盤點數(shù)據(jù)庫主從延遲的九個原因以及解決方案
前言
大家好,我是撿田螺的小男孩。
我們來看一道字節(jié)面試題:mysql主從延遲的原因有哪些?你遇到的最大延遲是多大?如何解決?
我以前見過的最大延遲是3個多小時。本文我們一起來聊聊主從延遲吧。
- 主從延遲的定義
- 主從延遲原因的9個原因以及解決方案
1. 主從延遲是怎么定義的呢?
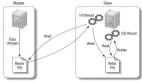
與主從數(shù)據(jù)同步相關的時間點有三個
- 主庫執(zhí)行完一個事務,寫入binlog,我們把這個時刻記為T1;
- 主庫同步數(shù)據(jù)給從庫,從庫接收完這個binlog的時刻,記錄為T2;
- 從庫執(zhí)行完這個事務,這個時刻記錄為T3。
所謂主從延遲,其實就是指同一個事務,在從庫執(zhí)行完的時間和在主庫執(zhí)行完的時間差值,即T3-T1。
主從復制原理不記得的伙伴,可以看這個圖哈:
 圖片
圖片
2. 主從延遲原因以及解決方法
2.1 網(wǎng)絡延遲,優(yōu)化網(wǎng)絡
網(wǎng)絡延遲是導致主從延遲的一個重要因素。我們要確保主從服務器之間的網(wǎng)絡連接是高速且穩(wěn)定的。可以考慮使用專用網(wǎng)絡連接或提高網(wǎng)絡帶寬。
比如帶寬20M升級到100M類似意思等。
2.2 從庫的壓力大,多搞幾個從庫分散壓力
如果從庫的壓力大,也會導致主從延遲。
比如主庫直接影響業(yè)務的,大家可能使用會比較克制,因此一般查詢都打到從庫了,結果導致從庫查詢消耗大量CPU,影響同步速度,最后導致主從延遲。
這種情況的話,可以搞了一主多從的架構,即多接幾個從庫分攤讀的壓力,增加從庫的數(shù)量可以分散讀取負載,提高數(shù)據(jù)同步的速度和可靠性。 另外,還可以把binlog接入到Hadoop這類系統(tǒng),讓它們提供查詢的能力。
2.3 數(shù)據(jù)庫參數(shù)配置不合理,優(yōu)化調(diào)整
調(diào)整MySQL數(shù)據(jù)庫中的相關參數(shù),如binlog格式、binlog緩沖區(qū)大小、innodb_flush_log_at_trx_commit等,以優(yōu)化性能。
適當?shù)膮?shù)設置可以減少磁盤I/O和事務提交延遲。
2.4 使用半同步復制
半同步復制是介于全同步復制和異步復制之間的一種復制方式。主庫在提交事務時需要等待至少一個從庫接收到并寫入到relay log中才返回結果給客戶端。
 圖片
圖片
這可以提高數(shù)據(jù)的安全性,并減少主從延遲。但需要注意的是,半同步復制可能會增加寫操作的延遲
2.5 升級硬件配置
如果從庫所在的機器比主庫的機器性能差,會導致主從延遲,這種情況比較好解決,只需選擇主從庫一樣規(guī)格的機器就好。
因此,我們可以:
- 升級從服務器的硬件,特別是磁盤I/O系統(tǒng)和CPU,以便更快地應用復制事件。
- 使用SSD可以顯著提高I/O性能。
這是減少主從延遲時間,最簡單粗暴的方法~~
2.6 避免大事務
- 可以將大事務分解為多個小事務。
如果一個事務執(zhí)行就要10分鐘,那么主庫執(zhí)行完后,給到從庫執(zhí)行,最后這個事務可能就會導致從庫延遲10分鐘啦。日常開發(fā)中,我們?yōu)槭裁刺貏e強調(diào),不要一次性delete太多SQL,需要分批進行,其實也是為了避免大事務。另外,大表的DDL語句,也會導致大事務,大家日常開發(fā)關注一下哈。
2.7 使用并行復制
- 在MySQL 5.6及以上版本中,可以使用并行復制來加速從庫應用binlog中的事件。
- 通過設置slave_parallel_workers參數(shù),可以指定并行工作線程的數(shù)量。
低版本的MySQL只支持單線程復制,如果主庫并發(fā)高,來不及傳送到從庫,就會導致延遲。可以換用更高版本的Mysql,可以支持多線程復制。
2.8 業(yè)務側(cè)加緩存,優(yōu)化查詢
- 在業(yè)務側(cè)添加緩存層,如Redis、Memcached等,優(yōu)化查詢接口,以減少對數(shù)據(jù)庫的查詢壓力。
2.9 避免大表DDL操作
- 大表的DDL操作(如添加索引、修改表結構等)會導致長時間的鎖等待和復制延遲。
- 盡量避免在主從復制環(huán)境中對大表進行DDL操作,或者選擇在業(yè)務低峰期進行。