說說Redis主從的腦裂行為,你看懂了嗎?
作者:撿田螺的小男孩
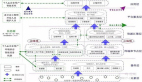
在 Redis 的主從架構中,如果主節點和從節點因網絡故障或其他原因失去聯系,哨兵開始選舉了新的主節點,而舊的主節點恢復過來繼續接受寫請求,也就是存在兩個redis主節點了,這就是redis的腦裂行為。
前言
大家好,我是田螺。
分享一道大廠面試真題:說說redis主從的腦裂?
我們可以按照這幾個維度來回答:
- 什么是腦裂行為
- 主從集群中為什么會發生腦裂?
- 腦裂為什么又會導致數據丟失呢?
- 我們該如何避免和應對腦裂的發生呢?
1. 什么是腦裂
什么是腦裂行為?
- 腦裂(Split-Brain)是指在分布式系統中,網絡分區導致多個節點之間失去聯系,形成了兩個或多個獨立的“腦”,每個腦都認為自己是主節點,導致數據寫入的沖突和不一致。
 圖片
圖片
- 在 Redis 的主從架構中,如果主節點和從節點因網絡故障或其他原因失去聯系,哨兵開始選舉了新的主節點,而舊的主節點恢復過來繼續接受寫請求,也就是存在兩個redis主節點了,這就是redis的腦裂行為。
2. 主從集群中為什么會發生腦裂?
腦裂行為在Redis主從集群中可能發生的原因,主要包括以下幾點:
 圖片
圖片
- 網絡故障:在網絡故障或不穩定的情況下,主節點與哨兵或從節點之間的通信可能會中斷。這時,哨兵可能會誤認為主節點已宕機。
- 哨兵的選舉機制:當哨兵無法與主節點通信時,會啟動選舉過程,從現有的從節點中選出一個新的主節點。如果此時網絡恢復,主節點仍在運行,就會導致出現兩個主節點。
- 假故障: 哨兵的故障轉移策略在網絡異常時會過于敏感,容易在錯誤的情況下進行主節點的選舉。也就是因為假故障導致又多選一個主節點出來。
3. 腦裂為什么又會導致數據丟失呢?
Redis的主從切換后,一旦從庫被提升為新的主庫,哨兵會指示原主庫去執行主從復制命令,以便與新主庫進行全量同步數據。最后在全量同步的階段的話,原主庫需要清除本地數據,加載來自新主庫的RDB文件(我們知道,redis主從同步是基于rdb文件的)。這就會導致在主從切換期間,原主庫接收的新寫數據會丟失啦。
還是上個簡單的圖,方便大家理解吧:
 圖片
圖片
上圖,大家可以發現:
- 當舊的主庫因為假死(假故障) 的原因,導致哨兵開始選舉新的主庫。在選舉新主庫期間,舊的主庫莫名奇妙又好了,它可以繼續接受寫入的請求了。
- 然后新主庫選好了,就有兩個主庫在同時處理寫請求啦。等到新主庫選好之后,舊的主庫就變成從庫了,它需要從新的主庫那里同步數據過來,這樣一來,在切換期間,舊主庫保存的數據就丟失啦。
4. 我們該如何避免/應對腦裂的發生呢?
為了避免腦裂的發生,我們嘗試這些方法:
 圖片
圖片
- 使用 Quorum 配置:確保哨兵數量為奇數,并設定適當的投票規則,以減少誤判的可能性。
- 合理設置超時參數:調整哨兵的 down-after-milliseconds 和 failover-timeout 參數,以適應實際網絡環境,減少誤判。
- 網絡隔離與監控:確保網絡穩定,監控網絡狀態和延遲,以便在問題出現時及時處理。
- 引入代理層:使用代理(如 Codis)來管理客戶端與 Redis 的連接,避免直接連接導致的腦裂。
還有個比較推薦的方式,那就是min-slaves-to-write 和 min-slaves-max-lag 這兩個參數,可以有效減少 Redis 腦裂的風險
- min-slaves-to-write:該參數設置在執行寫操作時,至少需要有多少個從節點在線并且處于同步狀態。如果在線的從節點數量低于此值,主節點將拒絕寫入請求,從而避免在不一致的情況下進行寫操作。
- min-slaves-max-lag:這個參數定義了允許的最大復制延遲(以秒為單位)。如果從節點的復制延遲超過此閾值,主節點將不會考慮這些從節點為有效,從而減少因落后節點引起的數據不一致問題。
責任編輯:武曉燕
來源:
撿田螺的小男孩