美團一面:聊聊分庫分表設計
1. 什么是分庫分表
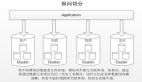
分庫:就是一個數據庫分成多個數據庫,部署到不同機器。
 圖片
圖片
分表:就是一個數據庫表分成多個表。
 圖片
圖片
2. 我們為什么需要分庫分表
在分庫分表之前,就需要考慮為什么需要拆分。我們不可能無緣無故就做分庫分表的。我們做一件事,肯定是有充分理由的。你可以好好跟面試官說一下你們分庫分表的理由哈。我現在就從兩個維度去回答,為什么要分庫?為什么要分表?
2.1 為什么要分庫
如果業務量劇增,數據庫可能會出現性能瓶頸,這時候我們就需要考慮拆分數據庫。從這兩方面來看:
 圖片
圖片
- 磁盤存儲
業務量劇增,MySQL單機磁盤容量會撐爆,拆成多個數據庫,磁盤使用率大大降低。
- 并發連接支撐
我們知道數據庫連接數是有限的。在高并發的場景下,大量請求訪問數據庫,MySQL單機是扛不住的!高并發場景下,會出現too many connections報錯。
當前非常火的微服務架構出現,就是為了應對高并發。它把訂單、用戶、商品等不同模塊,拆分成多個應用,并且把單個數據庫也拆分成多個不同功能模塊的數據庫(訂單庫、用戶庫、商品庫),以分擔讀寫壓力。
2.2 為什么要分表
假如你的單表數據量非常大,存儲和查詢的性能就會遇到瓶頸了,如果你做了很多優化之后還是無法提升效率的時候,就需要考慮做分表了。一般千萬級別數據量,就需要分表。
這是因為即使SQL命中了索引,如果表的數據量超過一千萬的話,查詢也是會明顯變慢的。這是因為索引一般是B+樹結構,數據千萬級別的話,B+樹的高度會增高,查詢就變慢啦。MySQL的B+樹的高度怎么計算的呢?跟大家復習一下:
InnoDB存儲引擎最小儲存單元是頁,一頁大小就是16k。B+樹葉子存的是數據,內部節點存的是鍵值+指針。索引組織表通過非葉子節點的二分查找法以及指針確定數據在哪個頁中,進而再去數據頁中找到需要的數據,B+樹結構圖如下:
 圖片
圖片
假設B+樹的高度為2的話,即有一個根結點和若干個葉子結點。這棵B+樹的存放總記錄數為=根結點指針數*單個葉子節點記錄行數。
如果一行記錄的數據大小為1k,那么單個葉子節點可以存的記錄數 =16k/1k =16. 非葉子節點內存放多少指針呢?我們假設主鍵ID為bigint類型,長度為8字節(面試官問你int類型,一個int就是32位,4字節),而指針大小在InnoDB源碼中設置為6字節,所以就是 8+6=14 字節,16k/14B =16*1024B/14B = 1170
因此,一棵高度為2的B+樹,能存放1170 * 16=18720條這樣的數據記錄。同理一棵高度為3的B+樹,能存放1170 *1170 *16 =21902400,大概可以存放兩千萬左右的記錄。B+樹高度一般為1-3層,如果B+到了4層,查詢的時候會多查磁盤的次數,SQL就會變慢。
因此單表數據量太大,SQL查詢會變慢,所以就需要考慮分表啦。
3. 什么時候考慮分庫分表?
對于MySQL,InnoDB存儲引擎的話,單表最多可以存儲10億級數據。但如果真的單表存儲這么多,性能就會非常差。一般數據量千萬級別,B+樹索引高度就會到3層以上了,查詢的時候會多查磁盤的次數,SQL就會變慢。
實際上,阿里巴巴的《Java開發手冊》提出:
單表行數超過500萬行或者單表容量超過2GB,才推薦進行分庫分表。
那我們是不是等到數據量到達五百萬,才開始分庫分表呢?
實際上,不能醬紫,我們應該提前規劃分庫分表,如果估算3年后,你的表都不會到達這個五百萬,則不需要分庫分表。也就是說不用杞人憂天。
MySQL服務器如果配置更好,是不是可以超過這個500萬這個量級,才考慮分庫分表?
雖然配置更好,可能數據量大之后,性能還是不錯,但是如果持續發展的話,還是要考慮分庫分表
一般什么類型業務表需要才分庫分表?
通用是一些流水表、用戶表等才考慮分庫分表,如果是一些配置類的表,則完全不用考慮,因為不太可能到達這個量級。
4.如何選擇分表鍵
分表鍵,即用來分庫/分表的字段,換種說法就是,你以哪個維度來分庫分表的。比如你按用戶ID分表、按時間分表、按地區分表,這些用戶ID、時間、地區就是分表鍵。
一般數據庫表拆分的原則,需要先找到業務的主題。比如你的數據庫表是一張企業客戶信息表,就可以考慮用了客戶號做為分表鍵。
為什么考慮用客戶號做分表鍵呢?
這是因為表是基于客戶信息的,所以,需要將同一個客戶信息的數據,落到一個表中,避免觸發全表路由。
5.非分表鍵如何查詢
分庫分表后,有時候無法避免一些業務場景查詢,比如需要通過非分表鍵來查詢某些信息。
假設一張用戶表,用userId做分表鍵,用它來分庫分表。但是用戶登錄時,需要根據用戶手機號來登陸。這時候,就需要通過手機號查詢用戶信息。而手機號是非分表鍵。。。
非分表鍵查詢,一般有這幾種方案:
- 遍歷:最粗暴的方法,就是遍歷所有的表,找出符合條件的手機號記錄(不建議)
- 將用戶信息冗余同步到ES,同步發送到ES,然后通過ES來查詢(推薦)
其實還有基因法:比如非分表鍵可以解析出分表鍵出來,比如常見的,訂單號生成時,可以包含客戶號進去,通過訂單號查詢,就可以解析出客戶號。但是這個場景有點特殊,手機號似乎不適合冗余userId,大家覺得呢,歡迎評論區留言討論哈~~
6. 分表策略如何選擇
6.1 range范圍
range,即范圍策略劃分表。比如我們可以將表的主鍵order_id,按照從0~300萬的劃分為一個表,300萬~600萬劃分到另外一個表。如下圖:
 圖片
圖片
有時候我們也可以按時間范圍來劃分,如不同年月的訂單放到不同的表,它也是一種range的劃分策略。
- 優點:Range范圍分表,有利于擴容。
- 缺點:可能會有熱點問題。因為訂單id是一直在增大的,也就是說最近一段時間都是匯聚在一張表里面的。比如最近一個月的訂單都在300萬~600萬之間,平時用戶一般都查最近一個月的訂單比較多,請求都打到order_1表啦。
6.2 hash取模
hash取模策略:
指定的路由key(一般是user_id、order_id、customer_no作為key)對分表總數進行取模,把數據分散到各個表中。
比如原始訂單表信息,我們把它分成4張分表:
 圖片
圖片
- 比如id=1,對4取模,就會得到1,就把它放到t_order_1;
- id=3,對4取模,就會得到3,就把它放到t_order_3;
一般,我們會取哈希值,再做取余:
Math.abs(orderId.hashCode()) % table_number- 優點:hash取模的方式,不會存在明顯的熱點問題。
- 缺點:如果未來某個時候,表數據量又到瓶頸了,需要擴容,就比較麻煩。所以一般建議提前規劃好,一次性分夠。(可以考慮一致性哈希)
6.3 一致性Hash
如果用hash方式分表,前期規劃不好,需要擴容二次分表,表的數量需要增加,所以hash值需要重新計算,這時候需要遷移數據了。
比如我們開始分了10張表,之后業務擴展需要,增加到20張表。那問題就來了,之前根據orderId取模10后的數據分散在了各個表中,現在需要重新對所有數據重新取模20來分配數據
為了解決這個擴容遷移問題,可以使用一致性hash思想來解決。
一致性哈希:在移除或者添加一個服務器時,能夠盡可能小地改變已存在的服務請求與處理請求服務器之間的映射關系。一致性哈希解決了簡單哈希算法在分布式哈希表存在的動態伸縮等問題
7. 如何避免熱點問題數據傾斜(熱點數據)
如果我們根據時間范圍分片,某電商公司11月搞營銷活動,那么大部分的數據都落在11月份的表里面了,其他分片表可能很少被查詢,即數據傾斜了,有熱點數據問題了。
我們可以使用range范圍+ hash哈希取模結合的分表策略,簡單的做法就是:
在拆分庫的時候,我們可以先用range范圍方案,比如訂單id在0~4000萬的區間,劃分為訂單庫1;id在4000萬~8000萬的數據,劃分到訂單庫2,將來要擴容時,id在8000萬~1.2億的數據,劃分到訂單庫3。然后訂單庫內,再用hash取模的策略,把不同訂單劃分到不同的表。
 圖片
圖片
8.分庫后,事務問題如何解決
分庫分表后,假設兩個表在不同的數據庫,那么本地事務已經無效啦,需要使用分布式事務了。
常用的分布式事務解決方案有:
- 兩階段提交
- 三階段提交
- TCC
- 本地消息表
- 最大努力通知
- saga
大家可以看下這幾篇文章:
- 后端程序員必備:分布式事務基礎篇
- 看一遍就理解:分布式事務詳解
- 框架篇:分布式一致性解決方案
9. 跨節點Join關聯問題
在單庫未拆分表之前,我們如果要使用join關聯多張表操作的話,簡直so easy啦。但是分庫分表之后,兩張表可能都不在同一個數據庫中了,那么如何跨庫join操作呢?
跨庫Join的幾種解決思路:
- 字段冗余:把需要關聯的字段放入主表中,避免關聯操作;比如訂單表保存了賣家ID(sellerId),你把賣家名字sellerName也保存到訂單表,這就不用去關聯賣家表了。這是一種空間換時間的思想。
- 全局表:比如系統中所有模塊都可能會依賴到的一些基礎表(即全局表),在每個數據庫中均保存一份。
- 數據抽象同步:比如A庫中的a表和B庫中的b表有關聯,可以定時將指定的表做同步,將數據匯合聚集,生成新的表。一般可以借助ETL工具。
- 應用層代碼組裝:分開多次查詢,調用不同模塊服務,獲取到數據后,代碼層進行字段計算拼裝。
10. order by,group by等聚合函數問題
跨節點的count,order by,group by以及聚合函數等問題,都是一類的問題,它們一般都需要基于全部數據集合進行計算。可以分別在各個節點上得到結果后,再在應用程序端進行合并。
也使用支持分庫分表的數據庫中間件(如MyCAT、ShardingSphere等),這些中間件通常提供了對跨分片查詢的支持,可以在一定程度上簡化聚合操作的處理。
還可以使用專門的聚合服務或大數據處理平臺(如Apache Flink、Apache Spark等)來進行全局聚合。這種方法可以處理大數據量,但需要額外的系統資源。
11. 分庫分表后的分頁問題
- 方案1(全局視野法):在各個數據庫節點查到對應結果后,在代碼端匯聚再分頁。這樣優點是業務無損,精準返回所需數據;缺點則是會返回過多數據,增大網絡傳輸,也會造成空查,
比如分庫分表前,你是根據創建時間排序,然后獲取第2頁數據。如果你是分了兩個庫,那你就可以每個庫都根據時間排序,然后都返回2頁數據,然后把兩個數據庫查詢回來的數據匯總,再根據創建時間進行內存排序,最后再取第2頁的數據。
- 方案2(業務折衷法-禁止跳頁查詢):這種方案需要業務妥協一下,只有上一頁和下一頁,不允許跳頁查詢了。
這種方案,查詢第一頁時,是跟全局視野法一樣的。但是下一頁時,需要把當前最大的創建時間傳過來,然后每個節點,都查詢大于創建時間的一頁數據,接著匯總,內存排序返回。
12. 分布式ID
數據庫被切分后,不能再依賴數據庫自身的主鍵生成機制啦,最簡單可以考慮UUID,或者使用雪花算法生成分布式ID。
雪花算法是一種生成分布式全局唯一ID的算法,生成的ID稱為Snowflake IDs。這種算法由Twitter創建,并用于推文的ID。
一個Snowflake ID有64位。
- 第1位:Java中long的最高位是符號位代表正負,正數是0,負數是1,一般生成ID都為正數,所以默認為0。
- 接下來前41位是時間戳,表示了自選定的時期以來的毫秒數。
- 接下來的10位代表計算機ID,防止沖突。
- 其余12位代表每臺機器上生成ID的序列號,這允許在同一毫秒內創建多個Snowflake ID。
 圖片
圖片
但是雪花算法存在時鐘回撥問題,大家知道如何解決嘛,歡迎評論區討論,嘻嘻~
13. 分庫分表選擇哪種中間件
目前流行的分庫分表中間件比較多:
- Sharding-JDBC
- cobar
- Mycat
- Atlas
- TDDL(淘寶)
- vitess
 圖片
圖片
我們項目當前就是使用Sharding-JDBC實現的分庫分表。
14.如何評估分庫數量
- 對于MySQL來說的話,一般單庫超過5千萬記錄,DB的壓力就非常大了。所以分庫數量多少,需要看單庫處理記錄能力有關。
- 如果分庫數量少,達不到分散存儲和減輕DB性能壓力的目的;如果分庫的數量多,對于跨多個庫的訪問,應用程序需要訪問多個庫。
- 一般是建議分4~10個庫,我們公司的企業客戶信息,就分了10個庫。
15.垂直分庫、水平分庫、垂直分表、水平分表的區別
- 水平分庫:以字段為依據,按照一定策略(hash、range等),將一個庫中的數據拆分到多個庫中。
- 水平分表:以字段為依據,按照一定策略(hash、range等),將一個表中的數據拆分到多個表中。
- 垂直分庫:以表為依據,按照業務歸屬不同,將不同的表拆分到不同的庫中。
- 垂直分表:以字段為依據,按照字段的活躍性,將表中字段拆到不同的表(主表和擴展表)中。
16.分表要停服嘛?不停服怎么做?
不用停服。不停服的時候,應該怎么做呢,主要分五個步驟:
- 編寫代理層,加個開關(控制訪問新的DAO還是老的DAO,或者是都訪問),灰度期間,還是訪問老的DAO。
- 發版全量后,開啟雙寫,既在舊表新增和修改,也在新表新增和修改。日志或者臨時表記下新表ID起始值,舊表中小于這個值的數據就是存量數據,這批數據就是要遷移的。
- 通過腳本把舊表的存量數據寫入新表。
- 停讀舊表改讀新表,此時新表已經承載了所有讀寫業務,但是這時候不要立刻停寫舊表,需要保持雙寫一段時間。
- 當讀寫新表一段時間之后,如果沒有業務問題,就可以停寫舊表啦
 圖片
圖片