理解 Go 協程調度的本質
作者 | jiayan
golang的一大特色就是goroutine,它是支持高并發程序的重要保障;通過 go 關鍵字我們就能輕易創建大量的輕量級協程,但它和我們認知中的線程有什么區別呢,輕量在哪里,具體是如何進行調度的..... 本文將從涉及到的一些基礎知識開始,逐步介紹到go協程調度的核心原理,希望你能有所收獲~

一、函數調用棧
1.進程在內存中的布局
首先回顧下進程的內存布局~ 操作系統把磁盤上的可執行文件加載到內存運行之前,會做很多工作,其中很重要的一件事情就是把可執行文件中的代碼,數據放在內存中合適的位置,并分配和初始化程序運行過程中所必須的堆棧,所有準備工作完成后操作系統才會調度程序起來運行。
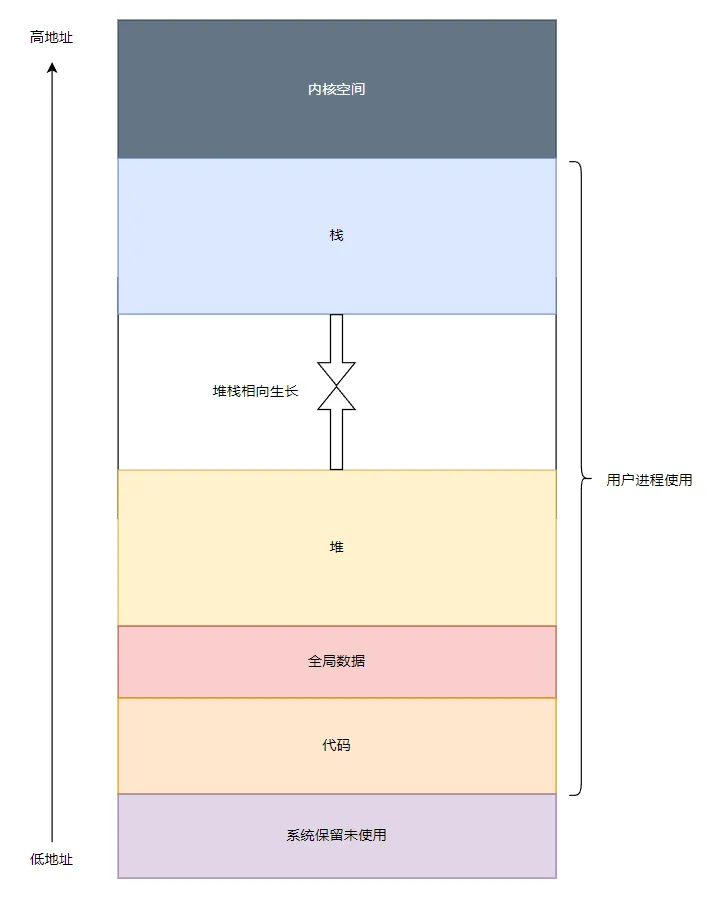
用戶程序所使用的內存空間在低地址,內核空間所使用的內存在高地址,需要特別注意的是棧是從高地址往低地址生長。
2.各區域詳解
- 代碼區,也被稱為代碼段,這部分內存存放了程序的機器代碼。這部分內存通常是只讀的,以防止程序意外地修改其自身的指令。
- 數據區,包括程序的全局變量和靜態變量,程序加載完畢后數據區的大小也不會發生改變。
- 堆,堆是用于動態內存分配的區域,例如c語言的malloc函數和go語言的new函數就是在堆上分配內存。堆從低地址向高地址增長。
- 棧,棧內存是一個連續的內存區域,通常從高地址向低地址增長。每次函數調用都會在棧上分配一個新的棧幀,函數返回時棧幀會被釋放。棧幀包含了函數調用的上下文信息,包括函數的參數、局部變量和返回地址。
3.棧詳解
(1) 棧內存中保存了什么
- 保存函數的局部變量;
- 返回函數的返回值;
- 向被調用函數傳遞參數;
- 保存函數的返回地址,返回地址是指從被調用函數返回后調用者應該繼續執行的指令地址;
每個函數在執行過程中都需要使用一塊棧內存用來保存上述這些值,我們稱這塊棧內存為某函數的棧幀(stack frame)。
(2) 與棧密切相關的三個寄存器
AMD64 CPU中有3個與棧密切相關的寄存器:
- rsp寄存器 ,始終指向當前函數調用棧棧頂。
- rbp寄存器 ,一般用來指向當前函數棧幀的起始位置,即棧底。
- ip寄存器,保存著下一條將要執行的指令的內存地址。CPU在執行指令時,會根據IP寄存器的值從內存中獲取指令從而執行,在大多數情況下,IP寄存器的值會按順序遞增,以指向下一條指令,這使得程序能夠順序執行。
假設現在有如下的一段go函數調用鏈且**當前正在執行函數C()**:
main() {
A()
}
func A() {
... 聲明了一些局部變量...
B(1, 2)
test := 123
}
func B (a int , b int) {
... 聲明了一些局部變量...
C()
}
func C (a int, b int , c int) {
test := 123
}則函數ABC的棧幀以及rsp/rbp/ip寄存器的狀態大致如下圖所示(注意,棧從高地址向低地址方向生長):
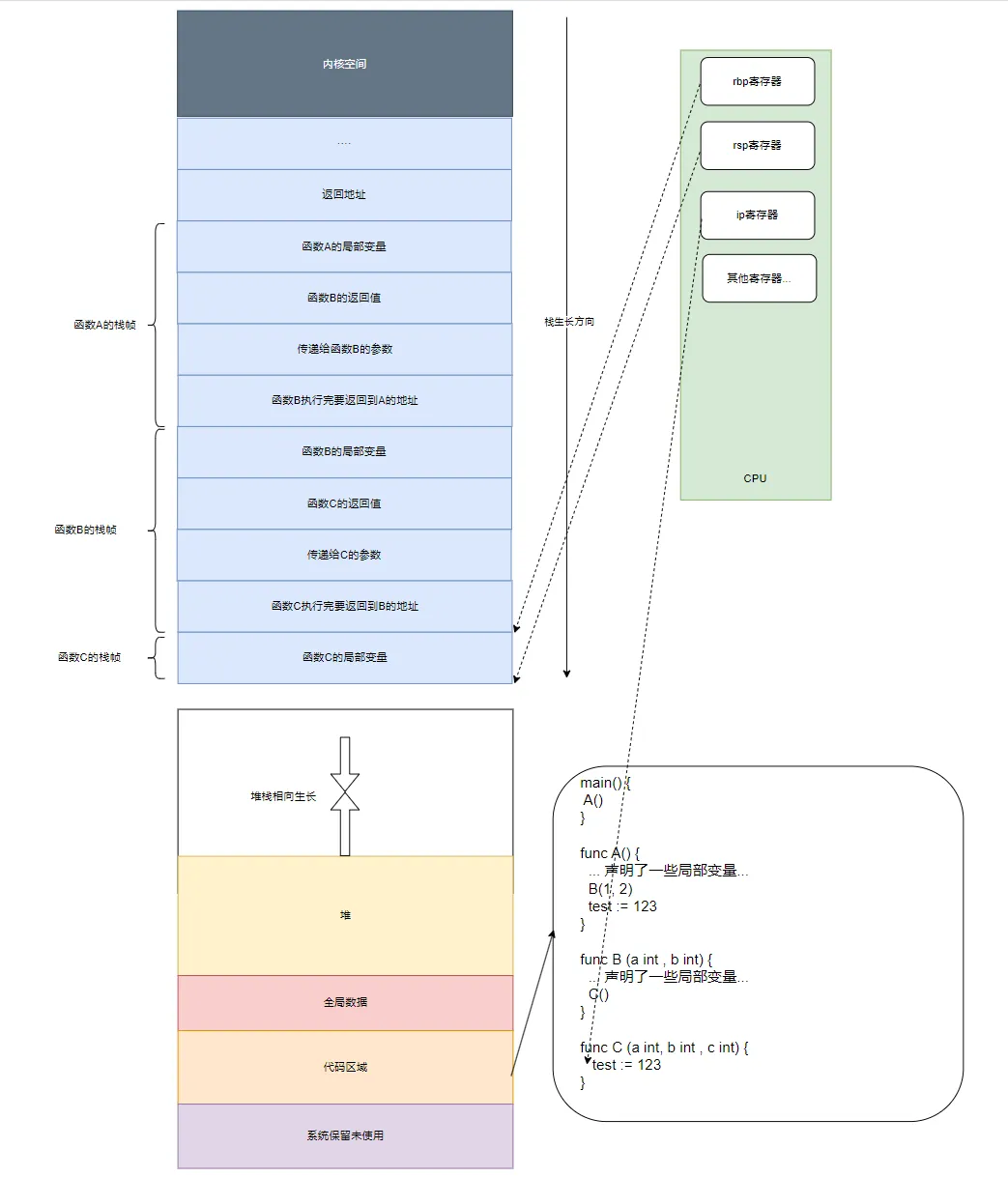
對于上圖,有幾點需要說明一下:
- go語言中調用函數時,參數和返回值都是存放在調用者的棧幀之中,而不是在被調函數之中;
- 目前正在執行C函數,且函數調用鏈為A()->B()->C(),所以以棧幀為單位來看的話,C函數的棧幀目前位于棧頂;
- cpu硬件寄存器rsp指向整個棧的棧頂,當然它也指向C函數的棧幀的棧頂,而rbp寄存器指向的是C函數棧幀的起始位置;
- 雖然圖中ABC三個函數的棧幀看起來都差不多大,但事實上在真實的程序中,每個函數的棧幀大小可能都不同,因為不同的函數局部變量的個數以及所占內存的大小都不盡相同;
- 有些編譯器比如gcc會把參數和返回值放在寄存器中而不是棧中,go語言中函數的參數和返回值都是放在棧上的;
隨著程序的運行,如果C、B兩個函數都執行完成并返回到了A函數繼續執行,則棧狀態如下圖:
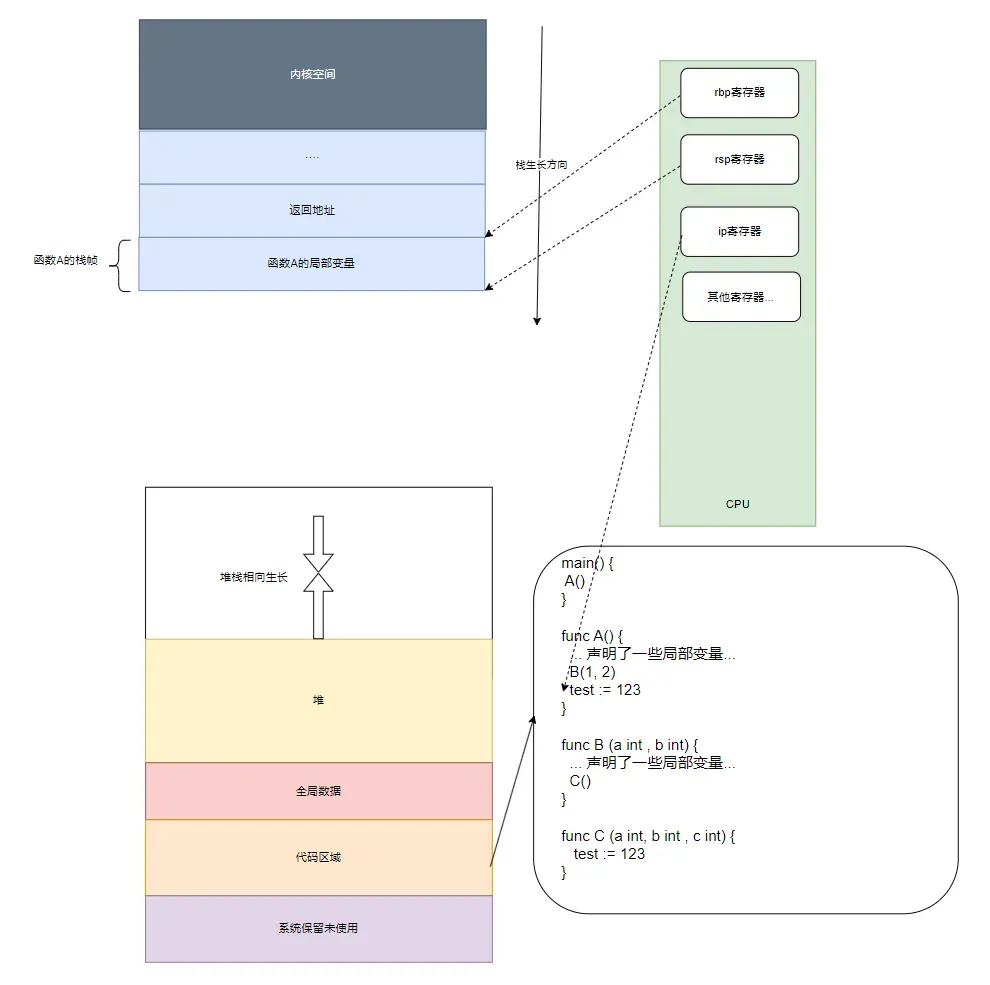
因為C、B兩個函數都已經執行完成并返回到了A函數之中,所以C、B兩個函數的棧幀就已經被POP出棧了,也就是說它們所消耗的棧內存被自動回收了。因為現在正在執行A函數,所以寄存器rbp和rsp指向的是A函數的棧中的相應位置。可以看到cpu 的rbp, rsp分別指向了a函數的棧底和棧頂,同時ip寄存器指向了A函數調用完B后的下一行代碼 test:= 123的地址,接下來CPU會根據IP寄存器,從代碼區的內存中獲取下一行代碼所對應的匯編指令去執行。
(3) 棧溢出
即使是同一個函數,每次調用都會產生一個不同的棧幀,因此對于遞歸函數,每遞歸一次都會消耗一定的棧內存,如果遞歸層數太多就有導致棧溢出的風險,這也是為什么我們在實際的開發過程中應該盡量避免使用遞歸函數的原因之一,另外一個原因是遞歸函數執行效率比較低,因為它要反復調用函數,而調用函數有較大的性能開銷。
二、Linux線程以及線程調度
1.一段c程序
要深入理解go的協程調度邏輯,就需要對操作系統線程有個大致的了解,因為go的調度系統是建立在操作系統線程之上的,所以我們先來通過linux下的C語言demo入手,我們把這個程序跑在一臺單核CPU的機器上。
C語言中我們一般使用pthread線程庫,而使用該線程庫創建的用戶態線程其實就是Linux操作系統內核所支持的線程,它與go語言中的工作線程是一樣的,這些線程都由Linux內核負責管理和調度,然后go語言在操作系統線程之上又做了goroutine,實現了一個二級線程模型。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define N (1000 * 1000 * 1000)
volatile int g = 0;
void *start(void *arg)
{
int i;
for (i = 0; i < N; i++) {
g++;
}
return NULL;
}
int main(int argc, char *argv[])
{
pthread_t tid;
// 使用pthread_create函數創建一個新線程執行start函數
pthread_create(&tid, NULL, start, NULL);
for (;;) {
usleep(1000 * 100 * 5);
printf("loop g: %d\n", g);
if (g == N) {
break;
}
}
pthread_join(tid, NULL); // 等待子線程結束運行
return 0;
}
```c
$./thread
loop g: 98938361
loop g: 198264794
loop g: 297862478
loop g: 396750048
loop g: 489684941
loop g: 584723988
loop g: 679293257
loop g: 777715939
loop g: 876083765
loop g: 974378774
loop g: 1000000000該程序運行起來之后將會有2個線程,一個是操作系統把程序加載起來運行時創建的主線程,另一個是主線程調用pthread_create創建的start子線程,主線程在創建完子線程之后每隔500毫秒打印一下全局變量 g 的值直到 g 等于10億,而start線程啟動后就開始執行一個10億次的對 g 自增加 1 的循環,這兩個線程同時并發運行在系統中,操作系統負責對它們進行調度,我們無法精確預知某個線程在什么時候會運行。
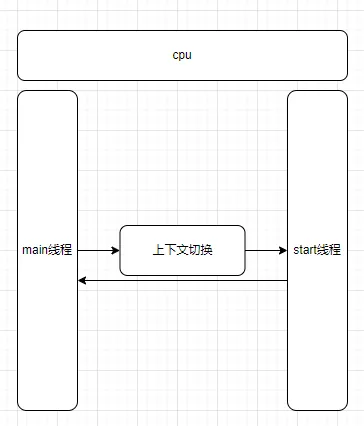
2.操作系統在調度線程時會做哪些事情
- 選擇線程:操作系統調度器會根據特定的調度算法(如優先級調度、輪轉調度、最短作業優先等)選擇下一個要執行的線程。
- 上下文切換:操作系統會保存當前正在運行的線程的狀態(這被稱為上下文),然后加載被選中的線程的上下文。上下文包括了線程的程序計數器、寄存器的值等。
- 線程切換:操作系統會將CPU的控制權交給被選中的線程,該線程會從它上次停止的地方開始執行。
- 回到原線程:當被選中的線程的執行時間片用完或者被阻塞時,操作系統會再次保存它的上下文,然后選擇另一個線程執行。這個過程會不斷重復。
3.具體需要保存哪些寄存器呢
- 通用寄存器,線程運行時很可能會用到,保存當前線程的一些工作變量。
- ip寄存器(指令指針寄存器)(程序運行起來后低地址有一部分專門用來存放代碼數據,IP寄存器通常指向這一區域,指明下一條要運行的代碼地址)。
- 棧寄存器RBP(指向當前棧的棧底)和RSP(當前棧的棧頂),2個棧寄存器確定了線程執行時需要使用的棧內存。所以恢復CPU寄存器的值就相當于改變了CPU下一條需要執行的指令,同時也切換了函數調用棧。
4.線程調度的核心是什么
操作系統對線程的調度可以簡單的理解為內核調度器對不同線程所使用的寄存器和棧的切換。
三、goroutine調度器
1.調度模型
(1) 傳統線程模型的問題
① 調度
上面講到了線程是操作系統級別的調度單位,通常由操作系統內核管理。切上下文切換的開銷通常在微秒級別,且頻繁的上下文切換會顯著影響性能。
② 資源消耗
每個線程都有自己的堆棧和線程局部存儲(Thread Local Storage),這會消耗更多的內存資源。創建和銷毀線程的開銷也相對較大。在 Linux 中,默認的線程棧大小通常為 8 MB。
③ 調度策略
線程調度通常由操作系統內核使用復雜的調度算法(如輪轉調度、優先級調度等)來管理。調度器需要考慮多個線程的優先級、狀態、資源占用等因素,調度過程相對復雜。
(2) goroutine有多輕量
而相對的,用戶態的goroutine則輕量得多:
- goroutine是用戶態線程,其創建和切換都在用戶代碼中完成而無需進入操作系統內核,所以其開銷要遠遠小于系統線程的創建和切換;
- goroutine啟動時默認棧大小只有2k,這在多數情況下已經夠用了,即使不夠用,goroutine的棧也會自動擴大,同時,如果棧太大了過于浪費它還能自動收縮,這樣既沒有棧溢出的風險,也不會造成棧內存空間的大量浪費。
正是因為go語言中實現了如此輕量級的線程,才使得我們在Go程序中,可以輕易的創建成千上萬甚至上百萬的goroutine出來并發的執行任務而不用太擔心性能和內存等問題。
(3) go調度器的簡化模型
goroutine建立在操作系統線程基礎之上,它與操作系統線程之間實現了一個多對多(M:N)的兩級線程模型 這里的 M:N 是指M個goroutine運行在N個操作系統線程之上,內核負責對這N個操作系統線程進行調度,而這N個系統線程又負責對這M個goroutine進行調度和運行。
所謂的對goroutine的調度,是指程序代碼按照一定的算法在適當的時候挑選出合適的goroutine并放到CPU上去運行的過程,這些負責對goroutine進行調度的程序代碼我們稱之為goroutine調度器。用極度簡化了的偽代碼來描述goroutine調度器的工作流程大概是下面這個樣子:
// 程序啟動時的初始化代碼
......
for i := 0; i < N; i++ { // 創建N個操作系統線程執行schedule函數
create_os_thread(schedule) // 創建一個操作系統線程執行schedule函數
}
//schedule函數實現調度邏輯
func schedule() {
for { //調度循環
// 根據某種算法從M個goroutine中找出一個需要運行的goroutine
g := find_a_runnable_goroutine_from_M_goroutines()
run_g(g) // CPU運行該goroutine,直到需要調度其它goroutine才返回
save_status_of_g(g) // 保存goroutine的狀態,主要是寄存器的值
}
}這段偽代碼表達的意思是,程序運行起來之后創建了N個由內核調度的操作系統線程(為了方便描述,我們稱這些系統線程為工作線程)去執行shedule函數,而schedule函數在一個調度循環中反復從M個goroutine中挑選出一個需要運行的goroutine并跳轉到該goroutine去運行,直到需要調度其它goroutine時才返回到schedule函數中通過save_status_of_g保存剛剛正在運行的goroutine的狀態然后再次去尋找下一個goroutine。
(4) GM模型
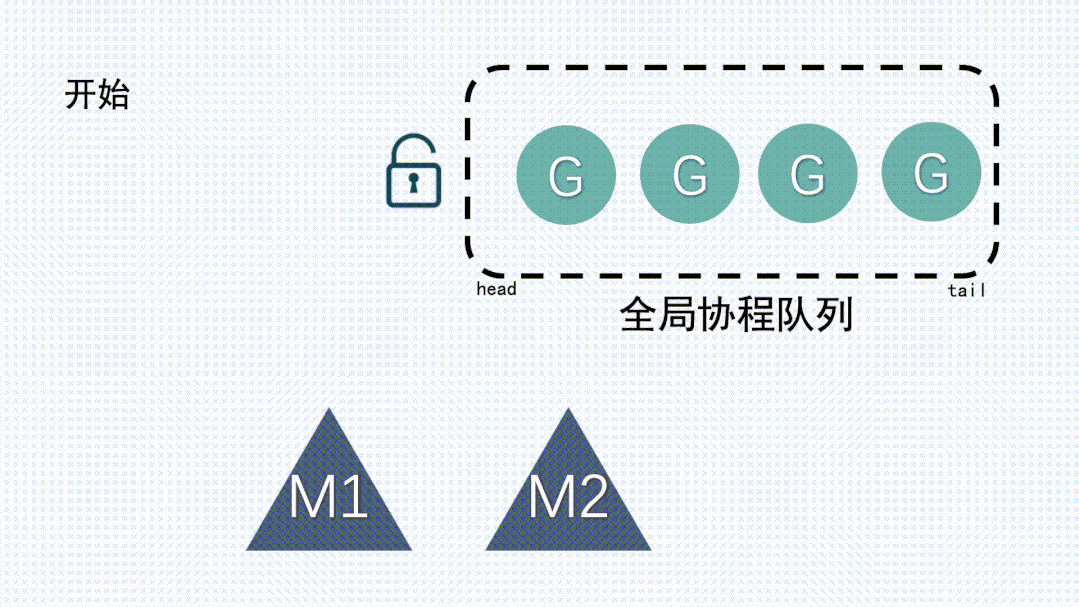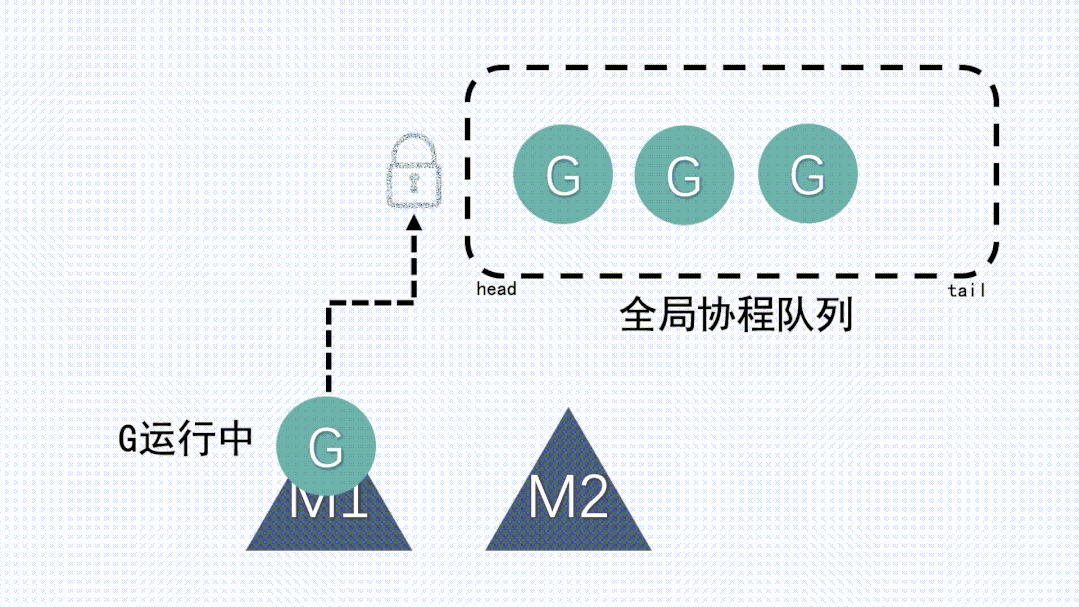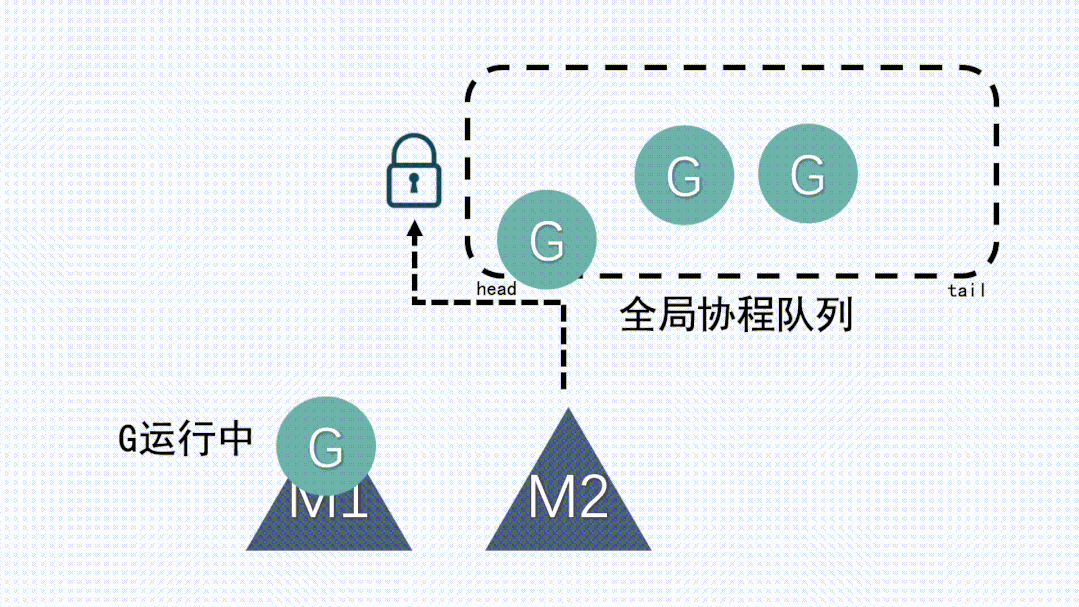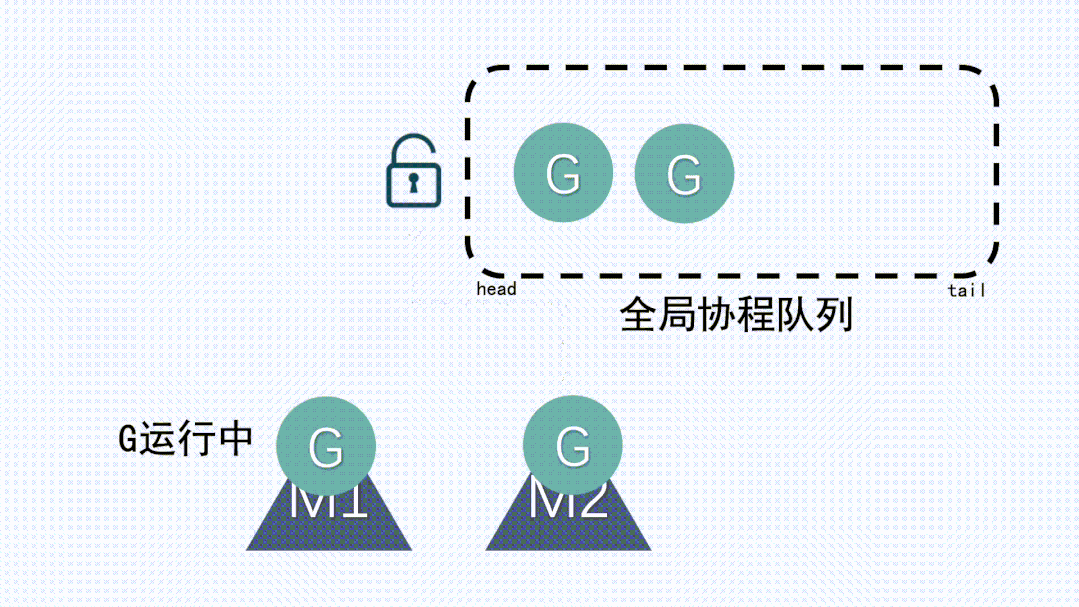
在 Go 1.1版本之前,其實用的就是GM模型。GM模型的調度邏輯和上面講到的簡化版模型非常類似,是一種多對多的模型,go程序底層使用了多個操作系統線程,同時在go語言層面實現了語言級的輕量級協程goroutine(對操作系統來說是透明的,操作系統只知道切換線程并且執行線程上的代碼),每個操作系統線程都會不斷的去全局隊列中獲取goroutine來執行。
- goroutine (G): goroutine 是 go 語言中的輕量級線程。它們由 go 運行時管理,創建和銷毀的開銷相對較小。用戶可以通過 go 關鍵字輕松地啟動一個新的 goroutine。
- 操作系統線程 (M): M 代表操作系統線程,go 運行時使用這些線程來執行 goroutine。每個 M 線程可以在操作系統的線程池中運行,負責執行 goroutine 的代碼。
(5) GM模型的缺點
有一個全局隊列帶來了一個問題,因為從隊列中獲取 goroutine 必須要加鎖,導致鎖的爭用非常頻繁。尤其是在大量 goroutine 被調度的情況下,對性能的影響也會非常明顯。
每個線程在運行時都可能會遇到需要進行系統調用的情況。早期GM模型中每個M都關聯了內存緩存(mcache)和其他的緩存(棧空間),但實際上只有正在運行的 go 代碼的 M 才需要 mcache(阻塞在系統調用的 M 不需要 mcache)。運行 go 代碼的 M 和系統調用阻塞的 M 比例大概在 1:100,這就導致了大量的資源消耗(每個 mcache 會占用到 2M)。
造成延遲和額外的系統負載。比如當G中包含創建新協程的時候,M創建了G’,為了繼續執行G,需要把G’交給M’執行,也造成了很差的局部性,因為G’和G是相關的,最好放在M上執行,而不是其他M'。
(6) GMP模型

基于沒有什么是加一個中間層不能解決的思路,golang在原有的GM模型的基礎上加入了一個調度器P,可以簡單理解為是在G和M中間加了個中間層。于是就有了現在的GMP模型里。
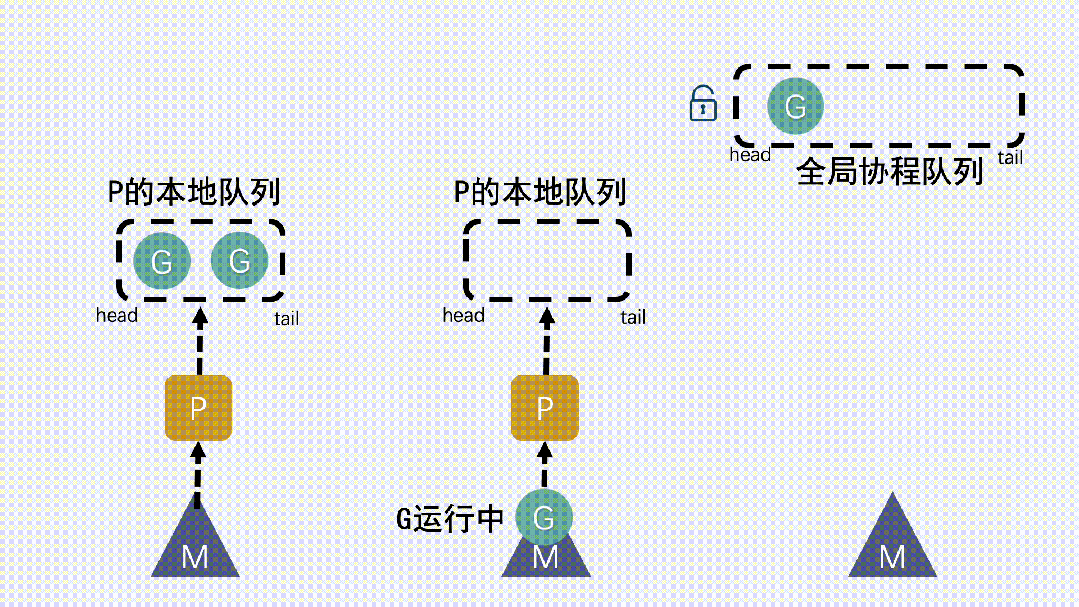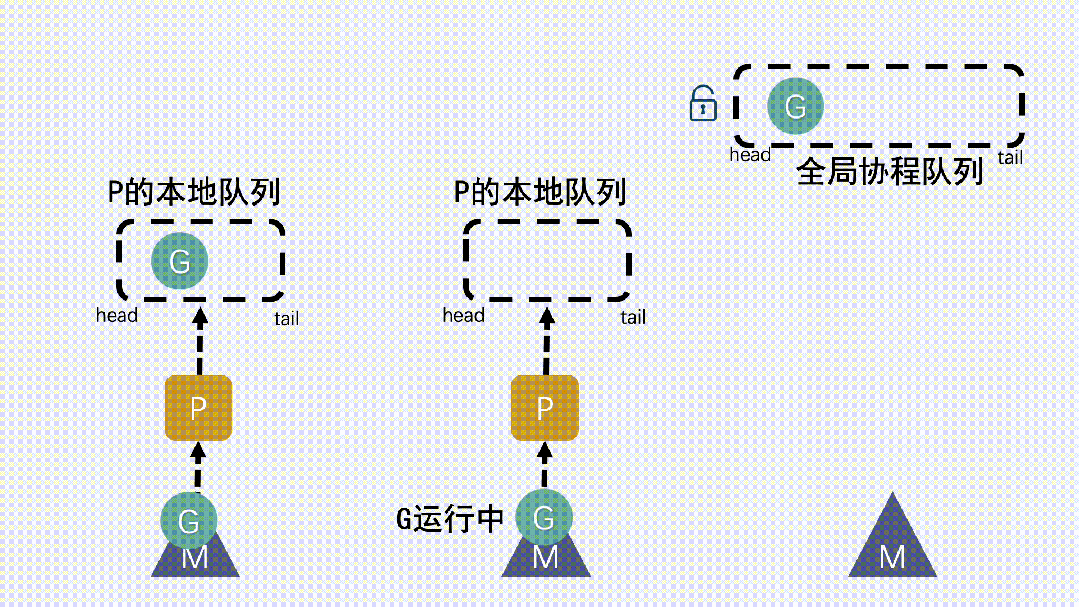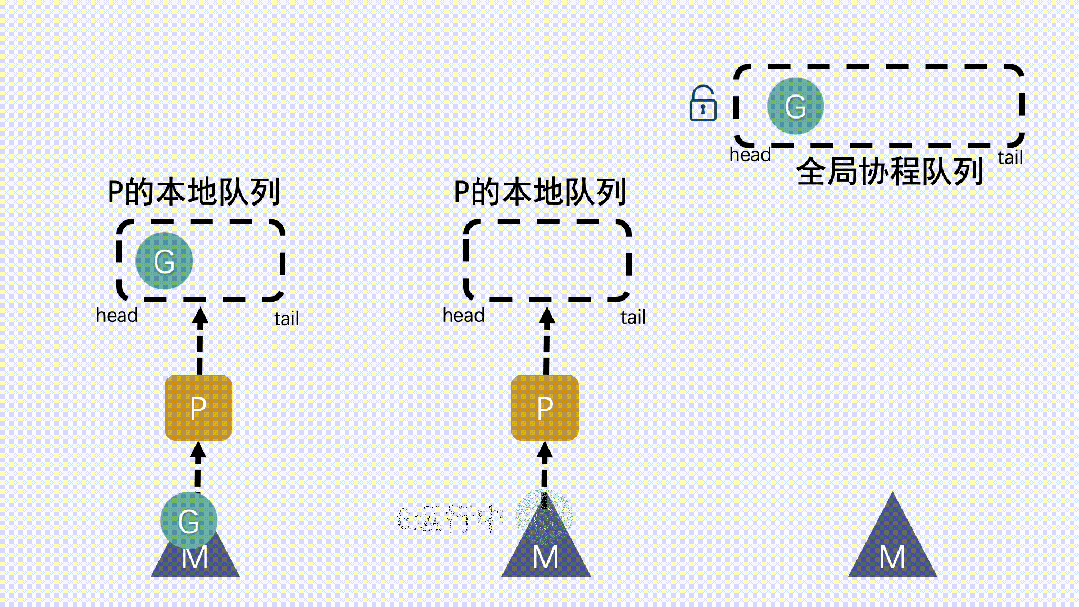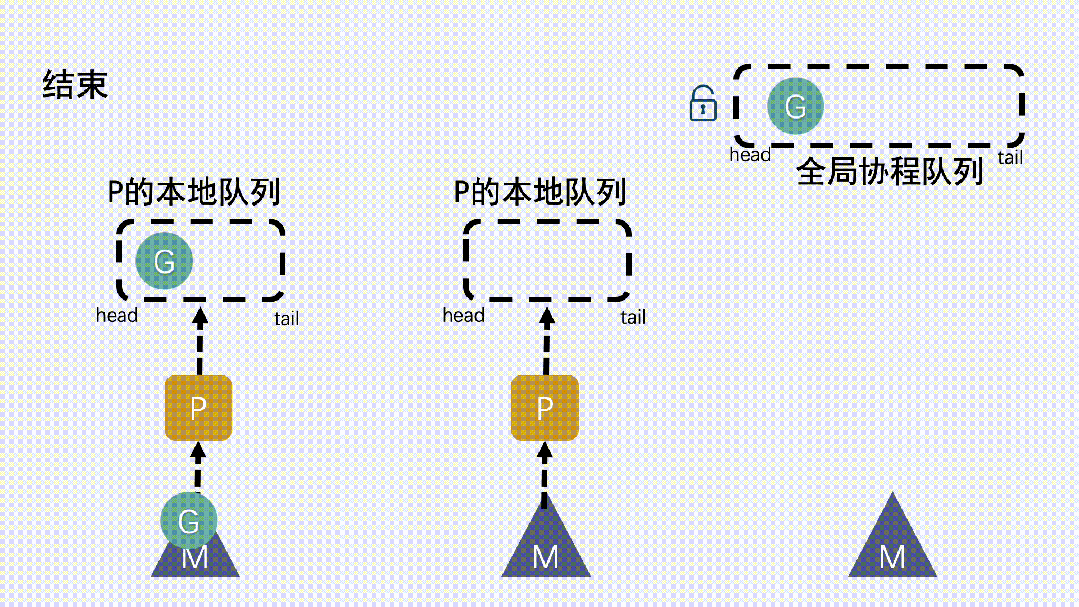
- P 的加入,還帶來了一個本地協程隊列,跟前面提到的全局隊列類似,也是用于存放G,想要獲取等待運行的G,會優先從本地隊列里拿,訪問本地隊列無需加鎖。而全局協程隊列依然是存在的,但是功能被弱化,不到萬不得已是不會去全局隊列里拿G的。
- GM模型里M想要運行G,直接去全局隊列里拿就行了;GMP模型里,M想要運行G,就得先獲取P,然后從 P 的本地隊列獲取 G。
- 新建 G 時,新G會優先加入到 P 的本地隊列;如果本地隊列滿了,則會把本地隊列中一半的 G 移動到全局隊列。P 的本地隊列為空時,就從全局隊列里去取。
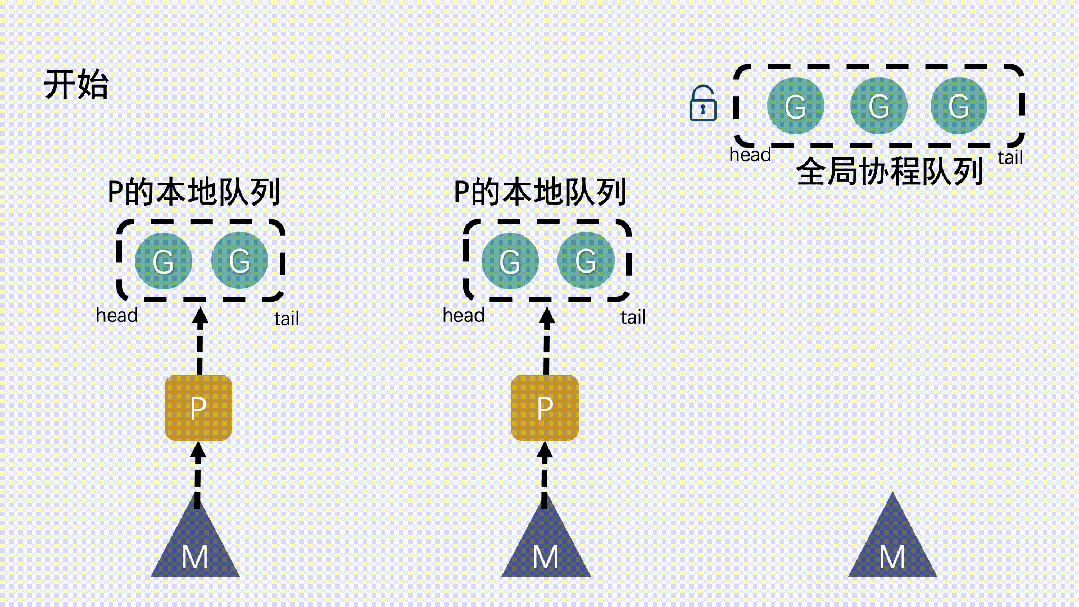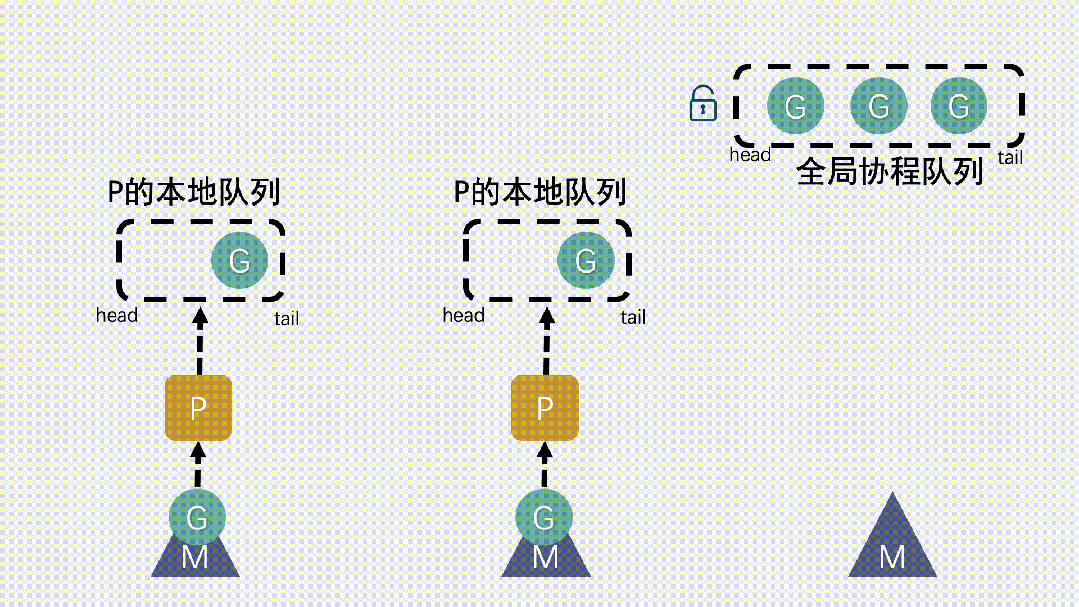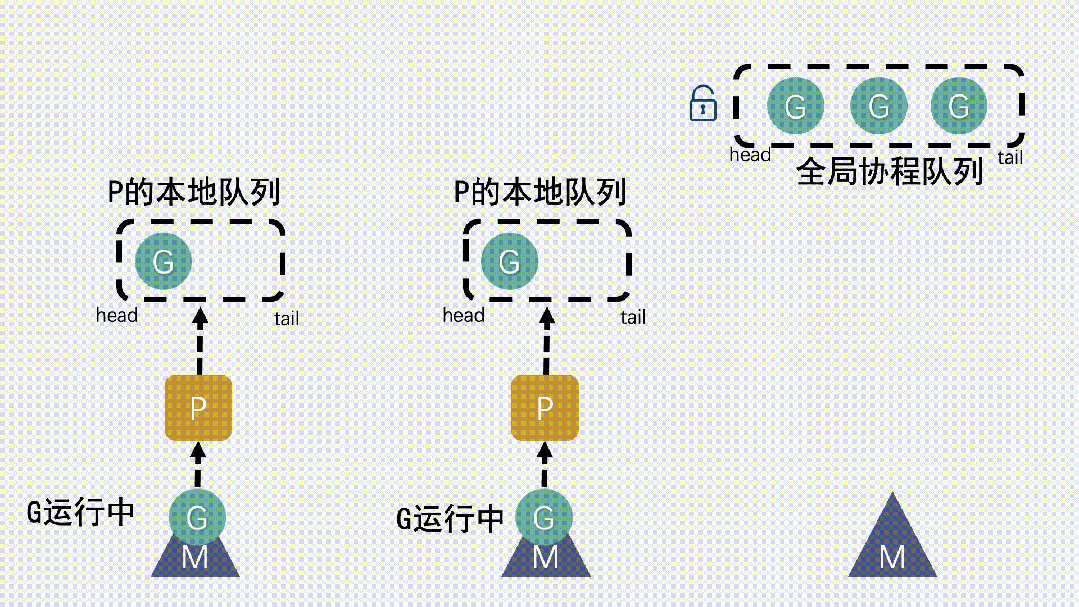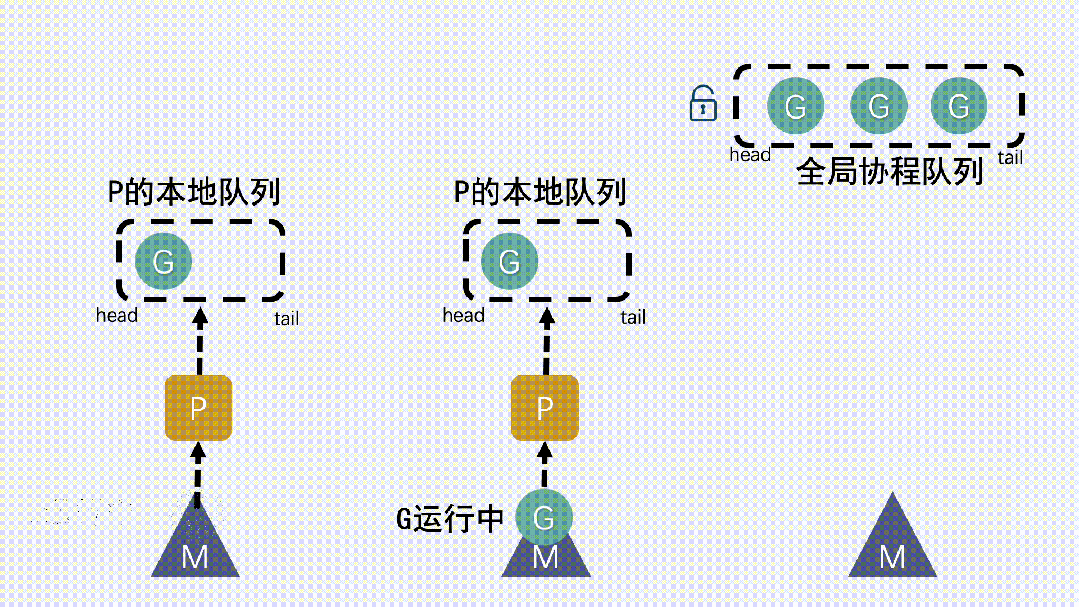
- 新建 G 時,新G會優先加入到 P 的本地隊列;如果本地隊列滿了,則會把本地隊列中一半的 G 移動到全局隊列。
- P 的本地隊列為空時,就從全局隊列里去取。
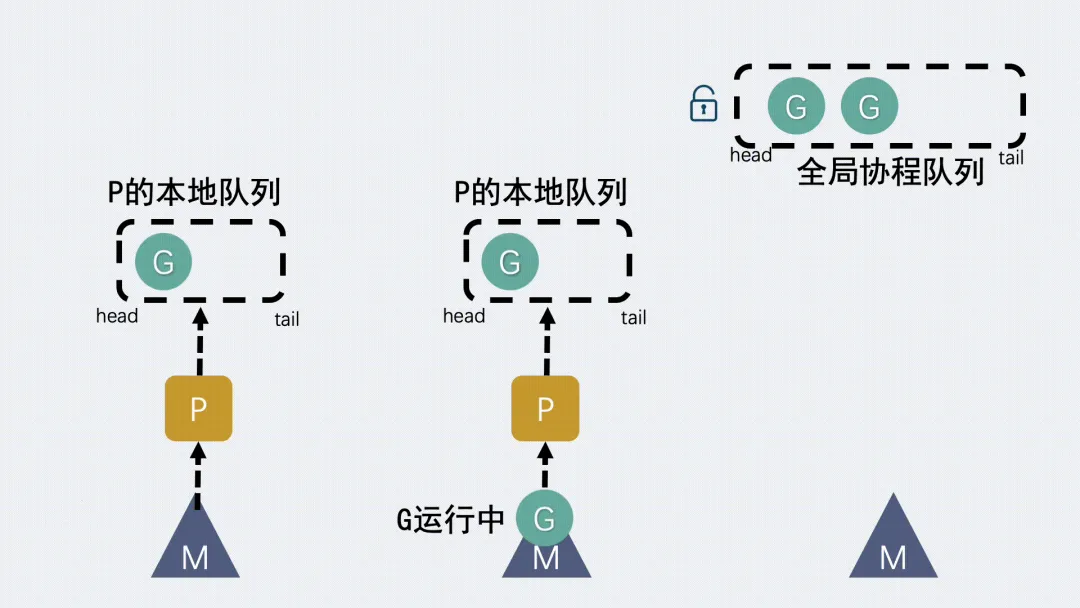
- 如果全局隊列為空時,M 會從其他 P 的本地隊列偷(stealing)一半 G放到自己 P 的本地隊列。
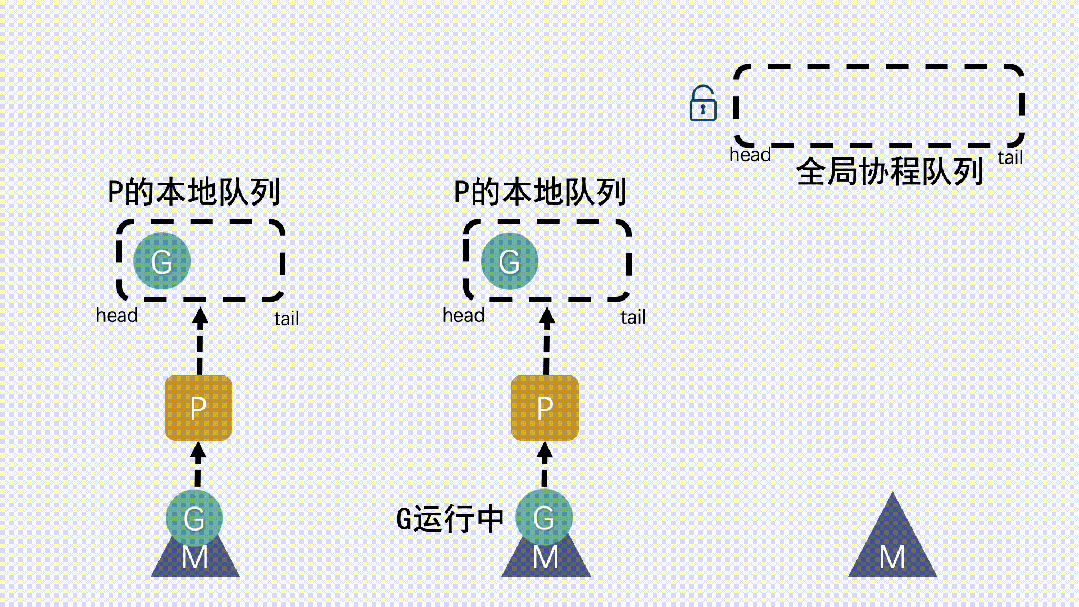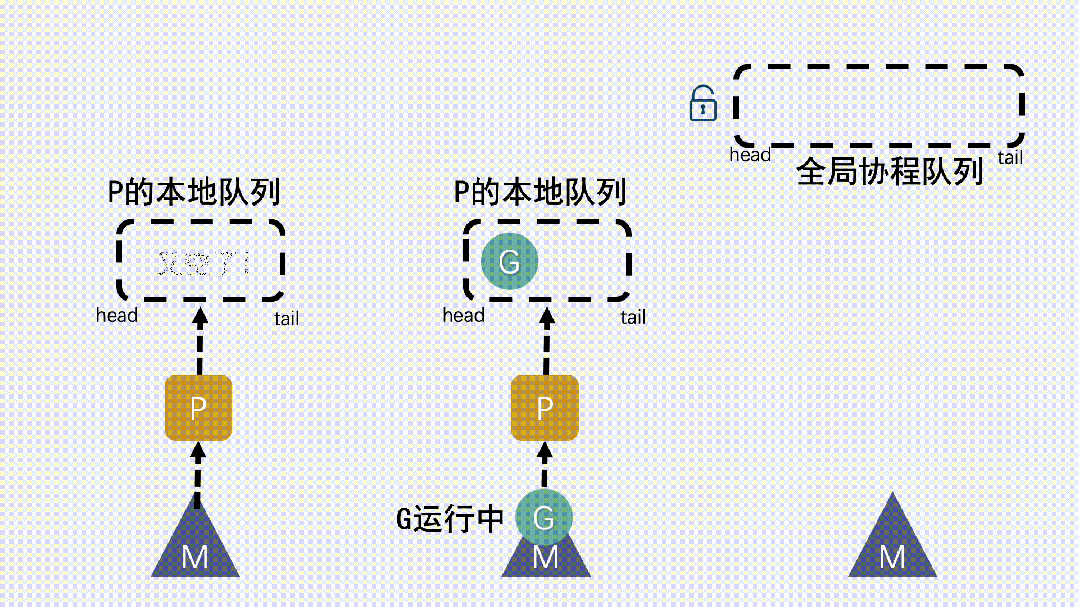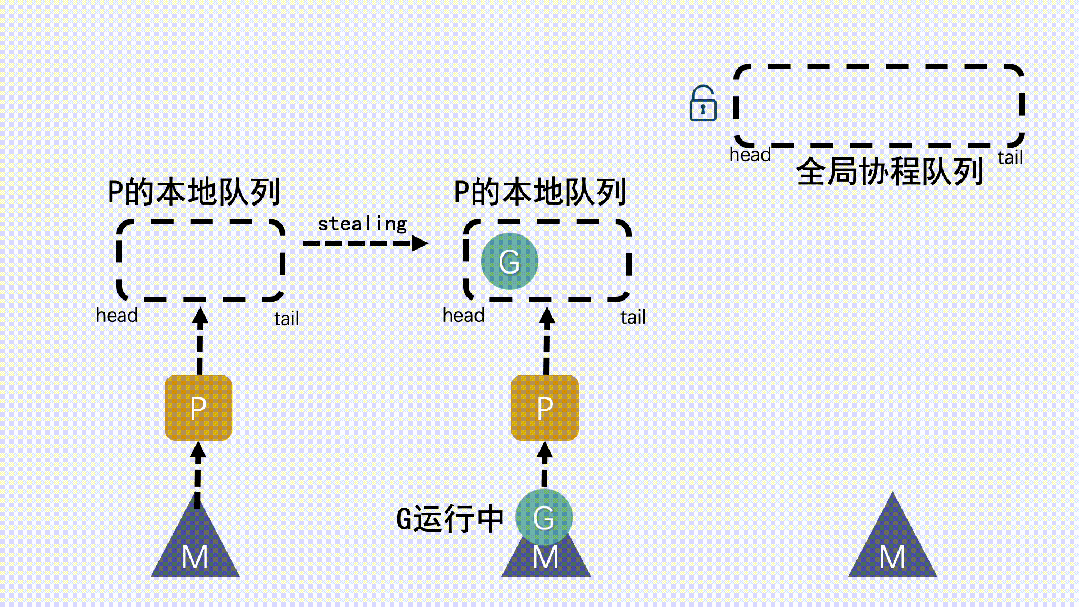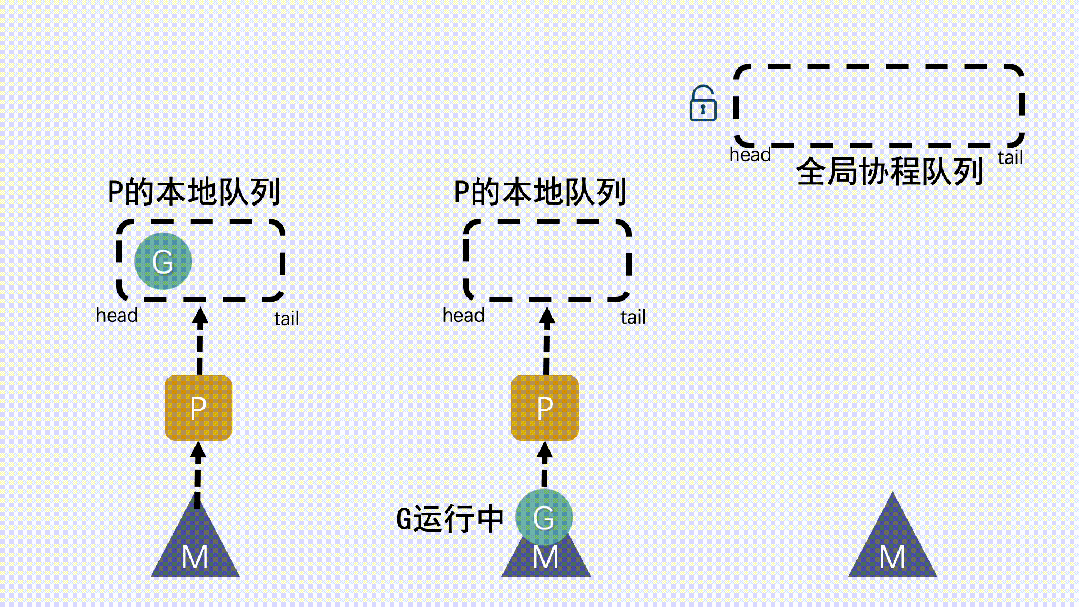
- M 運行 G,G 執行之后,M 會從 P 獲取下一個 G,不斷重復下去。
(7) 為什么要有P
這時候就有會疑惑了,如果是想實現本地隊列、Work Stealing 算法,那為什么不直接在 M 上加呢,M 也照樣可以實現類似的功能。為什么又再加多一個 P 組件?結合 M(系統線程) 的定位來看,若這么做,有以下問題。
- 一般來講,M 的數量都會多于 P。像在 Go 中,M 的數量最大限制是 10000,P 的默認數量的 CPU 核數。另外由于 M 的屬性,也就是如果存在系統阻塞調用,阻塞了 M,又不夠用的情況下,M 會不斷增加。
- M 不斷增加的話,如果本地隊列掛載在 M 上,那就意味著本地隊列也會隨之增加。這顯然是不合理的,因為本地隊列的管理會變得復雜,且 Work Stealing 性能會大幅度下降。
- M 被系統調用阻塞后,我們是期望把他既有未執行的任務分配給其他繼續運行的,而不是一阻塞就導致全部停止
2.調度器數據結構概述
系統線程對goroutine的調度與內核對系統線程的調度原理是一樣的,實質都是通過保存和修改CPU寄存器的值來達到切換線程/goroutine的目的。因此,為了實現對goroutine的調度,需要引入一個數據結構來保存CPU寄存器的值以及goroutine的其它一些狀態信息,在go語言調度器源代碼中,這個數據結構是一個名叫g的結構體,它保存了goroutine的所有信息,該結構體的每一個實例對象都代表了一個goroutine。調度器代碼可以通過g對象來對goroutine進行調度。
- 當goroutine被調離CPU時,調度器代碼負責把CPU寄存器的值保存在g對象的成員變量之中
- 當goroutine被調度起來運行時,調度器代碼又負責把g對象的成員變量所保存的寄存器的值恢復到CPU的寄存器
前面我們所講的G,M,P,在源碼中均有與之對應的數據結構。
(1) 重要的結構體
G M P 結構體定義于src/runtime/runtime2.go。
① g結構體
type g struct {
// 記錄該goroutine使用的棧,當前 goroutine 的棧內存范圍 [stack.lo, stack.hi)
stack stack
// 下面兩個成員用于棧溢出檢查,實現棧的自動伸縮,搶占調度也會用到stackguard0
stackguard0 uintptr
_panic *_panic
_defer *_defer
// 此goroutine正在被哪個工作線程執行
m *m
// 存儲 goroutine 的調度相關的數據
sched gobuf
// schedlink字段指向全局運行隊列中的下一個g,
// 所有位于全局運行隊列中的g形成一個鏈表
schedlink guintptr
// 不涉及本篇內容的字段已剔除
...
}下面看看gobuf結構體,主要在調度器保存或者恢復上下文的時候用到:
type gobuf struct {
// 棧指針,對應上文講到的RSP寄存器的值
sp uintptr
// 程序計數器,對應上文講到的RIP寄存器
pc uintptr
// 記錄當前這個gobuf對象屬于哪個goroutine
g guintptr
// 系統調用的返回值
ret sys.Uintreg
// 保存CPU的rbp寄存器的值
bp uintptr
...
}stack結構體主要用來記錄goroutine所使用的棧的信息,包括棧頂和棧底位置:
// Stack describes a Go execution stack.
// The bounds of the stack are exactly [lo, hi),
// with no implicit data structures on either side.
//用于記錄goroutine使用的棧的起始和結束位置
type stack struct {
lo uintptr // 棧頂,指向內存低地址
hi uintptr // 棧底,指向內存高地址
}在執行過程中,G可能處于以下幾種狀態:
const (
// 剛剛被分配并且還沒有被初始化
_Gidle = iota // 0
// 沒有執行代碼,沒有棧的所有權,存儲在運行隊列中
_Grunnable // 1
// 可以執行代碼,擁有棧的所有權,被賦予了內核線程 M 和處理器 P
_Grunning // 2
// 正在執行系統調用,擁有棧的所有權,沒有執行用戶代碼,
// 被賦予了內核線程 M 但是不在運行隊列上
_Gsyscall // 3
// 由于運行時而被阻塞,沒有執行用戶代碼并且不在運行隊列上,
// 但是可能存在于 Channel 的等待隊列上
_Gwaiting // 4
// 表示當前goroutine沒有被使用,沒有執行代碼,可能有分配的棧
_Gdead // 6
// 棧正在被拷貝,沒有執行代碼,不在運行隊列上
_Gcopystack // 8
// 由于搶占而被阻塞,沒有執行用戶代碼并且不在運行隊列上,等待喚醒
_Gpreempted // 9
// GC 正在掃描棧空間,沒有執行代碼,可以與其他狀態同時存在
_Gscan = 0x1000
...
)上面的狀態看起來很多,但是實際上只需要關注下面幾種就好了:
- 等待中:_ Gwaiting、_Gsyscall 和 _Gpreempted,這幾個狀態表示G沒有在執行;
- 可運行:_Grunnable,表示G已經準備就緒,可以在線程運行;
- 運行中:_Grunning,表示G正在運行;
② m結構體
type m struct {
// g0主要用來記錄工作線程使用的棧信息,在執行調度代碼時需要使用這個棧 // 執行用戶goroutine代碼時,使用用戶goroutine自己的棧,調度時會發生棧的切換
g0 *g
// 線程本地存儲 thread-local,通過TLS實現m結構體對象與工作線程之間的綁定,下文會詳細介紹
tls [6]uintptr // thread-local storage (for x86 extern register)
// 當前運行的G
curg *g // current running goroutine
// 正在運行代碼的P
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
// 之前使用的P
oldp puintptr
// 記錄所有工作線程的一個鏈表
alllink *m // on allm
schedlink muintptr
// Linux平臺thread的值就是操作系統線程ID
thread uintptr // thread handle
freelink *m // on sched.freem
...
}③ p結構體
調度器中的處理器 P 是線程 M 和 G 的中間層,用于調度 G 在 M 上執行。
type p struct {
id int32
// p 的狀態
status uint32
// 調度器調用會+1
schedtick uint32 // incremented on every scheduler call
// 系統調用會+1
syscalltick uint32 // incremented on every system call
// 對應關聯的 M
m muintptr
mcache *mcache
pcache pageCache
// defer 結構池
deferpool [5][]*_defer
deferpoolbuf [5][32]*_defer
// 可運行的 goroutine 隊列,可無鎖訪問
runqhead uint32
runqtail uint32
runq [256]guintptr
// 緩存可立即執行的 G
runnext guintptr
// 可用的 G 列表,G 狀態等于 Gdead
gFree struct {
gList
n int32
}
...
}P的幾個狀態:
const (
// 表示P沒有運行用戶代碼或者調度器
_Pidle = iota
// 被線程 M 持有,并且正在執行用戶代碼或者調度器
_Prunning
// 沒有執行用戶代碼,當前線程陷入系統調用
_Psyscall
// 被線程 M 持有,當前處理器由于垃圾回收 STW 被停止
_Pgcstop
// 當前處理器已經不被使用
_Pdead
)④ schedt結構體
type schedt struct {
...
// 鎖,從全局隊列獲取G時需要使用到
lock mutex
// 空閑的 M 列表
midle muintptr
// 空閑的 M 列表數量
nmidle int32
// 下一個被創建的 M 的 id
mnext int64
// 能擁有的最大數量的 M
maxmcount int32
// 由空閑的p結構體對象組成的鏈表
pidle puintptr // idle p's
// 空閑 p 數量
npidle uint32
// 全局 runnable G 隊列
runq gQueue
runqsize int32
// 有效 dead G 的全局緩存.
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// sudog 結構的集中緩存
sudoglock mutex
sudogcache *sudog
// defer 結構的池
deferlock mutex
deferpool [5]*_defer
...
}(2) 重要的全局變量
allgs []*g // 保存所有的g
allm *m // 所有的m構成的一個鏈表,包括下面的m0
allp []*p // 保存所有的p,len(allp) == gomaxprocs
ncpu int32 // 系統中cpu核的數量,程序啟動時由runtime代碼初始化
gomaxprocs int32 // p的最大值,默認等于ncpu,但可以通過GOMAXPROCS修改
sched schedt // 調度器結構體對象,記錄了調度器的工作狀態
m0 m // 代表進程的主線程
g0 g // m0的g0,也就是m0.g0 = &g0在程序初始化時,這些全變量都會被初始化為0值,指針會被初始化為nil指針,切片初始化為nil切片,int被初始化為數字0,結構體的所有成員變量按其本類型初始化為其類型的0值。所以程序剛啟動時allgs,allm和allp都不包含任何g,m和p。
(3) 線程執行的代碼是如何找到屬于自己的那個m結構體實例對象的呢
前面我們說GMP模型中每個工作線程都有一個m結構體對象與之對應,但并未詳細說明它們之間是如何對應起來的~ 如果只有一個工作線程,那么就只會有一個m結構體對象,問題就很簡單,定義一個全局的m結構體變量就行了。可是我們有多個工作線程和多個m需要一一對應,這里就需要用到線程的本地存儲了。
(4) 線程本地存儲(TLS)
TLS 是一種機制,允許每個線程有自己的獨立數據副本。這意味著多個線程可以同時運行而不會相互干擾,因為每個線程都可以訪問自己的數據副本。
① 寄存器中**fs 段的作用**
在 Linux 系統中,fs 段可以用于存儲線程的 TLS 數據,通常通過 fs 段寄存器來訪問。
② go 語言中的使用
- 在 Go 語言的運行時(runtime)中,fs 段被用來存儲與每個 goroutine 相關的線程局部數據。Go 的 GMP 模型(goroutine, M, P)中,m 結構體的 tls 字段通常會被設置為當前線程的 fs 段,以便快速訪問線程局部存儲。
- 通過將 fs 段與 m 結構體的 tls 字段關聯,Go 可以高效地管理和訪問每個 goroutine 的特定數據。
具體到goroutine調度器代碼,每個工作線程在剛剛被創建出來進入調度循環之前就利用線程本地存儲機制為該工作線程實現了一個指向m結構體實例對象的私有全局變量,這樣在之后的代碼中就使用該全局變量來訪問自己的m結構體對象以及與m相關聯的p和g對象。
有了上述數據結構以及工作線程與數據結構之間的映射機制,我們可以再豐富下前面講到的初始調度模型:
// 程序啟動時的初始化代碼
......
for i := 0; i < N; i++ { // 創建N個操作系統線程執行schedule函數
create_os_thread(schedule) // 創建一個操作系統線程執行schedule函數
}
// 定義一個線程私有全局變量,注意它是一個指向m結構體對象的指針
// ThreadLocal用來定義線程私有全局變量
ThreadLocal self *m
//schedule函數實現調度邏輯
func schedule() {
// 創建和初始化m結構體對象,并賦值給私有全局變量self
self = initm()
for { //調度循環
if (self.p.runqueue is empty) {
// 根據某種算法從全局運行隊列中找出一個需要運行的goroutine
g := find_a_runnable_goroutine_from_global_runqueue()
} else {
// 根據某種算法從私有的局部運行隊列中找出一個需要運行的goroutine
g := find_a_runnable_goroutine_from_local_runqueue()
}
run_g(g) // CPU運行該goroutine,直到需要調度其它goroutine才返回
save_status_of_g(g) // 保存goroutine的狀態,主要是寄存器的值
}
}僅僅從上面這個偽代碼來看,我們完全不需要線程私有全局變量,只需在schedule函數中定義一個局部變量就行了。但真實的調度代碼錯綜復雜,不光是這個schedule函數會需要訪問m,其它很多地方還需要訪問它,所以需要使用全局變量來方便其它地方對m的以及與m相關的g和p的訪問。
三、從main函數啟動開始分析
下面我們通過一個簡單的go程序入手分析 調度器的初始化,go routine的創建與退出,工作線程的調度循環以及goroutine的切換。
package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}1.程序入口
linux amd64系統的啟動函數是在asm_amd64.s的runtime·rt0_go函數中。當然,不同的平臺有不同的程序入口。rt0_go函數完成了go程序啟動時的所有初始化工作,因此這個函數比較長,也比較繁雜,但這里我們只關注與調度器相關的一些初始化,下面我們分段來看:
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
// copy arguments forward on an even stack
MOVQ DI, AX // 這行代碼將寄存器 `DI` 的值(通常是命令行參數的數量,即 `argc`)復制到寄存器 `AX` 中。`AX` 現在存儲了程序的參數個數
MOVQ SI, BX // 這行代碼將寄存器 `SI` 的值(通常是指向命令行參數字符串數組的指針,即 `argv`)復制到寄存器 `BX` 中。`BX` 現在存儲了指向命令行參數的指針。
SUBQ $(5*8), SP // 這行代碼從棧指針 `SP` 中減去 `40` 字節(`5*8`),為局部變量和函數參數分配空間。這里的 `5` 可能表示 3 個參數和 2 個自動變量(局部變量)。這行代碼的目的是在棧上為這些變量留出空間。
ANDQ $~15, SP // 這行代碼將棧指針 `SP` 對齊到 16 字節的邊界。確保棧在函數調用時是對齊的
MOVQ AX, 24(SP) // 這行代碼將 `AX` 中的值(即 `argc`)存儲到棧上相對于 `SP` 的偏移量 +`24` 的位置。
MOVQ BX, 32(SP) // - 這行代碼將 `BX` 中的值(即 `argv`)存儲到棧上相對于 `SP` 的偏移量 +`32` 的位置。上面的第4條指令用于調整棧頂寄存器的值使其按16字節對齊,也就是讓棧頂寄存器SP指向的內存的地址為16的倍數,最后兩條指令把argc和argv搬到新的位置。
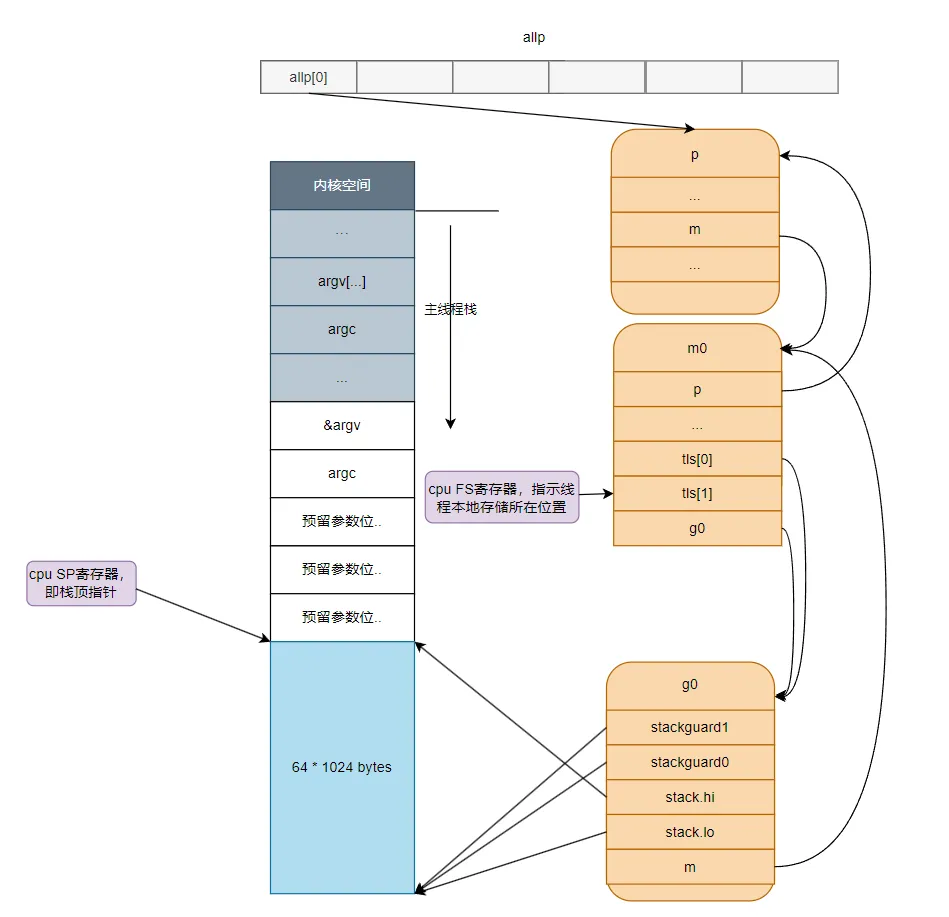
2.初始化g0
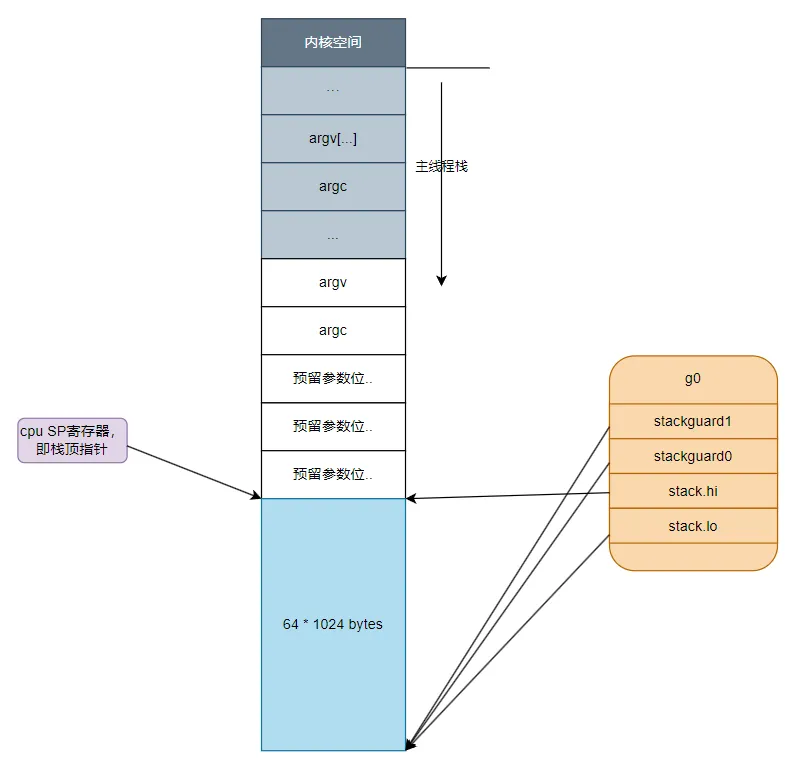
繼續看后面的代碼,下面開始初始化全局變量g0,前面我們說過,g0的主要作用是提供一個棧供runtime代碼執行,因此這里主要對g0的幾個與棧有關的成員進行了初始化,從這里可以看出g0的棧大約有64K。
從系統線程的棧中劃分出一部分作為g0的棧,然后初始化g0的棧信息和stackgard
MOVQ $runtime·g0(SB), DI // 把g0的地址放入寄存器DI
LEAQ (-64*1024)(SP), BX // 設置寄存器BX的值為 SP(主線程棧棧頂指針) - 64k 的位置
MOVQ BX, g_stackguard0(DI) // g0.stackguard0 = BX , 也就是設置g0.stackguard0 指向主線程棧的棧頂-64k的位置
MOVQ BX, g_stackguard1(DI) //g0.stackguard1 = SP - 64k
MOVQ BX, (g_stack+stack_lo)(DI) //g0.stack_lo = SP - 64k
MOVQ SP, (g_stack+stack_hi)(DI) //g0.stack_lo = SP運行完上面這幾行指令后g0與棧之間的關系如下圖所示:
四、主線程與m0綁定
設置好g0棧之后,我們跳過CPU型號檢查以及cgo初始化相關的代碼,接著分析如何把m數據結構 和 線程綁定在一起,原因在上面已描述過:每個線程需要能快速找到自己所屬的m結構體。
LEAQ runtime·m0+m_tls(SB), DI // DI = &m0.tls,取m0的tls成員的地址到DI寄存器
CALL runtime·settls(SB) // 調用settls設置線程本地存儲,settls函數的參數在DI寄存器中
// store through it, to make sure it works
// 驗證settls是否可以正常工作,如果有問題則abort退出程序
get_tls(BX) //獲取fs段基地址并放入BX寄存器,其實就是m0.tls[1]的地址,get_tls的代碼由編譯器生成
MOVQ $0x123, g(BX) //把整型常量0x123設置到線程本地存儲中
MOVQ runtime·m0+m_tls(SB), AX //獲取m.tls結構體的地址到AX寄存器中
CMPQ AX, $0x123 // 判斷m.tls[0]的值是否等于123,是的話說明tls工作正常
JEQ 2(PC)
CALL runtime·abort(SB)設置 tls 的函數 runtime·settls(SB) 位于源碼 src/runtime/sys_linux_amd64.s 處,主要內容就是通過一個系統調用將 fs 段基址設置成 m.tls[1] 的地址,而 fs 段基址又可以通過 CPU 里的寄存器 fs 來獲取。這段代碼運行后,工作線程代碼就可以通過CPU的 fs 寄存器來找到 m.tls。
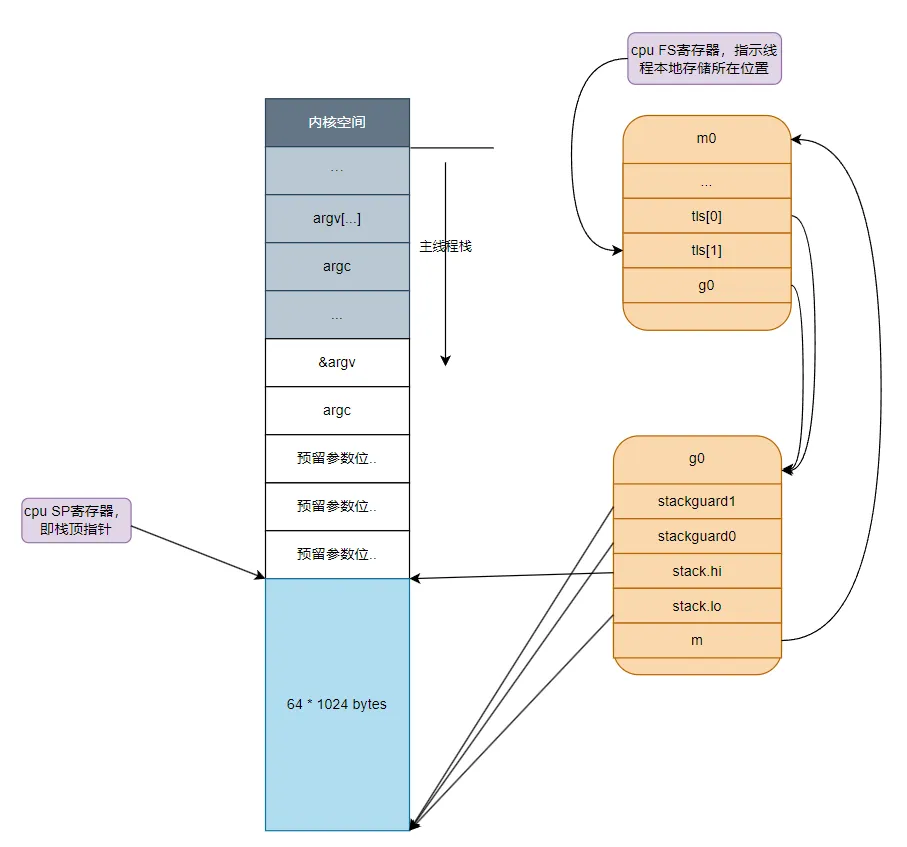
1.m0和g0綁定
ok:
// set the per-goroutine and per-mach "registers"
get_tls(BX) //獲取fs段基址到BX寄存器
LEAQ runtime·g0(SB), CX //CX = g0的地址
MOVQ CX, g(BX) //把g0的地址保存在線程本地存儲里面,也就是m0.tls[0]=&g0
LEAQ runtime·m0(SB), AX //AX = m0的地址
// 下面把m0和g0關聯起來m0->g0 = g0,g0->m = m0 // save m->g0 = g0
// save m->g0 = g0
MOVQ CX, m_g0(AX) //m0.g0 = g0
// save m0 to g0->m
MOVQ AX, g_m(CX) //g0.m = m0上面的代碼首先把g0的地址放入主線程的線程本地存儲中,然后把m0和g0綁定在一起,這樣,之后在主線程中通過get_tls可以獲取到g0,通過g0的m成員又可以找到m0,于是這里就實現了m0和g0與主線程之間的關聯。
從這里還可以看到,保存在主線程本地存儲中的值是g0的地址,也就是說工作線程的私有全局變量其實是一個指向g的指針而不是指向m的指針,目前這個指針指向g0,表示代碼正運行在g0棧。此時,主線程,m0,g0以及g0的棧之間的關系如下圖所示:
2.初始化m0
CALL runtime·check(SB)
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
CALL runtime·osinit(SB)
// 調度器初始化
CALL runtime·schedinit(SB)
// 新建一個 goroutine,該 goroutine 綁定 runtime.main
MOVQ $runtime·mainPC(SB), AX // entry
PUSHQ AX
CALL runtime·newproc(SB)
POPQ AX
// 啟動M,開始調度循環,運行剛剛創建的goroutine
CALL runtime·mstart(SB)
// 上面的mstart永遠不應該返回的,如果返回了,一定是代碼邏輯有問題,直接abort
CALL runtime·abort(SB) // mstart should never return
RET上面的CALL方法中:
- schedinit進行各種運行時組件初始化工作,這包括我們的調度器與內存分配器、回收器的初始化;
- newproc負責根據主 G 入口地址創建可被運行時調度的執行單元;
- mstart開始啟動調度器的調度循環;
3.調度器初始化(schedinit)
func schedinit() {
// raceinit must be the first call to race detector.
// In particular, it must be done before mallocinit below calls racemapshadow.
//getg函數在源代碼中沒有對應的定義,由編譯器插入類似下面兩行代碼
//get_tls(CX)
//MOVQ g(CX), BX; BX存器里面現在放的是當前g結構體對象的地址
_g_ := getg() // _g_ = &g0
......
//設置最多啟動10000個操作系統線程,也是最多10000個M
sched.maxmcount = 10000
......
mcommoninit(_g_.m) //初始化m0,因為從前面的代碼我們知道g0->m = &m0
......
sched.lastpoll = uint64(nanotime())
procs := ncpu //系統中有多少核,就創建和初始化多少個p結構體對象
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n //如果環境變量指定了GOMAXPROCS,則創建指定數量的p
}
if procresize(procs) != nil {//創建和初始化全局變量allp
throw("unknown runnable goroutine during bootstrap")
}
......
}前面我們已經看到,g0的地址已經被設置到了線程本地存儲之中,schedinit通過getg函數(getg函數是編譯器實現的,我們在源代碼中是找不到其定義的)從線程本地存儲中獲取當前正在運行的g,這里獲取出來的是g0,然后調用mcommoninit函數對m0(g0.m)進行必要的初始化,對m0初始化完成之后調用procresize初始化系統需要用到的p結構體對象,p就是processor的意思,它的數量決定了最多可以有多少個goroutine同時并行運行。
schedinit函數除了初始化m0和p,還設置了全局變量sched的maxmcount成員為10000,限制最多可以創建10000個操作系統線程出來工作。
(1) M0 初始化
func mcommoninit(mp *m, id int64) {
_g_ := getg()
...
lock(&sched.lock)
// 如果傳入id小于0,那么id則從mReserveID獲取,初次從mReserveID獲取id為0
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
//random初始化,用于竊取 G
mp.fastrand[0] = uint32(int64Hash(uint64(mp.id), fastrandseed))
mp.fastrand[1] = uint32(int64Hash(uint64(cputicks()), ^fastrandseed))
if mp.fastrand[0]|mp.fastrand[1] == 0 {
mp.fastrand[1] = 1
}
// 創建用于信號處理的gsignal,只是簡單的從堆上分配一個g結構體對象,然后把棧設置好就返回了
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard
}
// 把 M 掛入全局鏈表allm之中
mp.alllink = allm
...
}這里傳入的 id 是-1,初次調用會將 id 設置為 0,這里并未對m0做什么關于調度相關的初始化,所以可以簡單的認為這個函數只是把m0放入全局鏈表allm之中就返回了。
m0完成基本的初始化后,繼續調用procresize創建和初始化p結構體對象,在這個函數里面會創建指定個數(根據cpu核數或環境變量確定)的p結構體對象放在全變量allp里, 并把m0和allp[0]綁定在一起,因此當這個函數執行完成之后就有。
m0.p = allp[0]
allp[0].m = &m0到這里m0, g0, 和m需要的p完全關聯在一起了
(2) P初始化
由于用戶代碼運行過程中也支持通過 GOMAXPROCS()函數調用procresize來重新創建和初始化p結構體對象,而在運行過程中再動態的調整p牽涉到的問題比較多,所以這個函數的處理比較復雜,這里只保留了初始化時會執行的代碼。
func procresize(nprocs int32) *p {
old := gomaxprocs //系統初始化時 gomaxprocs = 0
......
// Grow allp if necessary.
if nprocs > int32(len(allp)) { //初始化時 len(allp) == 0
// Synchronize with retake, which could be running
// concurrently since it doesn't run on a P.
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
//初始化時進入此分支,創建allp 切片
nallp := make([]*p, nprocs)
// Copy everything up to allp's cap so we
// never lose old allocated Ps.
copy(nallp, allp[:cap(allp)])
allp = nallp
}
unlock(&allpLock)
}
// initialize new P's
//循環創建nprocs個p并完成基本初始化
for i := int32(0); i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)//調用內存分配器從堆上分配一個struct p
pp.id = i
pp.status = _Pgcstop
......
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
......
}
......
_g_ := getg() // _g_ = g0
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {//初始化時m0->p還未初始化,所以不會執行這個分支
// continue to use the current P
_g_.m.p.ptr().status = _Prunning
_g_.m.p.ptr().mcache.prepareForSweep()
} else {
//初始化時執行這個分支
// release the current P and acquire allp[0]
if _g_.m.p != 0 {//初始化時這里不執行
_g_.m.p.ptr().m = 0
}
_g_.m.p = 0
_g_.m.mcache = nil
p := allp[0]
p.m = 0
p.status = _Pidle
acquirep(p) //把p和m0關聯起來,其實是這兩個strct的成員相互賦值
if trace.enabled {
traceGoStart()
}
}
//下面這個for 循環把所有空閑的p放入空閑鏈表
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
if _g_.m.p.ptr() == p {//allp[0]跟m0關聯了,所以是不能放任
continue
}
p.status = _Pidle
if runqempty(p) {//初始化時除了allp[0]其它p全部執行這個分支,放入空閑鏈表
pidleput(p)
} else {
......
}
}
......
return runnablePs
}這里總結一下這個函數的主要流程:
- 使用make([]*p, nprocs)初始化全局變量allp,即allp = make([]*p, nprocs)
- 循環創建并初始化nprocs個p結構體對象并依次保存在allp切片之中
- 把m0和allp[0]綁定在一起,即m0.p = allp[0], allp[0].m = m0
- 把除了allp[0]之外的所有p放入到全局變量sched的pidle空閑隊列之中
下面我們用圖來總結下整個調度器各部分的組成:
(3) goroutine的創建(newproc)
經過上文介紹我們介紹m0初始化中有說到,初始化過程中會新建一個 goroutine,該 goroutine 綁定 runtime.main,而runtime.main實際上最后會走到我們實現的main函數上。新建goroutine的操作就是通過newproc()調用來實現的。
newproc函數用于創建新的goroutine,它有兩個參數,先說第二個參數fn,新創建出來的goroutine將從fn這個函數開始執行,而這個fn函數可能也會有參數,newproc的第一個參數正是fn函數的參數以字節為單位的大小。比如有如下go代碼片段:
func start(a, b, c int64) {
......
}
func main() {
go start(1, 2, 3)
}編譯器在編譯上面的go語句時,就會把其替換為對newproc函數的調用,編譯后的代碼邏輯上等同于下面的偽代碼。
func main() {
push 0x3
push 0x2
push 0x1
runtime.newproc(24, start)
}可以看到編譯器會幫我們把三個參數1,2,3分別壓棧作為start函數的參數,然后再調用newproc函數。我們會注意到newproc函數本身還需要兩個參數,第一個是24,表示start函數需要24個字節大小的參數 為什么需要傳遞start函數的參數大小給到newproc函數呢? 這里是因為新建goroutine會在堆上創建一個全新的棧,需要把start需要用到的參數先從當前goroutine的棧上拷貝到新的goroutine的棧上之后才能讓其開始執行,而newproc函數本身并不知道需要拷貝多少數據到新創建的goroutine的棧上去,所以需要用參數的方式指定拷貝多少數據。
newproc函數是對newproc1的一個包裝,這里最重要的準備工作有兩個,一個是獲取fn函數第一個參數的地址(代碼中的argp),另一個是使用systemstack函數切換到g0棧,當然,對于我們這個初始化場景來說現在本來就在g0棧,所以不需要切換,然而這個函數是通用的,在用戶的goroutine中也會創建goroutine,這時就需要進行棧的切換。
// Create a new g running fn with siz bytes of arguments.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
// Cannot split the stack because it assumes that the arguments
// are available sequentially after &fn; they would not be
// copied if a stack split occurred.
//go:nosplit
func newproc(siz int32, fn *funcval) {
//函數調用參數入棧順序是從右向左,而且棧是從高地址向低地址增長的
//注意:argp指向fn函數的第一個參數,而不是newproc函數的參數
//參數fn在棧上的地址+8的位置存放的是fn函數的第一個參數
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg() //獲取正在運行的g,初始化時是m0.g0
//getcallerpc()返回一個地址,也就是調用newproc時由call指令壓棧的函數返回地址,
//對于我們現在這個場景來說,pc就是CALLruntime·newproc(SB)指令后面的POPQ AX這條指令的地址
pc := getcallerpc()
//systemstack的作用是切換到g0棧執行作為參數的函數
//我們這個場景現在本身就在g0棧,因此什么也不做,直接調用作為參數的函數
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, gp, pc)
})
}newproc1函數的第一個參數fn是新創建的goroutine需要執行的函數,注意這個fn的類型是funcval結構體類型,其定義如下:
type funcval struct {
fn uintptr
// variable-size, fn-specific data here
}第二個參數argp是fn函數的第一個參數的地址,第三個參數是fn函數的參數以字節為單位的大小,后面兩個參數我們不用關心。這里需要注意的是,newproc1是在g0的棧上執行的。
// Create a new g running fn with narg bytes of arguments starting
// at argp. callerpc is the address of the go statement that created
// this. The new g is put on the queue of g's waiting to run.
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
//因為已經切換到g0棧,所以無論什么場景都有 _g_ = g0,當然這個g0是指當前工作線程的g0
//對于我們這個場景來說,當前工作線程是主線程,所以這里的g0 = m0.g0
_g_ := getg()
......
_p_ := _g_.m.p.ptr() //初始化時_p_ = g0.m.p,從前面的分析可以知道其實就是allp[0]
newg := gfget(_p_) //從p的本地緩沖里獲取一個沒有使用的g,初始化時沒有,返回nil
if newg == nil {
//new一個g結構體對象,然后從堆上為其分配棧,并設置g的stack成員和兩個stackgard成員
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead) //初始化g的狀態為_Gdead
//放入全局變量allgs切片中
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
......
//調整g的棧頂置針,無需關注
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.SpAlign - 1) // align to spAlign
sp := newg.stack.hi - totalSize
spArg := sp
//......
if narg > 0 {
//把參數從執行newproc函數的棧(初始化時是g0棧)拷貝到新g的棧
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
// ......
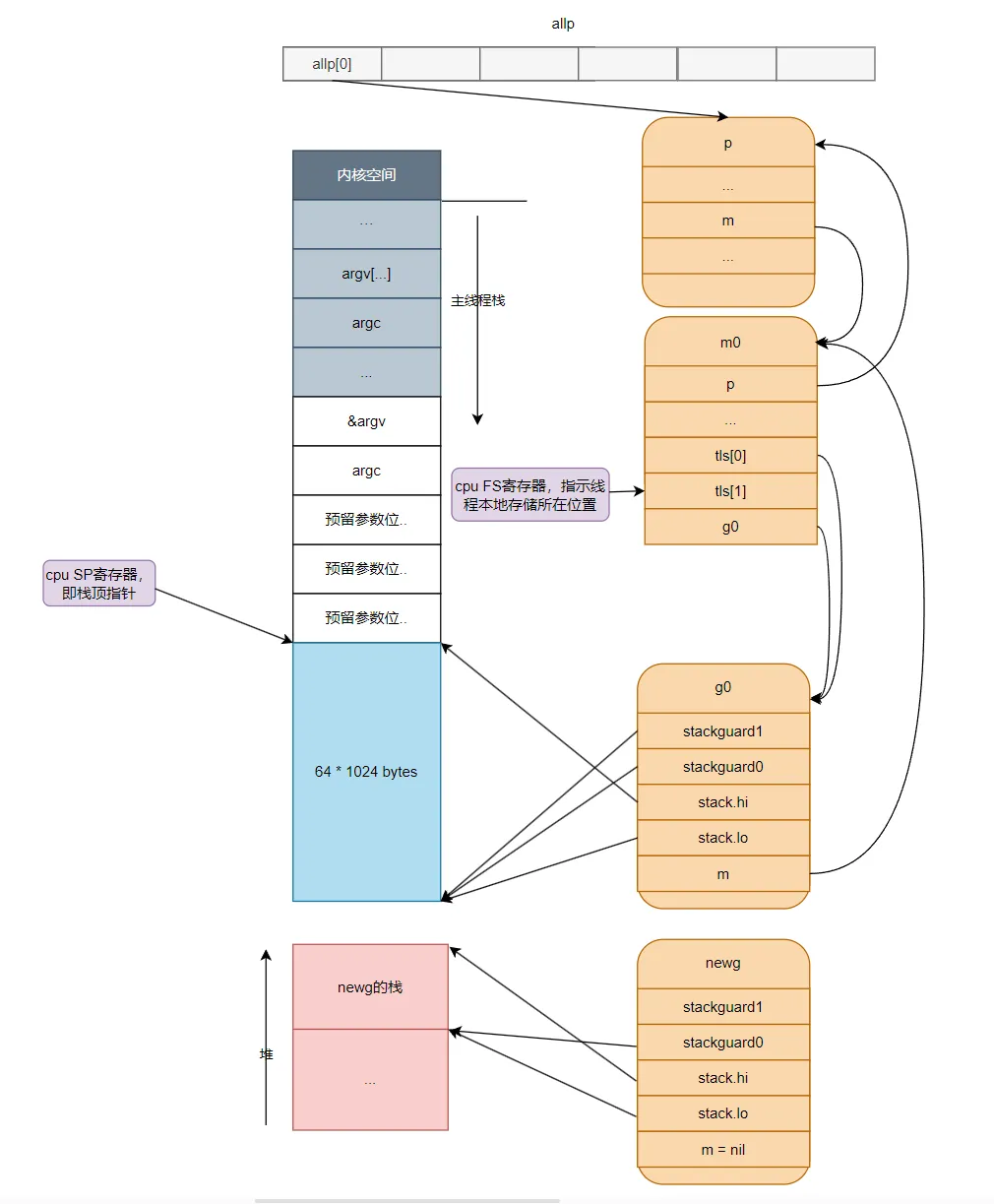
}這段代碼主要從堆上分配一個g結構體對象并為這個newg分配一個大小為2048字節的棧,并設置好newg的stack成員,然后把newg需要執行的函數的參數從執行newproc函數的棧(初始化時是g0棧)拷貝到newg的棧,完成這些事情之后newg的狀態如下圖所示:這里需要注意的是,新創建出來的g都是在堆上分配內存的,主要有以下幾個原因:
- 生命周期:goroutine的生命周期可能會超過創建它的函數的生命周期。如果在棧上分配goroutine,那么當創建goroutine的函數返回時,goroutine可能還在運行,這將導致棧被回收,從而引發錯誤。而在堆上分配goroutine可以避免這個問題,因為堆上的內存只有在沒有任何引用指向它時才會被垃圾回收。
- 大小:goroutine的棧大小是動態的,它可以根據需要進行擴展和收縮。如果在棧上分配goroutine,那么每次goroutine的棧大小改變時,都需要移動整個goroutine的內存,這將導致大量的性能開銷。而在堆上分配goroutine可以避免這個問題,因為堆上的內存可以動態地進行擴展和收縮。
- 并發:在go語言中,可以同時運行多個goroutine。如果在棧上分配goroutine,那么每個線程的棧大小都需要足夠大,以容納所有的goroutine,這將導致大量的內存浪費。而在堆上分配goroutine可以避免這個問題,因為堆是所有線程共享的,因此可以更有效地利用內存。因此,出于生命周期、大小和并發等考慮,GMP模型中新創建的goroutine都是在堆上分配內存的。下面讓我們用一個圖示來總結下目前的GMP模型中各個部分的情況。
繼續分析newproc1():
//把newg.sched結構體成員的所有成員設置為0
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
//設置newg的sched成員,調度器需要依靠這些字段才能把goroutine調度到CPU上運行。
newg.sched.sp = sp //newg的棧頂
newg.stktopsp = sp
//newg.sched.pc表示當newg被調度起來運行時從這個地址開始執行指令
//把pc設置成了goexit這個函數偏移1(sys.PCQuantum等于1)的位置,
//至于為什么要這么做需要等到分析完gostartcallfn函數才知道
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn) //調整sched成員和newg的棧
// adjust Gobuf as if it executed a call to fn
// and then did an immediate gosave.
func gostartcallfn(gobuf *gobuf, fv *funcval) {
var fn unsafe.Pointer
if fv != nil {
fn = unsafe.Pointer(fv.fn) //fn: goroutine的入口地址,初始化時對應的是runtime.main
} else {
fn = unsafe.Pointer(funcPC(nilfunc))
}
gostartcall(gobuf, fn, unsafe.Pointer(fv))
}
// adjust Gobuf as if it executed a call to fn with context ctxt
// and then did an immediate gosave.
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp //newg的棧頂,目前newg棧上只有fn函數的參數,sp指向的是fn的第一參數
if sys.RegSize > sys.PtrSize {
sp -= sys.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = 0
}
sp -= sys.PtrSize //為返回地址預留空間,
//這里在偽裝fn是被goexit函數調用的,使得fn執行完后返回到goexit繼續執行,從而完成清理工作
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc //在棧上放入goexit+1的地址
buf.sp = sp //重新設置newg的棧頂寄存器
//這里才真正讓newg的ip寄存器指向fn函數,注意,這里只是在設置newg的一些信息,newg還未執行,
//等到newg被調度起來運行時,調度器會把buf.pc放入cpu的IP寄存器,
//從而使newg得以在cpu上真正的運行起來
buf.pc = uintptr(fn)
buf.ctxt = ctxt
}gostartcall函數的主要作用有兩個:
- 調整newg的棧空間,把goexit函數的第二條指令的地址入棧,偽造成goexit函數調用了fn,從而使fn執行完成后執行ret指令時返回到goexit繼續執行完成最后的清理工作;
- 重新設置newg.buf.pc 為需要執行的函數的地址,即fn,我們這個場景為runtime.main函數的地址,如果是在運行中go aa()啟動的協程,那么newg.buf.pc會為aa()函數的地址。
//newg真正從哪里開始執行并不依賴于這個成員,而是sched.pc
newg.startpc = fn.fn
......
//設置g的狀態為_Grunnable,表示這個g代表的goroutine可以運行了
casgstatus(newg, _Gdead, _Grunnable)
......
//把newg放入_p_的運行隊列,初始化的時候一定是p的本地運行隊列,其它時候可能因為本地隊列滿了而放入全局隊列
runqput(_p_, newg, true)
......
}這時newg也就是main goroutine的狀態如下圖所示:
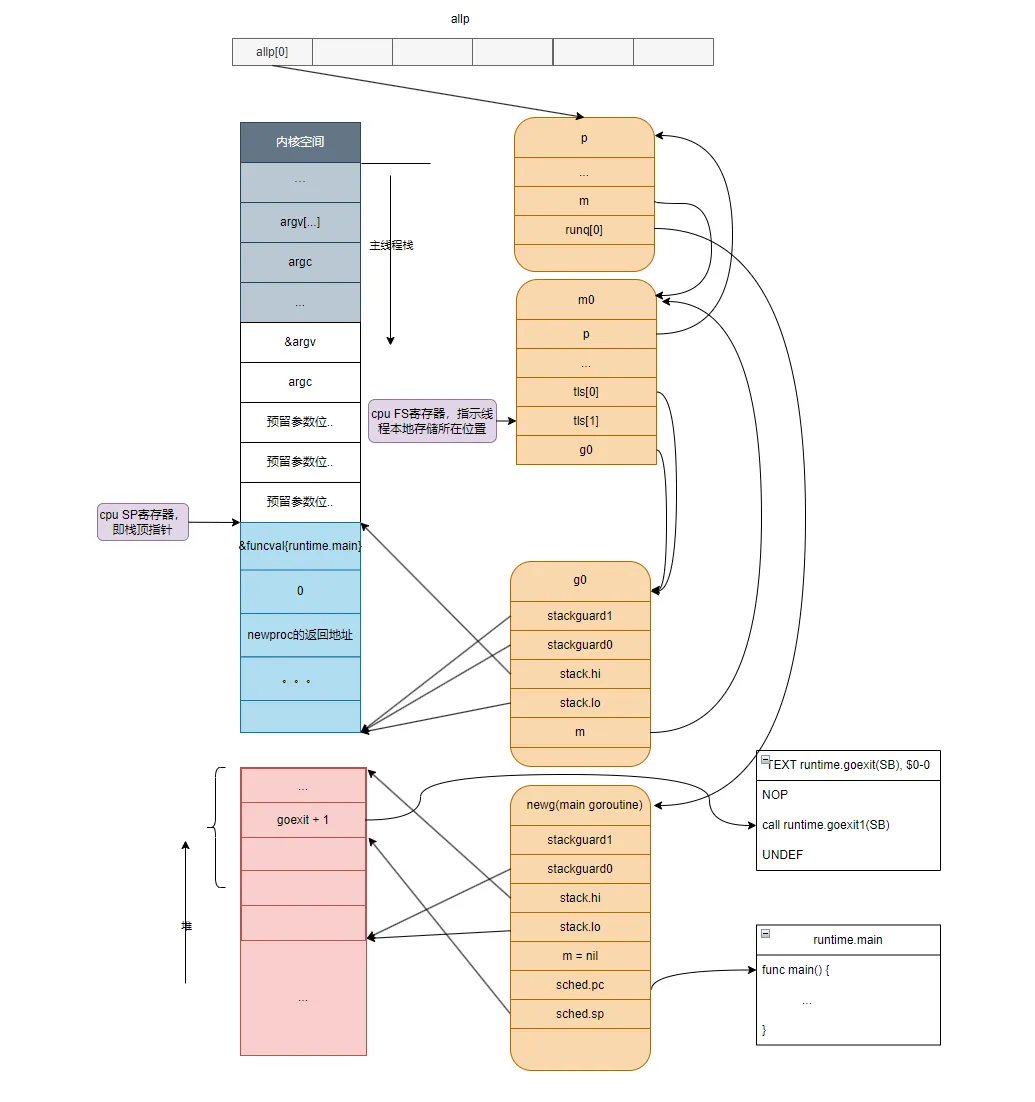
可以看到newproc執行完畢時,p, m0, g0, newg, allp的內存均已分配好且它們之間的關系也通過指針掛鉤上,我們留意下newg的堆棧中目前棧頂是 goexit+1 這個位置的返回地址;目前newg尚未被調度起來運行,只是剛加入p的本地隊列,后續該newg被cpu調度到時,cpu sp寄存器會指向棧頂,在newg自身的邏輯開始執行后,newg的棧內存會被不斷使用,SP寄存器不斷移動來指示棧的內存的增長與回收,當所有邏輯執行完時,sp寄存器重新指回這個goexit+1 這個位置。最后彈出該位置的值作為cpu rip寄存器的值,從而去執行 runtime.goexit1(SB) 這個命令,繼續進行調度循環(這個后面會講到)。
下面我們總結下newproc做了什么事情:
- 在堆上給新goroutine分配一段內存作為棧空間,設置堆棧信息到新goroutine對應的g結構體上,核心是設置gobuf.pc指向要執行的代碼段,待調度到該g時,會將保存的pc值設置到cpu的RIP寄存器上從而去執行該goroutine對應的代碼。
- 把傳遞給goroutine的參數從當前棧拷貝到新goroutine所在的棧上。
- 把g加入到p的本地隊列等待調度,如果本地隊列滿了會加入到全局隊列(程序剛啟動時只會加入到p的本地隊列)。
4.調度循環的啟動(mstart)
前面我們完成了 newproc 函數,接下來是runtime·rt0_go中的最后一步,啟動調度循環,即mstart函數。
func mstart0() {
gp := getg()
...
// Initialize stack guard so that we can start calling regular
// Go code.
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
mstart1()
// Exit this thread.
if GOOS == "windows" || GOOS == "solaris" || GOOS == "plan9" || GOOS == "darwin" || GOOS == "aix" {
// Window, Solaris, Darwin, AIX and Plan 9 always system-allocate
// the stack, but put it in _g_.stack before mstart,
// so the logic above hasn't set osStack yet.
osStack = true
}
}mstart 函數設置了 stackguard0 和 stackguard1 字段后,就直接調用 mstart1() 函數,由于只分析main goroutine的啟動,這里省略部分無關的代碼:
func mstart1() {
// 啟動過程時 _g_ = m0.g0
_g_ := getg()
//getcallerpc()獲取mstart1執行完的返回地址
//getcallersp()獲取調用mstart1時的棧頂地址
save(getcallerpc(), getcallersp())
...
// 進入調度循環。永不返回
schedule()save函數非常重要,它主要做了這兩個操作:
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()將mstart調用mstart1的返回地址以及當時的棧頂指針保存到g0的sched結構中,保存好后,我們可以看到現在的指針指向情況(注意紅線部分) 。
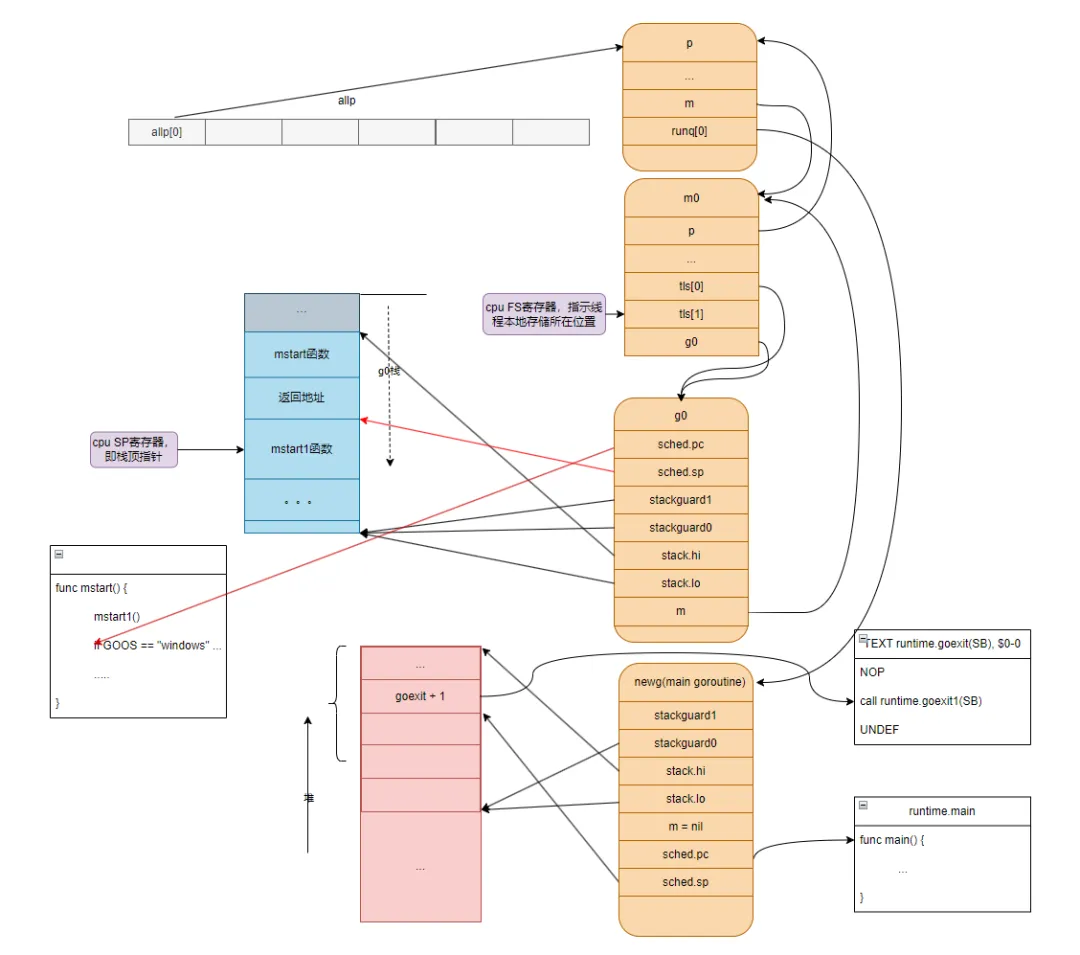
這里設置好后,g0對象的sp值就不會變化了,一直指向mstart函數的棧頂,后續每次切換回g0時,都會從g0對象的sp值中恢復寄存器SP,從而切換到g0棧。
繼續分析代碼,先看下schedule()函數的邏輯,這是GMP模型調度邏輯的核心,每次調度goroutine都是從它開始的:
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
_g_ := getg() //_g_ = 每個工作線程m對應的g0,初始化時是m0的g0
//......
var gp *g
//......
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
//為了保證調度的公平性,每進行61次調度就需要優先從全局運行隊列中獲取goroutine,
//因為如果只調度本地隊列中的g,那么全局運行隊列中的goroutine將得不到運行
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock) //所有工作線程都能訪問全局運行隊列,所以需要加鎖
gp = globrunqget(_g_.m.p.ptr(), 1) //從全局運行隊列中獲取1個goroutine
unlock(&sched.lock)
}
}
if gp == nil {
//從與m關聯的p的本地運行隊列中獲取goroutine
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
//如果從本地運行隊列和全局運行隊列都沒有找到需要運行的goroutine,
//則調用findrunnable函數從其它工作線程的運行隊列中偷取,如果偷取不到,則當前工作線程進入睡眠,
//直到獲取到需要運行的goroutine之后findrunnable函數才會返回。
gp, inheritTime = findrunnable() // blocks until work is available
}
//跟啟動無關的代碼.....
//當前運行的是runtime的代碼,函數調用棧使用的是g0的棧空間
//調用execte切換到gp的代碼和棧空間去運行
execute(gp, inheritTime)
}schedule函數優先從p本地隊列獲取goroutine,獲取不到時會去全局運行隊列中加鎖獲取goroutine,在我們的場景中,前面的啟動流程已經創建好第一個goroutine并放入了當前工作線程的本地運行隊列(即runtime.main對應的goroutine)。獲取到g后,會調用execute去切換到g,具體的切換邏輯繼續看下execute函數。
func execute(gp *g, inheritTime bool) {
_g_ := getg() //g0
//設置待運行g的狀態為_Grunning
casgstatus(gp, _Grunnable, _Grunning)
//......
//把g和m關聯起來
_g_.m.curg = gp
gp.m = _g_.m
//......
//gogo完成從g0到gp真正的切換
gogo(&gp.sched)
}這里的重點是gogo函數,真正完成了g0到g的切換,切換的實質就是CPU寄存器以及函數調用棧的切換:
TEXT runtime·gogo(SB), NOSPLIT, $16-8
//buf = &gp.sched
MOVQ buf+0(FP), BX # BX = buf
//gobuf->g --> dx register
MOVQ gobuf_g(BX), DX # DX = gp.sched.g
//下面這行代碼沒有實質作用,檢查gp.sched.g是否是nil,如果是nil進程會crash死掉
MOVQ 0(DX), CX # make sure g != nil
get_tls(CX)
//把要運行的g的指針放入線程本地存儲,這樣后面的代碼就可以通過線程本地存儲
//獲取到當前正在執行的goroutine的g結構體對象,從而找到與之關聯的m和p
MOVQ DX, g(CX)
//把CPU的SP寄存器設置為sched.sp,完成了棧的切換(畫重點!)
MOVQ gobuf_sp(BX), SP # restore SP
//下面三條同樣是恢復調度上下文到CPU相關寄存器
MOVQ gobuf_ret(BX), AX
MOVQ gobuf_ctxt(BX), DX
MOVQ gobuf_bp(BX), BP
//清空sched的值,因為我們已把相關值放入CPU對應的寄存器了,不再需要,這樣做可以少gc的工作量
MOVQ $0, gobuf_sp(BX) # clear to help garbage collector
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ $0, gobuf_bp(BX)
//把sched.pc值放入BX寄存器
MOVQ gobuf_pc(BX), BX
//JMP把BX寄存器的包含的地址值放入CPU的IP寄存器,于是,CPU跳轉到該地址繼續執行指令,
JMP BX這個函數,其實就只做了兩件事:
- 把gp.sched的成員恢復到CPU的寄存器完成狀態以及棧的切換;
- 跳轉到gp.sched.pc所指的指令地址(runtime.main)處執行。最后我們再總結一下程序開始運行后從g0棧切換到main goroutine棧的流程
保存g0的調度信息,主要是保存CPU棧頂寄存器SP到g0.sched.sp成員之中;調用schedule函數尋找需要運行的goroutine,我們這個場景找到的是main goroutine;調用gogo函數首先從g0棧切換到main goroutine的棧,然后從main goroutine的g結構體對象之中取出sched.pc的值并使用JMP指令跳轉到該地址去執行;
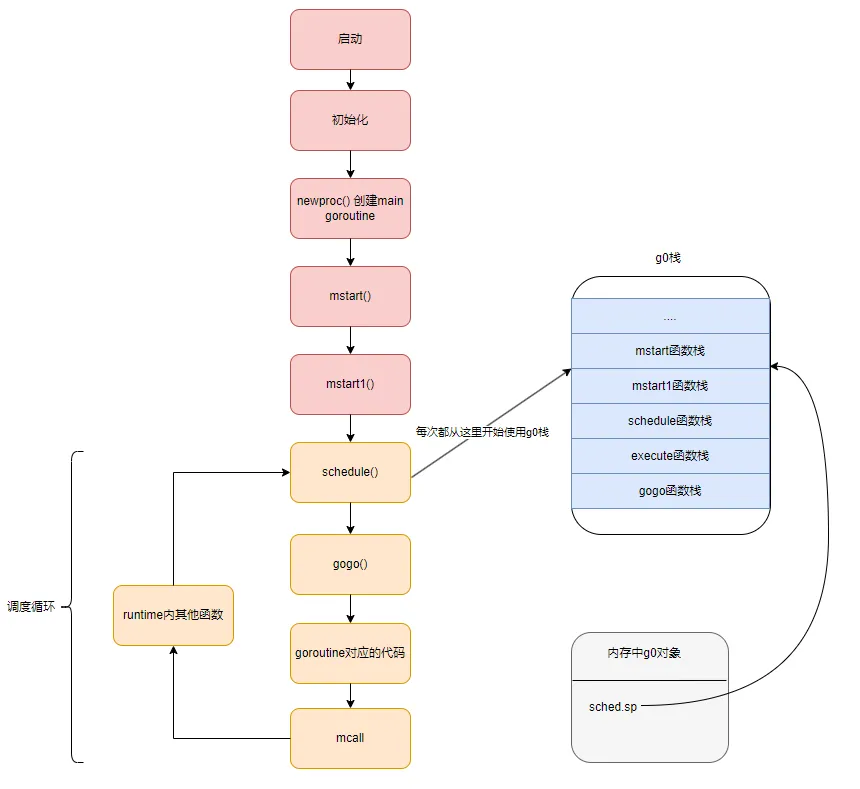
五、go的調度循環是什么
上文我們分析了main goroutine的啟動,main的goroutine和非main得goroutine稍微會有一點差別,主要在于main goutine對應的runtime.main函數,執行完畢后會直接在匯編代碼中執行exit從而退出程序,而非main goroutine在執行完對應的邏輯后,會進入調度循環,不斷找到下一個goroutine來執行。假設我們在代碼中使用go aa()啟動了一個協程,從aa()被開始調度到aa運行完后退出,是沿著這個路徑來執行的。
schedule()->execute()->gogo()->aa()->goexit()->goexit1()->mcall()->goexit0()->schedule()可以看出,一輪調度是從調用schedule函數開始的,然后經過一系列代碼的執行到最后又再次通過調用schedule函數來進行新一輪的調度,從一輪調度到新一輪調度的這一過程我們稱之為一個調度循環,這里說的調度循環是指某一個工作線程的調度循環,而同一個Go程序中可能存在多個工作線程,每個工作線程都有自己的調度循環,也就是說每個工作線程都在進行著自己的調度循環。
調度循環的細節這里就不再分析,本文就只介紹到協程調度的核心原理,相信看完本文你已經有所收獲~ 最后讓我們用一個圖來了解下調度循環的大體流程: