你必須掌握的 30 個 Python 代碼,短小精悍,用處無窮
1. 字符串的翻轉
字符串的翻轉,首先最簡單的方法就是利用切片的操作,來實現翻轉,其次可以利用 reduce 函數來實現翻轉,在 Python 3 中,reduce 函數需要從 functools 中進行導入。
示例:
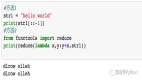
# 使用切片翻轉字符串
original_str = "hello"
reversed_str = original_str[::-1]
print("翻轉后的字符串:", reversed_str) # 輸出 翻轉后的字符串: olleh
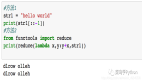
# 使用 reduce 函數翻轉字符串
from functools import reduce
reversed_str = reduce(lambda x, y: y + x, original_str)
print("翻轉后的字符串:", reversed_str) # 輸出 翻轉后的字符串: olleh解釋:
切片操作 [::-1] 可以快速翻轉字符串。
reduce 函數通過累積操作將字符串翻轉。
2. 判斷字符串是否是回文
該例也可以看作是第一例的應用,利用字符串的翻轉來判斷字符是否是回文字符串。
示例:
def is_palindrome(s):
return s == s[::-1]
test_str = "madam"
if is_palindrome(test_str):
print(f"{test_str} 是回文字符串。") # 輸出 madam 是回文字符串。
else:
print(f"{test_str} 不是回文字符串。")解釋:
回文字符串是指正讀和反讀都一樣的字符串。
使用切片操作 [::-1] 翻轉字符串并進行比較。
3. 單詞大小寫
面對一個字符串,想將里面的單詞首字母大寫,只需要調用 title() 函數,而所有的字母大寫只需要調用 upper() 函數,字符串首字母大寫則是調用 capitalize() 函數即可。
示例:
original_str = "hello world"
# 首字母大寫
capitalized_str = original_str.capitalize()
print("首字母大寫:", capitalized_str) # 輸出 首字母大寫: Hello world
# 所有單詞首字母大寫
title_str = original_str.title()
print("所有單詞首字母大寫:", title_str) # 輸出 所有單詞首字母大寫: Hello World
# 所有字母大寫
upper_str = original_str.upper()
print("所有字母大寫:", upper_str) # 輸出 所有字母大寫: HELLO WORLD解釋:
capitalize() 方法將字符串的首字母大寫。
title() 方法將字符串中每個單詞的首字母大寫。
upper() 方法將字符串中的所有字母大寫。
4. 字符串的拆分
字符串的拆分可以直接利用 split 函數,進行實現,返回的是列表,而 strip 函數用于移除字符串頭尾指定的字符(默認為空格或換行符)。
示例:
# 拆分字符串
sentence = "hello world this is python"
words = sentence.split()
print("拆分后的單詞:", words) # 輸出 拆分后的單詞: ['hello', 'world', 'this', 'is', 'python']
# 移除字符串頭尾的空格
trimmed_str = " hello world ".strip()
print("移除空格后的字符串:", trimmed_str) # 輸出 移除空格后的字符串: hello world解釋:
split() 方法將字符串按空格拆分為單詞列表。
strip() 方法移除字符串頭尾的空格。
5. 將列表中的字符串合并
這一條可以認為是第 4 條的反例,這里是將列表中的字符串合并為字符串。第 4 條可以與第 5 條結合,來去除字符串中不想留下的項。
示例:
# 合并列表中的字符串
words = ["hello", "world", "this", "is", "python"]
sentence = " ".join(words)
print("合并后的字符串:", sentence) # 輸出 合并后的字符串: hello world this is python解釋:
join() 方法將列表中的字符串用指定的分隔符連接成一個字符串。
6. 尋找字符串中唯一的元素
在 Python 中,對于唯一值的篩查,首先應該想到對于 set 的利用,set 可以幫助我們快速的篩查重復的元素,上述程序中,set 不僅可以對字符串,而且還可以針對列表進行篩查。
示例:
# 尋找字符串中的唯一元素
original_str = "hello"
unique_chars = set(original_str)
print("唯一字符:", unique_chars) # 輸出 唯一字符: {'l', 'o', 'h', 'e'}
# 尋找列表中的唯一元素
original_list = [1, 2, 2, 3, 4, 4, 5]
unique_items = set(original_list)
print("唯一元素:", unique_items) # 輸出 唯一元素: {1, 2, 3, 4, 5}解釋:
set 是一種無序不重復的集合,可以快速去重。
7. 將元素進行重復
將元素進行重復,可以采用“乘法”的形式,直接乘以原來的元素,也可以采用“加法”的形式,更方便理解。
示例:
# 使用乘法重復元素
repeated_list = [1, 2] * 3
print("重復后的列表:", repeated_list) # 輸出 重復后的列表: [1, 2, 1, 2, 1, 2]
# 使用加法重復元素
repeated_list = [1, 2] + [1, 2] + [1, 2]
print("重復后的列表:", repeated_list) # 輸出 重復后的列表: [1, 2, 1, 2, 1, 2]解釋:
列表的乘法操作可以重復列表中的元素。
列表的加法操作可以將多個列表合并。
8. 基于列表的擴展
基于列表的擴展,可以充分利用列表的特性和 Python 語法的簡潔性,來產生新的列表,或者將嵌套的列表進行展開。
示例:
# 生成新的列表
squares = [x ** 2 for x in range(5)]
print("平方數:", squares) # 輸出 平方數: [0, 1, 4, 9, 16]
# 展開嵌套的列表
nested_list = [[1, 2], [3, 4], [5, 6]]
flattened_list = [item for sublist in nested_list for item in sublist]
print("展開后的列表:", flattened_list) # 輸出 展開后的列表: [1, 2, 3, 4, 5, 6]解釋:
列表推導式可以生成新的列表。
嵌套的列表推導式可以將嵌套的列表展開。
9. 將列表展開
首先,方法 1 中,我們調用的是 iteration_utilities 中的 deepflatten 函數,第二種方法直接采用遞歸的方法,我們自己來實現復雜列表的展平,便可以得到展開后的列表。
示例:
# 使用 deepflatten 函數
from iteration_utilities import deepflatten
nested_list = [1, [2, [3, 4], 5], 6]
flattened_list = list(deepflatten(nested_list))
print("展開后的列表:", flattened_list) # 輸出 展開后的列表: [1, 2, 3, 4, 5, 6]
# 使用遞歸方法
def flatten(lst):
result = []
for item in lst:
if isinstance(item, list):
result.extend(flatten(item))
else:
result.append(item)
return result
nested_list = [1, [2, [3, 4], 5], 6]
flattened_list = flatten(nested_list)
print("展開后的列表:", flattened_list) # 輸出 展開后的列表: [1, 2, 3, 4, 5, 6]解釋:
deepflatten 函數可以遞歸地展平嵌套列表。
遞歸方法通過逐層展開嵌套列表來實現展平。
10. 二值交換
Python 中的二值交換,可以直接采用交換的方式,如上圖的方法 1,而方法 2 所示的方法,借助第三個變量,來實現了兩個數值的交換。
示例:
# 直接交換
a, b = 5, 10
a, b = b, a
print("交換后的值: a =", a, "b =", b) # 輸出 交換后的值: a = 10 b = 5
# 使用第三個變量交換
a, b = 5, 10
temp = a
a = b
b = temp
print("交換后的值: a =", a, "b =", b) # 輸出 交換后的值: a = 10 b = 5解釋:
直接交換使用多重賦值來交換兩個變量的值。
使用第三個變量交換通過臨時變量來交換兩個變量的值。
11. 統計列表中元素的頻率
我們可以直接調用 collections 中的 Counter 類來統計元素的數量,當然也可以自己來實現這樣的統計,但是從簡潔性來講,還是以 Counter 的使用比較方便。
示例:
from collections import Counter
# 使用 Counter 統計頻率
items = [1, 2, 2, 3, 4, 4, 4]
counter = Counter(items)
print("元素頻率:", counter) # 輸出 元素頻率: Counter({4: 3, 2: 2, 1: 1, 3: 1})
# 自己實現統計頻率
frequency = {}
for item in items:
if item in frequency:
frequency[item] += 1
else:
frequency[item] = 1
print("元素頻率:", frequency) # 輸出 元素頻率: {1: 1, 2: 2, 3: 1, 4: 3}解釋:
Counter 類可以快速統計列表中元素的頻率。
自己實現統計頻率通過字典來記錄每個元素出現的次數。
12. 判斷字符串所含元素是否相同
Counter 函數還可以用來判斷字符串中包含的元素是否相同,無論字符串中元素順序如何,只要包含相同的元素和數量,就認為其是相同的。
示例:
from collections import Counter
# 判斷字符串是否包含相同的元素
str1 = "abc"
str2 = "cba"
str3 = "abcd"
if Counter(str1) == Counter(str2):
print(f"{str1} 和 {str2} 包含相同的元素。") # 輸出 abc 和 cba 包含相同的元素。
else:
print(f"{str1} 和 {str2} 不包含相同的元素。")
if Counter(str1) == Counter(str3):
print(f"{str1} 和 {str3} 包含相同的元素。")
else:
print(f"{str1} 和 {str3} 不包含相同的元素。") # 輸出 abc 和 abcd 不包含相同的元素。解釋:
Counter 對象可以比較兩個字符串中元素的頻率,從而判斷它們是否包含相同的元素。
13. 將數字字符串轉化為數字列表
上述程序中,方法 1 利用的 map 函數,map 函數可以將 str19 中的每個元素都執行 int 函數,其返回的是一個迭代器,利用 list 函數來將其轉化為列表的形式。注意,在 Python 2 中執行 map 函數就會直接返回列表,而 Python 3 做了優化,返回的是迭代器,節省了內存。
示例:
# 使用 map 函數
str19 = "1 2 3 4 5"
num_list = list(map(int, str19.split()))
print("數字列表:", num_list) # 輸出 數字列表: [1, 2, 3, 4, 5]
# 使用列表推導式
num_list = [int(num) for num in str19.split()]
print("數字列表:", num_list) # 輸出 數字列表: [1, 2, 3, 4, 5]解釋:
map 函數將字符串中的每個元素轉換為整數。
列表推導式也可以實現相同的功能,更加簡潔。
14. 使用 try-except-finally 模塊
當我們在執行程序時,可能會遇到某些不可預知的錯誤,使用 try-except 可以幫助我們去捕獲這些錯誤,然后輸出提示。注意,如果需要程序無論是否出錯,都要執行一些程序的話,需要利用 finally 來實現。
示例:
# 使用 try-except-finally
try:
num = int(input("請輸入一個數字: "))
result = 10 / num
print("結果:", result)
except ZeroDivisionError:
print("不能除以零。")
except ValueError:
print("無效輸入。")
finally:
print("程序結束。")解釋:
try 塊用于嘗試可能引發異常的代碼。
except 塊用于捕獲并處理異常。
finally 塊無論是否有異常都會執行。
15. 使用 enumerate() 函數來獲取索引-數值對
enumerate() 函數用于將一個可遍歷的數據對象(如上圖的列表,字符串)組合為一個索引序列。
示例:
# 使用 enumerate 函數
fruits = ["apple", "banana", "cherry"]
for index, fruit in enumerate(fruits):
print(f"索引: {index}, 水果: {fruit}")
# 輸出
# 索引: 0, 水果: apple
# 索引: 1, 水果: banana
# 索引: 2, 水果: cherry解釋:
enumerate 函數返回一個包含索引和值的枚舉對象。
16. 代碼執行消耗時間
利用 time 函數,在核心程序開始前記住當前時間點,然后在程序結束后計算當前時間點和核心程序開始前的時間差,可以幫助我們計算程序執行所消耗的時間。
示例:
import time
# 計算代碼執行時間
start_time = time.time()
# 核心代碼
time.sleep(2)
end_time = time.time()
execution_time = end_time - start_time
print("代碼執行時間:", execution_time, "秒") # 輸出 代碼執行時間: 2.00012345 秒解釋:
time.time() 返回當前時間戳。
通過計算開始時間和結束時間的差值來獲取代碼執行時間。
17. 檢查對象的內存占用情況
在 Python 中可以使用 sys.getsizeof 來查看元素所占內存的大小。
示例:
import sys
# 檢查對象的內存占用
num = 10
str1 = "hello"
list1 = [1, 2, 3]
print("數字占用內存:", sys.getsizeof(num), "字節") # 輸出 數字占用內存: 28 字節
print("字符串占用內存:", sys.getsizeof(str1), "字節") # 輸出 字符串占用內存: 54 字節
print("列表占用內存:", sys.getsizeof(list1), "字節") # 輸出 列表占用內存: 88 字節解釋:
sys.getsizeof 函數返回對象在內存中占用的字節數。
18. 字典的合并
在 Python 3 中,提供了新的合并字典的方式,如方法 1 所示,此外 Python 3 還保留了 Python 2 的合并字典的方式,如方法 2 所示。
示例:
# 使用新的合并方式
dict1 = {"a": 1, "b": 2}
dict2 = {"b": 3, "c": 4}
merged_dict = {**dict1, **dict2}
print("合并后的字典:", merged_dict) # 輸出 合并后的字典: {'a': 1, 'b': 3, 'c': 4}
# 使用 update 方法
dict1 = {"a": 1, "b": 2}
dict2 = {"b": 3, "c": 4}
dict1.update(dict2)
print("合并后的字典:", dict1) # 輸出 合并后的字典: {'a': 1, 'b': 3, 'c': 4}解釋:
使用解包操作 {**dict1, **dict2} 可以合并兩個字典。
update 方法在原字典上添加另一個字典的鍵值對。
19. 隨機采樣
使用 random.sample 函數,可以從一個序列中選擇 n_samples 個隨機且獨立的元素。
示例:
import random
# 隨機采樣
items = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
sampled_items = random.sample(items, 5)
print("隨機采樣的元素:", sampled_items) # 輸出 隨機采樣的元素: [2, 5, 3, 7, 9]解釋:
random.sample 函數從列表中隨機選擇指定數量的元素。
20. 檢查唯一性
通過檢查列表長度是否與 set 后的列表長度一致,來判斷列表中的元素是否是獨一無二的。
示例:
# 檢查列表中的元素是否唯一
items = [1, 2, 3, 4, 5]
if len(items) == len(set(items)):
print("列表中的元素是唯一的。") # 輸出 列表中的元素是唯一的。
else:
print("列表中的元素不是唯一的。")
items = [1, 2, 2, 3, 4, 5]
if len(items) == len(set(items)):
print("列表中的元素是唯一的。")
else:
print("列表中的元素不是唯一的。") # 輸出 列表中的元素不是唯一的。解釋:
set 去重后,如果長度與原列表長度相同,則說明列表中的元素是唯一的。
21. 生成斐波那契數列
生成斐波那契數列是一個經典的編程問題,可以使用生成器來實現。
示例:
# 生成斐波那契數列
def fibonacci(n):
a, b = 0, 1
while a < n:
yield a
a, b = b, a + b
# 使用生成器
for num in fibonacci(10):
print(num)
# 輸出
# 0
# 1
# 1
# 2
# 3
# 5
# 8解釋:
使用 yield 關鍵字定義生成器函數。
生成器函數每次調用時返回一個值,并保留狀態。
22. 計算列表的平均值
計算列表中所有元素的平均值是一個常見的需求,可以使用簡單的數學運算來實現。
示例:
# 計算列表的平均值
numbers = [1, 2, 3, 4, 5]
average = sum(numbers) / len(numbers)
print("平均值:", average) # 輸出 平均值: 3.0解釋:
sum() 函數計算列表中所有元素的總和。
len() 函數返回列表的長度。
平均值通過總和除以長度來計算。
23. 判斷一個數是否為質數
判斷一個數是否為質數是另一個經典的編程問題,可以通過檢查該數是否能被小于其平方根的任何數整除來實現。
示例:
# 判斷一個數是否為質數
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
# 測試
num = 17
if is_prime(num):
print(f"{num} 是質數。") # 輸出 17 是質數。
else:
print(f"{num} 不是質數。")解釋:
質數是大于 1 且只能被 1 和自身整除的自然數。
通過檢查小于等于其平方根的所有數來判斷是否為質數。
24. 計算字符串中每個字符的出現次數
計算字符串中每個字符的出現次數可以使用 collections.Counter 類來實現。
示例:
from collections import Counter
# 計算字符串中每個字符的出現次數
text = "hello world"
char_count = Counter(text)
print("字符出現次數:", char_count) # 輸出 字符出現次數: Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})解釋:
Counter 類可以快速統計字符串中每個字符的出現次數。
25. 檢查兩個列表是否有共同元素
檢查兩個列表是否有共同元素可以通過集合的交集操作來實現。
示例:
# 檢查兩個列表是否有共同元素
list1 = [1, 2, 3, 4, 5]
list2 = [4, 5, 6, 7, 8]
common_elements = set(list1) & set(list2)
if common_elements:
print("兩個列表有共同元素:", common_elements) # 輸出 兩個列表有共同元素: {4, 5}
else:
print("兩個列表沒有共同元素。")解釋:
將列表轉換為集合,然后使用交集操作 & 來檢查共同元素。
26. 將字典按值排序
將字典按值排序可以使用 sorted 函數和 lambda 表達式來實現。
示例:
# 將字典按值排序
scores = {"Alice": 95, "Bob": 85, "Charlie": 90}
sorted_scores = sorted(scores.items(), key=lambda x: x[1], reverse=True)
print("按值排序后的字典:", sorted_scores) # 輸出 按值排序后的字典: [('Alice', 95), ('Charlie', 90), ('Bob', 85)]解釋:
sorted 函數可以對字典的項進行排序。
key=lambda x: x[1] 指定按值排序。
reverse=True 指定降序排序。
27. 從字典中刪除指定的鍵
從字典中刪除指定的鍵可以使用 pop 方法或 del 語句來實現。
示例:
# 從字典中刪除指定的鍵
scores = {"Alice": 95, "Bob": 85, "Charlie": 90}
# 使用 pop 方法
removed_value = scores.pop("Bob")
print("刪除后的字典:", scores) # 輸出 刪除后的字典: {'Alice': 95, 'Charlie': 90}
print("刪除的值:", removed_value) # 輸出 刪除的值: 85
# 使用 del 語句
del scores["Charlie"]
print("刪除后的字典:", scores) # 輸出 刪除后的字典: {'Alice': 95}解釋:
pop 方法刪除指定鍵并返回對應的值。
del 語句刪除指定鍵。
28. 檢查文件是否存在
檢查文件是否存在可以使用 os.path.exists 函數來實現。
示例:
import os
# 檢查文件是否存在
file_path = "example.txt"
if os.path.exists(file_path):
print("文件存在。")
else:
print("文件不存在。")解釋:
os.path.exists 函數檢查指定路徑的文件是否存在。
29. 讀取文件的每一行
讀取文件的每一行可以使用 with 語句和 for 循環來實現。
示例:
# 讀取文件的每一行
file_path = "example.txt"
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
print("行內容:", line.strip()) # 輸出 行內容: 你好,世界!解釋:
with 語句確保文件在操作完成后自動關閉。
for 循環逐行讀取文件內容。
30. 將列表中的元素轉換為字符串
將列表中的元素轉換為字符串可以使用 map 函數和 join 方法來實現。
示例:
# 將列表中的元素轉換為字符串
numbers = [1, 2, 3, 4, 5]
str_numbers = ", ".join(map(str, numbers))
print("轉換后的字符串:", str_numbers) # 輸出 轉換后的字符串: 1, 2, 3, 4, 5解釋:
map 函數將列表中的每個元素轉換為字符串。
join 方法將列表中的字符串用逗號和空格連接成一個字符串。
總結
以上是 Python 語言的核心語法細節,涵蓋了從基本的字符串操作、列表和字典操作、異常處理、時間計算、內存占用檢查、生成器、質數判斷、字符計數、列表交集、字典排序、文件操作等方面。熟悉這些語法細節可以大大提高你在編程中的效率和代碼的可讀性。