













AAAI 2025 | 大模型會組合關系推理嗎?打開黑盒,窺探Transformer腦回路
本文作者為北京郵電大學網絡空間安全學院碩士研究生倪睿康,指導老師為肖達副教授。主要研究方向包括自然語言處理、模型可解釋性。該工作為倪睿康在彩云科技實習期間完成。聯系郵箱:ni@bupt.edu.cn, xiaoda99@bupt.edu.cn
人類擁有一種強大的能力,能夠理解多個實體之間復雜的關系并基于這些關系進行推理,這被稱為組合關系推理(Compositional Relational Reasoning, CRR)。這種能力不僅是智能的標志,也是我們應對日常問題和復雜任務的核心技能。那么,像 GPT 這樣的大型語言模型(LLM)是否具備這種能力?它們又是如何在內部處理這種任務的?為了回答這個問題,研究者開發了一個新的基準測試,稱為廣義關聯回憶(Generalized Associative Recall, GAR),專門用來評估 LLM 在組合推理任務中的表現,并進一步研究模型如何解決這些任務。論文《Benchmarking and Understanding Compositional Relational Reasoning of LLMs》已被 AAAI 2025 接收。本工作由北京郵電大學和彩云科技合作完成。

- 論文地址:https://arxiv.org/abs/2412.12841
- 代碼地址:https://github.com/Caiyun-AI/GAR
GAR 基準測試
研究者注意到,目前大多數用于測試 LLM 的任務要么過于簡單,只能用于可解釋性分析,無法真實反映模型在復雜推理場景下的表現,要么過于復雜,不適合深入研究模型的內部機制。因此,他們設計了 GAR,一個更加多樣化和具有挑戰性的基準測試。GAR 整合了多個經典任務(如 knowledge recall、associate recall、Indirect Object Identification (IOI) 等),并通過不同的任務形式(如肯定 / 否定句、生成 / 分類任務)和難度等級,系統地考察模型的推理能力。
簡單來講(更多例子見下圖 1 和圖 2):
- associate recall 就是從前文 “抄寫”:前文說了 “小明有蘋果”,后文再說 “小明有__”,就知道要填 “蘋果”;
- knowledge recall 就是記到 “腦子” 里的各種常識知識:蘋果是一種__(水果),巴黎在__(法國)
- IOI 就是排除(否定):【蘋果、狗、蘋果】哪個不是蘋果?__(狗)
GAR 的特點是:
1. 挑戰性足夠高:即使是最先進的 LLM,在 GAR 任務上的表現也并不理想,暴露了它們在組合推理能力上的缺陷。
2. 適合深入研究:GAR 任務相對簡單的生成過程,使得研究者能夠更好地追蹤模型內部的推理機制。
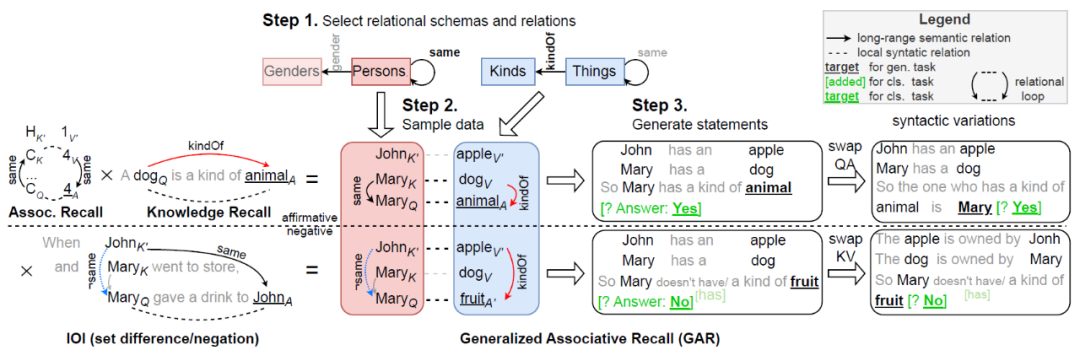
圖 1 廣義關聯回憶(Generalized Associative Recall, GAR)任務構建框架。GAR 任務的設計流程包括三個步驟:選擇關系模式(如 “same” 或 “kindOf”)、采樣數據構建關系環(結合語義與語法關系)以及生成語句并引入語義和句法變體(如否定形式或主賓交換),圖中左中右部分分別展示了關系環的構建、任務數據的生成與語句的多樣化處理,體現了 GAR 在任務靈活性和復雜度上的優勢

圖 2 GAR 任務示例。任務分為兩大類:生成式(填空題,補全最后一個詞)和判別式(判斷題,回答 Yes 或 No)
現有模型的表現
通過對主流開源(如 Llama-2/3 7B/13B/33B/70B)和閉源模型(如 GPT-3.5/4)的測試發現:
- 任務難度顯著影響表現:當任務的推理步驟或復雜度增加時,模型的正確率會明顯下降。
- “組合性差距(Compositionality Gap)”:模型在回答任務的各個子問題時可能表現良好,但無法正確組合這些答案以得出最終結論。例如,模型能回答對 “【小明有蘋果,小紅有狗】小明有__(蘋果)”(前文抄寫),對 “蘋果是一種__(水果)”(常識)和 “【小明、小紅】里哪個不是小紅?__(小明)”(否定排除)也毫無壓力,但把它們組合起來:“【小明有蘋果,小紅有狗】小紅沒有一種__(水果)”,模型就很容易蒙圈(在不允許 CoT 的情況下)。
- 模型規模與性能:雖然更大的模型在一些任務上表現更好,但它們的 “組合性差距” 往往更明顯,這表明增加模型規模并不能完全解決這個問題。
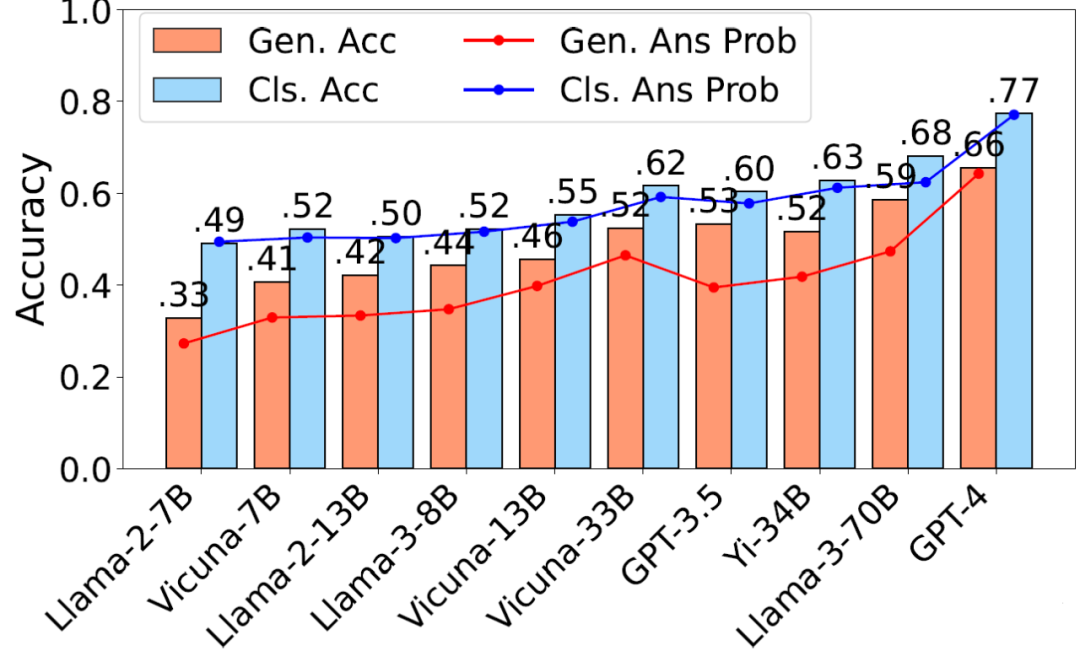
圖 3 (a) 不同 LLM 在 GAR 上的表現。本圖比較了生成任務(Gen.)和分類任務(Cls.)的平均準確率和正確答案的預測概率,隨著模型規模增大,準確率和答案概率均呈正相關增長

圖 3 (b 左) GPT-4 和 Vicuna-33B 在不同難度的生成式任務上的表現,通過增加非相同語義關系和引入否定語義變體調整任務難度;(c 中) 組合性差距隨模型規模的變化, Llama 系列模型隨規模增大而表現出更大的組合性差距,反映出 LLM 在組合關系推理中的不足;(d 右) 語法變化差距隨模型規模的變化,句法變體對模型性能影響較小,表明模型對語法變化的敏感性較低
GAR 任務還有個很有趣的特點:盡管它對最先進的 LLM 都具有挑戰性,它對人類來說卻非常簡單:研究者評估,在具備必要知識(如國家 - 首都關系)的情況下,人類完成任務的準確率超過 90%。并且通過實驗表明,LLM 回答錯誤并不是因為缺少這些事實性知識。這揭示了 LLM 在組合關系推理上存在某些根本性缺陷。
模型內部的推理機制
為了更好地理解 LLM 如何解決 GAR 任務,研究者采用了歸因補丁(attribution patching)的方法。這種技術可以幫助發現模型在推理過程中依賴的關鍵計算單元,特別是某些注意力頭的作用。值得指出的是,這里無論任務難度、回路復雜度還是模型大小,都遠超已有模型可解釋性工作。研究發現:
- 核心回路:Vicuna-33B 模型中存在一組通用的核心回路,能夠被不同任務重復利用。
- 注意力頭的作用:研究者識別出兩類關鍵注意力頭(True head 和 False head),它們的激活狀態分別表示抽象的 “真” 和 “假” 的概念。進一步的實驗表明,這些頭在不同任務和模型中都扮演了重要角色,是組合推理能力的基礎。

圖 4 (a 左) True head 子回路 (b 右) False head 子回路
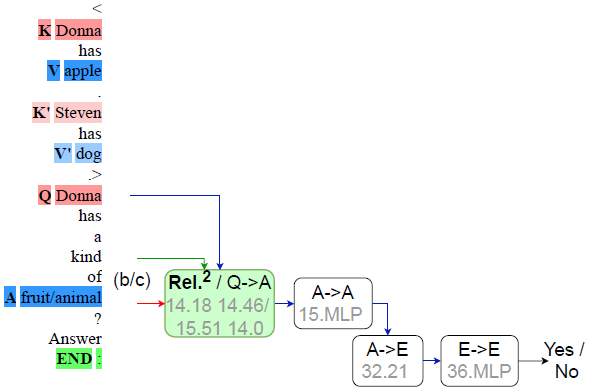
圖 4 (c) 判別回路

圖 4 (d) 肯定式生成回路
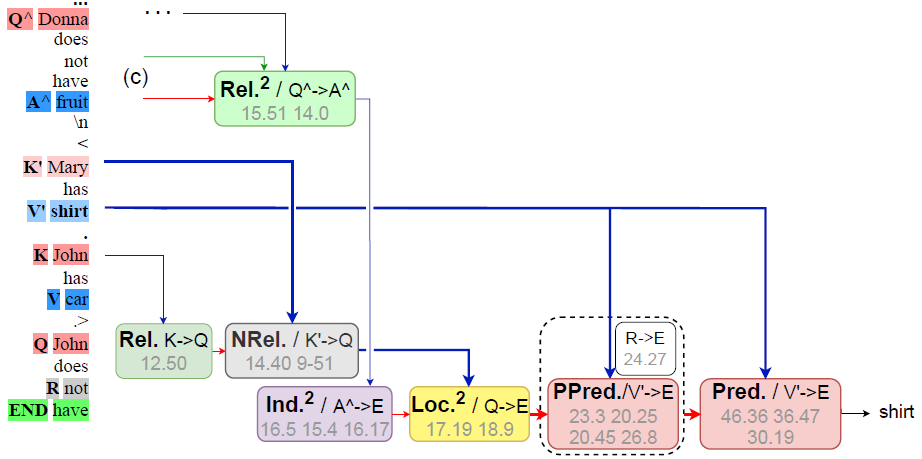
圖 4 (e) 否定式生成回路
研究者發現,無論哪種回路,從更高的層次看,都包含我們稱之為 “relational loop” 的由注意力邊組成的閉環。這和構造 GAR 任務時的關系環是一致的。研究者認為正是這些閉環的存在保證了可預測性。
通過干預關鍵注意力頭提升 LLM 表現
注意到 True/False 頭在圖 4 的所有回路中都有出現并扮演了關鍵角色。為了驗證 Vicuna 模型中的 True/False 頭的通用性和有效性,并探討其在不同模型規模上的一致性。研究者選擇了三個具有代表性的分類任務:由 GendersOfPersons 關系模式分別與 CountriesOfCities (CoC)、KindsOfThings (KoT) 和 UsagesOfThings (UoT) 三個關系模式組合作為數據源。首先,利用 attribution patching 識別不同規模的 Vicuna 模型(Vicuna-7B/13B/33B)的 True/False 頭。隨后,在模型推理過程中對 True/False 頭進行干預:當答案為 Yes/No 時,對 True/False 頭施加干預,同時屏蔽 False/True 頭,以觀察其對模型判斷的影響。
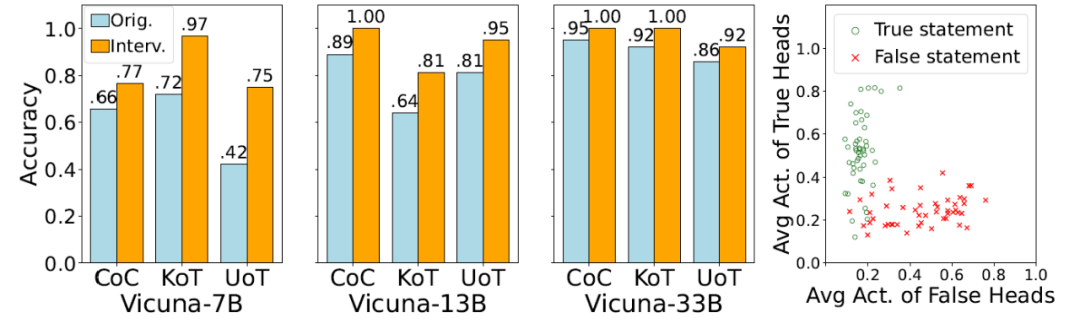
圖 5 (a 左) 干預 Vicuna-7B 的 True / False heads 提升判別任務的準確率,干預后模型準確率分別提高了 17%/14%/6%,證明 True/False 頭在各個模型中均表現出一致的效果;(b 右) True / False heads 的激活區分真 / 假陳述,通過可視化 True 和 False 頭的激活值,發現它們有效地區分了真假語句。這表明,True/False 頭編碼了真假概念,并在 GAR 任務中起到了判斷語句真偽的關鍵作用
研究意義
這項研究首次明確指出了 LLMs 在組合關系推理任務中的核心缺陷,并通過實驗揭示了模型內部的關鍵推理機制。這不僅加深了我們對 LLMs 工作原理的理解,也為模型改進提供了啟發和洞見。例如:
- 優化注意力機制:通過改進關鍵注意力頭的功能,可以顯著提升模型的推理能力,例如研究團隊的 DCFormer 工作 [1] 的最早期想法就是分析 LLM 在類似 GAR 任務上的表現啟發而來的。。
- 設計更具多樣性的基準:在真實世界任務中測試和改進模型的組合推理表現。





























