













戰勝100多位NLP研究人員!楊笛一團隊最新百頁論文:首次統計學上證明,LLM生成的idea新穎性優于人類
大型語言模型(LLMs)在各個領域都是一個優秀的助手,廣大科研人員也對LLM在加速科學發現方面的潛力充滿期待,比如已經有研究提出了能夠自主生成和驗證新想法的研究智能體。
然而,至今還沒有評估結果能夠證明LLM系統能夠生成新穎的、達到專家水平的想法(idea),更不用說接手完成整個研究流程了。
為了填補這一空白,斯坦福大學的研究人員最近發布了耗時一年完成的新實驗,獲得了第一個具有統計學意義的結論:LLM生成的想法比人類專家撰寫的想法更新穎!

論文鏈接:https://arxiv.org/pdf/2409.04109
在論文中,研究人員設計了一個完整的實驗,可以評估模型在新研究思路生成方面的能力,同時對可能的干擾因素進行控制,首次將專家級的自然語言處理(NLP)研究人員與LLM創意代智能體進行直接比較。
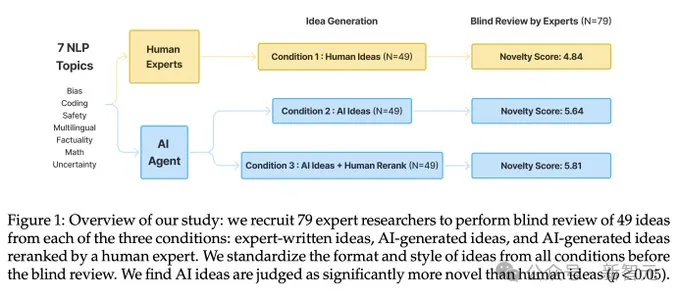
實驗招募了超過100名高水平NLP研究人員來撰寫新想法,然后對LLM生成的想法和人類想法進行盲審,參與者來自 36 個不同的機構,大部分是博士和博士后。
通過這種方式,研究人員首次得出「LLM在研究創意生成」能力的統計顯著結論:LLM生成的想法在新穎性方面優于人類專家的想法(p < 0.05),但在可行性方面略遜一籌。
在深入研究基線模型時,研究人員發現了構建和評估研究智能體中的一些開放性問題,包括LLM自我評估的不足以及在生成過程中缺乏多樣性。
在實驗過程中,研究人員意識到,即使是專家,對想法新穎性的判斷可能也非常困難,因此,文中提出了一個端到端的研究設計,招募研究人員將這些想法轉化為完整的項目。
問題設置
研究人員將科研想法評估(research idea evaluation)分為三個獨立的子部分,主要關注潛在的混雜因素,如研究領域、研究想法的格式和評估過程。
1. 想法本身,根據指令產生;
2. 傳達想法的書面報告(writeup);
3. 專家對書面報告的評估。
構想的范圍和指令(Ideation Scope and Instructions )
研究想法既可以是一個能夠提高模型性能的技巧,也可以是博士論文中描述的大規模研究計劃,任何關于構想的實驗都必須仔細平衡研究想法的「現實性」和「趣味性」。
受思維鏈等項目的啟發,一些簡單的提示思路就能大幅提升LLM的性能,還能夠在不復雜的計算硬件上執行,所以研究人員選擇「基于提示的自然語言處理」研究作為初步實驗領域。
在提示詞的編寫思路上,LLM更傾向于安全的主題,與人類的偏好不一致,所以研究人員為了統一目標,從最近的NLP會議的征稿頁面中提取了七個具體的研究主題,包括偏見(bias)、編碼(coding)、安全性(safety)、多語言性(multilingual)、事實性(factuality)、數學(math)和不確定性(uncertainty)。

想法書面報告(idea writeup)
一個想法只有在被寫出來后,其他人才能以此交流并評估,但寫作過程會引入其他混雜因素,例如人類研究者可能會用春秋筆法讓研究內容看起來更高大上,比如包括更多的例子和實現細節。
研究人員從資助申請中使用的指南中獲得靈感,編寫了一個模板來指定想法提案的結構和詳細程度,包括標題、問題陳述、動機、提出的方法、逐步實驗計劃、測試用例示例和備選計劃等字段。

不過,即使有了模板,可能仍然存在微妙的寫作風格差異,例如,人類可能傾向于以更具吸引力和非正式的語氣寫作。
為此,研究人員又開發了一個風格標準化提示,使用LLM將所有想法轉換為相同的寫作和格式化風格,而不改變原始內容。

評審和評估(review and evaluation)
對研究想法的評審往往是主觀的,研究人員的目標是設計一個明確定義所有評審標準的表格,以盡可能地將評審過程標準化和錨定評估。
研究人員在設計評審表格時,遵循了AI領域會議(如ACL和ICLR)評審的最佳實踐,定義了四個分解指標,包括新穎性(novelty)、興奮度(excitement)、可行性(feasibility)和預期效果(expected effectiveness)。
每個指標在評審時,都有一個1-10的數字評分,和一段文本作為理由。
盲審評估從三種不同條件下對想法進行對比:
1. 人類想法(human ideas):由招募的專家研究者撰寫的想法提案。
2. AI想法:由LLM智能體生成的想法提案,直接從智能體的輸出中獲取排名靠前的想法。
3. AI想法+人類重新排名:由LLM智能體生成的想法提案,再由人工手動從LLM智能體生成的所有想法中選擇了排名靠前的想法,以便更好地估計AI想法的上限質量。

想法生成智能體(idea generation agent)
論文檢索
為了使創意生成有據可依,智能體需要檢索與給定研究主題相關的論文,以便在生成新創意時能夠了解相關研究。
研究人員利用檢索增強生成(RAG),給定一個研究主題后,例如「能夠提高事實性并減少大型語言模型幻覺的新型提示方法」,首先提示一個LLM生成一系列對Semantic Scholar API的函數調用,然后使用claude-3-5-sonnet-20240620作為智能體的骨干模型,論文檢索的動作空間包括:{KeywordQuery(關鍵詞), PaperQuery(論文ID), GetReferences(論文ID)}。
然后根據一系列標準對檢索到的文獻進行評分和排序,包括文獻與主題的相關性、是否包含計算實驗的經驗性研究,以及文獻的創新性和啟發性,最多檢索120篇論文。
創意生成
研究人員的思路是,首先用LLM為每個研究主題生成4000個種子創意,創意生成提示包括示范示例和檢索到的論文;然后用排序器來從中選取出一小部分高質量的,為了從龐大的候選創意池中去除重復的創意,使用Sentence-Transformers中的all-MiniLM-L6-v2對所有種子創意進行編碼,然后計算成對的余弦相似度來進行一輪去重,最后得到大約5%非重復創意。
創意排名
為了對創意進行排名,研究人員利用了1200篇ICLR 2024會議中與大型語言模型相關的論文及其評審分數和接受決定的數據。
結果發現,當直接要求LLMs預測論文的最終分數或接受決定時,模型的預測準確性不高,但在成對比較中判斷哪篇論文更優秀時,卻能夠達到較高的準確性。
研究人員使用Claude-3.5-Sonnet模型作為自動排名器,在零樣本提示下,通過成對比較任務達到了71.4%的準確率,優于其他模型。
為了確保所有項目提案的排名可靠性,采用瑞士制比賽系統進行多輪評分;在驗證集上,發現排名前10的論文與排名后10的論文在平均評審分數上有明顯差異,證明了排序器的有效性;在實驗中,選擇了5輪作為評分標準。
此外,為了比較AI排序器與人類專家的差異,研究人員還設置了一個條件,即由人工手動對生成的項目提案進行重排,結果顯示兩種排名方法存在一定差異。




















