的優(yōu)化方案。
這些關(guān)鍵發(fā)現(xiàn),現(xiàn)如今已全部公開了。
本月初,OpenAI團(tuán)隊(duì)在arXiv發(fā)表了一篇,超全48頁推理模型參與競爭性編程的研究。

論文鏈接:https://arXiv.org/pdf/2502.06807
論文中,他們展示了LLM如何從「菜鳥」進(jìn)階到全球Top程序員,甚至拿下了IOI金牌的全過程!

最新研究,重點(diǎn)強(qiáng)調(diào)了「推理」在編程任務(wù)中的重要性,詳細(xì)呈現(xiàn)了o系推理模型在編程方面的進(jìn)展,以及在各類競賽編程、編碼基準(zhǔn)測試中評(píng)估方法和結(jié)果。
其中,關(guān)鍵亮點(diǎn)有以下四個(gè):
- 展示了CoT推理的強(qiáng)大作用:從競賽編程基準(zhǔn)到復(fù)雜軟件工程難題,編程表現(xiàn)都有提高
- 同時(shí)增加強(qiáng)化學(xué)習(xí)訓(xùn)練和測試時(shí)計(jì)算資源,能持續(xù)提升模型表現(xiàn),幾乎達(dá)到世界頂尖人類水平
- 利用CodeForces、IOI等多個(gè)權(quán)威平臺(tái)及數(shù)據(jù)集,全面驗(yàn)證模型在競賽和實(shí)際任務(wù)中的表現(xiàn)
- 發(fā)現(xiàn)LLM通過強(qiáng)化學(xué)習(xí)可超越特定領(lǐng)域模型,證實(shí)CoT推理提升模型性能
半個(gè)月前,奧特曼曾在采訪中劇透,「OpenAI內(nèi)部的一個(gè)推理模型已躍升至全球第50名,而且很可能在年底前霸榜」。

用不了多久,AI真的要踏平編程界了么。
AI拿下IOI金牌,卷趴頂尖程序員
競技編程,被廣泛認(rèn)為是評(píng)估推理和編程能力的具有挑戰(zhàn)性的基準(zhǔn)。
從文檔字符串合成程序,OpenAI早期某模型的正確率為28.8%,而GPT-3對這類問題甚至完全無能為力。
解決復(fù)雜的算法問題,需要高級(jí)的計(jì)算思維和問題解決技巧。此外,這些問題還具有客觀的可評(píng)分性,使其成為評(píng)估AI系統(tǒng)推理能力的理想試驗(yàn)平臺(tái)。
AlphaCode通過大規(guī)模代碼生成和推理過程中的啟發(fā)式方法,成功解決了競賽編程任務(wù)。隨后推出的AlphaCode2,幾乎使AlphaCode的解決問題數(shù)量翻倍,并使其在CodeForces平臺(tái)上躋身前15%。

論文地址:https://www.science.org/doi/10.1126/science.abq1158
這兩種系統(tǒng)都在問題上大規(guī)模采樣,最多生成一百萬個(gè)候選解決方案,然后通過手工設(shè)計(jì)的測試策略選擇前10個(gè)提交結(jié)果。
自那時(shí)以來,利用強(qiáng)化學(xué)習(xí)提升大規(guī)模語言模型(LLM)推理能力取得了顯著進(jìn)展。這促使了大規(guī)模推理模型(LRM)的出現(xiàn):這些語言模型通過強(qiáng)化學(xué)習(xí)進(jìn)行訓(xùn)練,以「推理」和「思考」復(fù)雜的思維鏈。
一個(gè)尚未解決的問題是,領(lǐng)域特定的手工設(shè)計(jì)推理策略與模型自主生成并執(zhí)行的學(xué)習(xí)方法相比,效果如何?
為了解決這個(gè)問題,團(tuán)隊(duì)希望從o1、o1-ioi和o3的早期checkpoint中獲得靈感。
OpenAI o1使用通用方法來提升編程性能。而o1-ioi是一個(gè)針對2024年國際信息學(xué)奧林匹克(IOI)競賽進(jìn)行微調(diào)的系統(tǒng),采用了類似于AlphaCode系統(tǒng)的測試時(shí)策略。與o1-ioi或AlphaCode不同,o3不依賴于由人工定義的特定編碼的測試時(shí)策略。
值得注意的是,o3在2024年IOI中贏得了金牌,并獲得了與人類頂尖選手相當(dāng)?shù)腃odeForces評(píng)級(jí)。
o1:推理模型先鋒
o1通過強(qiáng)化學(xué)習(xí)訓(xùn)練的大型語言模型,利用CoT將復(fù)雜任務(wù)分解為易于處理的部分,用于處理復(fù)雜的推理任務(wù)。
此外,o1能夠使用外部工具,特別是在安全環(huán)境中編寫和執(zhí)行代碼,讓o1能夠驗(yàn)證生成的代碼是否能編譯、能否通過測試用例并滿足其他正確性檢查。
通過測試和優(yōu)化其輸出,o1在單次樣本過程中不斷改進(jìn)其解決方案。
CodeForces是一個(gè)舉辦實(shí)時(shí)編程競賽的網(wǎng)站,吸引了世界上頂尖的競賽程序員。
為了評(píng)估模型在競賽編程中的能力,模擬了與實(shí)際比賽條件非常相似的CodeForces競賽,包括使用每個(gè)問題的完整測試集,并為解決方案設(shè)定適當(dāng)?shù)臅r(shí)間和內(nèi)存限制。
o1與非推理模型gpt4o和早期的推理模型o1-preview進(jìn)行了比較。如圖1顯示,o1-preview和o1的表現(xiàn)遠(yuǎn)遠(yuǎn)超越了gpt-4o,突顯了強(qiáng)化學(xué)習(xí)在復(fù)雜推理中的有效性。
o1-preview模型在CodeForces上的評(píng)分為1258(第62百分位),相比之下,gpt-4o的評(píng)分為808(第11百分位)。進(jìn)一步的訓(xùn)練使o1的評(píng)分提高到1673(第89百分位),為AI在競賽編程中的表現(xiàn)設(shè)立了新的里程碑。

圖1:在CodeForces上不同大語言模型OpenAI o1-preview、o1與GPT-4o的表現(xiàn)
o1-ioi:為競賽「量身定制」
o1-ioi起源
在開發(fā)和評(píng)估OpenAI o1的過程中,發(fā)現(xiàn)增加強(qiáng)化學(xué)習(xí)(RL)計(jì)算量和測試時(shí)間推理計(jì)算量,都能持續(xù)提高模型性能。
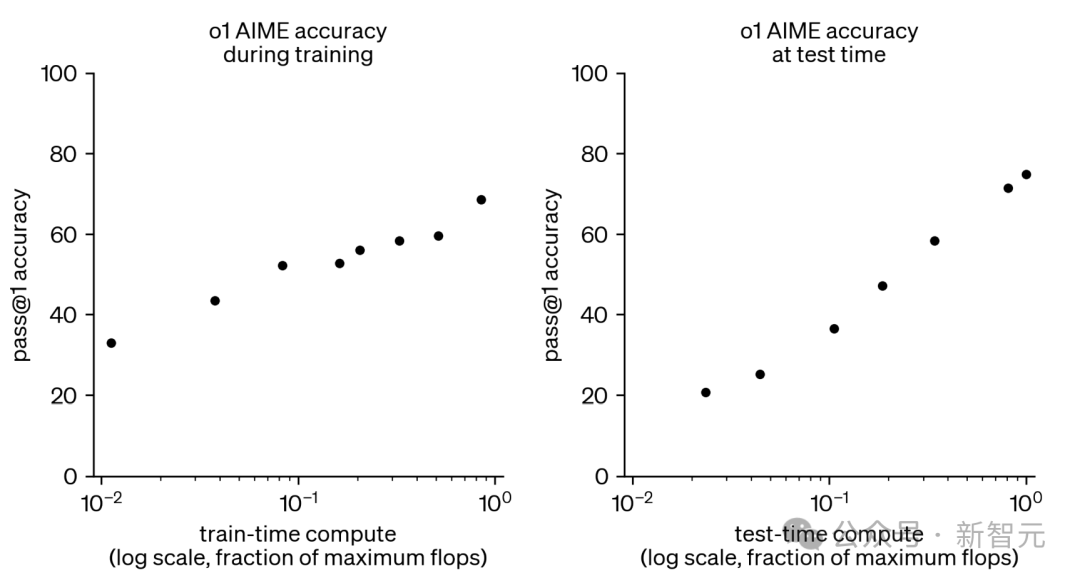
圖2:更多的強(qiáng)化學(xué)習(xí)訓(xùn)練/測試時(shí)計(jì)算資源提升了競賽數(shù)學(xué)表現(xiàn)
基于這些洞察,研究團(tuán)隊(duì)創(chuàng)建了o1-ioi系統(tǒng),用于參加2024年國際信息學(xué)奧林匹克(IOI)。
除了針對編程任務(wù)進(jìn)行的持續(xù)強(qiáng)化學(xué)習(xí)訓(xùn)練,o1-ioi還結(jié)合了專門為競賽編程設(shè)計(jì)的測試時(shí)推理策略。
編程任務(wù)的強(qiáng)化微調(diào)
第一步是擴(kuò)展OpenAI o1的強(qiáng)化學(xué)習(xí)階段,重點(diǎn)聚焦于編程任務(wù)。
通過將額外的訓(xùn)練計(jì)算資源投入到編程問題中,我們增強(qiáng)了模型規(guī)劃、實(shí)現(xiàn)和調(diào)試更復(fù)雜解決方案的能力。具體來說:
- 從OpenAI o1的checkpoint恢復(fù)了強(qiáng)化學(xué)習(xí)訓(xùn)練
- 特別強(qiáng)調(diào)了具有挑戰(zhàn)性的編程問題,幫助模型提升C++代碼生成和運(yùn)行時(shí)檢查能力
- 引導(dǎo)模型生成符合IOI提交格式的輸出
這種額外的編程訓(xùn)練使得o1-ioi在推理過程中能夠編寫并執(zhí)行C++程序。通過反復(fù)運(yùn)行和優(yōu)化解決方案,模型在推理過程中不斷改進(jìn)其推理能力,從而增強(qiáng)了編程和解決問題的技能。
o1-ioi測試時(shí)策略
從整體上看,測試時(shí)策略將每個(gè)IOI問題分解成多個(gè)子任務(wù)。
對于每個(gè)子任務(wù),從o1-ioi中采樣了10,000個(gè)解決方案,然后采用基于聚類和重新排序的方法,來決定從這些解決方案中提交哪些結(jié)果。
問題設(shè)定
o1-ioi選擇單獨(dú)解決每個(gè)問題的各個(gè)子任務(wù),因?yàn)镮OI的評(píng)分是基于每個(gè)子任務(wù)進(jìn)行的,并且每個(gè)選手的最終得分是所有子任務(wù)中最佳嘗試的得分。
因此,將每個(gè)IOI問題分解為其組成的子任務(wù)(根據(jù)每個(gè)問題的評(píng)分指南中的劃分)。具體做法是為每個(gè)子任務(wù)創(chuàng)建一個(gè)版本的文檔,刪除其他子任務(wù)的信息。
聚類
基于模型生成的測試輸入的輸出,對生成的解決方案進(jìn)行了聚類。
對于每個(gè)子任務(wù),首先讓模型根據(jù)問題規(guī)格和子任務(wù)要求生成隨機(jī)的C++測試輸入生成器。研究團(tuán)隊(duì)使用這些生成器生成256個(gè)隨機(jī)測試輸入。
為了確保這些測試輸入的有效性,接著讓模型編寫C++的測試輸入驗(yàn)證器,檢查每個(gè)測試輸入是否滿足子任務(wù)的約束條件。
最終,只接受通過至少75%驗(yàn)證器檢查的測試輸入。對于每個(gè)子任務(wù),生成了256個(gè)這樣的隨機(jī)測試輸入,并基于這些測試輸入的輸出進(jìn)行了聚類。所有在所有測試輸入上輸出相同的程序?qū)⒈粴w為同一類。
重新排序
接著,研究團(tuán)隊(duì)實(shí)現(xiàn)了測試時(shí)計(jì)算策略中的重新排序核心部分。根據(jù)以下幾個(gè)方面,對每個(gè)解決方案進(jìn)行了評(píng)分:
- 根據(jù)學(xué)習(xí)得來的評(píng)分函數(shù)評(píng)估解決方案的質(zhì)量
- 在模型生成的測試輸入上出現(xiàn)的錯(cuò)誤
- 未通過提供的公共測試用例
每個(gè)聚類都被賦予了一個(gè)分?jǐn)?shù),該分?jǐn)?shù)定義為該聚類中包含的樣本的平均分?jǐn)?shù)減去每次從該聚類提交樣本時(shí)所受到的懲罰。所有這些懲罰的權(quán)重是通過對過去幾年IOI問題的解決方案進(jìn)行隨機(jī)搜索調(diào)整的,具體方法是通過直接模擬提交過程來進(jìn)行調(diào)優(yōu)。
模擬提交
隨后以輪詢的方式提交了最多50個(gè)解決方案(這是人類參賽者允許的最大提交次數(shù)),從最難的子任務(wù)開始,覆蓋所有子任務(wù)。
研究團(tuán)隊(duì)為每個(gè)子任務(wù)選擇排名靠前的集群中的最高排名解決方案。
當(dāng)某個(gè)子任務(wù)被解決(即獲得了最高分)時(shí),停止對該子任務(wù)的采樣。
在提交任何嚴(yán)格包含已解決子任務(wù)的子任務(wù)的解決方案時(shí),會(huì)過濾掉那些與已解決子任務(wù)的測試輸入輸出不匹配的解決方案,從而通過剔除幾乎肯定會(huì)在較簡單子任務(wù)上失敗的解決方案,快速縮小較難子任務(wù)上的候選解決方案范圍。
CodeForces基準(zhǔn)測試
研究團(tuán)隊(duì)再次模擬了CodeForces競賽,以評(píng)估o1-ioi的編程能力,競賽條件與實(shí)際比賽高度一致,包括每個(gè)問題的完整測試集和適當(dāng)?shù)臅r(shí)間與內(nèi)存限制。
圖3顯示,o1-ioi達(dá)到了1807的CodeForces評(píng)分,超越了93%的競爭者——這清楚地展示了通過在編程任務(wù)上進(jìn)行額外強(qiáng)化學(xué)習(xí)訓(xùn)練所帶來的改進(jìn)。
當(dāng)應(yīng)用簡單的篩選器,拒絕任何未通過公共測試的解決方案時(shí),評(píng)分提高到了2092(第96百分位)。完整的測試時(shí)策略進(jìn)一步提升了性能,達(dá)到了2214的評(píng)分(第98百分位)。
這些結(jié)果驗(yàn)證了領(lǐng)域特定的強(qiáng)化學(xué)習(xí)微調(diào)與先進(jìn)的選擇啟發(fā)式方法相結(jié)合,可以顯著提升競賽編程的成果。

圖3:通過對OpenAI o1進(jìn)行編碼任務(wù)的進(jìn)一步訓(xùn)練并結(jié)合測試時(shí)策略,可以提升性能
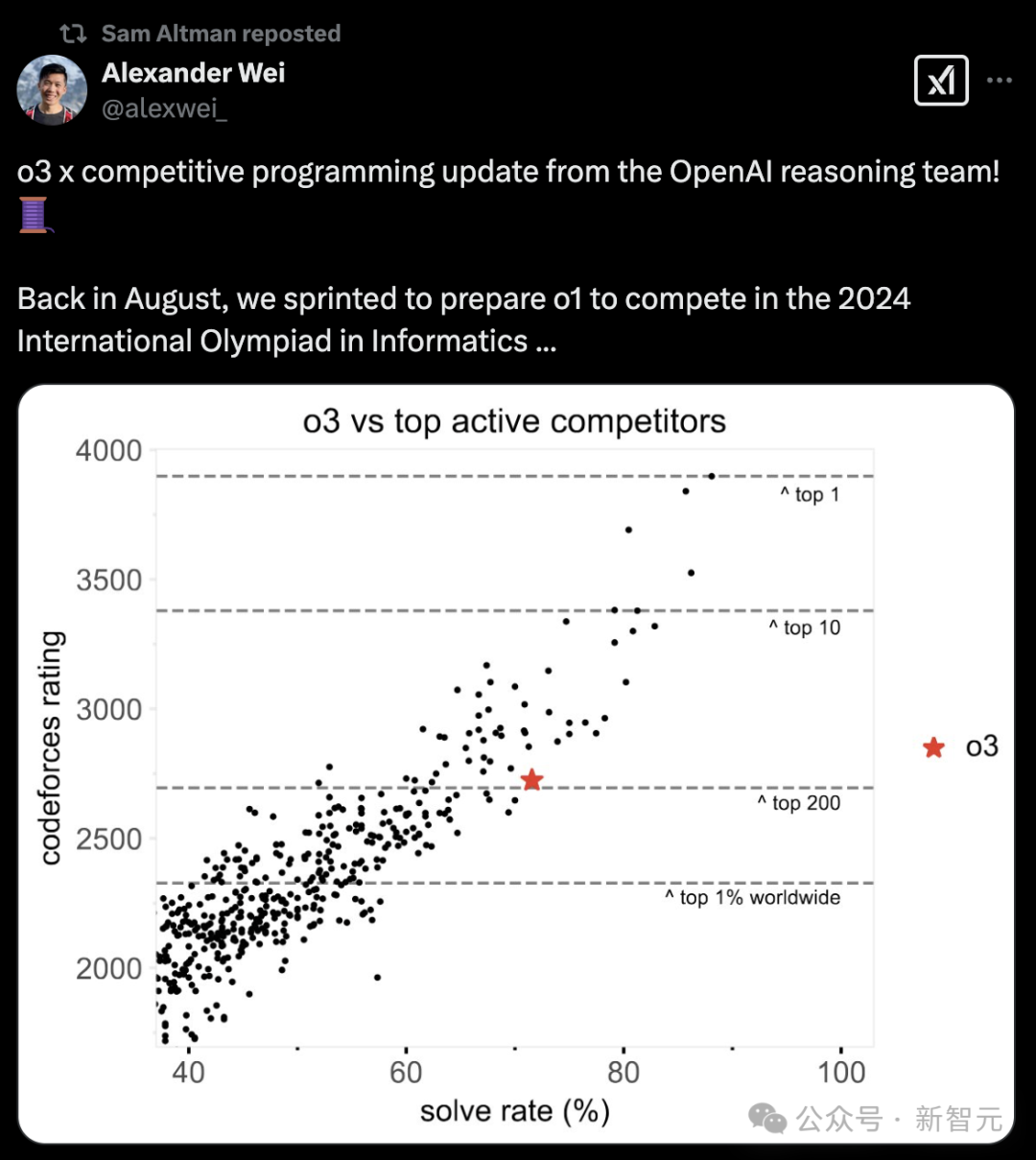
CodeForces維護(hù)著一個(gè)全球活動(dòng)參與者的排行榜。研究團(tuán)隊(duì)直接將o3在測試競賽中的解題率與其他參賽者進(jìn)行比較。
圖10展示了這兩種比較,展示了他們在參賽的競賽中的平均解題率與他們的評(píng)分,并標(biāo)出了關(guān)鍵績效水平的評(píng)分閾值。
其中,每個(gè)點(diǎn)代表至少參加了8場測試競賽的參賽者。水平線表示全球CodeForces活躍競爭者排行榜上的表現(xiàn)閾值。
盡管最頂尖的人類參賽者仍然遠(yuǎn)遠(yuǎn)強(qiáng)于o3,他們的解題率超過85%,但評(píng)分和解題率都表明,o3可以位列全球前200名活躍參與者之中。
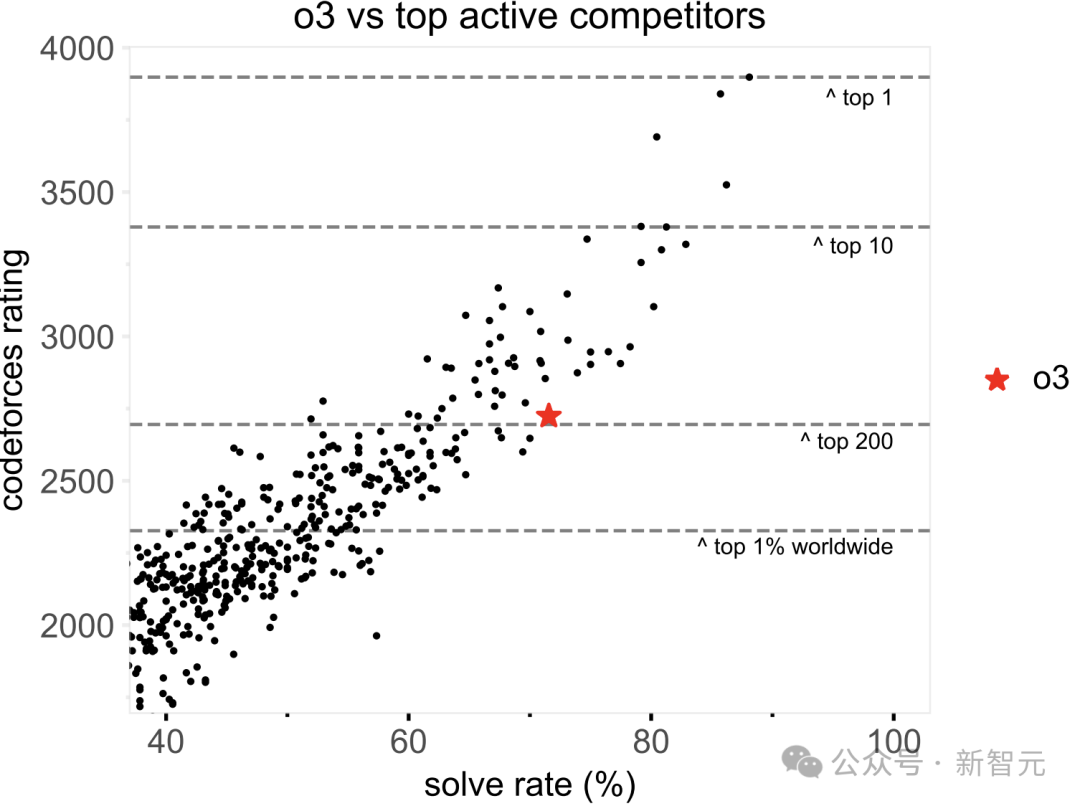
圖10:o3位居全球Top 200競賽程序員之列
IOI 2024
o1-ioi系統(tǒng)在與人類參賽者相同的條件下參加了2024年國際信息學(xué)奧林匹克競賽(IOI)。它有10小時(shí)的時(shí)間解決六個(gè)高難度算法問題,每個(gè)問題最多允許提交50次。
在競賽期間,系統(tǒng)為每個(gè)問題生成了10,000個(gè)候選解決方案,并使用設(shè)計(jì)的測試時(shí)選擇策略從中挑選50個(gè)提交方案。
該策略根據(jù)提交方案在IOI公開測試用例、模型生成的測試用例以及學(xué)習(xí)得到的評(píng)分函數(shù)上的表現(xiàn)進(jìn)行優(yōu)先級(jí)排序。該模型最終得分213分,位列競賽的第49百分位。
相比之下,隨機(jī)選擇50個(gè)提交方案的平均得分僅為156分,這表明選擇策略在競賽的限制條件下額外貢獻(xiàn)了近60分。
當(dāng)每個(gè)問題的提交限制放寬到10,000次時(shí),模型的表現(xiàn)顯著提升。在不采用任何測試時(shí)選擇策略的情況下,其得分達(dá)到了362.14分,超過了金牌門檻。
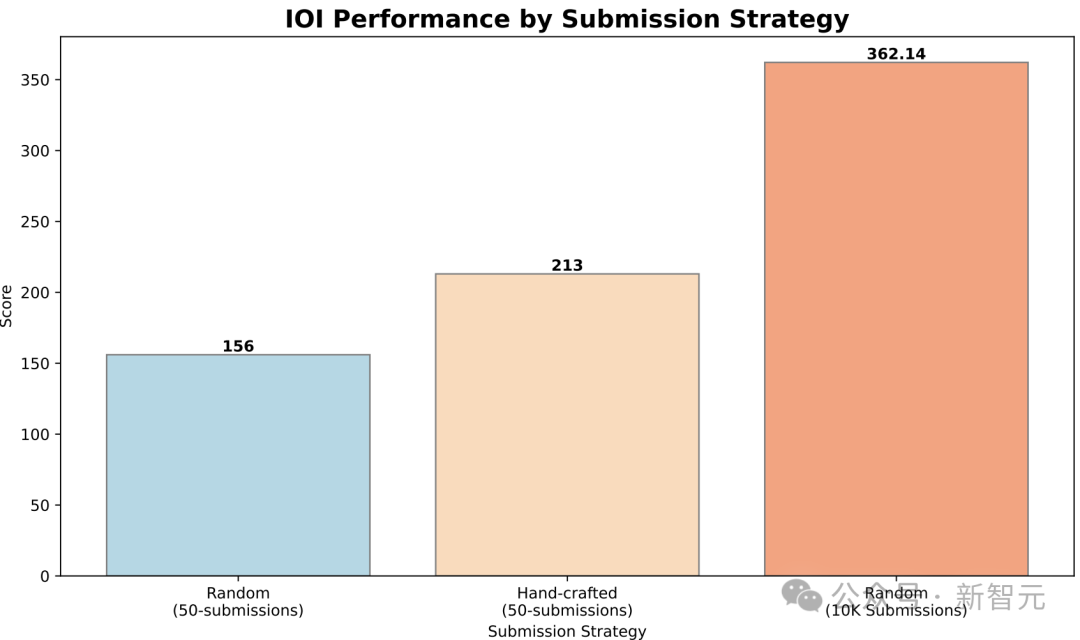
圖4:o1-ioi在IOI 2024競賽中的表現(xiàn)
o3:自主推理新SOTA
o3在o1和o1-ioi的基礎(chǔ)上,進(jìn)行了更具創(chuàng)新性的探索。它致力于僅依靠強(qiáng)化學(xué)習(xí)訓(xùn)練,擺脫對人工設(shè)計(jì)測試時(shí)策略的依賴,挖掘模型自主推理的極限。
研究人員獲取了o3的早期checkpoint,在編程競賽任務(wù)上對其進(jìn)行評(píng)估。
在CodeForces基準(zhǔn)測試中,o3的表現(xiàn)堪稱驚艷。進(jìn)一步的RL訓(xùn)練讓o3相較于o1和o1-ioi有了質(zhì)的飛躍。
o3的評(píng)分從o1-ioi的2214(98百分位)提升至 2724(99.8百分位),這一巨大的提升反映出o3在解決復(fù)雜算法問題的能力有了顯著增強(qiáng),可靠性更高,在CodeForces平臺(tái)上的實(shí)力已經(jīng)接近頂尖人類選手。
o3在推理過程中展現(xiàn)出更具洞察力和深度思考的思維鏈。
對于驗(yàn)證過程較為復(fù)雜的問題,o3會(huì)采用一種獨(dú)特的策略:先編寫簡單的暴力解法,犧牲一定效率來確保正確性,然后將暴力解法的輸出與更優(yōu)化的算法實(shí)現(xiàn)進(jìn)行交叉檢查。

這種自我驗(yàn)證機(jī)制有效地幫助o3發(fā)現(xiàn)潛在錯(cuò)誤,提高了解決方案的可靠性。
在2024年IOI基準(zhǔn)測試中,研究人員對o3在相同的6個(gè)IOI問題上進(jìn)行了回溯評(píng)估。o3采用了與o1-ioi不同的采樣和選擇策略。
o3從包含原始問題陳述的單個(gè)提示中采樣,每個(gè)問題僅采樣1000個(gè)解決方案,選擇策略也更為簡潔,即從1024個(gè)樣本中選取測試時(shí)計(jì)算得分最高的50個(gè)解決方案。
即便采用如此簡化的方法,o3依然能夠生成強(qiáng)大的解決方案,覆蓋大部分甚至全部子任務(wù),而無需像o1-ioi那樣依賴子任務(wù)特定的提示、手動(dòng)分區(qū)或復(fù)雜的提交策略。

最終,o3在僅提交50次的情況下,得分達(dá)到395.64分,超過了金牌分?jǐn)?shù)線,而o1-ioi在相同提交次數(shù)下僅得到213分,提交次數(shù)增加到10000次才超過金牌分?jǐn)?shù)線。
這充分證明了o3無需依賴特定領(lǐng)域的啟發(fā)式方法或基于聚類的復(fù)雜策略,僅靠大規(guī)模強(qiáng)化學(xué)習(xí)訓(xùn)練就能實(shí)現(xiàn)卓越的編碼和推理性能。
編程中的「實(shí)戰(zhàn)」表現(xiàn)
編程競賽雖然能展示AI的能力,在實(shí)際的軟件開發(fā)任務(wù)中,模型的表現(xiàn)又如何呢?
研究人員通過HackerRank Astra和SWE-bench Verified這兩個(gè)數(shù)據(jù)集,對模型進(jìn)行了進(jìn)一步的測試。
HackerRank Astra數(shù)據(jù)集包含65個(gè)編碼挑戰(zhàn),旨在模擬現(xiàn)實(shí)世界的軟件開發(fā)任務(wù)。
這些挑戰(zhàn)涵蓋了React.js、Django和Node.js等多種框架,要求開發(fā)者在復(fù)雜的多文件、長上下文場景中解決問題,并且不提供公共測試用例。
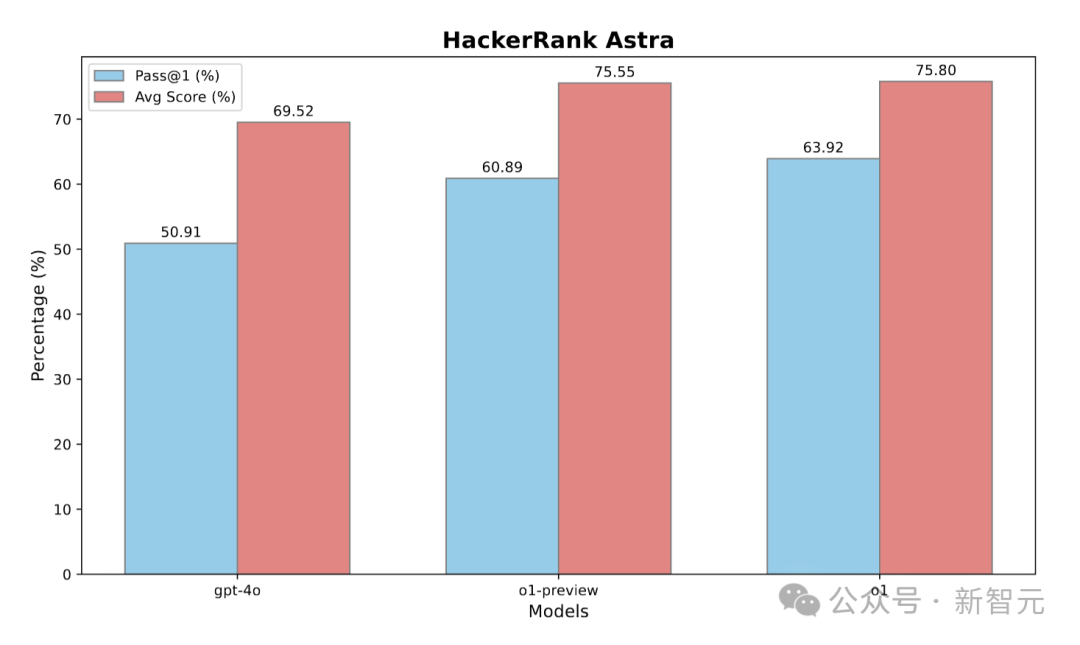
測試結(jié)果顯示,o1-preview相較于GPT-4o,首次嘗試完成任務(wù)的概率(pass@1)上提高了9.98%,平均得分提升了6.03分。
經(jīng)強(qiáng)化學(xué)習(xí)微調(diào)后的o1表現(xiàn)更優(yōu),pass@1達(dá)到63.92%,平均得分達(dá)到75.80%,相比o1-preview又有了進(jìn)一步提升。這表明o1能夠有效地應(yīng)對復(fù)雜的軟件開發(fā)任務(wù)。
SWE-bench Verified是OpenAI對SWE-bench進(jìn)行人工驗(yàn)證后的子集,用于更可靠地評(píng)估AI模型解決實(shí)際軟件問題的能力。
在這個(gè)數(shù)據(jù)集上,o1-preview相較于GPT-4o有8.1%的性能提升,經(jīng)過更多強(qiáng)化學(xué)習(xí)訓(xùn)練的o1進(jìn)一步提升了8.6%,o3相較于o1更是實(shí)現(xiàn)了22.8%的顯著提升。
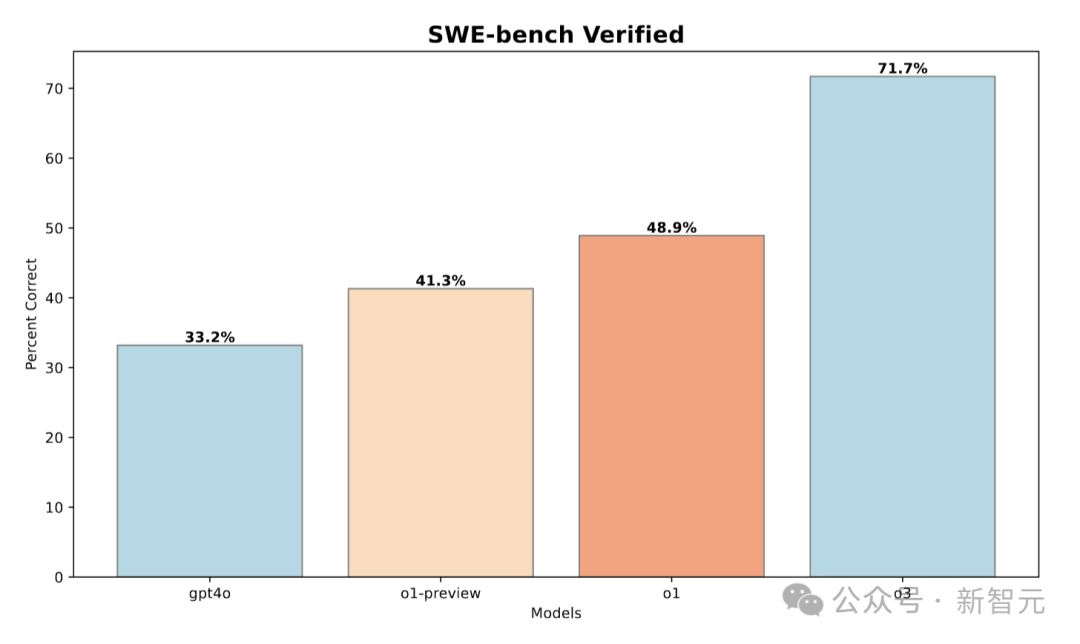
這些結(jié)果說明,LLM的強(qiáng)大推理能力不僅在編程競賽中表現(xiàn)出色,在實(shí)際的軟件工程任務(wù)中同樣具有重要價(jià)值。
思維鏈推理對于提升編碼任務(wù)的性能有巨大威力。
從CodeForces和IOI等編程競賽基準(zhǔn)測試,到SWE-bench和Astra等復(fù)雜的軟件工程挑戰(zhàn),增加強(qiáng)化學(xué)習(xí)訓(xùn)練計(jì)算量和測試時(shí)計(jì)算量,能持續(xù)推動(dòng)模型性能提升,使其接近甚至超越世界頂尖人類選手的水平。