解讀 MySQL Explain 關(guān)鍵字:優(yōu)化查詢(xún)執(zhí)行計(jì)劃的實(shí)用指南
在MySQL數(shù)據(jù)庫(kù)中,優(yōu)化查詢(xún)性能是每個(gè)開(kāi)發(fā)人員和數(shù)據(jù)庫(kù)管理員都需要面對(duì)的重要挑戰(zhàn)之一。其中,EXPLAIN關(guān)鍵字是一個(gè)強(qiáng)大的工具,可以幫助我們深入了解MySQL是如何執(zhí)行查詢(xún)的,以及如何優(yōu)化查詢(xún)性能。
本文將深入探討MySQL中的EXPLAIN關(guān)鍵字,探究其背后的工作原理和輸出信息含義。通過(guò)本文的闡述,您將了解如何解讀EXPLAIN的輸出結(jié)果,優(yōu)化查詢(xún)執(zhí)行計(jì)劃,提升數(shù)據(jù)庫(kù)性能,以及避免常見(jiàn)的查詢(xún)性能陷阱。
無(wú)論您是初學(xué)者還是有經(jīng)驗(yàn)的數(shù)據(jù)庫(kù)專(zhuān)家,本文都將為您提供有價(jià)值的見(jiàn)解和實(shí)用的技巧,助您在MySQL數(shù)據(jù)庫(kù)中更好地利用EXPLAIN關(guān)鍵字,優(yōu)化查詢(xún)性能,提升數(shù)據(jù)庫(kù)應(yīng)用的效率和穩(wěn)定性。

詳解explain對(duì)應(yīng)關(guān)鍵字
通過(guò)explain關(guān)鍵字可以獲取我們給定查詢(xún)SQL經(jīng)由成本和規(guī)則優(yōu)化后的執(zhí)行計(jì)劃,通過(guò)這個(gè)計(jì)劃我們可以得到查詢(xún)語(yǔ)句實(shí)際的工作步驟,這里我們就針對(duì)這關(guān)鍵字得出的執(zhí)行計(jì)劃的每一列都進(jìn)行介紹。
為了更直觀的演示explain各個(gè)關(guān)鍵字段的信息,我們這里不妨通過(guò)兩張表針對(duì)每一種訪(fǎng)問(wèn)方式進(jìn)行講解,對(duì)應(yīng)數(shù)據(jù)表的DDL如下所示,可以看到筆者創(chuàng)建了一張s1表,其中:
- id作為主鍵。
- key1作為普通索引。
- key2是唯一索引。
- key_part1+key_part2+key_part3構(gòu)成唯一索引。
s2與s1結(jié)構(gòu)一致,這里就不多做介紹,對(duì)應(yīng)DDL語(yǔ)句如下所示:
CREATE TABLE s1
(
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1,key_part2,key_part3)
) Engine = InnoDB CHARSET = utf8;id字段
針對(duì)每一個(gè)select語(yǔ)句都會(huì)為其分配一個(gè)id字段,該id就代表的每一個(gè)select語(yǔ)句的執(zhí)行計(jì)劃信息。
我們先說(shuō)個(gè)簡(jiǎn)單的例子,針對(duì)下面這句單表執(zhí)行的語(yǔ)句,它就只有一行數(shù)據(jù),所以就只有一個(gè)id為1的執(zhí)行計(jì)劃:
explain select * FROM s1 WHERE s1.common_field =1;
我們?cè)賮?lái)一個(gè)union合并查詢(xún):
explain select * FROM s1 union select * from s2;從執(zhí)行計(jì)劃可以看到s1的id為1,s2的id為2,分別進(jìn)行了一個(gè)select查詢(xún):

需要注意的是連接查詢(xún)的驅(qū)動(dòng)表和被驅(qū)動(dòng)表的id都是一樣的,出現(xiàn)在前面的是驅(qū)動(dòng)表,而后面的就是被驅(qū)動(dòng)表:
explain select * from s1 inner join s2 on s1.id =s2.id ;從執(zhí)行計(jì)劃就可以看出,s1就是驅(qū)動(dòng)表,s2就是被驅(qū)動(dòng)表:

我們?cè)賮?lái)一個(gè)特殊的SQL,這句原本是子查詢(xún),正常情況下應(yīng)該是s1表的id為1,s2表的id為2:
explain select * FROM s1 where key1 in (select key3 from s2 );但是SQL優(yōu)化器經(jīng)過(guò)分析發(fā)現(xiàn)這句可以被優(yōu)化為連接查詢(xún),即下面這句SQL:
explain select * from s1 inner join s2 on s1.key1 =s2.key3 ;所以執(zhí)行計(jì)劃就顯示id是一樣的,且s1作為驅(qū)動(dòng)表,s2作為被驅(qū)動(dòng)表:

table字段
table字段含義比較簡(jiǎn)單,它表示當(dāng)前查詢(xún)計(jì)劃所針對(duì)的數(shù)據(jù)表,例如下面這個(gè)簡(jiǎn)單查詢(xún)語(yǔ)句:
explain select * FROM s1 WHERE s1.common_field =1;它所查詢(xún)的就是針對(duì)s1表:

而下面這句涉及連接查詢(xún),所以從執(zhí)行計(jì)劃中也能看出不同執(zhí)行計(jì)劃所針對(duì)的表:
explain select * from s1 inner join s2;可以看到驅(qū)動(dòng)表s1進(jìn)行全表掃描,而被驅(qū)動(dòng)表s2是通過(guò)hash join進(jìn)行連接查詢(xún):

select_type
select_type決定了你的SQL涉及的查詢(xún)類(lèi)型,常見(jiàn)的有:
(1) SIMPLE:簡(jiǎn)單查詢(xún),如下所示,可以看到簡(jiǎn)單的SQL語(yǔ)句就屬于這種查詢(xún)類(lèi)型
explain select * from s1對(duì)應(yīng)的執(zhí)行計(jì)劃如下所示:

(2) PRIMARY:涉及關(guān)聯(lián)或者子查詢(xún)的語(yǔ)句對(duì)應(yīng)左邊的語(yǔ)句就是PRIMARY,如下SQL所示,可以看到對(duì)應(yīng)的u表的查詢(xún)就可以作為PRIMARY語(yǔ)句:
explain select * FROM s1 union select * from s2;我們查看執(zhí)行計(jì)劃的截圖,可以看到涉及這種嵌套查詢(xún)的SQL左邊的SQL就是PRIMARY:

(3) UNION:從執(zhí)行計(jì)劃的截圖就可以看出union關(guān)鍵字后面的SQL就屬于union
explain select * FROM s1 union select * from s2;對(duì)應(yīng)執(zhí)行計(jì)劃如下圖所示:

(4) UNION RESULT:包含union的處理結(jié)果集,在union和union all語(yǔ)句中,基于其它查詢(xún)結(jié)果進(jìn)行合并(可能有去重的過(guò)程),需要通過(guò)一個(gè)臨時(shí)表才能完成的操作就是UNION RESULT也就是我們上述那句SQL的第三步。
(5) DEPENDENT SUBQUERY:如下SQL所示,在SQL優(yōu)化器明確指明子查詢(xún)無(wú)法轉(zhuǎn)為半連接查詢(xún)的情況下,第一個(gè)select的子查詢(xún)對(duì)應(yīng)的select type就是DEPENDENT SUBQUERY:
explain select * from s1 where s1.common_field in (SELECT id from s2 WHERE s1.common_field=s2.common_field) or key3='a';對(duì)應(yīng)的執(zhí)行計(jì)劃如下所示,可以看到s2的執(zhí)行類(lèi)型就是DEPENDENT SUBQUERY:

(6) DEPENDENT UNION:如下SQL所示,在涉及union的子查詢(xún)中有無(wú)數(shù)個(gè)小查詢(xún),除去union的左邊哪個(gè)小查詢(xún),其余的都是DEPENDENT UNION
explain select * from s1 WHERE key1 IN (SELECT key1 from s1 union SELECT key1 from s2)這一點(diǎn),從執(zhí)行計(jì)劃中就可以看出,子查詢(xún)內(nèi)部的s2查詢(xún)的類(lèi)型就是DEPENDENT UNION

(7) DERIVED:在FROM列表中包含的子查詢(xún)被標(biāo)記為DERIVED(衍生);MySQL會(huì)遞歸執(zhí)行這些子查詢(xún), 把結(jié)果放在臨時(shí)表里:
explain SELECT * from (select COUNT(*) from student as a) b對(duì)應(yīng)的我們可以在執(zhí)行計(jì)劃中印證這一點(diǎn):

type字段(重點(diǎn))
type決定了進(jìn)行SQL查詢(xún)的時(shí)的訪(fǎng)問(wèn)方法,該字段對(duì)于SQL執(zhí)行性能分析有著至關(guān)重要的參考價(jià)值:
(1) system:表中只有一行或者空表,即存儲(chǔ)引擎中統(tǒng)計(jì)的數(shù)據(jù)是正確的。
(2) const:基于聚簇索引或者非空的唯一二級(jí)索進(jìn)行定位數(shù)據(jù),時(shí)間復(fù)雜度為O(1),這種高速的常量級(jí)查詢(xún)我們就可以稱(chēng)為const:
explain select * FROM s1 WHERE id=1;對(duì)應(yīng)執(zhí)行計(jì)劃如下:

(3) eq_ref:該查詢(xún)意味著進(jìn)行關(guān)聯(lián)查詢(xún)時(shí),被驅(qū)動(dòng)表內(nèi)部走了聚簇索引或者非空的二級(jí)索引查詢(xún):
explain SELECT * FROM s1 inner join s2 on s1.id=s2.id;(4) ref:通過(guò)那些非唯一的二級(jí)索引進(jìn)行精準(zhǔn)定位,這種在二級(jí)索引區(qū)間構(gòu)成一個(gè)掃描區(qū)間進(jìn)行定位,然后再通過(guò)回表獲取所有數(shù)據(jù)的執(zhí)行就是ref:
explain select * from s1 WHERE key1='a';對(duì)應(yīng)的執(zhí)行計(jì)劃截圖如下圖所示:

(5) fulltext:全文匹配,大字符索引匹配。
(6) ref_or_null:基于普通二級(jí)索引查詢(xún)且查詢(xún)時(shí)還需要查詢(xún)可能為空的情況:
explain select * from s1 WHERE key1='a' or key1 is NULL ;(7) unique_subquery:即子查詢(xún)被優(yōu)化為exist,且子查詢(xún)返回的是聚簇索引:
explain select * from s1 where s1.common_field in (SELECT id from s2 WHERE s1.common_field=s2.common_field) or key3='a';(8) index_subquery:和上述查詢(xún)類(lèi)似,只不過(guò)子查詢(xún)內(nèi)部返回的是普通二級(jí)索引:
(9) range:范圍查詢(xún)。
(10) index_merge:索引合并,即進(jìn)行SQL查詢(xún)時(shí)對(duì)應(yīng)的條件都是索引類(lèi)型,SQL優(yōu)化器進(jìn)行查詢(xún)時(shí)讓兩個(gè)索引分別到自己的二級(jí)索引樹(shù)拿到有序的id集合然后取交集得到聚簇索引值進(jìn)行回表:
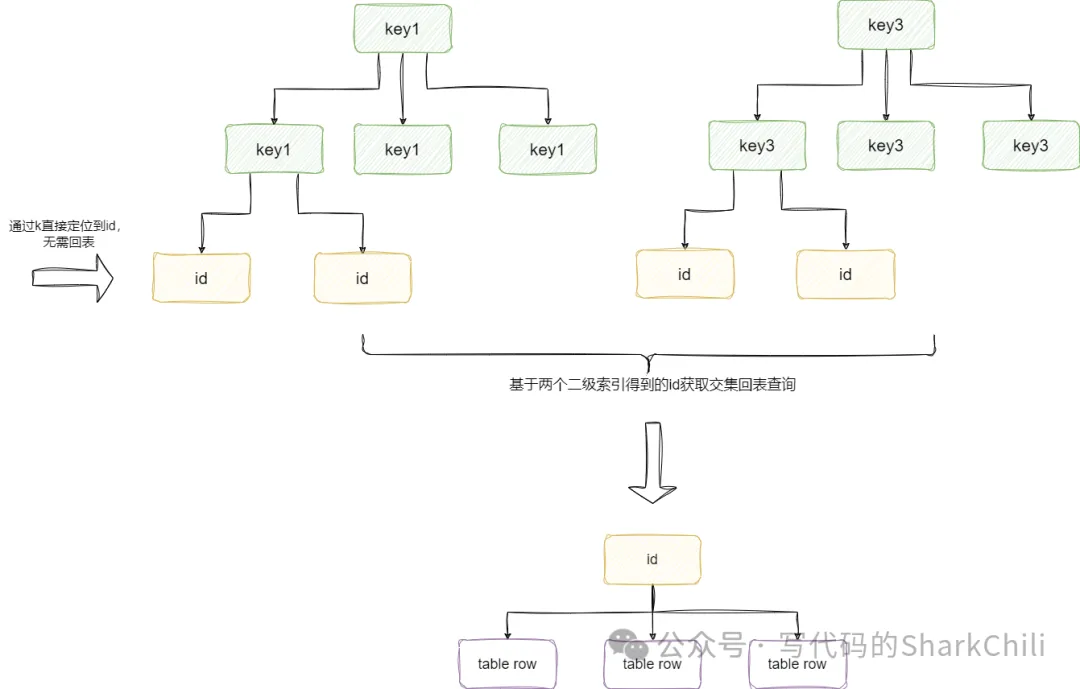
對(duì)飲的SQL如下,可以看到我們查詢(xún)條件都走了索引,查詢(xún)結(jié)果是基于多個(gè)索引的掃描區(qū)間共同構(gòu)成的聚簇索引,然后取并集進(jìn)行回表:
EXPLAIN select * FROM s1 WHERE KEY1='a' or key3='b'這一點(diǎn)我們可以通過(guò)查詢(xún)執(zhí)行計(jì)劃印證: +
(11) index:如下SQL所示,查詢(xún)時(shí)基于聯(lián)合索引,但不符合最左匹配原則,所以需要進(jìn)行全索引掃描匹配key_part2,但查詢(xún)時(shí)無(wú)需回表,這種基于二級(jí)索引全掃描但無(wú)需回表的訪(fǎng)問(wèn)方法就是index:
explain select s1.key_part1,s1.key_part2,s1.key_part3 from s1 WHERE key_part2='a';對(duì)應(yīng)執(zhí)行計(jì)劃如下圖所示:

(12) ALL:全表掃描。
extra
這個(gè)字段也很重要,它表示當(dāng)前SQL語(yǔ)句的一些額外的信息:
- Using filesort:即代表SQL查詢(xún)時(shí)用到了文件掃描,使用了外部的索引進(jìn)行排序,并沒(méi)有用到我們自己定義的索引,性能較差。
- using index:這種方式性能就不錯(cuò)了,使用了索引并且不需要回表就得到了我們需要的數(shù)據(jù),即用到了索引覆蓋。
- Using temporary:MySQL查詢(xún)排序時(shí)使用了臨時(shí)表性能較于filesort更差。
- using where:即代表查詢(xún)時(shí)僅僅用到了普通的where條件,并沒(méi)有用到任何索引,查詢(xún)需要在server層進(jìn)行判斷。
- Using join buffer:在進(jìn)行連接查詢(xún)時(shí),被驅(qū)動(dòng)表的數(shù)據(jù)定位并沒(méi)有走索引,于是將驅(qū)動(dòng)表的數(shù)據(jù)放入緩沖區(qū)進(jìn)行關(guān)聯(lián)匹配。
- impossible where:說(shuō)明where條件基本得不到需要的結(jié)果,篩選數(shù)據(jù)時(shí)一直處于false的狀態(tài)。
possible_keys
表示當(dāng)前查詢(xún)可能用到的索引。如下這個(gè)執(zhí)行計(jì)劃,它就以為著可能用到了主鍵

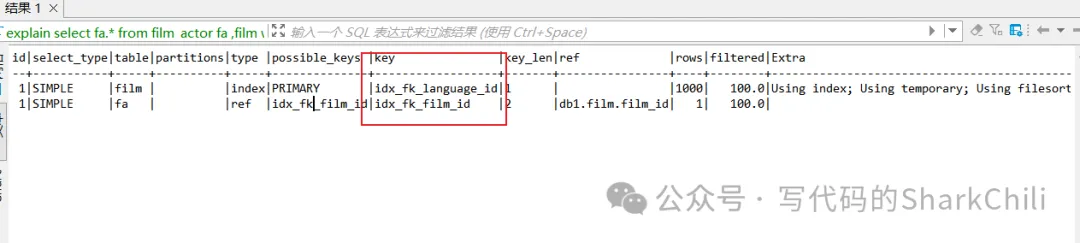
key(用到的索引名稱(chēng))
表示用到的索引名稱(chēng),如下所示下面這條sql可能就用到了這兩個(gè)索引。
key_len
key_len表示使用索引時(shí),對(duì)應(yīng)使用到的索引的長(zhǎng)度,在MySQL的EXPLAIN語(yǔ)句中,key_len列表示使用索引的鍵部分的字節(jié)數(shù)。它是一個(gè)估計(jì)值,根據(jù)查詢(xún)中使用的索引類(lèi)型和數(shù)據(jù)類(lèi)型來(lái)計(jì)算。通常,key_len越小,性能就越好,因?yàn)樗馕吨枰x取更少的數(shù)據(jù)塊。 例如,如果你有一個(gè)使用VARCHAR(100)數(shù)據(jù)類(lèi)型的列作為索引,并且查詢(xún)中只使用了前10個(gè)字符作為搜索條件,則key_len將是10。如果你使用的是INT(10)數(shù)據(jù)類(lèi)型的列作為索引,則key_len將是4,因?yàn)镮NT類(lèi)型占用4個(gè)字節(jié)。 在優(yōu)化查詢(xún)時(shí),理解key_len可以幫助你確定哪些索引可以更有效地支持查詢(xún),以及如何進(jìn)一步優(yōu)化索引設(shè)計(jì)。
例如下面這一句,實(shí)際上索引長(zhǎng)度就是303,原因很簡(jiǎn)單:
- key1為varchar(100)且用的是utf8,所以長(zhǎng)度為300字節(jié)。
- 允許空再加一個(gè)字節(jié)。
- varchar需要2字節(jié)維護(hù)長(zhǎng)度進(jìn)行再加2字節(jié)。 最終得到303字節(jié):
explain select * from s1 WHERE key1>'a' and key1<'b';ref
表示進(jìn)行索引匹配時(shí),與之比對(duì)的數(shù)據(jù)類(lèi)型,例如下面這句key1比對(duì)的是一個(gè)函數(shù)計(jì)算值,所以ref是func:
explain select * FROM s1 inner join s2 on s2.key1 =UPPER(s1.key1);例如這句與索引匹配的是常數(shù),所以得到的是const:
explain select * from s1 WHERE key1='a';當(dāng)然進(jìn)行關(guān)聯(lián)查詢(xún)時(shí)被驅(qū)動(dòng)表得到的就是驅(qū)動(dòng)表的id,如下返回的就是s1.id:
explain SELECT * FROM s1 inner join s2 on s1.id=s2.id;rows
rows意味著我們查詢(xún)時(shí)大體需要掃描多少行,對(duì)于單表查詢(xún)沒(méi)什么,但是對(duì)于多表查詢(xún),從這個(gè)數(shù)據(jù)我們可以得知關(guān)聯(lián)查詢(xún)哪個(gè)作為驅(qū)動(dòng)表:
explain SELECT * FROM customer c inner join customer_balances cb on c.id =cb.c_id ;因?yàn)閏b的rows為1,可知這張表變?yōu)楸或?qū)動(dòng)表走索引定位:
id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows |filtered|Extra|
--+-----------+-----+----------+----+--------------------------+--------------------------+-------+-------+-------+--------+-----+
1|SIMPLE |c | |ALL |PRIMARY | | | |4270364| 100.0| |
1|SIMPLE |cb | |ref |customer_balances_c_id_IDX|customer_balances_c_id_IDX|8 |db.c.id| 1| 100.0| |filter(讀取和過(guò)濾占比)
表示選取的行和讀取的行占比,例如下面這句SQL:
explain select * from s1 WHERE key1 > '1' and s1.common_field ='1';從筆者執(zhí)行計(jì)劃來(lái)看,可能會(huì)掃描49902,只有大約10%的符合要求:

該查詢(xún)?cè)趩伪聿樵?xún)中沒(méi)有太大意義,但是在連接查詢(xún)中就比較有參考價(jià)值了,例如下面這句SQL:
explain
select
*
from
s1
inner join s2 on
s1.key1 = s2.key1
WHERE
s1.common_field = 'a'從執(zhí)行計(jì)劃可以看出s1作為驅(qū)動(dòng)表大約掃描99805列數(shù)據(jù),有10%符合要求,而被驅(qū)動(dòng)表s2過(guò)濾值為1和100%比例,這意味著針對(duì)被驅(qū)動(dòng)表的查詢(xún)次數(shù)可能是99805*0.1大約9980次。
小結(jié)
通過(guò)本文的探索,我們深入了解了MySQL中的EXPLAIN關(guān)鍵字的重要性和作用。EXPLAIN不僅可以幫助我們分析查詢(xún)執(zhí)行計(jì)劃,還可以為我們提供優(yōu)化查詢(xún)性能的關(guān)鍵線(xiàn)索。
通過(guò)解讀EXPLAIN的輸出結(jié)果,我們學(xué)會(huì)了如何識(shí)別潛在的性能瓶頸,并優(yōu)化查詢(xún)以提高數(shù)據(jù)庫(kù)的效率和響應(yīng)速度。了解索引的使用、表連接順序以及訪(fǎng)問(wèn)類(lèi)型等信息,能夠幫助我們更好地優(yōu)化查詢(xún)并避免常見(jiàn)的查詢(xún)性能問(wèn)題。
在實(shí)際應(yīng)用中,不斷深入學(xué)習(xí)和理解EXPLAIN的輸出結(jié)果,結(jié)合實(shí)際場(chǎng)景進(jìn)行優(yōu)化實(shí)踐,將為我們的數(shù)據(jù)庫(kù)應(yīng)用帶來(lái)明顯的性能改善和優(yōu)勢(shì)。通過(guò)不斷優(yōu)化查詢(xún)性能,我們可以提升數(shù)據(jù)庫(kù)系統(tǒng)的整體效率,提供更好的用戶(hù)體驗(yàn)和服務(wù)質(zhì)量。
在今后的數(shù)據(jù)庫(kù)開(kāi)發(fā)和維護(hù)工作中,讓我們繼續(xù)積極運(yùn)用EXPLAIN關(guān)鍵字,不斷優(yōu)化查詢(xún)執(zhí)行計(jì)劃,提升數(shù)據(jù)庫(kù)性能,為應(yīng)用程序的穩(wěn)定性和可靠性打下堅(jiān)實(shí)的基礎(chǔ)。