近端策略優(yōu)化(PPO)算法的理論基礎(chǔ)與PyTorch代碼詳解
近端策略優(yōu)化(Proximal Policy Optimization, PPO)算法作為一種高效的策略優(yōu)化方法,在深度強(qiáng)化學(xué)習(xí)領(lǐng)域獲得了廣泛應(yīng)用。特別是在大語言模型(LLM)的人類反饋強(qiáng)化學(xué)習(xí)(RLHF)過程中,PPO扮演著核心角色。本文將深入探討PPO的基本原理和實(shí)現(xiàn)細(xì)節(jié)。
PPO屬于在線策略梯度方法的范疇。其基礎(chǔ)形式可以用帶有優(yōu)勢函數(shù)的策略梯度表達(dá)式來描述:

策略梯度的基礎(chǔ)表達(dá)式(包含優(yōu)勢函數(shù))。
這個(gè)表達(dá)式實(shí)際上構(gòu)成了優(yōu)勢演員-評(píng)論家(Advantage Actor-Critic)方法的基礎(chǔ)目標(biāo)函數(shù)。PPO算法可以視為對(duì)該方法的一種改進(jìn)和優(yōu)化。
PPO算法的損失函數(shù)設(shè)計(jì)
PPO通過引入策略更新約束機(jī)制來提升訓(xùn)練穩(wěn)定性。這種機(jī)制很好地平衡了更新幅度:過大的策略更新可能導(dǎo)致訓(xùn)練偏離優(yōu)化方向,而過小的更新則可能降低訓(xùn)練效率。為此,PPO采用了一個(gè)特殊的替代目標(biāo)函數(shù),該函數(shù)由裁剪項(xiàng)和非裁剪項(xiàng)組成,并取兩者的最小值。
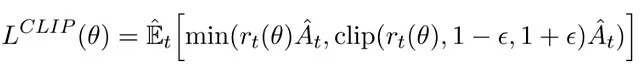
PPO的損失函數(shù)結(jié)構(gòu)。
替代損失函數(shù)的非裁剪部分分析
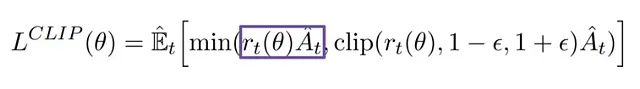
損失函數(shù)中的非裁剪部分示意圖。
在PPO中,比率函數(shù)定義為在狀態(tài)st下執(zhí)行動(dòng)作at時(shí),當(dāng)前策略與舊策略的概率比值。
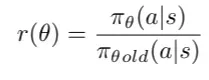
策略概率比率r(θ)的定義。
這個(gè)比率函數(shù)r(θ)為我們提供了一個(gè)度量新舊策略差異的有效工具,它可以替代傳統(tǒng)策略梯度目標(biāo)函數(shù)中的對(duì)數(shù)概率項(xiàng)。非裁剪部分的損失通過將此比率與優(yōu)勢函數(shù)相乘得到。

非裁剪部分損失計(jì)算示意圖。
替代損失函數(shù)的裁剪機(jī)制
為了防止過大的策略更新,PPO引入了裁剪機(jī)制,將策略比率r(θ)限制在[1-?, 1+?]的區(qū)間內(nèi)。其中?是一個(gè)重要的超參數(shù),在PPO的原始論文中設(shè)定為0.2。這樣,我們可以得到完整的PPO目標(biāo)函數(shù):

PPO完整目標(biāo)函數(shù),包含非裁剪項(xiàng)和裁剪項(xiàng)。
PPO的最終優(yōu)化目標(biāo)是在這兩部分中取較小值,從而實(shí)現(xiàn)穩(wěn)定的策略優(yōu)化。
算法實(shí)現(xiàn)流程
1. 系統(tǒng)初始化
a. 設(shè)置隨機(jī)種子
b. 初始化演員網(wǎng)絡(luò)與評(píng)論家網(wǎng)絡(luò)的優(yōu)化器
c. 配置損失追蹤器和獎(jiǎng)勵(lì)記錄器
d. 加載超參數(shù)配置
2. 訓(xùn)練回合迭代
a. 環(huán)境重置
b. 回合內(nèi)循環(huán):
i. 通過演員網(wǎng)絡(luò)預(yù)測動(dòng)作概率分布并采樣
ii. 記錄動(dòng)作的對(duì)數(shù)概率(作為old policy的參考)
iii. 執(zhí)行環(huán)境交互,獲取轉(zhuǎn)移數(shù)據(jù)
c. 計(jì)算衰減回報(bào)
d. 存儲(chǔ)回合經(jīng)驗(yàn)數(shù)據(jù)
e. 按更新頻率執(zhí)行網(wǎng)絡(luò)優(yōu)化:
i. 評(píng)估狀態(tài)價(jià)值
ii. 計(jì)算優(yōu)勢估計(jì)
iii. 構(gòu)建PPO損失函數(shù)
iv. 執(zhí)行梯度優(yōu)化
3. 訓(xùn)練監(jiān)控
a. 記錄并可視化平均損失指標(biāo)PyTorch實(shí)現(xiàn)詳解
1、初始化
torch.manual_seed(self.cfg['train']['random_seed'])
actor_optim = optim.Adam(self.actor.parameters(), lr=self.cfg['train']['lr'], betas=self.cfg['train']['betas'])
critic_optim = optim.Adam(self.critic.parameters(), lr=self.cfg['train']['lr'], betas=self.cfg['train']['betas'])
avg_actor_losses = []
avg_critic_losses = []
actor_losses = []
critic_losses = []
eps = np.finfo(np.float32).eps.item()
batch_data = []2、回合循環(huán)
2.1 重置環(huán)境
for episode in range(self.cfg['train']['n_epidode']):
rewards = []
log_probs = []
actions = []
states = []
state_values = []
self.actor.train()
self.critic.train()
terminated, truncated = False, False # 初始化終止和截?cái)鄻?biāo)志
state, info = self.env.reset()
# 轉(zhuǎn)換為張量
state = torch.FloatTensor(state).to(self.device)2.2 當(dāng)回合未結(jié)束時(shí):
timesteps = 0
# 遍歷時(shí)間步
while not terminated and not truncated:
timesteps += 1演員預(yù)測動(dòng)作概率并從分布中采樣動(dòng)作。
# 演員層輸出動(dòng)作概率,因?yàn)檠輪T神經(jīng)網(wǎng)絡(luò)在輸出層有softmax
action_prob = self.actor(state)
# 我們知道我們不直接使用分類交叉熵?fù)p失函數(shù),而是手動(dòng)構(gòu)建以獲得更多控制。
# PyTorch中的分類交叉熵?fù)p失函數(shù)使用softmax將logits轉(zhuǎn)換為概率到分類分布,
# 然后計(jì)算損失。所以通常不需要顯式地將softmax函數(shù)添加到神經(jīng)網(wǎng)絡(luò)中。在這項(xiàng)工作中,
# 我們?cè)谏窠?jīng)網(wǎng)絡(luò)上添加softmax層并計(jì)算分類分布。
# categorical函數(shù)可以從softmax概率或從logits(輸出中沒有softmax層)生成分類分布,
# 將logits作為屬性
action_dist= Categorical(action_prob)
# 采樣動(dòng)作
action = action_dist.sample()
actions.append(action)獲取對(duì)數(shù)概率,這被視為比率的log pi_theta_old
# 獲取對(duì)數(shù)概率以得到log pi_theta_old(a|s)并保存到列表中
log_probs.append(action_dist.log_prob(action))在環(huán)境中執(zhí)行動(dòng)作,獲取下一個(gè)狀態(tài)、獎(jiǎng)勵(lì)和終止標(biāo)志。
# 動(dòng)作必須從張量轉(zhuǎn)換為numpy以供環(huán)境處理
next_state, reward, terminated, truncated, info = self.env.step(action.item())
rewards.append(reward)
# 將下一個(gè)狀態(tài)分配為當(dāng)前狀態(tài)
state = torch.FloatTensor(next_state).to(self.device)2.3 計(jì)算折扣回報(bào)
R = 0
returns = [] # 用于保存真實(shí)值的列表
# 使用環(huán)境在回合中返回的獎(jiǎng)勵(lì)計(jì)算每個(gè)回合的回報(bào)
for r in rewards[::-1]:
# 計(jì)算折扣值
R = r + self.cfg['train']['gamma'] * R
returns.insert(0, R)
returns = torch.tensor(returns).to(self.device)
returns = (returns - returns.mean()) / (returns.std() + eps)2.4 將每個(gè)回合的經(jīng)驗(yàn)存儲(chǔ)在batch_data中
# 存儲(chǔ)數(shù)據(jù)
batch_data.append([states, actions, returns, log_probs, state_values])2.5 每update_freq回合更新網(wǎng)絡(luò):
if episode != 0 and episode%self.cfg['train']['update_freq'] == 0:
# 這是我們更新網(wǎng)絡(luò)一些n個(gè)epoch的循環(huán)。這個(gè)額外的for循環(huán)
# 改善了訓(xùn)練效果
for _ in range(5):
for states_b, actions_b, returns_b, old_log_probs, old_state_values in batch_data:
# 將列表轉(zhuǎn)換為張量
old_states = torch.stack(states_b, dim=0).detach()
old_actions = torch.stack(actions_b, dim=0).detach()
old_log_probs = torch.stack(old_log_probs, dim=0).detach()計(jì)算狀態(tài)值
state_values = self.critic(old_states)計(jì)算優(yōu)勢。
# 計(jì)算優(yōu)勢
advantages = returns_b.detach() - state_values.detach()
# 規(guī)范化優(yōu)勢在理論上不是必需的,但在實(shí)踐中它降低了我們優(yōu)勢的方差,
# 使收斂更加穩(wěn)定和快速。我添加這個(gè)是因?yàn)? # 解決一些環(huán)境問題如果沒有它會(huì)太不穩(wěn)定。
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-10)計(jì)算演員和評(píng)論家的PPO損失。
# 現(xiàn)在我們需要計(jì)算比率(pi_theta / pi_theta__old)。為了做到這一點(diǎn),
# 我們需要從存儲(chǔ)的狀態(tài)中獲取所采取動(dòng)作的舊策略,并計(jì)算相同動(dòng)作的新策略
# 演員層輸出動(dòng)作概率,因?yàn)檠輪T神經(jīng)網(wǎng)絡(luò)在輸出層有softmax
action_probs = self.actor(old_states)
dist = Categorical(action_probs)
new_log_probs = dist.log_prob(old_actions)
# 因?yàn)槲覀內(nèi)?duì)數(shù),所以我們可以用減法代替除法。然后取指數(shù)將得到與除法相同的結(jié)果
ratios = torch.exp(new_log_probs - old_log_probs)
# 替代損失函數(shù)的非裁剪部分
surr1 = ratios * advantages
# 替代損失函數(shù)的裁剪部分
surr2 = torch.clamp(ratios, 1 - self.cfg['train']['clip_param'], 1 + self.cfg['train']['clip_param']) * advantages
# 更新演員網(wǎng)絡(luò):loss = min(surr1, surr2)
actor_loss = -torch.min(surr1, surr2).mean()
actor_losses.append(actor_loss.item())
# 使用Huber損失計(jì)算評(píng)論家(價(jià)值)損失
# Huber損失對(duì)數(shù)據(jù)中的異常值比平方誤差損失更不敏感。在基于價(jià)值的RL設(shè)置中,
# 推薦使用Huber損失。
# Smooth L1損失與HuberLoss密切相關(guān)
critic_loss = F.smooth_l1_loss(state_values, returns_b.unsqueeze(1)) #F.huber_loss(state_value, torch.tensor([R]))
critic_losses.append(critic_loss.item())使用梯度下降更新網(wǎng)絡(luò)
actor_optim.zero_grad()
critic_optim.zero_grad()
# 執(zhí)行反向傳播
actor_loss.backward()
critic_loss.backward()
# 執(zhí)行優(yōu)化
actor_optim.step()
critic_optim.step()