













深入剖析 MySQL 某條執行過程
在當今的信息技術領域,MySQL 作為廣泛應用的數據庫管理系統,其重要性不言而喻。當我們執行一條 MySQL 語句時,看似簡單的操作背后,實則隱藏著一個嚴謹而有序的執行過程。深入探究這一過程,對于理解數據庫的運作原理以及優化數據庫性能都具有至關重要的意義。本文將以專業且深入的視角,對一條 MySQL 執行過程展開全面而細致的解析,旨在揭示其中蘊含的關鍵步驟和邏輯,帶領讀者一同領略 MySQL 執行機制的精妙與嚴謹。

一、詳解MySQL基本架構
從宏觀角度來說MySQL架構可以分為server層和存儲引擎層,其中Server層核心組件如下:
- 連接器:進行身份認證和權限相關校驗。
- 查詢緩存:查詢緩存主要是用于提高查詢效率而加的一層緩存,但在MySQL8.0已廢棄。
- 分析器:對SQL執行動作、語法、詞法進行分析。
- 優化器:對要被執行的SQL進行優化。
- 執行器:執行SQL查詢語句,然后從存儲引擎返回結果。
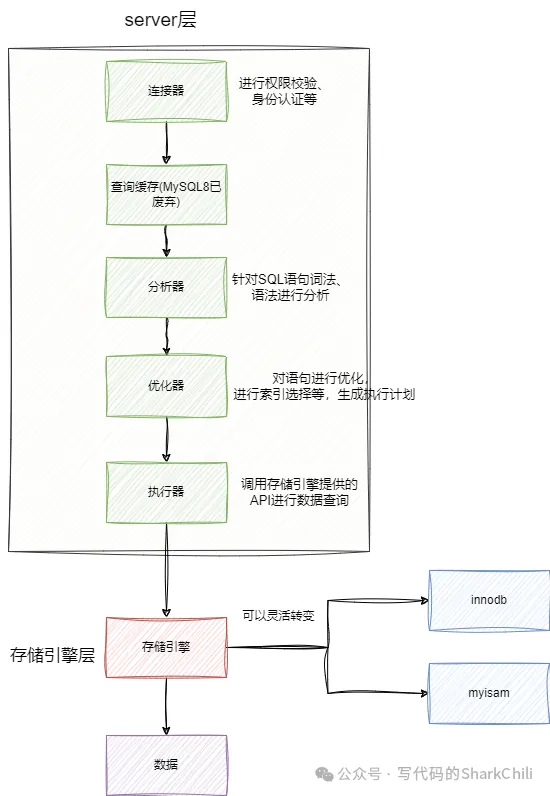
接下來說說存儲引擎,對于MySQL而言存儲引擎是支持插拔的,常見的存儲引擎有myisam、innodb、memory,而MySQL默認的使用的是innodb。
二、詳解MySQL各層的組件分工內容與職責
1. MySQL客戶端和服務端的通信協議
對于MySQL而言,客戶端和服務端之間采用的是一種半雙工的通信協議,這樣就意味著同一時刻要么客戶端向服務端發送數據,要么服務端向客戶端發送數據。所以客戶端必須完整的收到服務端響應的數據才能斷開連接。
這個交互流程也在告訴我們,進行大量數據查詢的時候,若無必要盡可能使用limit進行分頁查詢,避免這種半雙工的通信方式導致客戶端接收導致資源長時間的占用。

2. 連接器
主要判斷用戶登錄的賬戶密碼是否正確,如果賬戶密碼都正確,則進行權限查詢,注意在本次連接期間只要不斷開,無論外界如何修改權限,這個會話的權限都是以連接器查詢到的為主。
3. 查詢緩存
MySQL8已經廢棄的功能,這個功能常用于結果的緩存復用以提高查詢性能,例如我們進行select * from table where id=1的查詢。第一次發現緩存中沒有,就從數據庫中查出來并放到緩存中下次可以在復用。 MySQL8之所以廢棄是因為數據庫中的數據經常更新導致緩存失效,就需要清空這個緩存,這期間和開銷是非常沒必要的,所以索性廢掉這個功能。
這里筆者也補充一下MySQL8廢棄查詢緩存的原因:
- 鎖競爭:為了保存查詢緩存正確性,我們必須在多線程讀寫操作時針對特定緩存進行鎖定保證臨界資源的線程安全,這勢必導致高并發場景下因為緩存鎖競爭而出現性能瓶頸。
- 緩存失效:在進行insert或者update修改時,MySQL都會將表級緩存清空,所以針對寫多的場景下查詢緩存命中率不高。
- 內存負擔:為緩存數據就需要一定的內存空間,如果查詢和表的量級都十分龐大的話,那么就需要占用較大的內存資源。
- 維護成本:查詢緩存的存在增加了MySQL的復雜性,為保存緩存一致性,針對緩存添加、刪除等邏輯都需要有更加完善且復雜的舉措,這勢必增加開發和維護的成本,容易導致各種潛在的錯誤和性能問題。
4. 分析器
分析器主要是負責SQL解析和預處理,它會將客戶端發來的查詢一句進行解析生成一顆解析樹,然后解析器根據自定義規則對SQL語句進行詞法和語法分析和語義分析。
- 詞法分析:分析關鍵字是否拼寫有誤,并通過關鍵字判斷這條SQL做什么。
- 語法分析:對這條SQL語句的語法進行檢查。
- 語義分析:完成上述步驟后,分析器會解析出對應的表名和查詢條件,將其放到MySQL服務器內部的特定數據結構上開始后續的步驟。
5. 優化器
分析器分析無誤之后,說明這條語句是可以正常執行的。MySQL優化器就會通過分析找出成本最小的一種方式生成執行計劃,交由執行器執行。
對此,我們這里不妨補充一下MySQL能夠自己處理的一些優化類型:
將外連接轉為內連接:某些場景之下,我們可能會用到外連接,但是在where或者庫表結構的調整之后,我們的左外連接后者右外連接可能不存在null的連接。 例如下面這段sql,我們對table2進行左外連接,但是我們條件關聯之后,table1對應的id值在table2中都有,那么查詢優化器可能就會對其進行優化,會將其轉換為內連接,更加精確的去匹配索要查詢的行避免沒必要的掃描。
SELECT *
FROM table1
LEFT JOIN table2
ON table1.id = table2.id;舉個例子,上面的sql如果table1對應的id在table2中都有,那么sql語句就會變成這樣
SELECT *
FROM table1
LEFT JOIN table2
ON table1.id = table2.id
WHERE table2.id IS NOT NULL;然后優化器就會將其優化成這樣,直接通過inner join進行查詢,讓優化器根據兩個表的量級讓小表驅動大表:
SELECT *
FROM table1
inner JOIN table2
ON table1.id = table2.id;使用代數等價變換規則,例如我們的查詢條件是5=5 and a>5,那么MySQL就會將其優化為:a>5,再比如說我們有這樣一條SQL,條件語句為(a<b and b=c) and a=5,那么MySQL就會將其優化為: b > 5 and b=c。
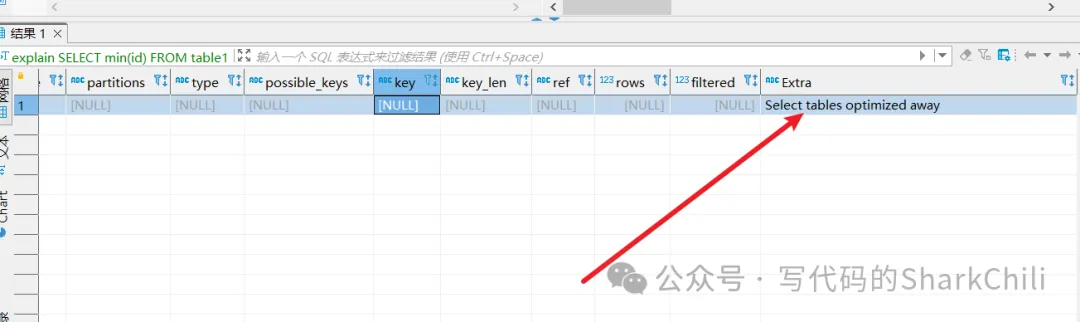
優化min、max,對于建立索引的數據表來說,使用索引所在列的進行最大值和最小值查詢時,MySQL優化器會將這種sql判定為常數查詢,例如筆者建立的下面這張表,我們將table1的id設置為索引。 然后查詢下面這句sql:
SELECT min(id)
FROM table1;使用explain查看其執行計劃,可以看到執行計劃顯示Select tables optimized away,原因很簡單,這句查詢僅僅是需要table1表的id最小值即通過索引就可以直接定位到數據列,本質上通過b+樹最左端即可:
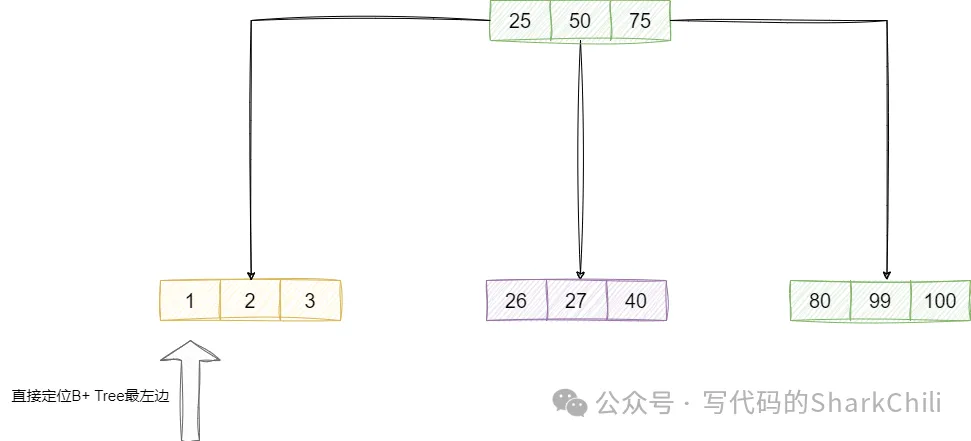
這就意味查詢不需要通過表的維度進行查詢,而是用一個常數查詢來代替。
預估并轉為為常數表達式:最典型的例子就select * from table1 where id=1+2,MySQL優化器就會將其轉為select * fromt table1 where id=3。
索引掃描:這個無需多說,當要查詢的列都包含在索引中時,無需進行回表查詢,避免沒必要的IO操作。
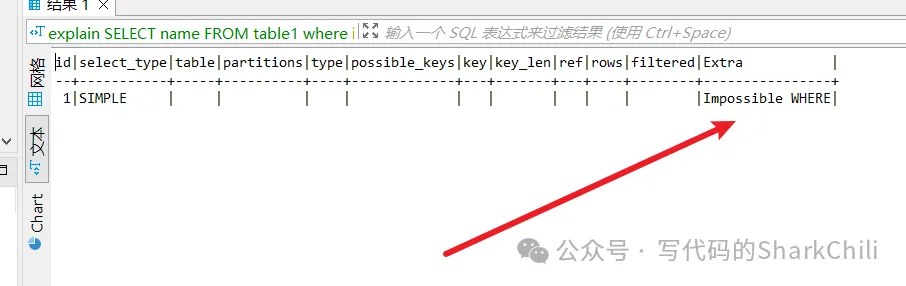
提前終止查詢:對于limit查詢而言,MySQL優化器會在查詢到需要的數據時直接終止查詢,還有一些比較特殊的,例如對于某些不可能的條件,MySQL優化器也會提前將其終止,例如我們將tbale1的id設置為主鍵,然后鍵入下面這句查詢語句。
selct * from table1 where id is null那么執行計劃就會顯示Impossible WHERE從而提前終止查詢:
6. 執行器
對用戶進行權限校驗,若權限校驗不通過則報錯,然后執行器就會根據優化器優化后的執行計劃(這里的執行計劃是一個數據結構),執行器根據這個數據結構順序調用存儲引擎提供的API進行數據查詢,并將查詢結果返回給客戶端,從而完成一次完整的SQL查詢。
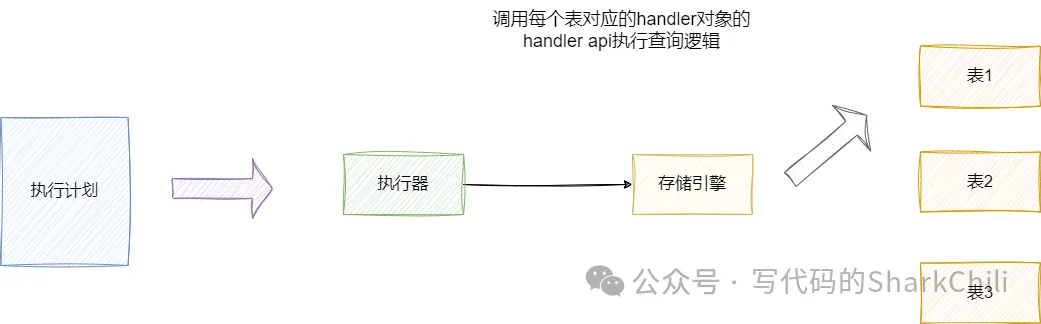
三、用兩條完整的sql走一遍上述的流程
了解SQL執行過程之后,我們不妨通過一個實際的例子帶入一下了解全過程。
1. 查詢語句的執行流程
sql如下所示:
select * from table where b=1 and a=2;按照我們上文所說的過程:
- 校驗用戶賬戶密碼是否正確,查詢權限
- 查詢緩存(mysql8.0之前),若有數據則直接返回,反之下一步
- 分析器進行詞法、語法分析。
- MySQL優化器進行優化,以本SQL為例,假如我們創建了一個聯合索引(a,b),那么優化器就會遵循最左匹配原則將a,b條件進行調換。
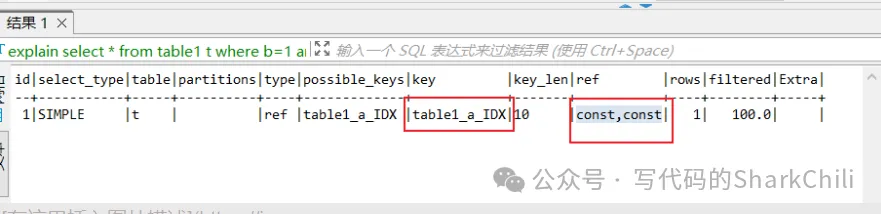
- 進行權限校驗,若有權限執行器進行查詢,將結果從引擎取出返回。
2. 更新語句的執行流程
更新語句我們示例SQL如下:
update table set a=1 where b=1;步驟還是一樣:
- 連接器的工作,不多贅述
- 查詢緩存,若有則直接操作這條數據(mysql8不走這一步)
- 分析器的工作,不多贅述
- 進行更新操作,首先調用引擎API,將這個修改寫入內存中,同時記錄redo log,此時redo log是prepare狀態,然后執行器執行操作,完成后提交事務成功,寫入bin log,最后redo log更新為commit。
- 更新完成。
小結
通過對這條 MySQL 執行過程的詳盡剖析,我們清晰地了解到從語句輸入到最終結果輸出所經歷的各個關鍵階段。我們看到了查詢優化器如何智能地選擇最優執行計劃,索引在加速數據檢索方面的關鍵作用,以及數據存儲和讀取的具體機制。這不僅讓我們對 MySQL 的內部工作原理有了更深入的認知,也為我們在實際應用中更好地利用 MySQL 、優化性能提供了堅實的理論基礎。然而,MySQL 的奧秘遠不止于此,這僅僅是一個開始,未來我們還需不斷探索和學習,以更好地駕馭這一強大的數據庫工具。














