













譯者 | 汪昊
審校 | 重樓
推薦系統(tǒng)自 1992 年基于用戶的協(xié)同過濾算法誕生以來,經(jīng)歷了一波又一波的革新大潮,發(fā)展至今,已經(jīng)形成了一套體系完善,理論嚴密的技術領域。隨著越來越多的基于深度學習的推薦系統(tǒng)模型誕生,該領域關于準確率的追求似乎已經(jīng)不再吸引人們的眼球。相反,越來越多的人開始關注其他熱點技術,比如大模型算法。
2023 年,來自澳大利亞 RMIT 大學的 Yueqing Xuan 等研究人員在 arXiv 上公布了一篇題為 More Is Less: When Do Recommenders Underperform for Data-rich Users? 的論文,指出推薦系統(tǒng)未必數(shù)據(jù)越多效果越好。這和最近熱潮的大模型 Scaling Law 之類的理論形成了鮮明對比。下面,我們帶領讀者對該篇論文的理論和實驗一探究竟。
因為這篇論文主要通過實驗來檢驗數(shù)據(jù)量和對應算法的效果的對比情況。我們先來了解一下實驗中用到的數(shù)據(jù)和算法。在實驗中,我們用到了如下數(shù)據(jù)集合:
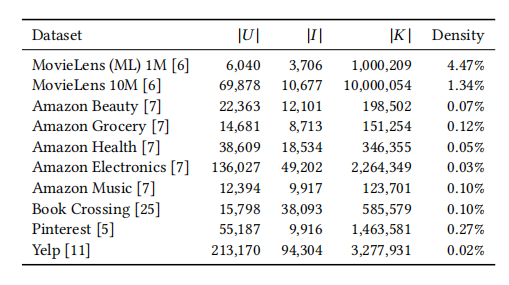
在這個表格中,|U| 代表用戶數(shù),|I| 代表物品數(shù),|K| 代表評分數(shù)量。作者在實驗中用到的都是推薦系統(tǒng)領域經(jīng)常用到的開源數(shù)據(jù)集合。
作者在實驗中主要檢測了如下算法:ItemKNN , Bayesian Personalised Ranking (BPR) , Multi-Variational Auto-encoder (Mult-VAE) , Neural Matrix Factorization (NeuMF) , Light Graph Convolution Network (LightGCN) 和 ADMMSLIM 。 作者使用了開源推薦系統(tǒng)算法庫 RecBole 進行對比實驗。
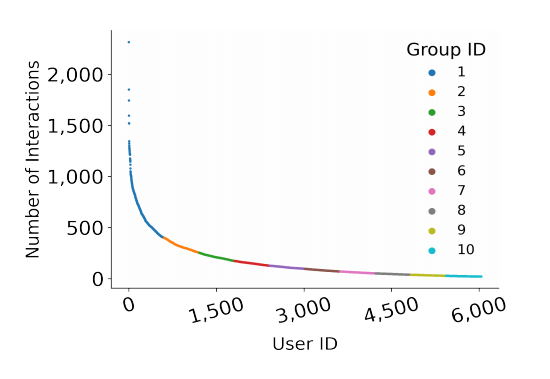
作者按照用戶交互數(shù)據(jù)的豐富程度,把輸入數(shù)據(jù)分成了十份,然后按照八二比率把數(shù)據(jù)切分成了訓練集和測試集。例如,MovieLens 1 M的數(shù)據(jù)集合的劃分如下圖所示:
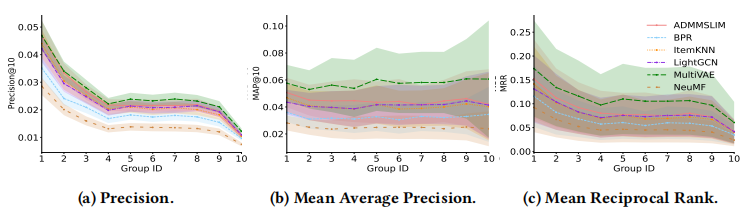
作者在 Pinterest 數(shù)據(jù)集合上進行了對比測試:
作者隨后也在 MovieLens 1M 數(shù)據(jù)集合上進行了評測,得到了下圖:
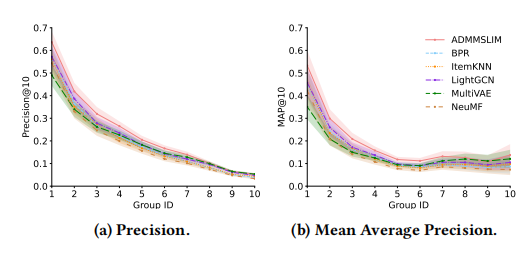
通過進行大量的類比實驗和結果可視化,作者得出了以下結論:在所有數(shù)據(jù)集上,交互豐富的數(shù)據(jù)類型的精確度(Precision)比其他組要高;Mean Average Precision 指標在各個群組卻沒有太大的區(qū)分度;而對于召回率(Recall)來說,數(shù)據(jù)越豐富,算法表現(xiàn)卻越差。
這篇論文的作者沒有用到任何高深的數(shù)學知識或者工具,只是利用最普通的數(shù)據(jù)分析的方法對算法的結果進行統(tǒng)計并用最簡單的圖形圖像工具進行可視化,從而得到了推薦系統(tǒng)不是數(shù)據(jù)越多越好的重要結論,值得推薦系統(tǒng)從業(yè)者認真學習。
我們在互聯(lián)網(wǎng)行業(yè)從事算法相關的工作的時候,除了完成公司制定的 KPI / OKR 指標之外,還應該靜下心來思考算法的理論基礎和復雜模型背后的原理。這樣才能從各個方面深入的理解算法,從而有助于我們設計出更加優(yōu)秀的技術作品,既滿足了工作的需要,也能在學術上給相關領域帶來推動作用。
譯者簡介
汪昊,前達評奇智董事長兼創(chuàng)始人。前 FunPlus 人工智能實驗室負責人。在 ThoughtWorks, 百度,聯(lián)想,網(wǎng)易和 FunPlus 等科技公司有超過 13 年的技術和技術管理經(jīng)驗。精通推薦系統(tǒng)、金融風控、爬蟲和聊天機器人等領域。在國際學術會議和期刊發(fā)表論文 44 篇。5 次獲得國際學術會議最佳論文獎和最佳論文報告獎。2006 年 ACM/ICPC 北美落基山區(qū)域賽金牌。2004 年全國大學生英語能力競賽口語總決賽銅牌。本科(2008年)和碩士(2010年)畢業(yè)于美國猶他大學。對外經(jīng)貿大學(2016 年)在職 MBA 學位。




















