記錄一次MySQL+Redis實現優化百萬數據統計的方式
提到歷史項目,大家對它的第一印象可能會是數據量大、技術老舊、文檔缺失、開發人員斷層、"屎山"等。剛好這幾天就接到了一個優化老項目的需求,客戶反饋頁面數據加載緩慢甚至加載不出來,希望能夠做一些優化。
剛接到這個任務后真的是一臉懵逼,因為既沒有文檔,也沒有相關的開發人員,甚至連需求都不了解。唯一的解決辦法就是向上面多要時間,有了足夠的時間就可以通過代碼梳理出業務邏輯。
背景
客戶在我司采購了WAF防火墻產品,用于攔截和阻斷非法請求和一些具有攻擊行為的請求。隨著系統的不斷運作,數據量也隨之增長,這就導致客戶系統部分報表頁面加載時間過長,用戶體驗極差。
技術棧
SSM + Gateway + Redis + Kafka + MySQL
其中Gateway負責安全防護和限流,當請求經過Gateway時,Gateway會將該請求的原參數,以及安全狀態,是否存在攻擊,請求ip等信息通過Kafka發送到后臺系統并當作日志記錄到數據庫中。
優化思路
當我看到報表接口的第一眼,就被驚呆了。先不說業務邏輯,單單一個函數中的代碼行數將近1000行,在這1000行的代碼中依稀殘留著幾行簡潔而又模糊的注釋,并且函數內對象的命名也是慘不忍睹,比如format1,data1,data2,collect1, collect2......。即使冒著涉密的風險,我也要復制出來,與大家一起分享。
 圖片
圖片
if (pageResultDTO.isPresent()) {
List<SecurityIncidentDTO> data = pageResultDTO.get().getData();
Long count = Long.parseLong(pageResultDTO.get().getCount().toString());
long normalCount = data.stream().filter(log -> log.getType().equals("正常")).count();
response.setTotalCount(count);
response.setNormalCount(normalCount);
response.setAbNormalCount(count - normalCount);
Map<String, List<SecurityIncidentDTO>> collect = data.stream()
.filter(log -> log.getType().equals("正常"))
.collect(Collectors.groupingBy(
item -> new SimpleDateFormat(
"yyyy-MM-dd HH").format(
com.payegis.antispider.admin.common.utils.DateUtil
.pars2Calender(item.getTime())
.getTime())));
Map<String, List<SecurityIncidentDTO>> collect1 = data.stream()
.filter(log -> !log.getType().equals("正常"))
.collect(Collectors.groupingBy(
item -> new SimpleDateFormat(
"yyyy-MM-dd HH").format(
com.payegis.antispider.admin.common.utils.DateUtil
.pars2Calender(item.getTime())
.getTime())));
Map<String, List<SecurityIncidentDTO>> ipMap = data.stream()
.filter(log -> !log.getType().equals("正常"))
.collect(Collectors.groupingBy(
SecurityIncidentDTO::getSourceIp));
for (String s : ipMap.keySet()) {
List<SecurityIncidentDTO> tempList = ipMap.get(s);
int size = tempList.size();
ApiStatisticDataVO apiStatisticDataVO = new ApiStatisticDataVO();
apiStatisticDataVO.setValue(size);
apiStatisticDataVO.setMsg(s);
apiStatisticDataVO.setId(s);
ipList.add(apiStatisticDataVO);
}
List<ApiStatisticDataVO> collect3 = ipList.stream()
.sorted(Comparator.comparing(ApiStatisticDataVO::getValue)
.reversed())
.limit(5)
.collect(Collectors.toList());
ipList = new ArrayList<>(5);
for (int i = 0; i < 5; i++) {
ApiStatisticDataVO apiStatisticDataVO = new ApiStatisticDataVO();
apiStatisticDataVO.setId(i + "");
apiStatisticDataVO.setValue(0);
apiStatisticDataVO.setMsg("");
ipList.add(i, apiStatisticDataVO);
}
for (int i = 0; i < collect3.size(); i++) {
ipList.set(i, collect3.get(i));
}
for (String hour2 : list) {
boolean falg = false;
for (String hour : collect.keySet()) {
if (hour2.substring(0, 2).equals(hour.substring(hour.length() - 2))) {
data1.add(collect.get(hour).size());
falg = true;
}
}
if (!falg) {
data1.add(0);
}
}
for (String hour2 : list) {
boolean falg = false;
for (String hour : collect1.keySet()) {
if (hour2.substring(0, 2).equals(hour.substring(hour.length() - 2))) {
data2.add(collect1.get(hour).size());
falg = true;
}
}
if (!falg) {
data2.add(0);
}
}吐槽完了,下面開始正式步入正題。經過不知道多久的時間,該方法的邏輯也慢慢變得清晰起來,其主要實現的是:將Kafka接受并存儲在數據庫中的日志數據,進行分類統計,具體包括事件狀態統計(正常訪問量,異常訪問量,總訪問量),近12/24小時內各時間段的事件統計,攻擊IP地址TOP5,接口訪問TOP5,安全類型分布等報表。
原有邏輯是直接查詢數據庫,通過sql來實現統計,這種方式如果在數據量小的情況下并不會出現什么問題并且實現方式也相對簡單。但是,當數據量上去之后,sql的查詢效率就會隨之下降,即使通過優化索引的方式也無濟于事。
那么在不能引入其他組件或框架情況下,該如何優化查詢呢?
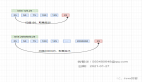
經過短暫的思考后,決定以歸檔的方式進行數據處理,即在存儲日志前,先對日志數據進行分門別類的處理,比如需要統計每個時段的事件訪問量,那么就以小時和事件狀態為標識進行存儲,假設在12:30分有一條異常的訪問,那么在消費端接收到消息后,先查詢數據庫中是否存在12點且訪問異常的數據,如果存在,那么次數加一,否則將該數據插入到數據庫中,這樣在一小時內統一時間狀態只會存在一條數據。
 圖片
圖片
上面的方式是可以減少一定的數據量并且可以提高查詢效率,但是如果請求量很大,消息在不斷的消費那么就意味著需要不斷的查詢數據庫,更新數據庫,這樣就會造成一定的性能消耗,而且還會出現并發問題,造成數據重復。
本打算先用這種方式來解決的,有并發就加鎖。但是在劃了一小時水之后突然想到,當前小時的數據是不是可以存到redis中?
經過片刻的構想,發現確實可以,畢竟變得只是一個數量,可以用redis自增去做。存到緩存后,定時在同步到數據庫中不就搞定了嗎,這樣既可以大大減少數據庫操作,還能提高查詢效率。
 圖片
圖片
/**
* 將事件詳情按事件正常狀態進行歸檔,將次數緩存到redis用于報表查詢
*
* @param log
*/
@Override
public void handleWebEventStatus(Log log) {
String siteId = antispiderDetailLog.getSiteId();
Date curr = new Date();
DateTime beginOfHour = DateUtil.beginOfHour(curr);
Integer eventStatus = log.getAntispiderRule().intValue() == 0 ? 0 : 1;
// 不同站點事件(區分站點)
String cacheKey = StrUtil.format(RedisConstant.REPORT_WEB_TIME_EXIST, siteId, DateUtil.format(beginOfHour, timeFormat), eventStatus.intValue());
// 所有站點事件(不區分站點)
String cacheKeyAll = StrUtil.format(RedisConstant.REPORT_WEN_TIME_ALL, DateUtil.format(beginOfHour, timeFormat), eventStatus.intValue());
if (redisService.exist(cacheKeyAll)) {
redisService.increment(cacheKeyAll, 1L);
} else {
redisService.setValueByHour(cacheKeyAll, 1, 2L);
}
if (redisService.exist(cacheKey)) {
redisService.increment(cacheKey, 1L);
} else {
redisService.setValueByHour(cacheKey, 1, 2L);
}
}
/**
* 將當前小時內的數據 以及上一個小時內的數據同步到數據庫
*/
@Scheduled(cron = "0 0/30 * * * ?")
public void synRedisDataToDB() {
synchronized (lock) {
reportWebEventStatusService.synRedisDataToDB();
reportWebEventTopService.synRedisDataToDB();
reportWebIpTopService.synRedisDataToDB();
}
}上面的搞完后,我突然又發現,如果要統計24小時內的數據,那前23小時的數據肯定都已經固定了,不會在發生變化了。那完全可以將前23小時的數據統計完后存入redis,查詢的時候只需要在數據庫中查詢當前所屬小時的數據即可。更新緩存的時間可以設定為1小時1更新,這樣就可以保證到一個新時段時,可以保證緩存中的數據為近23小時內的數據。
 圖片
圖片
/**
* 每小時同步所有站點23小時內的事件數據到緩存中
*/
@Scheduled(cron = "0 0 0/1 * * ?")
public void synAllSiteWebEventDataToRedis() {
synchronized (lock) {
synReportWebDataToRedis();
}
}現在經過優化以后,幾乎所有的數據都通過定時任務的方式來統計和存儲了,不在需要通過sql的方式實時統計了。最后還是會有個地方存在優化的空間,由于原業務接口是將所有統計報表的數據放在一個接口里面返回的,那么在不改變原參數和不拆分接口的情況下,可以使用Future做異步處理,畢竟每個報表的數據查詢統計操作都是獨立的,可以按照預估的查詢效率做個排序。那么,最終的一個方法就是將上述幾個報表數據進行組裝,并統一返回給前端。
@Override
public ApiDashboardResponse webDashboardV2(DashboardRequest request) throws Exception {
ApiDashboardResponse response = new ApiDashboardResponse();
// 1. 統計近12/24小時事件防護數量排名
Future<ReportWebEventTopVo> reportWebEventTopVoFuture = reportTaskExecutor.submit(() -> {
ReportWebEventTopVo webEventTopVo = reportWebEventTopService.getWebEventTopVo(request.getSiteId(), request.getTimeType());
return webEventTopVo;
});
// 2. 統計近12/24小時內各時段安全事件狀態
Future<ReportWebEventStatusVo> webEventTopVoFuture = reportTaskExecutor.submit(() -> {
ReportWebEventStatusVo reportWebEventStatus = reportWebEventStatusService.getReportWebEventStatus(request.getSiteId(), request.getTimeType());
return reportWebEventStatus;
});
// 3.統計top5的攻擊ip地址
Future<ReportWebIpTopVo> reportWebIpTopVoFuture = reportTaskExecutor.submit(() -> {
ReportWebIpTopVo reportWebIpTop5 = reportWebIpTopService.getReportWebIpTop5(request.getSiteId(), request.getTimeType());
return reportWebIpTop5;
});
// 4. 統計訪問top5的站點
Future<ReportWebSiteTopVo> reportWebSiteTopVoFuture = reportTaskExecutor.submit(() -> {
ReportWebSiteTopVo webSiteTop5 = reportWebSiteTopService.getWebSiteTop5Vo(request.getSiteId(), request.getTimeType());
return webSiteTop5;
});
// 拼裝響應數據
// 站點訪問量的數據都存儲在redis處理速度應該最快
ReportWebSiteTopVo reportWebSiteTopVo = reportWebSiteTopVoFuture.get();
ReportWebEventTopVo reportWebEventTopVo = reportWebEventTopVoFuture.get();
ReportWebEventStatusVo reportWebEventStatusVo = webEventTopVoFuture.get();
//攻擊源ip的數據可能相對較多
ReportWebIpTopVo reportWebIpTopVo = reportWebIpTopVoFuture.get();
//......
return response;
}小結
由于是公司項目的代碼,所以在這里只能粘貼一小部分。但代碼不是關鍵,關鍵在于如何在不借助其他數據處理的中間件的情況下,如何優化大量數據查詢速度。數據分類歸檔確實是一種可行的解決方式,如果你的項目中有一些需要以月,以天,以人或者其他標準來進行統計的話,不妨可以嘗試一下。
如果有更好的方法方式,可以忽略。下面的兩張圖是測試人員提供的優化前后對比,發現150萬的日志量,查詢時間在1秒內,比老版本提高很多倍。
優化前
 圖片
圖片
優化后
 圖片
圖片