













從零開始了解推薦系統(tǒng)全貌
有幸參與了幾個業(yè)務(wù)推薦系統(tǒng)搭建的全流程,本文將從實際經(jīng)驗出發(fā),為大家解構(gòu)如何從零搭建推薦系統(tǒng),希望跟大家能夠相互交流,如有錯誤之處煩請指正。

一、推薦算法的理解
如果說互聯(lián)網(wǎng)的目標(biāo)就是連接一切,那么推薦系統(tǒng)的作用就是建立更加有效率的連接,推薦系統(tǒng)可以更有效率的連接用戶與內(nèi)容和服務(wù),節(jié)約了大量的時間和成本。
如果把推薦系統(tǒng)簡單拆開來看,推薦系統(tǒng)主要是由數(shù)據(jù)、算法、架構(gòu)三個方面組成。
- 數(shù)據(jù)提供了信息。數(shù)據(jù)儲存了信息,包括用戶與內(nèi)容的屬性,用戶的行為偏好例如對新聞的點擊、玩過的英雄、購買的物品等等。這些數(shù)據(jù)特征非常關(guān)鍵,甚至可以說它們決定了一個算法的上限。
- 算法提供了邏輯。數(shù)據(jù)通過不斷的積累,存儲了巨量的信息。在巨大的數(shù)據(jù)量與數(shù)據(jù)維度下,人已經(jīng)無法通過人工策略進(jìn)行分析干預(yù),因此需要基于一套復(fù)雜的信息處理邏輯,基于邏輯返回推薦的內(nèi)容或服務(wù)。
- 架構(gòu)解放了雙手。架構(gòu)保證整個推薦自動化、實時性的運(yùn)行。架構(gòu)包含了接收用戶請求,收集、處理,存儲用戶數(shù)據(jù),推薦算法計算,返回推薦結(jié)果等。有了架構(gòu)之后算法不再依賴于手動計算,可以進(jìn)行實時化、自動化的運(yùn)行。例如在淘寶推薦中,對于數(shù)據(jù)實時性的處理,就保證了用戶在點擊一個物品后,后續(xù)返回的推薦結(jié)果就可以立刻根據(jù)該點擊而改變。一個推薦系統(tǒng)的實時性要求越高、訪問量越大那么這個推薦系統(tǒng)的架構(gòu)就會越復(fù)雜。
二、推薦系統(tǒng)的整體框架
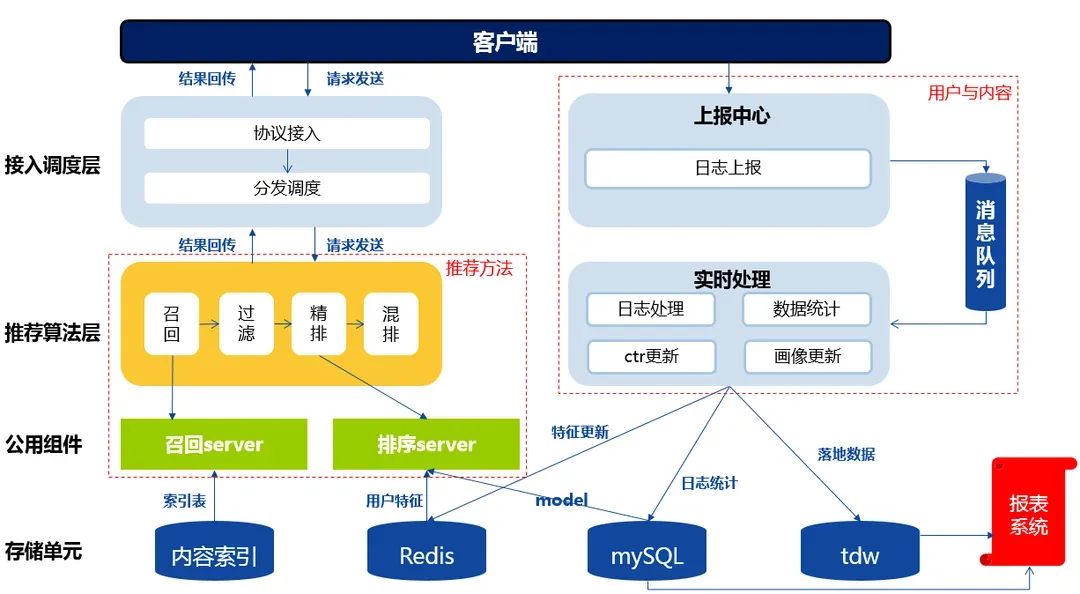
推薦的框架主要有以下幾個模塊:
- 協(xié)議調(diào)度:請求的發(fā)送和結(jié)果的回傳。在請求中,用戶會發(fā)送自己的 ID,地理位置等信息。結(jié)果回傳中會返回推薦系統(tǒng)給用戶推薦的結(jié)果。
- 推薦算法:算法按照一定的邏輯為用戶產(chǎn)生最終的推薦結(jié)果。不同的推薦算法基于不同的邏輯與數(shù)據(jù)運(yùn)算過程。
- 消息隊列:數(shù)據(jù)的上報與處理。根據(jù)用戶的 ID,拉取例如用戶的性別、之前的點擊、收藏等用戶信息。而用戶在 APP 中產(chǎn)生的新行為,例如新的點擊會儲存在存儲單元里面。
- 存儲單元:不同的數(shù)據(jù)類型和用途會儲存在不同的存儲單元中,例如內(nèi)容標(biāo)簽與內(nèi)容的索引存儲在 mysql 里,實時性數(shù)據(jù)存儲在 redis 里,需要進(jìn)行數(shù)據(jù)統(tǒng)計的數(shù)據(jù)存儲在 TDW 里。
三、用戶畫像
1. 用戶標(biāo)簽
標(biāo)簽是我們對多維事物的降維理解,抽象出事物更具有代表性的特點。 我們永遠(yuǎn)無法完全的了解一個人,所以我們只能夠通過一個一個標(biāo)簽的來刻畫他,所有的標(biāo)簽最終會構(gòu)建為一個立體的畫像,一個詳盡的用戶畫像可以幫助我們更加好的理解用戶。
2. 用戶畫像的分類
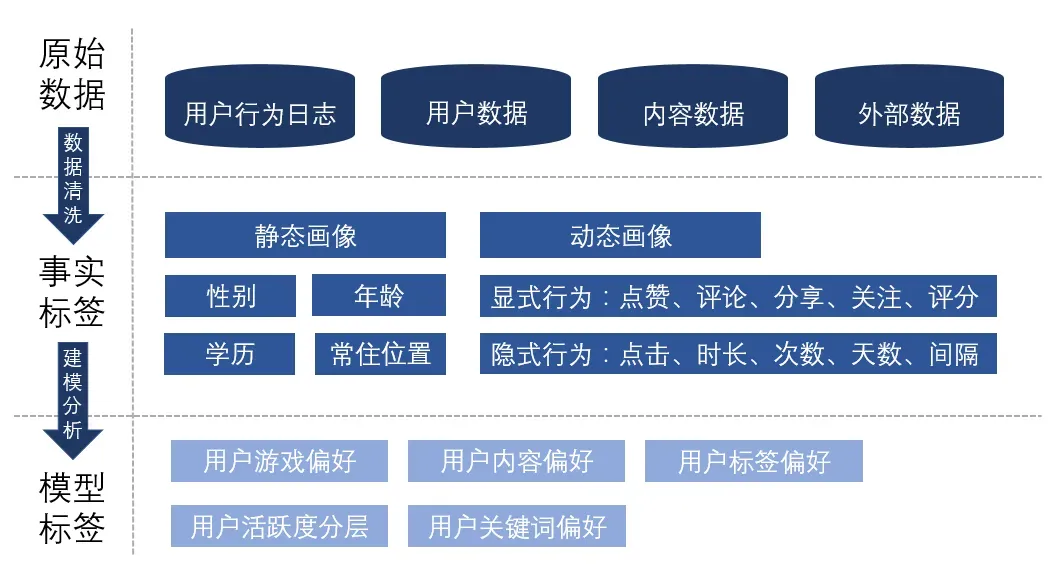
(1) 原始數(shù)據(jù)
原始數(shù)據(jù)一共包含四個方面:
- 用戶數(shù)據(jù): 例如用戶的性別、年齡、渠道、注冊時間、手機(jī)機(jī)型等。
- 內(nèi)容數(shù)據(jù): 例如游戲的品類,對游戲描述、評論的爬蟲之后得到的關(guān)鍵詞、標(biāo)簽等。
- 用戶與內(nèi)容的交互: 基于用戶的行為,了解了什么樣的用戶喜歡什么樣的游戲品類、關(guān)鍵詞、標(biāo)簽等。
- 外部數(shù)據(jù): 單一的產(chǎn)品只能描述用戶的某一類喜好,例如游戲的喜好、視頻的喜好,外部數(shù)據(jù)標(biāo)簽可以讓用戶更加的立體。
(2) 事實標(biāo)簽
事實標(biāo)簽可以分為靜態(tài)畫像和動態(tài)畫像:
- 靜態(tài)畫像: 用戶獨(dú)立于產(chǎn)品場景之外的屬性,例如用戶的自然屬性,這類信息比較穩(wěn)定,具有統(tǒng)計性意義。
- 動態(tài)畫像: 用戶在場景中所產(chǎn)生的顯示行為或隱式行為。
- 顯示行為:用戶明確的表達(dá)了自己的喜好,例如點贊、分享、關(guān)注、評分等。(評論的處理更加復(fù)雜,需要通過 NLP 的方式來判斷用戶的感情是正向、負(fù)向、中性)。
- 隱式行為:用戶沒有明確表達(dá)自己的喜好,但“口嫌體正直”,用戶會用實際行動,例如點擊、停留時長等隱性的行為表達(dá)自己的喜好。
隱式行為的權(quán)重往往不會有顯示行為大,但是在實際業(yè)務(wù)中,用戶的顯示行為都是比較稀疏的,所以需要依賴大量的隱式行為。
(3) 模型標(biāo)簽
模型標(biāo)簽是由事實標(biāo)簽通過加權(quán)計算或是聚類分析所得。通過一層加工處理后,標(biāo)簽所包含的信息量得到提升,在推薦過程中效果更好。
- 聚類分析: 例如按照用戶的活躍度進(jìn)行聚類,將用戶分為高活躍-中活躍-低活躍三類。
- 加權(quán)計算: 根據(jù)用戶的行為將用戶的標(biāo)簽加權(quán)計算,得到每一個標(biāo)簽的分?jǐn)?shù),用于之后推薦算法的計算。
四、內(nèi)容畫像
1. 內(nèi)容畫像
推薦內(nèi)容與場景通常可以分為以下幾類,根據(jù)所推薦的內(nèi)容不同,其內(nèi)容畫像的處理方式也不同。
- 文章推薦:例如新聞內(nèi)容推薦,需要利用NLP的技術(shù)對文章的標(biāo)題,正文等提取關(guān)鍵詞、標(biāo)簽、分類等。
- 視頻推薦:除了對于分類、標(biāo)題關(guān)鍵詞的抓取外,還依賴于圖片與視頻處理技術(shù),例如識別內(nèi)容標(biāo)簽、內(nèi)容相似性等。
2. 環(huán)境變量
內(nèi)容畫像外,環(huán)境畫像也非常重要。例如在短視頻的推薦場景中,用戶在看到一條視頻所處的時間、地點以及當(dāng)時所瀏覽的前后內(nèi)容、當(dāng)天已瀏覽時間等也是非常重要的信息,但由于環(huán)境變量數(shù)據(jù)量較大、類型較多,對推薦架構(gòu)以及工程實現(xiàn)能力的要求也較高。
五、算法構(gòu)建
1. 推薦算法流程
推薦算法其實本質(zhì)上是一種信息處理邏輯,當(dāng)獲取了用戶與內(nèi)容的信息之后,按照一定的邏輯處理信息后,產(chǎn)生推薦結(jié)果。熱度排行榜就是最簡單的一種推薦方法,它依賴的邏輯就是當(dāng)一個內(nèi)容被大多數(shù)用戶喜歡,那大概率其他用戶也會喜歡。但是基于粗放的推薦往往會不夠精確,想要挖掘用戶個性化的,小眾化的興趣,需要制定復(fù)雜的規(guī)則運(yùn)算邏輯,并由機(jī)器完成。
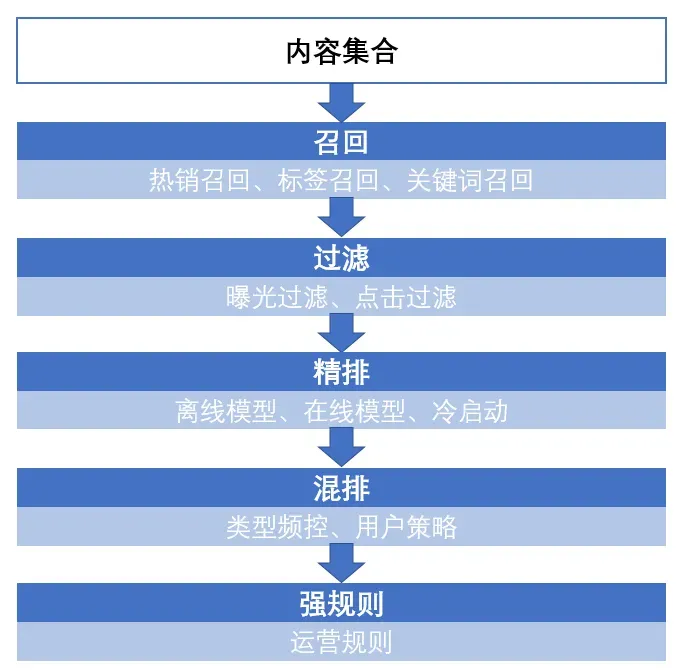
推薦算法主要分為以下幾步:
- 召回:當(dāng)用戶以及內(nèi)容量比較大的時候,往往先通過召回策略,將百萬量級的內(nèi)容先縮小到百量級。
- 過濾:對于內(nèi)容不可重復(fù)消費(fèi)的領(lǐng)域,例如實時性比較強(qiáng)的新聞等,在用戶已經(jīng)曝光和點擊后不會再推送到用戶面前。
- 精排:對于召回并過濾后的內(nèi)容進(jìn)行排序,將百量級的內(nèi)容并按照順序推送。
- 混排:為避免內(nèi)容越推越窄,將精排后的推薦結(jié)果進(jìn)行一定修改,例如控制某一類型的頻次。
- 強(qiáng)規(guī)則:根據(jù)業(yè)務(wù)規(guī)則進(jìn)行修改,例如在活動時將某些文章置頂。
2. 召回策略
(1) 召回的目的:當(dāng)用戶與內(nèi)容的量級比較大,例如對百萬量級的用戶與內(nèi)容計算概率,就會產(chǎn)生百萬*百萬量級的計算量。但同時,大量內(nèi)容中真正的精品只是少數(shù),對所有內(nèi)容進(jìn)行一次計算將非常的低效,會浪費(fèi)大量的資源和時間。因此采用召回策略,例如熱銷召回,召回一段時間內(nèi)最熱門的 100 個內(nèi)容,只需進(jìn)行一次計算動作,就可以對所有用戶應(yīng)用。
(2) 召回的重要性:召回模型是一個推薦系統(tǒng)的天花板,決定了后續(xù)可排序的空間。
(3) 召回方法:召回對算法的精度、范圍、性能都有較高要求。當(dāng)前業(yè)界常采用離線訓(xùn)練+打分或離線訓(xùn)練達(dá)到向量表達(dá)+向量檢索的方式。(對比精排為了提高準(zhǔn)確率,更多用離線+實時打分,或在線學(xué)習(xí)的方式)。
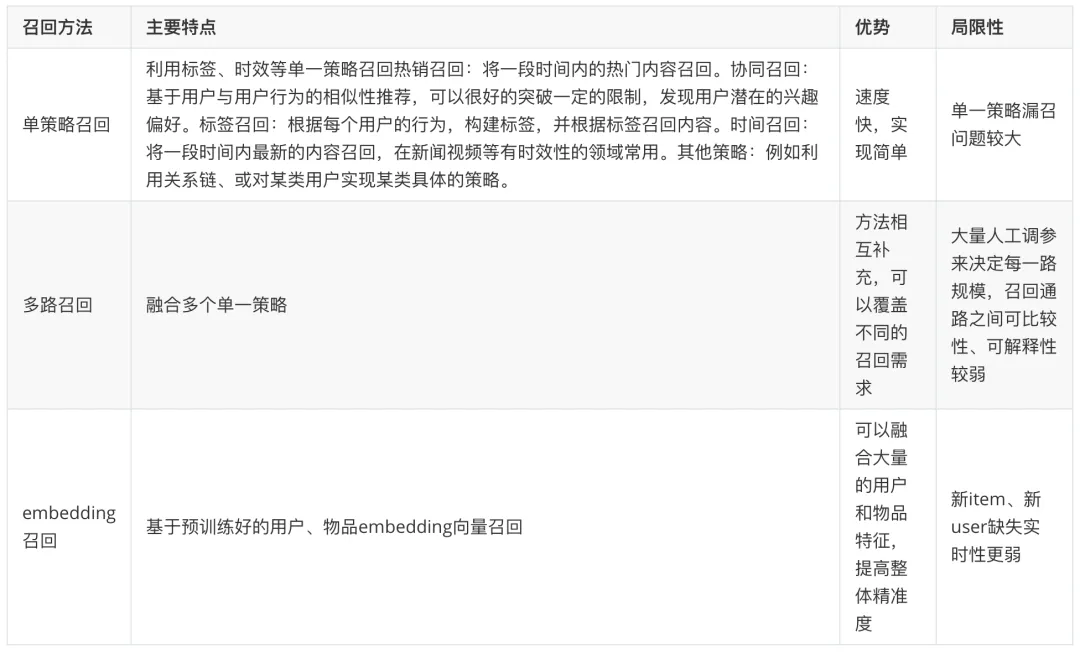
(4) 召回層與業(yè)務(wù)場景的結(jié)合
除了常規(guī)召回方式外,召回可以更多的與實際業(yè)務(wù)目標(biāo)與場景結(jié)合,例如在飛豬業(yè)務(wù)場景中,其存在幾類行業(yè)特點:
- 訂單類型較多(涉及到交通、酒店、景區(qū)、周邊游),且業(yè)務(wù)之間具有一定的相關(guān)性和搭配性。
- 用戶存在周期性復(fù)購情況。
- 用戶訂單的稀疏性較大。
針對這些問題,其召回層會結(jié)合以下解決方案:
① 相關(guān)性&搭配性問題
- 協(xié)同往往只能召回相似的商品,而考慮到推薦目標(biāo)的替代性和互補(bǔ)性,更多挖掘反應(yīng)搭配關(guān)系的行為集合。
- 數(shù)據(jù)稀疏且噪音較大,僅僅基于數(shù)據(jù)構(gòu)建圖,bad case較多,所以需要利用行業(yè)的知識圖譜。
- 結(jié)合行為序列:行為序列挖掘->構(gòu)件圖(通過知識圖譜來增加約束)->序列采樣(降低噪音,抑制熱門問題)->訓(xùn)練。
② 周期性復(fù)購問題
部分用戶存在固定的購買模式。利用Poission-Gamma分布的統(tǒng)計建模。計算在某個時間點,購買某個商品的概率,在正確的時間點給用戶推出合適的復(fù)購商品。
內(nèi)容來源:《阿里飛豬個性化推薦:召回篇》
3. 粗排策略
(1) 粗排層目的:為后續(xù)鏈路提供集合。
(2) 粗排層特點:打分量高于精排,但有嚴(yán)格的延遲約束。
(3) 粗排層方法:主要分為兩種路線
- 集合選擇:以集合為建模目標(biāo),選出滿足后鏈路需求集合。其可控性較弱,算力消耗較小。(多通道、listwise、序列生成)
- 精準(zhǔn)預(yù)估:以值為建模目標(biāo),直接對系統(tǒng)目標(biāo)進(jìn)行值預(yù)估。可控性較高,算力消耗較大。(pointwise)
- 粗排層發(fā)展歷史:質(zhì)量分->LR等傳統(tǒng)機(jī)器學(xué)習(xí)->向量內(nèi)內(nèi)卷積(雙塔模型)->COLD全鏈路(阿里)
4. 精排策略
(1) 精排層多目標(biāo)融合原則
- 用戶的效用需要通過多個指標(biāo)反饋:例如用戶對視頻的喜好,會通過停留時長、完播、點贊等多個動作反應(yīng)。
- 產(chǎn)品的目標(biāo)需要通過多個指標(biāo)衡量:例如短視頻產(chǎn)品不僅需要考慮用戶效用,也需要考慮作者效用、平臺目標(biāo)與生態(tài)影響。
(2) 精排層多目標(biāo)融合實例
以短視頻行業(yè)為例,推薦目標(biāo)主要由幾個方面組成:
- 對用戶價值。
- 對作者價值,包括給作者的流量、互動、收入等。
- 對內(nèi)容生態(tài)價值,包括品牌價值、內(nèi)容安全、平臺收入。
- 間接價值,非直接由視頻產(chǎn)生,例如用戶的評論提醒,會改善用戶的留存率。
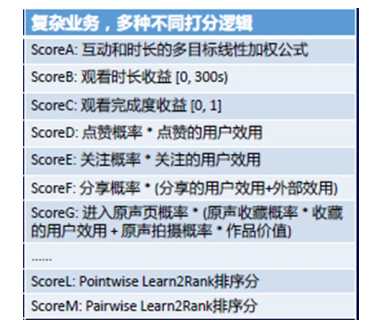
參考:《多目標(biāo)排序在快手短視頻推薦中的實踐》
(3) 精排層多目標(biāo)融合方法
① 改變樣本權(quán)重/多模型分?jǐn)?shù)融合:
- 改變樣本權(quán)重:先通過權(quán)重構(gòu)造目標(biāo)值,再進(jìn)行模型擬合。
- 多模型分?jǐn)?shù)融合:先進(jìn)行模型擬合在進(jìn)行加權(quán)融合。缺點:依賴規(guī)則設(shè)計,依賴人工調(diào)參,且經(jīng)常面臨以A目標(biāo)換取B目標(biāo)的問題。
② Learn to rank :pairwise、listwise直接排序。
③ 結(jié)合在線數(shù)據(jù)自動調(diào)參:5%線上流量探索,每次探索N組參數(shù),根據(jù)用戶的實時reward來優(yōu)化線上的調(diào)參算法。設(shè)計約束項,在閾值內(nèi)線性弱衰減,超出閾值指數(shù)強(qiáng)衰減。
④ 多任務(wù)學(xué)習(xí):結(jié)合深度學(xué)習(xí)網(wǎng)絡(luò),可以共享embedding特征,采用多種特征組合方式,達(dá)到相互促進(jìn)以及泛化的作用。例如MMOE模型,不同的專家可以從相同的輸入中提取出不同的特征,由gate attention結(jié)構(gòu),把專家提取出的特征篩選出各個task最相關(guān)的特征,分別接入不同任務(wù)的全連接層。不同的任務(wù)需要不同的信息,因此每個任務(wù)都由獨(dú)立gate負(fù)責(zé)。
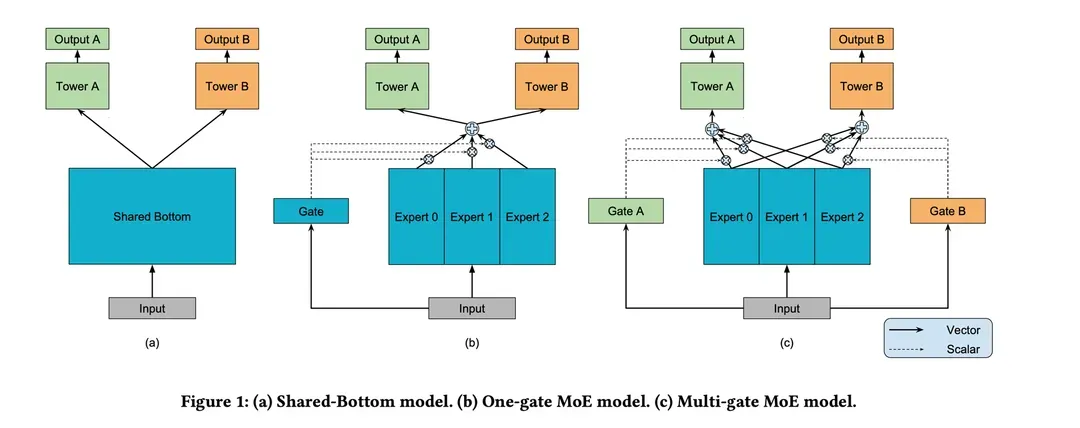
(4) 精排模型
① 精排模型發(fā)展歷史
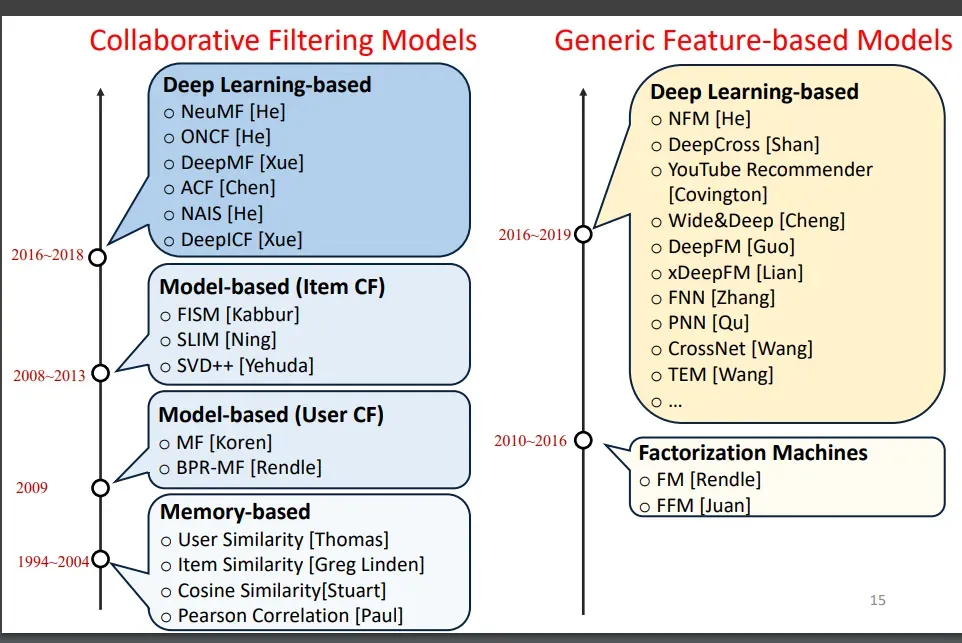
② 精排模型分類
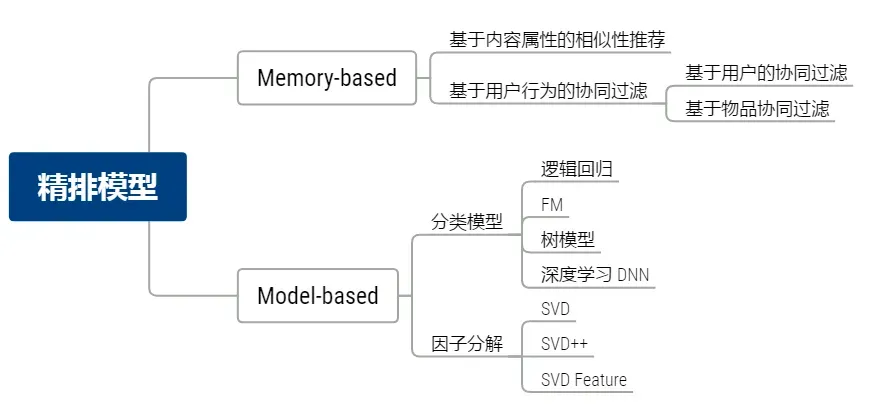
③ 精排模型基本原理

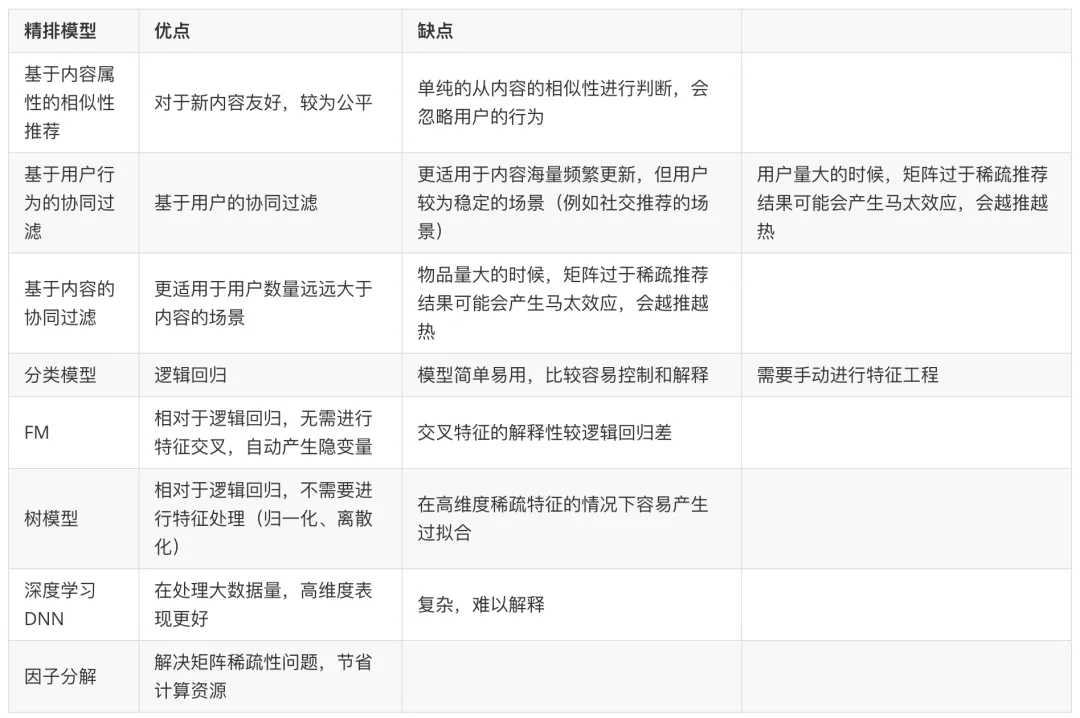
④ 精排模型優(yōu)缺點
(5) 邏輯回歸——最簡單Model-based模型
① 原理介紹
概念:邏輯回歸通過 sigmoid 函數(shù),將線性回歸變?yōu)榭梢越鉀Q二分類的方法,它可用于估計某種事物發(fā)生的可能性。
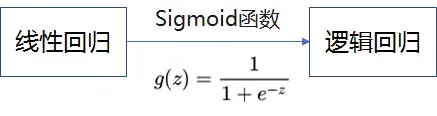
計算公式:Y 根據(jù)目標(biāo)設(shè)計:例如是否點擊(是:1,否:0,最后預(yù)測一個 0-1 之間的點擊概率);X 根據(jù)特征工程設(shè)計:這一塊就涉及到了前面提到的用戶畫像與內(nèi)容畫像,所有的畫像都是對樣本的特征的刻畫。特征工程需要根據(jù)業(yè)務(wù)場景選擇合適的特征并進(jìn)行一定的加工;W 由模型訓(xùn)練得到。

② 構(gòu)建流程
基于我們的目標(biāo),需要進(jìn)行樣本的收集(樣本是對客觀世界的具體描述),通過對已收集到的樣本進(jìn)行特征構(gòu)造,并對其進(jìn)行訓(xùn)練,最終求出模型參數(shù)的具體數(shù)值。

a.建立樣本
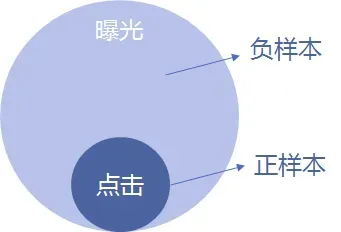
邏輯回歸為有監(jiān)督模型,因此需要有已經(jīng)分類好的樣本。正樣本:用戶曝光過某物品并點擊。負(fù)樣本:用戶曝光過某物品并且沒有點擊。如果正負(fù)樣本差距過大,可以將負(fù)樣本隨機(jī)抽樣后與正樣本一起訓(xùn)練。或只保留有點擊行為的用戶作為樣本,將曝光但是沒有被點擊的物品作為負(fù)樣本。
b.特征工程
特征工程是對收集到的樣本進(jìn)行更加深度的特征刻畫。雖然作為算法人員與用戶接觸較少,但對身邊使用該產(chǎn)品的同學(xué),進(jìn)行深入的觀察與訪談,了解他們對于所推薦內(nèi)容的反饋,往往可以得到意料之外的特征開發(fā)方向。主要分為以下幾個維度。
- 基礎(chǔ)數(shù)據(jù)
- 趨勢數(shù)據(jù)
- 時間數(shù)據(jù)
- 交叉數(shù)據(jù)
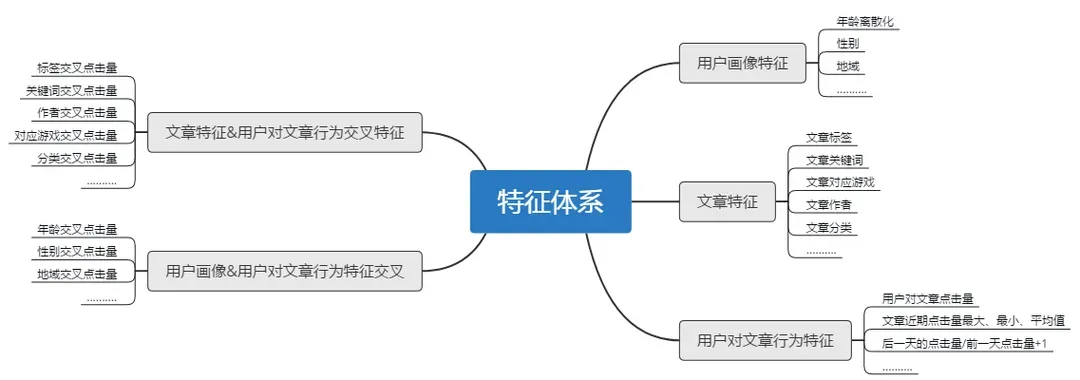
不同交叉方法得到的不同的參數(shù)數(shù)量:

(6) 深度學(xué)習(xí)——當(dāng)前最新發(fā)展方向
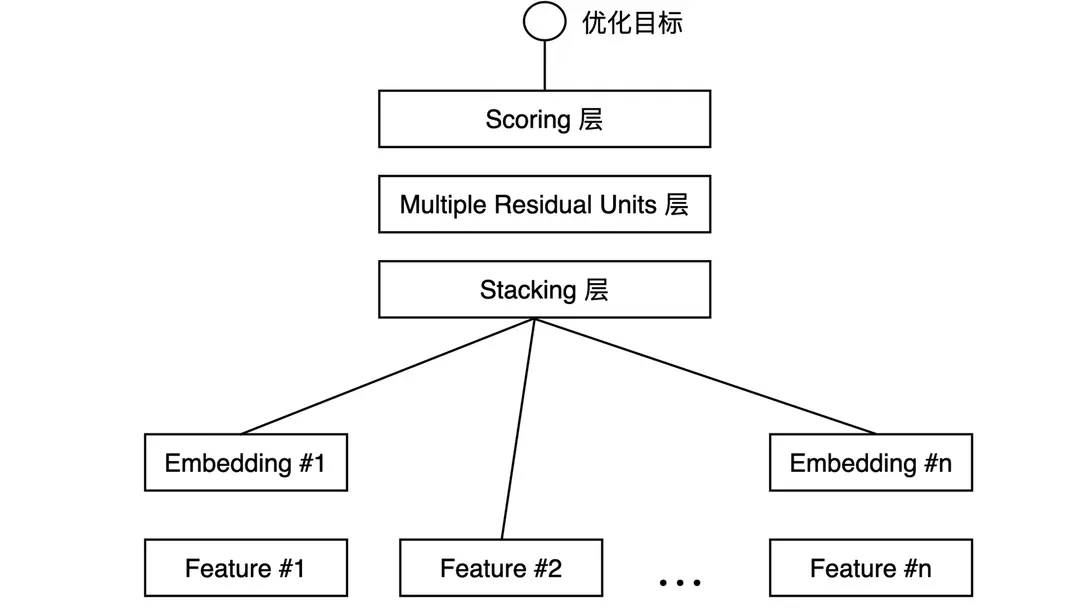
① 深度學(xué)習(xí)基礎(chǔ) Embedding+MLP 模型
Embedding+MLP 模型結(jié)構(gòu):微軟在 2016 年提出 Deep Crossing,用于廣告推薦中。
從下到上可以分為 5 層,分別是 Feature 層、Embedding 層、Stacking 層、MLP 層和 Scoring 層。
對于類別特征,先利用 Embedding 層進(jìn)行特征稠密化,再利用 Stacking 層連接其他特征,輸入 MLP (多層神經(jīng)元網(wǎng)絡(luò)),最后用 Scoring 層預(yù)估結(jié)果。
② 深度學(xué)習(xí)主要特點
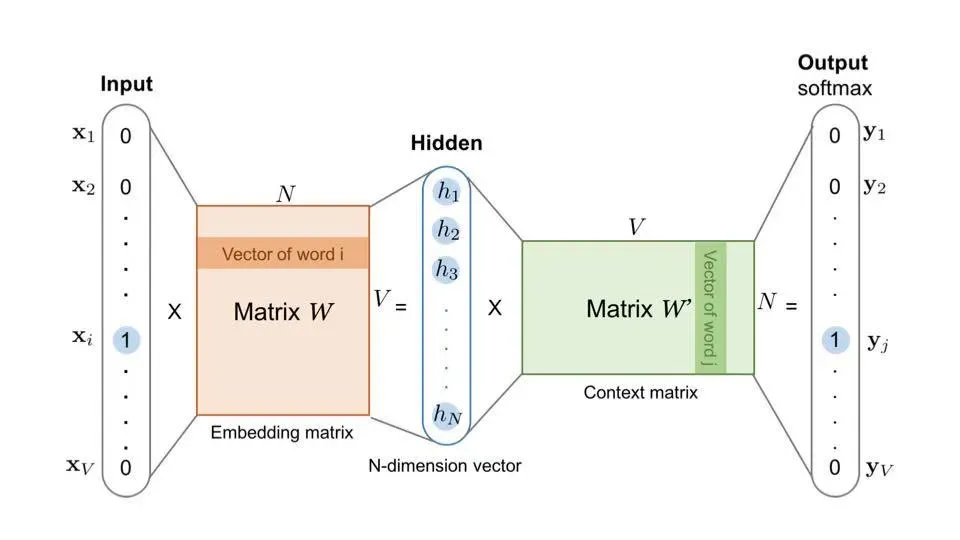
- embedding技術(shù)在召回層的應(yīng)用:embedding,即用一個數(shù)值向量來表示一個對象的方法,對于處理稀疏特征有比較重要的應(yīng)用,其將稀疏高維特征向量轉(zhuǎn)換為稠密低維特征向量,可以融合大量價值信息。其主要方法有基于文本的Word2Vec, 基于物品的Item2Vec, 基于圖結(jié)構(gòu)(社交關(guān)系、知識圖譜、行為關(guān)系等)的 deep walk、Node2Vec(增加了隨機(jī)過程中跳轉(zhuǎn)概率的傾向性)等。
- 深度學(xué)習(xí)模型在排序?qū)拥膽?yīng)用:深度學(xué)習(xí)模型以MLP為基礎(chǔ)結(jié)構(gòu),embedding+MLP是最經(jīng)典結(jié)合,google在此基礎(chǔ)上提出的Wide&Deep在業(yè)界得到了廣泛的應(yīng)用。
③ 目前主要的衍化方向
- 改變神經(jīng)網(wǎng)絡(luò)的復(fù)雜程度。
- 改變特征交叉方式。
- 多種模型組合應(yīng)用。
- 與其他領(lǐng)域的結(jié)合,例如自然語言處理,圖像處理,強(qiáng)化領(lǐng)域等。
來源:王哲-深度學(xué)習(xí)推薦系統(tǒng)實戰(zhàn)
④ 深度學(xué)習(xí)模型舉例
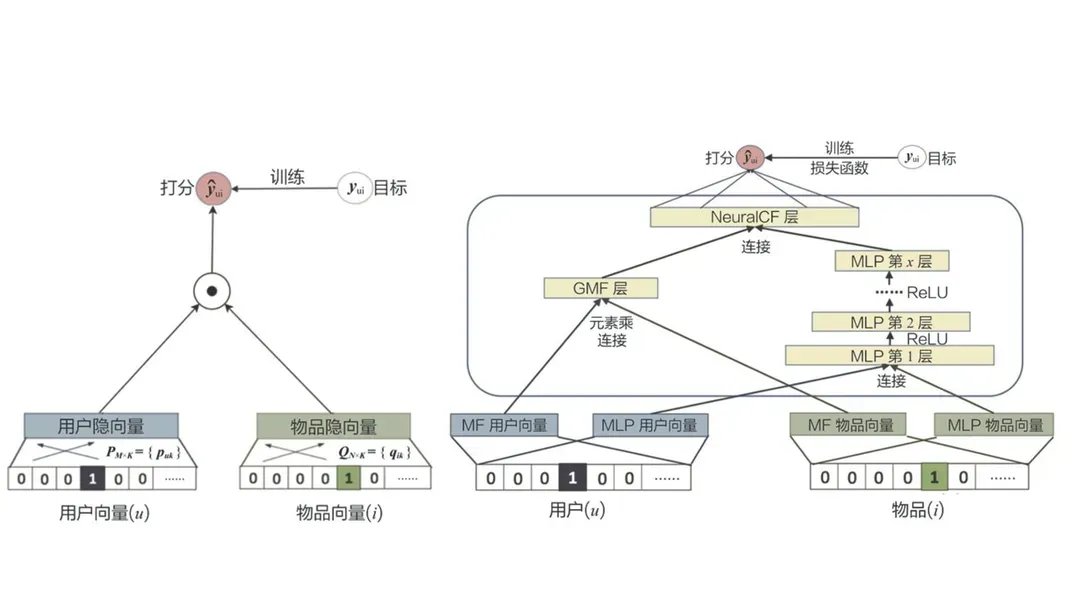
- Wide&Deep模型
2016年谷歌發(fā)表的Wide&Deep模型與YouTube深度學(xué)習(xí)推薦模型,引領(lǐng)推薦算法走向了對深度學(xué)習(xí)的應(yīng)用。
相比傳統(tǒng)機(jī)器學(xué)習(xí)推薦模型,深度學(xué)習(xí)具有更加復(fù)雜的模型結(jié)構(gòu),而使其具備了理論上擬合任何函數(shù)的能力。同時深度學(xué)習(xí)的結(jié)構(gòu)靈活性可以讓其模擬出用戶興趣的變遷過程。左側(cè)傳統(tǒng)推薦模型與右側(cè)深度學(xué)習(xí)推薦模型對比,其模型復(fù)雜度增加:
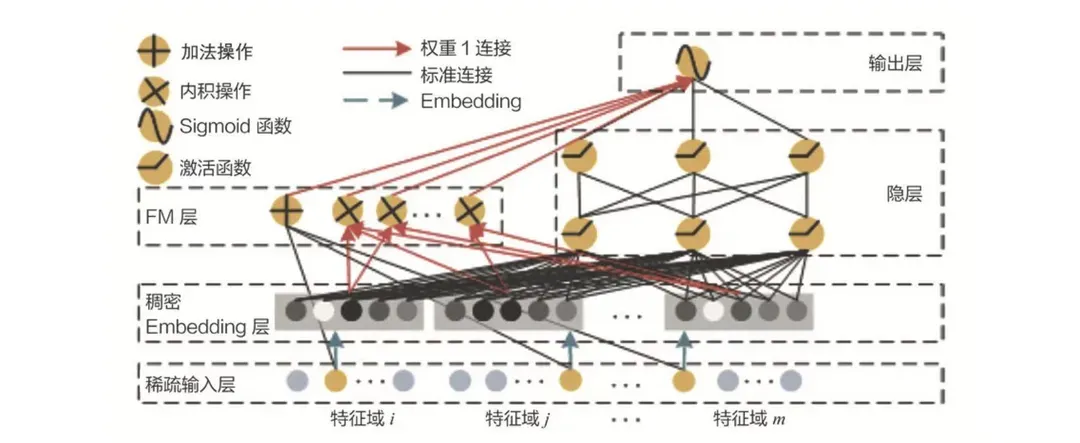
- DeepFM模型
由FM與深度學(xué)習(xí)模型的結(jié)合生成的DeepFM模型:即FM替換了Wide&Deep的Wide部分,加強(qiáng)了淺層網(wǎng)絡(luò)部分特征組合的能力,右邊的部分跟Deep部分一樣,利用多層神經(jīng)網(wǎng)絡(luò)進(jìn)行特征的深層處理。
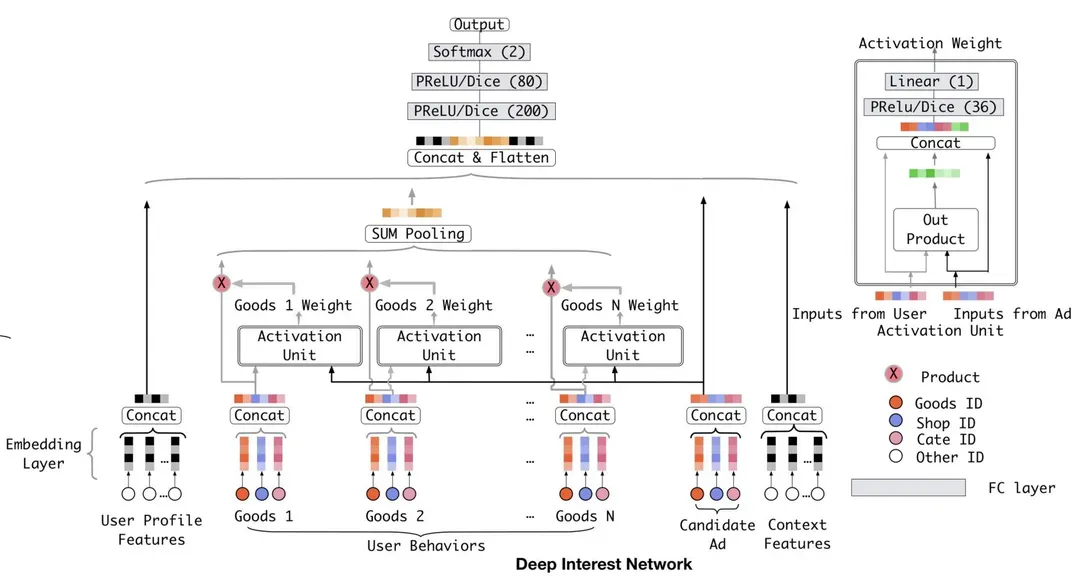
- 深度興趣DIN模型
DIN模型為阿里的電商廣告推薦模型,預(yù)測其廣告點擊率。它主要利用注意力機(jī)制,即通過用戶歷史行為序列,為每一個用戶的歷史購買商品上面加入了激活單元,激活單元相當(dāng)于一個嵌套在其中的深度學(xué)習(xí)模型,利用兩個商品的embedding,生成了代表他們關(guān)聯(lián)程度的注意力權(quán)重。
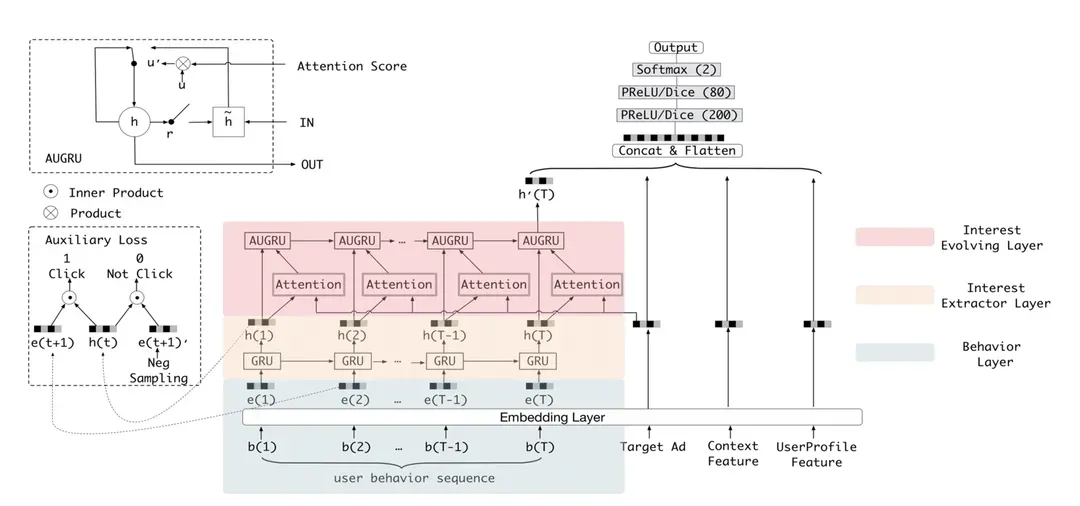
- 深度興趣進(jìn)化網(wǎng)絡(luò)DIEN
彌補(bǔ)DIN沒有對行為序列進(jìn)行建模的缺點,通過序列層,興趣抽取層,興趣進(jìn)化層。其中利用序列模型利用商品ID和前一層序列模型的embedding向量,輸出商品embedding與興趣embedding。
5. 重排層策略
(1) EE問題
MBA問題:所有的選擇都要同時考慮尋找最優(yōu)解以及累計收益最大的問題。
解決方案:Bandit算法,衡量臂的平均收益,收益越大越容易被選擇,以及臂的方差,方差越大越容易被選擇。

常用算法:湯普森采樣算法,UCB算法,Epsilon貪婪算法,LinUCB算法,與協(xié)同過濾結(jié)合的COFIBA。
(2) 多樣性問題
多樣性問題:
- 多樣性過差:用戶探索不夠,興趣過窄,系統(tǒng)泛化能力以及可持續(xù)性變差;流量過于集中在少數(shù)item上,系統(tǒng)缺乏活力。
- 多樣性過強(qiáng):用戶興趣聚焦程度弱;item流量分配平均,對優(yōu)質(zhì)item激勵不足。
多樣性解法:
- 根據(jù)內(nèi)容的相關(guān)性以及相似性進(jìn)行打散。
- 保持用戶以及內(nèi)容探索比例。
- 人工規(guī)則控制。
(3) 上下文問題
pointwise排序中,僅考慮item與user之間的相關(guān)性,而較少考慮前序item對后續(xù)item的影響,主要的解決方案有兩種。
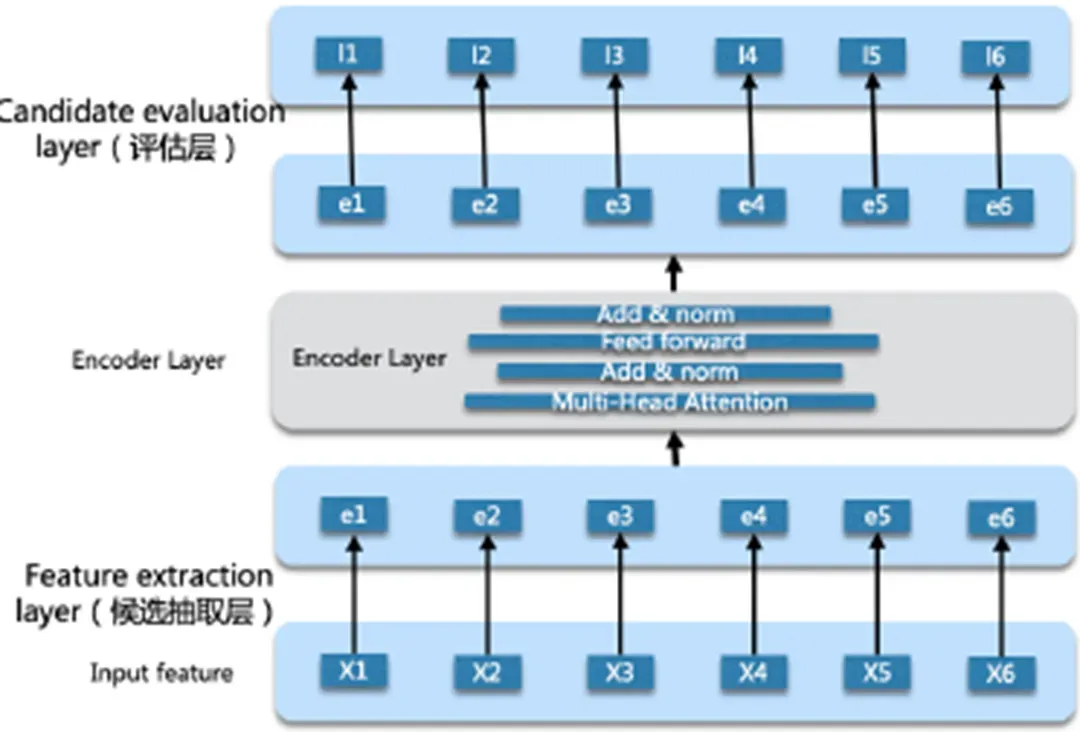
① listwise排序
Pointwise考慮單點目標(biāo)/Pairwise考慮一個pair/Listwise考慮整個集合的指標(biāo)。
Listwise 對視頻組合進(jìn)行transformer建模,刻畫視頻間的相互影響,前序視頻對后續(xù)視頻觀看有影響,前后組合決定總收益。
② 強(qiáng)化學(xué)習(xí)
考慮序列決策,從前向后依次貪心的選擇動作概率最大的視頻。
Reward = f(相關(guān)性,多樣性,約束)。
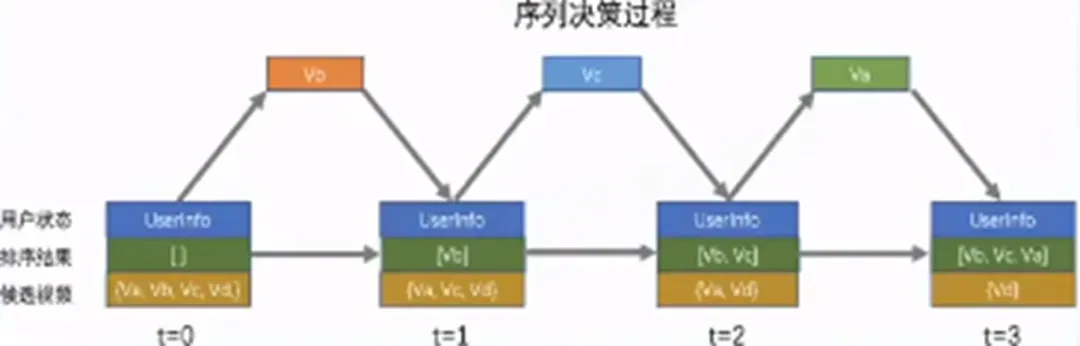
6. 冷啟動
(1) 用戶冷啟
其主要幾個方向為:加強(qiáng)特征與信息的補(bǔ)充、EE問題平衡、實時化加強(qiáng)。
信息補(bǔ)充:
- side information 補(bǔ)充:例如商品類目、領(lǐng)域知識圖譜、第三方公司數(shù)據(jù)的補(bǔ)充。
- Cross domain:利用共同的用戶在不同地方的數(shù)據(jù)進(jìn)行冷啟。
- 用戶填寫興趣。
- 元學(xué)習(xí):利用多任務(wù)間具有泛化能力的模型,進(jìn)行少樣本學(xué)習(xí)(few-shot learning)。
EE探索
快速收斂:
- 主動學(xué)習(xí)、在線學(xué)習(xí)、強(qiáng)化學(xué)習(xí):快速收集數(shù)據(jù),且反饋到特征與模型中。
- 增強(qiáng)模型實時化以及收斂能力。
(2) 內(nèi)容冷啟
以短視頻推薦為例,平臺常常采用大小池邏輯,對內(nèi)容進(jìn)行不同流量的探索,并根據(jù)實際的反饋數(shù)據(jù)來決定內(nèi)容可以進(jìn)入的推薦范圍。其中表現(xiàn)優(yōu)質(zhì)的內(nèi)容將不斷的進(jìn)入更大的流量池中,最終進(jìn)入推薦池,形成精品召回池。
六、當(dāng)前發(fā)展
(1) 因果與推薦結(jié)合
推薦系統(tǒng)中的特征向量和用戶最終的反饋(比如點擊、點贊等)之間的關(guān)系是由因果關(guān)系和非因果關(guān)系共同組成。因果關(guān)系是反應(yīng)物品被用戶偏好的原因,非因果關(guān)系僅反應(yīng)用戶和物品之間的統(tǒng)計相關(guān)性,比如曝光模式、公眾觀念、展示位置等。而現(xiàn)有推薦算法缺乏對這兩種關(guān)系的區(qū)分。
A Model-Agnostic Causal Learning Framework for Recommendation using Search Data。論文提出了一個基于工具變量的模型無關(guān)的因果學(xué)習(xí)框架 IV4Rec,聯(lián)合考慮了搜索場景和推薦場景下的用戶行為,利用搜索數(shù)據(jù)輔助推薦模型。即將用戶的搜索行為作為工具變量,來幫助分解原本推薦中 特征( treatments),使用深度神經(jīng)網(wǎng)絡(luò)將分離的兩個部分結(jié)合起來,來完成推薦任務(wù)。
(2) 序列/會話推薦
推薦系統(tǒng)傾向于學(xué)習(xí)每個用戶對物品的長期和靜態(tài)的偏好,但一個用戶的所有的歷史交互行為對他當(dāng)前的偏好并非同等重要,用戶的短期偏好和跟時間相關(guān)的上下文場景所包含的信息更加實時也更加靈敏。基于會話的推薦系統(tǒng)從一個用戶的最近產(chǎn)生的會話中捕獲他的短期偏好,以及利用會話和會話間的偏好變化,進(jìn)行更精準(zhǔn)和實時推薦。
TKDE 2022 | Disentangled Graph Neural Networks for Session-based Recommendation。用戶選擇某個物品的意圖是由該物品的某些因素驅(qū)動的,本文的方法建模了這種細(xì)粒度的的興趣來生成高質(zhì)量的會話嵌入。
(3) 圖神經(jīng)網(wǎng)絡(luò)與推薦結(jié)合
大部分的信息本質(zhì)上都是圖結(jié)構(gòu),GNN能夠自然地整合節(jié)點屬性信息和拓?fù)浣Y(jié)構(gòu)信息,來減少特征處理中的信息折損。
ICDE 2021 | Multi-Behavior Enhanced Recommendation with Cross-Interaction Collaborative Relation Modeling。利用圖神經(jīng)網(wǎng)絡(luò)建模Multi-Behavior 推薦。
(4) 知識圖譜與推薦結(jié)合
先驗的知識圖譜可以對推薦系統(tǒng)進(jìn)行很好的信息補(bǔ)充和信息約束,特別是在數(shù)據(jù)較為稀疏的場景下。(1)知識圖譜中的結(jié)構(gòu)化知識可以在冷啟動場景中提供更多的信息。(2)對于數(shù)據(jù)稀疏,方差過大的情況下,增加有效約束。(3)先驗知識糾正數(shù)據(jù)偏差。(4)增強(qiáng)推薦算法可解釋性。
Conditional Graph Attention Networks for Distilling and Refining Knowledge Graphs in Recommendation 由于知識圖譜的泛化性和規(guī)模性,大多數(shù)知識關(guān)系對目標(biāo)用戶-物品預(yù)測沒有幫助。為了利用知識圖譜來捕獲推薦系統(tǒng)中特定目標(biāo)的知識關(guān)系,需要對知識圖譜進(jìn)行提取以保留有用信息,并對知識進(jìn)行提煉以捕獲更準(zhǔn)確的用戶偏好。這篇文章提出了Knowledge-aware Conditional Attention Networks(KGAN)網(wǎng)絡(luò),對于給定target(即用戶-物品對),基于知識感知的注意力自動從全局的知識圖譜中提取出特定于target的子圖。通過在子圖上應(yīng)用條件注意力機(jī)制進(jìn)行鄰居聚合,以此實現(xiàn)對知識圖譜的細(xì)化,進(jìn)而獲得特定target的節(jié)點表示。
(5) 強(qiáng)化學(xué)習(xí)
與傳統(tǒng)推薦算法不同,其主要描述和解決智能體在與環(huán)境的交互過程中通過學(xué)習(xí)策略以達(dá)成回報最大化或?qū)崿F(xiàn)特定目標(biāo)的問題。
CIKM 2021 | Supervised Advantage Actor-Critic for Recommender Systems。現(xiàn)有的RL+(self-)supervised sequential learning方式由于缺乏負(fù)獎勵信號,q值的估計往往偏向于正值。此外,q值還嚴(yán)重依賴于序列的特定時間戳。本文提出負(fù)采樣策略來訓(xùn)練RL分量,并將其與有監(jiān)督序列學(xué)習(xí)相結(jié)合。
(6) 多模態(tài)內(nèi)容推薦
短視頻推薦業(yè)務(wù)中,涉及的上下文信息包含圖像,語音,文本,社交網(wǎng)絡(luò),知識圖譜,將不同的上下文特征進(jìn)行融合。
Arxiv 2021 | MultiHead MultiModal Deep Interest Recommendation Network。在DIN模型的基礎(chǔ)上,增加了多頭多模態(tài)模塊(MultiHead MultiModal),豐富了模型可以使用的特征集,同時增強(qiáng)了模型的交叉組合和擬合能力。
(7) 對話系統(tǒng):主要分為兩種方向(1)通過NLP的方式來構(gòu)建對話機(jī)器人。(2)交互式的意圖挖掘,利用用戶少量交互行為,快速得到用戶偏好以完成推薦任務(wù)。
部分內(nèi)容來源:推薦與廣告最新論文追蹤 https://www.zhihu.com/column/c_1410364359926906880
七. 算法衡量標(biāo)準(zhǔn)
1. 指標(biāo)選擇
- 硬指標(biāo):對于大多數(shù)的平臺而言,推薦系統(tǒng)最重要的作用是提升一些“硬指標(biāo)”。例如新聞推薦中的點擊率,但是如果單純以點擊率提升為目標(biāo),最后容易成為一些低俗內(nèi)容,“標(biāo)題黨”的天下。
- 軟指標(biāo):除了“硬指標(biāo)”,推薦系統(tǒng)還需要很多“軟指標(biāo)”以及“反向指標(biāo)”來衡量除了點擊等之外的價值。好的推薦系統(tǒng)能夠擴(kuò)展用戶的視野,發(fā)現(xiàn)那些他們感興趣,但是不會主動獲取的內(nèi)容。同時推薦系統(tǒng)還可以幫助平臺挖掘被埋沒的優(yōu)質(zhì)長尾內(nèi)容,介紹給感興趣的用戶。

2. 推薦效果
如何去獲得推薦效果。可以分為離線實驗、用戶調(diào)查、在線實驗三種方法。

- 離線效果:通過反復(fù)在數(shù)據(jù)樣本進(jìn)行實驗來獲得算法的效果。通常這種方法比較簡單、明確。但是由于數(shù)據(jù)是離線的,基于過去的歷史數(shù)據(jù),不能夠真實的反應(yīng)線上效果。同時需要通過時間窗口的滾動來保證模型的客觀性和普適性。
- 白板測試:當(dāng)在離線實驗階段得到了一個比較不錯的預(yù)測結(jié)果之后,就需要將推薦的結(jié)果拿到更加真實的環(huán)境中進(jìn)行測評,如果這個時候?qū)⑺惴ㄖ苯由暇€,會面臨較高的風(fēng)險。因為推薦結(jié)果的好壞不能僅僅從離線的數(shù)字指標(biāo)衡量,更要關(guān)注用戶體驗,所以可以通過小范圍的反復(fù)白板測試,獲得自己和周圍的人對于推薦結(jié)果的直觀反饋,進(jìn)行優(yōu)化。
- 在線測試(AB test):實踐是檢驗真理的唯一標(biāo)準(zhǔn),在推薦系統(tǒng)的優(yōu)化過程中,在線測試是最貼近現(xiàn)實、最重要的反饋方式。通過AB測試的方式,可以衡量算法與其他方法、算法與算法之間的效果差異。

八. 除了算法本身之外...
1. 推薦算法是否會導(dǎo)致信息不平等和信息繭房?
推薦系統(tǒng)并非導(dǎo)致信息不平等和信息繭房的根本原因。
- 內(nèi)容的不平等或許更多的產(chǎn)生于用戶天性本身,而推薦算法的作用更像是幫助用戶“訂閱”了不同的內(nèi)容。用戶天然的會對信息產(chǎn)生篩選,并集中在自己的興趣領(lǐng)域。在過去雜志訂閱的階段,雖然每個雜志和報紙的內(nèi)容都是完全相同的,但是用戶通過訂閱不同的雜志實際接受到了完全不同的消息。而今天的內(nèi)容APP提供了各種話題,各種類型的內(nèi)容,但用戶通過推薦算法,在無意識的情況下“訂閱”了不同的“雜志”。
- 人們更加集中于垂直的喜好是不可逆轉(zhuǎn)的趨勢。從內(nèi)容供給的角度來講,從內(nèi)容的匱乏到繁榮,從中心化到垂直聚群,用戶的選擇更貼近自己的喜好是不可逆轉(zhuǎn)的趨勢。在沒有提供太多選項的時候,人們會更多的集中在某幾個內(nèi)容上面,而當(dāng)今天層出不窮的內(nèi)容出現(xiàn),人們開始追逐更加個性化,精細(xì)化的內(nèi)容。
但不可否認(rèn)的是,推薦系統(tǒng)的便捷性、自動化、實時性會加重這些問題。在這樣的情況下,我們能做些什么?
- 產(chǎn)品價值與數(shù)據(jù)指標(biāo)的平衡:推薦算法是對短期數(shù)據(jù)指標(biāo)的高度擬合,一定階段后會發(fā)現(xiàn)對推薦系統(tǒng)的人工干擾往往會造成負(fù)向的指標(biāo)波動。但推薦算法往往只能帶來短期的局部最優(yōu)解。產(chǎn)品仍需要從本質(zhì)出發(fā),來看待產(chǎn)品給用戶帶來的本質(zhì)價值。對產(chǎn)品方向的判斷、以及對產(chǎn)品價值的堅持才是產(chǎn)品尋找全局最優(yōu)解的方式。
2. 算法可能產(chǎn)生的蝴蝶效應(yīng)
在很多場景中,并非只有機(jī)器算法一種推薦方式。以視頻號為例,除公域機(jī)器推薦外,也存在私域(朋友圈、群聊、單聊)、半公域(朋友tab社交推薦)等推薦方式,但推薦對整個產(chǎn)品體驗、內(nèi)容生態(tài)、作者生態(tài)的影響都是巨大的。
(1) 推薦算法對feed傳播的影響
從feed傳播來看,推薦算法給予其冷啟流量,提升傳播速率,利于其對抗時間衰減,快速達(dá)到社交裂變拐點,進(jìn)而大規(guī)模傳播
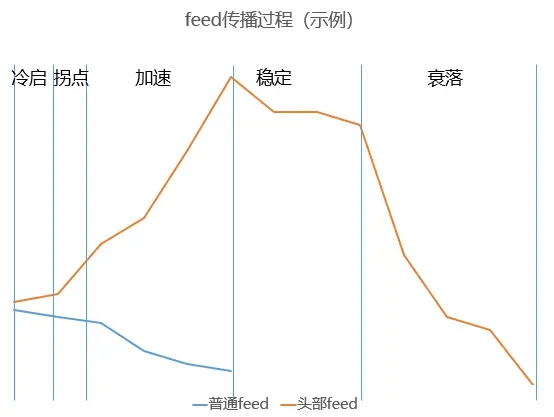
(圖中曲線均為模擬,非真實曲線,僅供示例)
一個feed在傳播過程中,主要影響因素有:
- feed特性:優(yōu)質(zhì)度、傳播性、普適性,這三點決定其傳播速度、傳播穩(wěn)定性以及天花板。
- feed發(fā)表時間:feed與時間的“對抗性”。因為(1)feed無法重復(fù)消費(fèi)且一段時間內(nèi)目標(biāo)受眾有限(2)由于環(huán)境背景、文化潮流、熱點等feed具有一定時效性(3)不確定性,時間越長影響其傳播的因素越多,受眾的注意力發(fā)生轉(zhuǎn)移的可能越大。
熱門對頭部內(nèi)容的最重要影響集中在冷啟期、拐點期與加速時期。在前幾個小時的冷啟動時期,社交推薦無法達(dá)到其裂變點,對其傳播的效果影響非常有限。feed要對抗漫長的時間影響來達(dá)到裂變點,對feed本身質(zhì)量要求非常高。而通過熱門的傳播可以直接給到較大的冷啟量,以及更快的傳播速度、在feed受時間影響衰退前迎來社交裂變拐點,社交傳播開始作為主場景進(jìn)行下一輪傳播。(社交推薦具有積累慢,但達(dá)到拐點可進(jìn)行網(wǎng)絡(luò)裂變傳播,速度快、衰減慢。因此頭部feed在視頻號同時享受算法推薦早期爆發(fā)性強(qiáng),熱度積累快,又享受社交推薦,傳播范圍大、熱度衰減慢的雙重優(yōu)勢。)

(2) 推薦算法對平臺的影響
① 推薦算法作為最初的內(nèi)容篩選器,對視頻號的內(nèi)容分布以及產(chǎn)品體驗有較大影響
推薦算法對feed的影響是巨大的,若無法被推薦算法識別,其獲得較高熱度的可能性較低,最終導(dǎo)致產(chǎn)品的流量主要集中在被推薦算法識別并推薦的feed上。其短期內(nèi)對內(nèi)容生態(tài)、瀏覽者體驗有較為重要的決定作用;長期來看,對內(nèi)容氛圍、作者反饋、瀏覽者長期留存都有較大的影響。

② 推薦算法的影響需要進(jìn)行全局評估,而非局部評估
每個場景具有不同的特點,可能存在某類內(nèi)容(或比例)更適合推薦場景而不適合社交場景,在達(dá)到推薦場景最優(yōu)后傳導(dǎo)進(jìn)入其他場景,導(dǎo)致其他場景該類內(nèi)容過少或過多。例如某類內(nèi)容在一定比例下,推薦場景有收益,而社交場景收益為負(fù)。在此類情況下,當(dāng)該類內(nèi)容在熱門達(dá)到最優(yōu)比例后傳到進(jìn)入社交場景,在社交場景會而產(chǎn)生負(fù)向影響,僅評估推薦場景將無法衡量其對產(chǎn)品的整體效果。
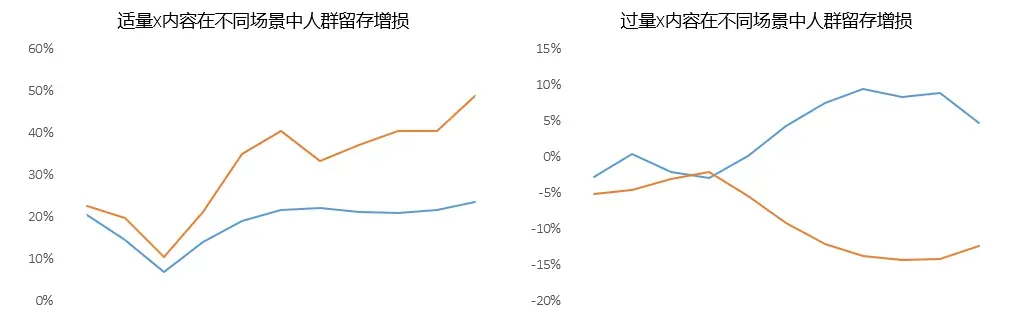
黃色曲線為推薦場景、藍(lán)色為社交傳播場景























