













SFT并非必需!推理模型僅靠RL就能獲得長思維鏈能力,清華CMU團隊破解黑盒
DeepSeek-R1慢思考、長推理的表現,展現了訓練步驟增加,會導致長CoT的涌現。
它通過模擬人類思維逐步推導答案,提升了AI大模型的推理能力和可解釋性。
但長CoT的觸發條件是什么?怎么做能優化它?像個黑盒,還沒研究明白。
來自清華、CMU和IN.AI的研究團隊,近期專門探究了長CoT在大模型中的工作機制和優化策略。

先把該研究得出的4點發現給大家呈上來:
- SFT并非必需,但能簡化訓練并提高效率;
- 推理能力隨著訓練計算的增加而出現,但并非總是如此;
- 可驗證獎勵函數對增長CoT至關重要;
- 糾錯等核心能力基礎模型天生自帶,但通過RL有效地激勵這些技能需要大量的計算。
這篇論文開始被網友瘋轉,并被感慨道:這可太酷啦!
還有網友表示,不出所料,獎勵函數果然很重要~

從SFT和RL兩方面研究長CoT
研究團隊明確表示:
我們的目標是揭開大模型中長CoT推理的神秘面紗。
通過系統分析和消融,提取關鍵見解,并提供實用策略來增強和穩定其性能。

團隊采用了2款基礎模型:
- Llama-3.1-8B:來自Meta,是具有代表性的通用模型。
- Qwen2.5-7B-Math:來自阿里通義,是具有代表性的數學專業模型。
同時采用了4個代表性推理基準:
MATH-500、AIME 2024、TheoremQA和MMLU-Pro-1k。
默認情況下,溫度t=0.7、頂部?p值=0.95,最大輸出長度=16384 tokens。
而具體過程,從SFT(監督微調)和RL(強化學習)兩方面下手。
研究人員默認使用MATH的7500個訓練樣本提示集來提供可驗證的真值答案。
SFT對長CoT的影響
團隊首先探究了SFT對長CoT的影響。
通過在長CoT數據上進行SFT,模型能夠學習到更復雜的推理模式。
但目前而言,短CoT更為常見,這就意味著針對其收集SFT數據相對簡單。
鑒于此,團隊選擇用阿里通義的QwQ-32B-Preview來提煉長CoT,用阿里通義的Qwen2.5-Math-72B-Struct來提煉短CoT。
具體來說,研究人員先對每個prompt的N個候選響應進行采樣,然后篩選出具有正確答案的響應。
對于長CoT,使用N∈{32, 64, 128, 192, 256};對于短CoT,使用N∈{32, 64, 128, 256},(此處為了提高效率跳過了一個N)。
在每種情況下, SFT標記的數量都與N成正比。
如下圖虛線所示,隨著擴大SFT的token,對長CoT進行SFT,會繼續提高模型準確性;而對短CoT來說,SFT帶來的效益在很早就達到飽和。
譬如在MATH-500上,長CoT SFT的準確率超過70%,tokens達到3.5B時仍然沒有進入瓶頸期。
相比之下,短CoT SFT的tokens從約0.25B增加到1.5B,準確率僅產生了3%的增長。

實驗結果顯示,長CoT SFT能夠顯著提高模型的性能上限。
而且,在達到更高性能的同時,還有比短CoT更高的性能拓展空間。
RL對長CoT的影響
由于業內普遍認為RL的上限高于SFT,團隊將長CoT和短CoT視為針對RL的不同SFT初始化方法進行比較。
研究人員使用SFT檢查點來初始化RL,并訓練了四個epoch,每個prompt生成四個響應。
此外,團隊把PPO和來自MATH數據集的基于規則的驗證器訓練拆分,作為RL的提示集。
具體結果同樣在下圖中顯示出來:
圖中實線和虛線之間的間隙表明,使用長CoT SFT初始化的模型通常可以通過RL進一步顯著改進,而使用短CoT SFT初始化的模型從RL中獲得的收益很小。
例如,在MATH-500上,RL可以將長CoT SFT模型絕對改進3%以上,而短CoT SFT模型在RL前后的精度幾乎相同。

需要注意的是,RL并不總是能夠穩定地擴展思維鏈的長度和復雜性。
為此,研究團隊引入了一種帶有重復懲罰的余弦長度縮放獎勵機制,有效穩定了思維鏈的增長,并鼓勵模型在推理過程中進行分支和回溯。
整理長CoT數據
除上述研究外,為了整理長CoT數據,研究團隊比較了兩種方法。
一種是通過提示短CoT模型,生成原始動作,并按順序組合它們,以此構建長CoT軌跡。
另一種是從現有的長CoT模型中提煉出長CoT軌跡——這些模型表現出涌現長CoT(emergent long CoT)。
結果表明,從涌現長CoT模式中提煉出來的模型,比構建的模式泛化得更好,并且可以用RL進一步顯著改進。
在構建模式上訓練的模型則不能做到這一點。
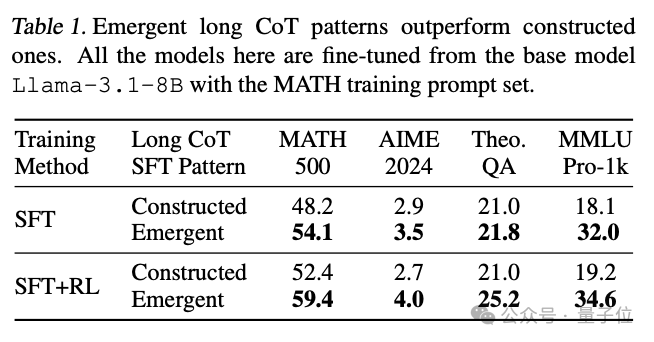
此外,由于DeepSeek-R1已經證明,在基礎模型上擴展RL計算可以出現長CoT,自我驗證行為有時會被模型的探索標記為緊急行為或 “頓悟時刻”。
這種模式在短CoT數據中很少見,但研究人員注意到,有時基座模型已經存在自我驗證行為,而用RL強化這些行為需要嚴苛的條件。
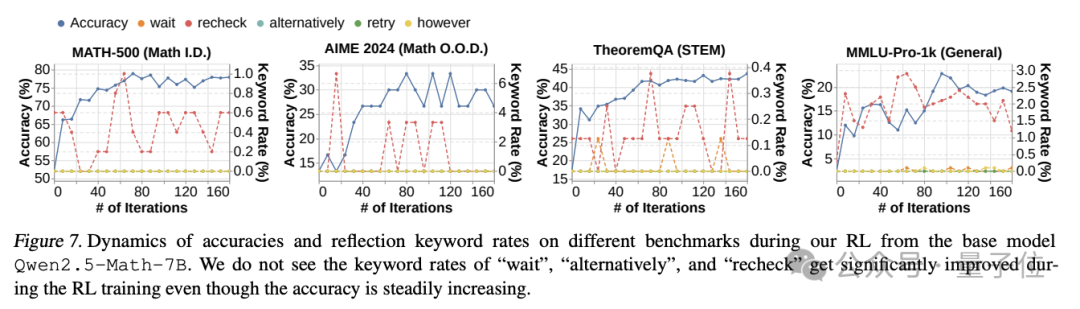
如下圖所示,Qwen2.5Math-7B的RL有效地提高了準確性,但沒有增加基礎模型輸出中存在的 “recheck” 模式的頻率,也沒有有效地激勵其他反射模式,如 “retry” 和 “alternatively”。
這表明盡管提高性能效果顯著,但來自基座模型的RL不一定會激勵反射模式。
四個關鍵發現
在系統性研究了長CoT推理的機制后,團隊提出了4個關鍵發現。
第一,SFT并非必需,但能簡化訓練并提高效率。
雖然SFT并非訓練長CoT的必要條件,但它能夠有效地初始化模型,并為后續的RL訓練提供堅實的基礎。
第二,推理能力隨著訓練計算的增加而出現,但并非總是如此。
長CoT的出現并非必然,且樸素的RL方法并不總是能有效地延長CoT長度。
需要通過獎勵塑造等技巧來穩定CoT長度的增長,團隊的做法是引入了一種余弦長度縮放獎勵,并加入了重復懲罰,這既平衡了推理深度,又防止了無意義的長度增加。
第三,可驗證獎勵函數對CoT擴展至關重要。
由于高質量、可驗證數據稀缺,擴展可驗證獎勵函數對RL至關重要。
論文探索了利用網絡提取的包含噪聲解決方案的數據,并發現這種“銀色”監督信號在RL中展現出巨大的潛力,尤其是在處理OOO任務(如STEM推理)時。
第四,基模型中天生存在錯誤修正和回溯等技能,但通過RL有效地激勵這些技能需要大量的計算。
而測量這些能力的出現需要更精細的方法,需要謹慎設計RL激勵。
最后,研究團隊提出了幾個未來的研究方向,包括:
擴大模型規模、改進RL基礎設施、探索更有效的驗證信號以及深入分析基礎模型中的潛在能力。
這些方向有望進一步推動長CoT在大模型中的應用。





























