













自定義訓練的 YOLOv8 模型進行郵票整理
還記得人們過去常常寄信和明信片的日子嗎?明信片上通常描繪了你所訪問的城市或國家的一些風景如畫的景色,但對許多人來說,郵票才是主要的吸引力。它們被視為微型藝術品,被認為是非常值得收藏的。
由于每張明信片、信封、包裹和郵包都需要郵票,許多人最終擁有了大量的郵票收藏。這變成了一個計算機視覺項目:我沒有一張一張地拍攝每張郵票的照片,而是拍攝了郵票相冊的每一頁,并使用目標檢測來找到并存儲圖片中所有郵票的圖像。

目標檢測
由于我之前沒有嘗試過目標檢測(只做過圖像分類),我花了一些時間尋找完成這項任務的最佳方法。我在Roboflow上發現了一個類似的項目[1],并能夠在線測試一些我自己的圖像,使用已經在一個郵票數據集上訓練過的YOLOv8模型。然而,我無法讓模型在我自己的機器上本地運行,所以我決定使用Ultralytics的YOLOv8模型訓練自己的模型。下圖展示了我自定義訓練的YOLOv8目標檢測模型如何處理一張包含57張意大利郵票的圖片。

使用自定義訓練的YOLOv8模型進行郵票檢測
每張檢測到的郵票也自動保存為單獨的裁剪圖像文件,其中一些如下所示。



自動裁剪并保存的單個郵票圖像
在自定義數據集上訓練YOLO
加載一個YOLO模型(使用COCO數據集的預訓練權重)并在你自己的機器上使用自定義數據集進行訓練并不困難。一旦創建了虛擬環境并安裝了所需的Python庫(例如pytorch、ultralytics),實際的訓練和推理只需要幾行代碼。
困難的部分可能是獲取足夠大的標注數據集。在我的情況下,我很幸運地在網上找到了一個已經標注并已轉換為YOLOv8格式的郵票數據集[1]。如果你必須制作自己的數據集來讓YOLO檢測不屬于其開箱即用的80個類別之一的東西,Roboflow和CVAT提供了注釋工具,你可以使用它們來完成這項工作。
一旦數據集準備好并保存在本地文件夾中,可以使用config.yaml文件提供模型訓練、驗證和測試所需的類標簽和路徑。我的config.yaml文件如下所示:
path: /home/username/venv_folder/venv_name/yolov8-project/ # absolute path to dataset
test: test/images # relative path to test images
train: train/images # relative path to training images
val: val/images # relative path to validation images
# classes
names:
0: postage-stamp使用自定義數據集訓練YOLOv8所需的Python代碼如下所示。建議使用GPU,并在訓練前檢查其可用性。
import torch, ultralytics
# Check library versions
print("PyTorch version:", torch.__version__)
print("Ultralytics version:", ultralytics.__version__)
# Check if GPU is available
if torch.cuda.is_available():
print(f"GPU is available: {torch.cuda.get_device_name(0)}")
else:
print("GPU is not available")
在訓練之前,加載帶有預訓練權重的YOLOv8模型。模型名稱末尾的字母(yolov8n.pt)可用于選擇模型大小。字母n表示最小且最快的模型,具有最少的可訓練參數,但如果需要更高的精度且速度不是關鍵,你可以選擇另一個模型(n,s,m,l,x)[2]。
from ultralytics import YOLO
# Load model with pretrained weights (recommended)
model = YOLO("yolov8n.pt")
# Optionally load a model without pretrained weights
# model = YOLO("yolov8n.yaml")
# You can also try yolo11n
# model = YOLO("yolo11n.pt")
# Train model
model.train(data="config.yaml", epochs=100, patience=10)訓練完成后,會生成一個runs/detect/train/文件夾,其中包含許多有用的信息,如訓練/驗證指標和混淆矩陣,因此請務必查看它們以更好地了解模型性能。
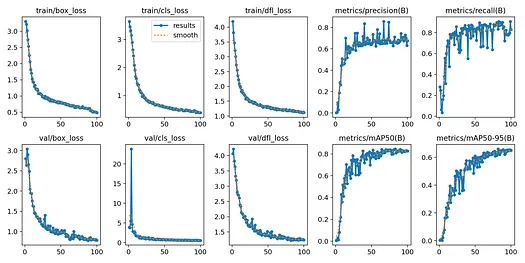
YOLOv8訓練指標
要使用自定義訓練的模型從新圖像中檢測對象,請從runs/detect/train/weights文件夾加載它。你可以選擇best.pt或last.pt,前者是得分最高的模型,后者是最后一個epoch訓練的模型。
# Load the trained YOLO model
model = YOLO("/home/username/venv_folder/venv_name/runs/detect/train/weights/best.pt")
# Specify folder containing images for object detection
image_folder = "/home/username/venv_folder/venv_name/images"
# Perform object detection on every image in specified folder
results = model(
source=image_folder,
show=False, # Set to True if you want to display the image
cnotallow=0.60, # Confidence threshold
save=True, # Save results
save_txt=True, # Save results as text files
save_cnotallow=True, # Save confidence scores
line_width=3, # Adjust line width for bounding boxes
save_crop=True # Save cropped detections as image files
)由于每張圖像的目標檢測結果都保存到單獨的文本文件中,你可以使用pandas讀取所有這些文件以獲取檢測到的對象總數。結果文件還包含每個檢測的類別、x_center、y_center、寬度和高度,這些數據可能對進一步分析有用。
import os
import pandas as pd
# Path to folder containing result text files
folder_path = "/home/username/venv_folder/venv_name/runs/detect/predict/labels"
# Empty list to store data from each file
dataframes = []
# Define column names
column_names = ["class", "x_center", "y_center", "width", "height", "confidence"]
# Iterate over all result files in the folder
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
df = pd.read_csv(file_path, delimiter=' ', header=None, names=column_names,)
df['filename'] = filename # Add column to record filename of each result
dataframes.append(df) # Append results to dataframes list
# Combine all into a single DataFrame
combined_df = pd.concat(dataframes, ignore_index=True)
# Check the top five rows of the DataFrame
display(combined_df.head(5))
# Count number of rows in DataFrame
num_rows = combined_df.shape[0]
print(f"Number of detected stamps: {num_rows}")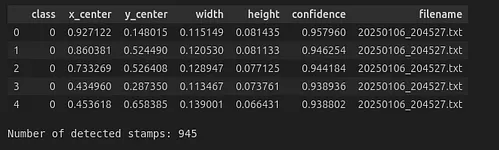
檢測結果的DataFrame(前五行)和檢測到的對象計數
人臉檢測
現在,收藏中每張郵票的圖像都已保存(在我的情況下總共945張圖像),如何搜索其中包含人臉的郵票呢?沒問題,使用人臉數據集訓練新模型并再次運行目標檢測。



使用人臉數據集訓練的YOLOv8n檢測郵票中的人臉
一些看起來更像卡通的人臉沒有被檢測到,因為訓練數據由實際人臉的圖片組成。需要進一步調整以獲得更好的性能,但希望我能夠展示使用自定義數據集訓練YOLO檢測任何對象是多么容易。
參考資料
- [1] https://universe.roboflow.com/jackwildgooglecom/detect-postage-stamp
- [2] https://docs.ultralytics.com/models/yolov8/#supported-tasks-and-modes





























