從4.75s到0.6s,我只動了一條SQL
一、前言
軟件在持續的開發和維護過程中,會不斷添加新功能和修復舊的缺陷,這往往伴隨著代碼的快速增長和復雜性的提升。若代碼庫沒有得到良好的管理和重構,就可能積累大量的技術債務,包括不一致的設計、冗余代碼、過時的庫和框架以及不再使用的功能。這些因素都會導致軟件結構的脆弱,增加系統出錯的可能性,我們俗稱為“代碼腐化”,持續性的重構是一種好的解決方案。SQL也是我們常用的代碼語言,雖然SQL本身作為一種標準化的查詢語言不會"腐化",但是使用SQL編寫的數據庫應用程序、查詢和架構確實可能會因時間推移而面臨類似于代碼腐化的問題。
平臺技術部一直堅持做穩定性建設,其中慢SQL就作為一個核心指標在治理。在治理進入深水區時,就會啃到因“SQL腐化”引入的復雜SQL治理這種硬骨頭。本文以一個案例為依托來看看怎樣像重構Java等高級編程語言一樣來重構SQL。
二、JDL路由系統復雜SQL治理案例
路由規劃是為保障客戶體驗,依據產品需求及時效目標,設計物流網絡中每個節點的操作時長,然后通過節點互相串聯保障全程鏈通且綜合最優,同步輸出規劃方案并指導運營現場操作,雙向校驗優化,實現路由規劃與實際運營的不斷趨合。
簡言之,路由系統支持的路由規劃就是在做基于物流網絡運營的運籌優化,網絡是基礎。而網絡的基礎又是線路,必然對線路的操作會“千奇百怪”。
1.問題SQL
select count(*) total_count from (select * from (select a.line_store_goods_id as line_resource_id, a.group_num as group_num, a.approval_erp as approval_erp, a.approval_person as approval_person, a.approval_status as approval_status, a.approval_time as approval_time, a.approval_remark as approval_remark, a.master_slave as master_slave, a.parent_line_code as parent_line_code, a.remarks as remarks, a.operator_time, a.same_stowage as same_stowage, b.start_org_id, b.start_org_name, b.start_province_id, b.start_province_name, b.start_city_id, b.start_city_name, b.start_node_code, b.start_node_name, b.end_org_id, b.end_org_name, b.end_province_id, b.end_province_name, b.end_city_id, b.end_city_name, b.end_node_code, b.end_node_name, b.depart_time, b.arrive_time, b.depart_wave_code, b.arrive_wave_code, b.enable_time, b.disable_time, a.store_enable_time, a.store_disable_time, a.update_name operator_name, b.line_code, b.line_type, b.transport_type, IF(a.store_enable_time > b.enable_time, IF(a.store_enable_time > c.enable_time, a.store_enable_time, c.enable_time), IF(b.enable_time > c.enable_time, b.enable_time, c.enable_time)) as insect_start_time, IF(a.store_disable_time < b.disable_time, IF(a.store_disable_time < c.disable_time, a.store_disable_time, c.disable_time), IF(b.disable_time < c.disable_time, b.disable_time, c.disable_time)) as insect_end_time FROM (select * FROM line_store_goods WHERE yn = 1 and master_slave = 1) a join (select start_org_id, start_org_name, start_province_id, start_province_name, start_city_id, start_city_name, start_node_code, start_node_name, end_org_id, end_org_name, end_province_id, end_province_name, end_city_id, end_city_name, end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code, arrive_wave_code, line_code, line_type, transport_type, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource where line_code in (select line_code from line_store_goods WHERE yn = 1 ) and yn=1 group by line_code) b ON a.line_code = b.line_code and a.start_node_code = b.start_node_code join (select line_code,start_node_code, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource WHERE yn = 1 group by line_code) c ON a.parent_line_code = c.line_code and a.start_node_code = c.start_node_code) temp WHERE start_node_code = '311F001' and disable_time > '2023-11-15 00:00:00' and enable_time < disable_time) t_total;這是一段運行在生產上的復雜SQL案例,通過慢SQL指標統計識別出來。一眼看過去毫無頭緒(說明不僅性能差,而且可讀性差,那么必然可維護性差),非功能性指標總是存在很強的關聯性。
2.開始治理
step1.格式化
對工程人員而言:要重構,格式化很重要,保證一定的可讀性。
select count(*) total_count from (select * from (select a.line_store_goods_id as line_resource_id, a.group_num as group_num, a.approval_erp as approval_erp, a.approval_person as approval_person, a.approval_status as approval_status, a.approval_time as approval_time, a.approval_remark as approval_remark, a.master_slave as master_slave, a.parent_line_code as parent_line_code, a.remarks as remarks, a.operator_time, a.same_stowage as same_stowage, b.start_org_id, b.start_org_name, b.start_province_id, b.start_province_name, b.start_city_id, b.start_city_name, b.start_node_code, b.start_node_name, b.end_org_id, b.end_org_name, b.end_province_id, b.end_province_name, b.end_city_id, b.end_city_name, b.end_node_code, b.end_node_name, b.depart_time, b.arrive_time, b.depart_wave_code, b.arrive_wave_code, b.enable_time, b.disable_time, a.store_enable_time, a.store_disable_time, a.update_name operator_name, b.line_code, b.line_type, b.transport_type, IF(a.store_enable_time > b.enable_time, IF(a.store_enable_time > c.enable_time, a.store_enable_time, c.enable_time), IF(b.enable_time > c.enable_time, b.enable_time, c.enable_time)) as insect_start_time, IF(a.store_disable_time < b.disable_time, IF(a.store_disable_time < c.disable_time, a.store_disable_time, c.disable_time), IF(b.disable_time < c.disable_time, b.disable_time, c.disable_time)) as insect_end_time FROM (select * FROM line_store_goods WHERE yn = 1 and master_slave = 1) a join (select start_org_id, start_org_name, start_province_id, start_province_name, start_city_id, start_city_name, start_node_code, start_node_name, end_org_id, end_org_name, end_province_id, end_province_name, end_city_id, end_city_name, end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code, arrive_wave_code, line_code, line_type, transport_type, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource where line_code in (select line_code from line_store_goods WHERE yn = 1 ) and yn=1 group by line_code) b ON a.line_code = b.line_code and a.start_node_code = b.start_node_code join (select line_code,start_node_code, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource WHERE yn = 1 group by line_code) c ON a.parent_line_code = c.line_code and a.start_node_code = c.start_node_code) temp WHERE start_node_code = '311F001' and disable_time > '2023-11-15 00:00:00' and enable_time < disable_time) t_total;經過格式化之后,能簡單判斷出SQL的功能是檢索滿足某條件的線路數量統計。
注意:格式化作為一個重要的工具可以在任意階段發生作用。
step2.分層拆解
- level0
select count(*) total_count from t_total- level1 - t_total
select * from temp WHERE start_node_code = '311F001' and disable_time > '2023-11-15 00:00:00' and enable_time < disable_time- level2 - temp
select a.line_store_goods_id as line_resource_id, a.group_num as group_num, a.approval_erp as approval_erp, a.approval_person as approval_person, a.approval_status as approval_status, a.approval_time as approval_time, a.approval_remark as approval_remark, a.master_slave as master_slave, a.parent_line_code as parent_line_code, a.remarks as remarks, a.operator_time, a.same_stowage as same_stowage, b.start_org_id, b.start_org_name, b.start_province_id, b.start_province_name, b.start_city_id, b.start_city_name, b.start_node_code, b.start_node_name, b.end_org_id, b.end_org_name, b.end_province_id, b.end_province_name, b.end_city_id, b.end_city_name, b.end_node_code, b.end_node_name, b.depart_time, b.arrive_time, b.depart_wave_code, b.arrive_wave_code, b.enable_time, b.disable_time, a.store_enable_time, a.store_disable_time, a.update_name operator_name, b.line_code, b.line_type, b.transport_type, IF(a.store_enable_time > b.enable_time, IF(a.store_enable_time > c.enable_time, a.store_enable_time, c.enable_time), IF(b.enable_time > c.enable_time, b.enable_time, c.enable_time)) as insect_start_time, IF(a.store_disable_time < b.disable_time, IF(a.store_disable_time < c.disable_time, a.store_disable_time, c.disable_time), IF(b.disable_time < c.disable_time, b.disable_time, c.disable_time)) as insect_end_time FROM join_table- level3 - join_table
(select * FROM line_store_goods WHERE yn = 1 and master_slave = 1) a join (select start_org_id, start_org_name, start_province_id, start_province_name, start_city_id, start_city_name, start_node_code, start_node_name, end_org_id, end_org_name, end_province_id, end_province_name, end_city_id, end_city_name, end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code, arrive_wave_code, line_code, line_type, transport_type, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource where line_code in (select line_code from line_store_goods WHERE yn = 1 ) and yn=1 group by line_code) b ON a.line_code = b.line_code and a.start_node_code = b.start_node_code join (select line_code,start_node_code, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource WHERE yn = 1 group by line_code) c ON a.parent_line_code = c.line_code and a.start_node_code = c.start_node_code- level4 - a,b,c
select * FROM line_store_goods WHERE yn = 1 and master_slave = 1
select start_org_id, start_org_name, start_province_id, start_province_name, start_city_id, start_city_name, start_node_code, start_node_name, end_org_id, end_org_name, end_province_id, end_province_name, end_city_id, end_city_name, end_node_code, end_node_name, depart_time, arrive_time, depart_wave_code, arrive_wave_code, line_code, line_type, transport_type, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource where line_code in (select line_code from line_store_goods WHERE yn = 1 ) and yn=1 group by line_codeselect line_code,start_node_code, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource WHERE yn = 1 group by line_codestep3.重構
對于Java程序員而言,《重構 - 改善既有代碼的設計》一書應該不陌生。重構的核心在設計原則(“道”&“法”);但是工具包(“術”)同樣重要,指導具體落地。
工具包準備:
- 層級合并:減少臨時表個數
- 條件下推:減少檢索行數&臨時表大小
- join優化:減少檢索行數&臨時表大小
- 子查詢刪除:減少臨時表個數
- 子查詢與join的相互轉換:減少檢索行數
重構1 - 層級合并
- level0 & level1
如下兩個SQL執行效果一致,但是性能表現會有很大差異。
select count(*) total_count from (select * from temp where a = "1")select count(*) from temp where a = "1"第二種方式的性能表現會更好一些。原因如下:
1)減少查詢計算開銷:在第二種方式中,直接對表進行 count(*) 統計,不需要額外的子查詢和臨時表操作,可以減少計算的開銷。
2)減少內存占用:第一種方式需要在內存中創建一個臨時表來存儲子查詢的結果,而第二種方式直接對原表進行統計,不需要額外的內存占用。
3)減少磁盤 IO:第二種方式可以直接利用表的索引進行 count(*) 統計,而第一種方式可能需要額外的磁盤 IO 來處理子查詢和臨時表的操作。
因此,一般情況下,推薦使用第二種方式來進行 count()統計,以獲得更好的性能表現。當然,在實際情況中,也需要根據具體的業務場景和數據量來綜合考慮,有時候使用子查詢的方式也是必要的,但總體來說,直接對原表進行 count() 統計會更高效。
重構2 - 條件下推
start_node_code = '311F001' 直接下推至level4
SQL的執行是流程化的,從執行層視角看,涉及時空資源消耗最關鍵的有兩類:1-時間(行記錄掃描)、2-空間(臨時表)。
簡化來看,問題SQL的執行過程是子查詢形成臨時表,而后基于臨時表做各種形式的計算(過濾、聯合)。
通過條件下推,可以將過濾動作盡可能前置,減少后續過程臨時表的大小。
重構3 - join優化
按個人喜好進行格式化:
 圖片
圖片
條件下推:
 圖片
圖片
剝離冗余字段,冗余字段在SQL優化過程中是一個影響易讀性的干擾信息,剝離冗余字段給工程人員一個干凈的畫板來盡情施為。
 圖片
圖片
刪除無效條件。join的on條件中start_node_code條件因為條件下推已經不再是有效條件。注意,此處為了行文方便做了一定的簡化,理論上之前的剝離冗余字段理論上需要包含start_node_code字段查詢,在此步驟之后變為冗余字段后被剝離
 圖片
圖片
刪除無效子查詢。此時從上往下看,表a和表b存在一個奇怪的現象 - 使用了兩個類似功能(子查詢和join),兩者的功能完全一致。題外話:此案例作為反面教材真心不錯。涉及兩者的優劣決策,個人做取舍的兩個點是性能和可讀性。在此案例中功能實現場景特別簡單,join的可讀性明顯更好,在條件限定后掃描行數基本一致,但子查詢多一個臨時表;綜合考量會刪除子查詢。
 圖片
圖片
合并冗余join。繼續從上往下看,表b和表c看起來一模一樣。再次重復題外話:此案例作為反面教材真心不錯。
 圖片
圖片
等價條件替換,再次刪除冗余字段。
 圖片
圖片
經過優化后的join語句,可讀性發生了很大的變化 - 簡單的雙表關聯查詢。
 圖片
圖片
step4.結果的理論驗證
select count(*) from ( (select line_code FROM line_store_goods WHERE yn = 1 and parent_line_code = line_code and master_slave = 1 and start_node_code = '311F001') a join (select line_code, min(enable_time) as enable_time, max(disable_time) as disable_time from line_resource where yn=1 and start_node_code = '311F001' group by line_code) b ON a.line_code = b.line_code) where disable_time > '2023-11-15 00:00:00' and enable_time < disable_time重構后的SQL具備良好的可讀性,基于此很容易反推出SQL的業務功能。基于此與其理論應用場景做是否匹配的理論判斷很重要。有的時候生產上的SQL不一定是正確的,因為部分場景下可用性并不完全等價于正確性。
step5.索引優化
大量索引優化的文章可參考,此處不再贅述。
step6.結果的測試驗證
與代碼重構一樣,測試通過永遠是變更的正確性保證。較為特殊的是SQL改造后功能測試和性能測試都是必要的。
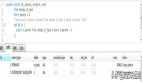
3.效果對比

三、寫在最后
重構的原則具備普適性,但是工具包每個人都有自己用得順手的一套,沒必要完全趨同。
另外,上面的技術能不用就不用,好的前置設計勝過事后的十八般武藝。