













終于把神經網絡中的正則化技術搞懂了!!
大家好,我是小寒
今天給大家分享神經網絡中常用的正則化技術。
神經網絡中的正則化技術是用于防止模型過擬合的一系列方法。
過擬合通常發生在模型在訓練數據上表現得很好,但在測試數據上表現不佳,這意味著模型在訓練過程中學習到了數據中的噪聲或細節,而非通用的模式。
神經網絡中常用的正則化技術包括
- 早停法
- L1 和 L2 正則化
- Dropout
- 數據增強
- 添加噪聲
- Batch Normalization
早停法
早停法是一種簡單但非常有效的正則化技術。
模型在訓練過程中會定期在驗證集上進行評估,如果驗證集上的損失開始增大(即驗證集的性能變差),則認為模型可能已經過擬合。
早停法會在驗證損失不再下降時停止訓練,以防止模型繼續在訓練集上過度擬合。

import tensorflow as tf
# Creating a simple neural network model
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activatinotallow='relu', input_shape=(100,)),
tf.keras.layers.Dense(32, activatinotallow='relu'),
tf.keras.layers.Dense(1, activatinotallow='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Using EarlyStopping callback
early_stopping = tf.keras.callbacks.EarlyStopping(
mnotallow='val_loss', # Monitoring validation loss
patience=5, # Number of epochs with no improvement to wait before stopping
restore_best_weights=True # Restores the weights of the best epoch
)
# Train the model with early stopping
model.fit(X_train, y_train, validation_split=0.2, epochs=100, callbacks=[early_stopping])L1 和 L2 正則化
L1正則化

import tensorflow as tf
from tensorflow.keras import regularizers
# Creating a simple neural network model with L1 regularization
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(100,),
kernel_regularizer=regularizers.l1(0.01)), # L1 Regularization
tf.keras.layers.Dense(32, activation='relu',
kernel_regularizer=regularizers.l1(0.01)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Summary of the model
model.summary()L2正則化
L2 正則化則在損失函數中加入權重平方和作為懲罰項,其公式為
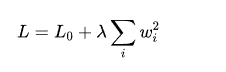
正則化通過懲罰大權重的參數,迫使權重的分布更加均勻,防止模型對訓練數據中的特定特征過于敏感。
它不會像L1那樣產生稀疏解,但可以有效控制模型的復雜度。
import tensorflow as tf
from tensorflow.keras import regularizers
# Creating a neural network model with L2 regularization
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(100,),
kernel_regularizer=regularizers.l2(0.01)), # L2 Regularization
tf.keras.layers.Dense(32, activation='relu',
kernel_regularizer=regularizers.l2(0.01)),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Summary of the model
model.summary()Dropout
Dropout 是一種非常流行的正則化方法,尤其在深度神經網絡中。
訓練過程中,Dropout 隨機地“關閉”一部分神經元及其連接,使得網絡在每次訓練迭代中只使用部分神經元進行前向傳播和反向傳播。
Dropout 可以防止神經元之間的共適應性,提高網絡的泛化能力。
 圖片
圖片
import tensorflow as tf
# Creating a neural network model with Dropout
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activatinotallow='relu', input_shape=(100,)),
tf.keras.layers.Dropout(0.5), # 50% Dropout
tf.keras.layers.Dense(64, activatinotallow='relu'),
tf.keras.layers.Dropout(0.5), # 50% Dropout
tf.keras.layers.Dense(10, activatinotallow='softmax')
])
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Summary of the model
model.summary()數據增強
數據增強是通過對訓練數據進行一些隨機變換(如旋轉、翻轉、縮放、裁剪等),人為地擴充數據集的規模,使模型能夠看到更多的“不同”的數據,從而減少過擬合。
這些變換不會改變數據的標簽,但會增加訓練數據的多樣性,迫使模型對不同的輸入具有更強的魯棒性。
 圖片
圖片
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Create an ImageDataGenerator with augmentation
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
# Example of applying the augmentation to an image
# Assuming 'images' is a numpy array of images
augmented_images = datagen.flow(images, batch_size=32)
# Use the augmented data for training
model.fit(augmented_images, epochs=10)添加噪聲
在訓練過程中,向輸入或隱藏層的神經元加入隨機噪聲,以增強模型的魯棒性。
例如,可以向輸入數據中加入高斯噪聲或其他分布的噪聲。
這樣模型可以在面對真實數據中的擾動或噪聲時表現得更好,從而提升泛化能力。
 圖片
圖片
Batch Normalization
批歸一化(Batch Normalization)也是一種廣泛使用的正則化技術,它的主要目的是解決訓練過程中的“內部協變量偏移”,即網絡的每一層輸入分布在訓練過程中不斷變化的問題。
BN 將每一批數據的輸入進行歸一化,使得輸入數據的均值為0,方差為1,然后再對其進行縮放和平移:































