業務腳本:為什么說可編程訂閱式緩存服務更有用?
我們已經習慣了使用緩存集群對數據做緩存。然而,這種常見的內存緩存服務存在諸多不便之處。首先,集群會獨占大量的內存。這意味著在資源有限的情況下,可能會對其他系統資源的分配造成壓力,影響整體系統的性能和穩定性。
其次,不能原子修改緩存的某一個字段。在一些對數據一致性要求較高的場景中,這可能會引發數據不一致的問題,從而影響業務的正常運行。
再者,多次通訊有網絡損耗。尤其是在頻繁進行數據交互的情況下,網絡損耗可能會導致數據傳輸延遲增加,降低系統的響應速度。
另外,很多時候我們獲取數據并不需要全部字段,但因為緩存不支持篩選,在批量獲取數據的場景下性能就會下降很多。這種情況在數據量較大時尤為明顯,會嚴重影響系統的效率。
而這些問題在讀多寫多的場景下,會更加突出。那么,有什么方式能夠解決這些問題呢?
緩存即服務
可編程訂閱式緩存服務意味著我們能夠自行實現一個數據緩存服務,進而直接提供給業務服務使用。這種實現方式具有獨特的優勢,它可以依據業務的具體需求,主動地對數據進行緩存,并且能夠提供一些數據整理以及計算的服務。
雖然自行實現這樣的數據緩存服務過程較為繁瑣,然而其帶來的優勢卻是顯著的。除了吞吐能力能夠得到提升之外,我們還可以實現眾多有趣的定制功能。比如,我們可以根據業務的特定邏輯對數據進行個性化的整理和優化,使其更符合業務的使用場景。
同時,它還具備更好的計算能力。這使得我們在處理數據時,能夠更加高效地進行各種復雜的計算操作,為業務提供更強大的數據支持。
甚至,它可以讓我們的緩存直接對外提供基礎數據的查詢服務。這樣一來,業務在獲取基礎數據時無需再通過繁瑣的流程從其他數據源獲取,大大提高了數據獲取的效率和便捷性,進一步提升了整個業務系統的性能和靈活性。
 圖片
圖片
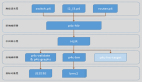
上圖展示了一個自實現的緩存功能結構。不得不說,這種緩存的性能和效果更為出色,究其原因在于它對數據的處理方式與傳統模式大相徑庭。
在傳統模式下,緩存服務并不會對數據進行任何加工處理,所保存的是系列化的字符串。在這種情況下,大部分的數據無法直接進行修改。當我們利用這種緩存對外提供服務時,業務服務不得不將所有數據取出至本地內存,隨后進行遍歷加工才能投入使用。
然而,可編程緩存卻能夠將數據結構化地存儲在 map 中。相較于傳統模式下序列化的字符串,它更為節省內存。更為便捷的是,我們的服務無需再從其他服務獲取數據來進行計算,如此便能夠節省大量網絡交互所耗費的時間,因而非常適合應用于對實時要求極高的場景之中。
倘若我們的熱數據量頗為龐大,那么可以結合 RocksDB 等嵌入式引擎,憑借有限的內存來為大量數據提供服務。除了常規的數據緩存服務之外,可編程緩存還具備諸多強大的功能,比如支持對緩存數據的篩選過濾、統計計算、查詢、分片以及數據拼合。
在此,關于查詢服務,我要補充說明一下。對于對外的服務,建議通過類似 Redis 的簡單文本協議來提供服務,因為這樣相較于 HTTP 協議,其性能會更為優越。
Lua 腳本引擎
雖然緩存提供業務服務能夠提升業務的靈活度,然而這種方式也存在諸多缺點。其中最大的缺點便是業務修改后,我們需要重啟服務才能夠更新我們的邏輯。由于內存中存儲了大量的數據,每重啟一次,數據就需要經歷繁瑣的預熱過程,同步代價極為高昂。
為此,我們需要對設計進行再次升級。在這種情況下,lua 腳本引擎不失為一個上佳的選擇。lua 是一種小巧的嵌入式腳本語言,借助它能夠實現一個高性能、可熱更新的腳本服務,進而與嵌入的服務進行高效靈活的互動。
我繪制了一張示意圖,用以描述如何通過 lua 腳本來具體實現可編程緩存服務:
 圖片
圖片
上圖所示,可以看到我們提供了 Kafka 消費、周期任務管理、內存緩存、多種數據格式支持、多種數據驅動適配這些服務。不僅僅如此,為了減少由于邏輯變更導致的服務經常重啟的情況,我們還以性能損耗為代價,在緩存服務里嵌入了 lua 腳本引擎,借此實現動態更新業務的邏輯。lua 引擎使用起來很方便,我們結合后面這個實現例子看一看,這是一個 Go 語言寫的嵌入 lua 實現,代碼如下所示:
package main
import "github.com/yuin/gopher-lua"
// VarChange 用于被lua調用的函數
func VarChange(L *lua.LState) int {
lv := L.ToInt(1) //獲取調用函數的第一個參數,并且轉成int
L.Push(lua.LNumber(lv * 2)) //將參數內容直接x2,并返回結果給lua
return 1 //返回結果參數個數
}
func main() {
L := lua.NewState() //新lua線程
defer L.Close() //程序執行完畢自動回收
// 注冊lua腳本可調用函數
// 在lua內調用varChange函數會調用這里注冊的Go函數 VarChange
L.SetGlobal("varChange", L.NewFunction(VarChange))
//直接加載lua腳本
//腳本內容為:
// print "hello world"
// print(varChange(20)) # lua中調用go聲明的函數
if err := L.DoFile("hello.lua"); err != nil {
panic(err)
}
// 或者直接執行string內容
if err := L.DoString(`print("hello")`); err != nil {
panic(err)
}
}
// 執行后輸出結果:
//hello world
//40
//hello從這個例子里我們可以看出,lua 引擎是可以直接執行 lua 腳本的,而 lua 腳本可以和 Golang 所有注冊的函數相互調用,并且可以相互傳遞交換變量。回想一下,我們做的是數據緩存服務,所以需要讓 lua 能夠獲取修改服務內的緩存數據,那么,lua 是如何和嵌入的語言交換數據的呢?我們來看看兩者相互調用交換的例子:
package main
import (
"fmt"
"github.com/yuin/gopher-lua"
)
func main() {
L := lua.NewState()
defer L.Close()
//加載腳本
err := L.DoFile("vardouble.lua")
if err != nil {
panic(err)
}
// 調用lua腳本內函數
err = L.CallByParam(lua.P{
Fn: L.GetGlobal("varDouble"), //指定要調用的函數名
NRet: 1, // 指定返回值數量
Protect: true, // 錯誤返回error
}, lua.LNumber(15)) //支持多個參數
if err != nil {
panic(err)
}
//獲取返回結果
ret := L.Get(-1)
//清理下,等待下次用
L.Pop(1)
//結果轉下類型,方便輸出
res, ok := ret.(lua.LNumber)
if !ok {
panic("unexpected result")
}
fmt.Println(res.String())
}
// 輸出結果:
// 30其中 vardouble.lua 內容為:
function varDouble(n)
return n * 2
end過這個方式,lua 和 Golang 就可以相互交換數據和相互調用。對于這種緩存服務普遍要求性能很好,這時我們可以統一管理加載過 lua 的腳本及 LState 腳本對象的實例對象池,這樣會更加方便,不用每調用一次 lua 就加載一次腳本,方便獲取和使用多線程、多協程。
Lua 腳本統一管理
從前面所做的講解當中,我們能夠察覺到,在實際進行使用的時候,lua 會有許多實例在內存之中運行著。
為了能夠對這些實例實現更為妥善的管理,并且進一步提升效率,我們最為理想的做法便是運用一個專門的腳本管理系統,來對所有 lua 的運行實例展開管理。通過這樣的操作,便可以達成對腳本進行統一更新、實現編譯緩存、完成資源調度以及對單例加以控制等一系列目標。
lua 腳本其自身特性是單線程的,不過它的體量非常輕,單個實例所造成的內存損耗大概僅為 144kb 左右。在一些服務當中,平常運行的時候甚至能夠同時開啟成百上千個 lua 實例。
倘若要提高服務的并行處理能力,我們可以選擇啟動多個協程,讓每一個協程都能夠獨立去運行一個 lua 線程。
正是出于這樣的需求,gopher-lua 庫為我們提供了一種類似于線程池的實現方式。借助于這種方式,我們就不再需要頻繁地去創建以及關閉 lua 了,其官方所給出的具體例子如下:
//保存lua的LState的池子
type lStatePool struct {
m sync.Mutex
saved []*lua.LState
}
// 獲取一個LState
func (pl *lStatePool) Get() *lua.LState {
pl.m.Lock()
defer pl.m.Unlock()
n := len(pl.saved)
if n == 0 {
return pl.New()
}
x := pl.saved[n-1]
pl.saved = pl.saved[0 : n-1]
return x
}
//新建一個LState
func (pl *lStatePool) New() *lua.LState {
L := lua.NewState()
// setting the L up here.
// load scripts, set global variables, share channels, etc...
//在這里我們可以做一些初始化
return L
}
//把Lstate對象放回到池中,方便下次使用
func (pl *lStatePool) Put(L *lua.LState) {
pl.m.Lock()
defer pl.m.Unlock()
pl.saved = append(pl.saved, L)
}
//釋放所有句柄
func (pl *lStatePool) Shutdown() {
for _, L := range pl.saved {
L.Close()
}
}
// Global LState pool
var luaPool = &lStatePool{
saved: make([]*lua.LState, 0, 4),
}
//協程內運行的任務
func MyWorker() {
//通過pool獲取一個LState
L := luaPool.Get()
//任務執行完畢后,將LState放回pool
defer luaPool.Put(L)
// 這里可以用LState變量運行各種lua腳本任務
//例如 調用之前例子中的的varDouble函數
err = L.CallByParam(lua.P{
Fn: L.GetGlobal("varDouble"), //指定要調用的函數名
NRet: 1, // 指定返回值數量
Protect: true, // 錯誤返回error
}, lua.LNumber(15)) //這里支持多個參數
if err != nil {
panic(err) //僅供演示用,實際生產不推薦用panic
}
}
func main() {
defer luaPool.Shutdown()
go MyWorker() // 啟動一個協程
go MyWorker() // 啟動另外一個協程
/* etc... */
}通過這個方式我們可以預先創建一批 LState,讓它們加載好所有需要的 lua 腳本,當我們執行 lua 腳本時直接調用它們,即可對外服務,提高我們的資源復用率。
變量的交互
實際上,我們的數據既能夠存儲在 lua 當中,也可以存放在 Go 里面,然后通過相互調用的方式來獲取對方所存儲的數據。就我個人而言,更習慣把數據放在 Go 中進行封裝處理,之后供 lua 來調用。之所以會這樣選擇,主要是因為這種做法相對更加規范,在管理方面也會比較便捷,畢竟腳本在運行過程中是會存在一定損耗的。
前面也曾提到過,我們會采用 struct 和 map 相互組合的方式來對一些數據進行處理,進而對外提供數據服務。那么,lua 和 Golang 之間究竟是如何實現像 struct 這一類數據的交換呢?
在這里,我選取了官方所提供的例子,并且還額外添加了大量的注釋內容,其目的就是為了能夠更好地幫助大家去理解這兩者之間的數據交互過程。
// go用于交換的 struct
type Person struct {
Name string
}
//為這個類型定義個類型名稱
const luaPersonTypeName = "person"
// 在LState對象中,聲明這種類型,這個只會在初始化LState時執行一次
// Registers my person type to given L.
func registerPersonType(L *lua.LState) {
//在LState中聲明這個類型
mt := L.NewTypeMetatable(luaPersonTypeName)
//指定 person 對應 類型type 標識
//這樣 person在lua內就像一個 類聲明
L.SetGlobal("person", mt)
// static attributes
// 在lua中定義person的靜態方法
// 這句聲明后 lua中調用person.new即可調用go的newPerson方法
L.SetField(mt, "new", L.NewFunction(newPerson))
// person new后創建的實例,在lua中是table類型,你可以把table理解為lua內的對象
// 下面這句主要是給 table定義一組methods方法,可以在lua中調用
// personMethods是個map[string]LGFunction
// 用來告訴lua,method和go函數的對應關系
L.SetField(mt, "__index", L.SetFuncs(L.NewTable(), personMethods))
}
// person 實例對象的所有method
var personMethods = map[string]lua.LGFunction{
"name": personGetSetName,
}
// Constructor
// lua內調用person.new時,會觸發這個go函數
func newPerson(L *lua.LState) int {
//初始化go struct 對象 并設置name為 1
person := &Person{L.CheckString(1)}
// 創建一個lua userdata對象用于傳遞數據
// 一般 userdata包裝的都是go的struct,table是lua自己的對象
ud := L.NewUserData()
ud.Value = person //將 go struct 放入對象中
// 設置這個lua對象類型為 person type
L.SetMetatable(ud, L.GetTypeMetatable(luaPersonTypeName))
// 將創建對象返回給lua
L.Push(ud)
//告訴lua腳本,返回了數據個數
return 1
}
// Checks whether the first lua argument is a *LUserData
// with *Person and returns this *Person.
func checkPerson(L *lua.LState) *Person {
//檢測第一個參數是否為其他語言傳遞的userdata
ud := L.CheckUserData(1)
// 檢測是否轉換成功
if v, ok := ud.Value.(*Person); ok {
return v
}
L.ArgError(1, "person expected")
return nil
}
// Getter and setter for the Person#Name
func personGetSetName(L *lua.LState) int {
// 檢測第一個棧,如果就只有一個那么就只有修改值參數
p := checkPerson(L)
if L.GetTop() == 2 {
//如果棧里面是兩個,那么第二個是修改值參數
p.Name = L.CheckString(2)
//代表什么數據不返回,只是修改數據
return 0
}
//如果只有一個在棧,那么是獲取name值操作,返回結果
L.Push(lua.LString(p.Name))
//告訴會返回一個參數
return 1
}
func main() {
// 創建一個lua LState
L := lua.NewState()
defer L.Close()
//初始化 注冊
registerPersonType(L)
// 執行lua腳本
if err := L.DoString(`
//創建person,并設置他的名字
p = person.new("Steven")
print(p:name()) -- "Steven"
//修改他的名字
p:name("Nico")
print(p:name()) -- "Nico"
`); err != nil {
panic(err)
}
}可以看到,我們通過 lua 腳本引擎就能很方便地完成相互調用和交換數據,從而實現很多實用的功能,甚至可以用少量數據直接寫成 lua 腳本的方式來加載服務。
緩存預熱與數據來源
在對 lua 有了一定了解之后,接下來我們一起探討一下服務是如何加載數據的。
當服務啟動之時,我們首先要做的就是將數據緩存加載到緩存當中,以此來完成緩存預熱的操作。只有在數據全部加載完成之后,才會開放對外的 API 端口,從而正式對外提供服務。
在這個加載數據的過程中,如果引入了 lua 腳本的話,那么就能夠在服務啟動之際,針對不同格式的數據開展適配加工的工作。如此一來,數據的來源也會變得更加豐富多樣。
通常情況下,常見的數據來源是由大數據挖掘周期所生成的全量數據離線文件。這些文件會通過 NFS 或者 HDFS 進行掛載操作,并且會定期進行刷新,以便加載最新的文件。這種通過掛載離線文件來獲取數據的方式,比較適合那些數據量龐大且更新速度較為緩慢的數據。不過,它也存在一定的缺點,那就是在加載數據的時候需要對數據進行整理工作。要是情況較為復雜的話,比如對于 800M 大小的數據,可能就需要花費 1 至 10 分鐘的時間才能夠完成加載操作。
除了采用上述這種利用文件獲取數據的方式之外,我們還可以在程序啟動之后,通過掃描數據表的方式來恢復數據。但是這樣做的話,數據庫將會承受一定的壓力,所以建議使用專門的從庫來進行此項操作。而且需要注意的是,相較于通過磁盤離線文件獲取數據的方式,這種掃描數據表的方式其加載速度會更慢一些。
前面所提及的那兩種數據加載方式,在速度方面都存在一定的不足。接下來,我們還可以考慮另外一種做法,那就是將 RocksDB 嵌入到進程之中。通過這樣的操作,能夠極大幅度地提升我們的數據存儲容量,進而實現內存與磁盤之間高性能的讀取和寫入操作。不過,這么做也是有代價的,那就是相對而言會使得查詢性能出現一定程度的降低。
關于 RocksDB 的數據獲取,我們可以借助大數據來生成符合 RocksDB 格式的數據庫文件,然后將其拷貝給我們的服務,以便服務能夠直接進行加載。采用這種方式的好處在于,它可以大幅減少系統在啟動過程中整理以及加載數據所耗費的時間,從而能夠實現更多的數據查詢操作。
另外,倘若我們存在對于本地有關系數據進行查詢的需求,那么還可以選擇嵌入 SQLite 引擎。通過這個引擎,我們就能夠開展各種各樣的關系數據查詢工作。對于 SQLite 的數據生成,同樣也可以利用相關工具提前完成,生成之后便可以直接提供給我們的服務使用。但在這里需要特別注意的是,這個數據庫的數據量最好不要超過 10 萬條,不然的話,很有可能會導致服務出現卡頓的現象。
最后,在涉及離線文件加載的情況時,我們最好能夠制作一個類似于 CheckSum 的文件。制作這個文件的目的在于,在加載文件之前,可以利用它來檢查文件的完整性。因為我們所使用的是網絡磁盤,所以不太能確定這個文件是否正在處于拷貝的過程當中,這就需要運用一些小技巧來確保我們的數據完整性。其中,最為簡單粗暴的方式就是,在每次拷貝完畢之后,生成一個與原文件同名的文件,并且在這個新生成的文件內部記錄一下它的 CheckSum 值,這樣一來,便方便我們在加載文件之前進行校驗操作。
離線文件在實際應用當中具有一定的優勢,它能夠幫助我們快速實現多個節點之間的數據共享以及數據的統一。倘若我們要求多個節點的數據要保持最終的一致性,那么就需要通過離線與同步訂閱相結合的方式來實現數據的同步操作。
訂閱式數據同步及啟動同步
那么,咱們的數據究竟是怎樣實現同步更新的呢?通常而言,我們的數據是從多個基礎數據服務獲取而來的。要是希望能夠實時同步數據所發生的更改情況,一般會采用訂閱 binlog 的方式,先將變更的相關信息同步到 Kafka 當中。接著,再憑借 Kafka 的分組消費功能,去通知那些分布在不同集群里面的緩存。
當收到消息變更的服務接收到相關通知后,就會觸發 lua 腳本,進而依據腳本對數據展開同步更新的操作。通過 lua 腳本的運作,我們能夠以觸發式的方式同步更新其他與之相關的緩存。
比如說,當用戶購買了一個商品的時候,我們就需要同步刷新與之相關的一些數據,像是他的積分情況、訂單信息以及消息列表的個數等等,以此來確保各項數據的一致性和實時性。
周期任務
在談及任務管理這個話題時,就不得不著重說一說周期任務了。周期任務在通常情況下,主要是被用于對數據統計進行刷新的工作。我們只要將周期任務和 lua 自定義邏輯腳本相互結合起來加以運用,便能夠輕松實現定期開展統計的操作,這無疑是給我們的工作帶來了更多的便利條件。
在執行定期任務或者進行延遲刷新的這個過程當中,較為常見的一種處理方式就是運用時間輪來對任務加以管理。通過采用這種方式,能夠把定時任務轉化為事件觸發的形式,如此一來,就可以非常便捷地對內存當中那些有待觸發的任務列表進行管理了,進而能夠實現并行處理多個周期任務,也就無需再通過使用 sleep 循環這種方式去不斷地進行查詢操作了。要是您對時間輪的具體實現方式感興趣的話,可以直接點擊此處進行查看哦。
另外,前面也曾提到過,我們所用到的很多數據都是借助離線文件來進行批量更新的。假如是每一小時就更新一次數據的話,那么在這一小時之內新更新的數據就需要進行同步處理。一般而言,處理的方式是這樣的:當我們的服務啟動并加載離線文件的時候,要把這個離線文件生成的時間給保存下來,然后憑借這個保存下來的時間來對數據更新隊列當中的消息進行過濾操作。等到我們的隊列任務進度追趕至接近當前時間的時候,再開啟對外提供數據的服務。
總結
在那些讀多寫多的服務當中,實時交互類的服務數量相當多,并且這類服務對于數據的實時性有著很高的要求。若是采用集中型緩存的方式,往往很難滿足此類服務所提出的各項需求。
基于這樣的情況,在行業當中,多數會選擇通過服務自身內存中的數據來為實時交互服務提供支持。然而,這種做法存在一個明顯的弊端,那就是維護起來特別麻煩,一旦服務重啟,就必須要對數據進行恢復操作。
為了能夠實現業務邏輯在無需重啟的情況下就可以完成更新,在行業里通常會采用內嵌腳本的熱更新方案。在眾多的腳本引擎當中,較為常見且通用的就是 lua 腳本引擎了。lua 是一種非常流行且使用起來極為方便的腳本引擎,在行業領域中,許多知名的游戲以及各類服務都借助 lua 來實現高性能服務的定制化業務功能,像 Nginx、Redis 等就是如此。
當我們把 lua 和我們所定制的緩存服務相互結合起來的時候,便能夠打造出很多強大的功能,以此來應對各種各樣不同的場景需求。
由于 lua 具備十分節省內存的特性,所以我們可以在進程當中開啟數量多達成千上萬的 lua 小線程。甚至可以做到為每一個用戶都配備一個 LState 線程,從而為客戶端提供類似于狀態機一樣的服務。
通過運用上述所提到的這些方法,再將 lua 和靜態語言之間進行數據交換以及相互調用,并且配合上我們所實施的任務管理以及各種各樣的數據驅動方式,這樣就能夠構建出一個幾乎可以應對所有情況的萬能緩存服務了。
在此,推薦大家在一些小型項目當中親自去實踐一下上述的這些內容。相信通過這樣的實踐,會讓大家從一個與以往不同的視角去重新審視那些已經習慣了的服務,如此一來,大家必定會從中獲得更多的收獲。