













ECCV 2024 | 機(jī)器遺忘之后,擴(kuò)散模型真正安全了嗎?
本文第一作者為密歇根州立大學(xué)計(jì)算機(jī)系博士生張益萌,賈景晗,兩人均為OPTML實(shí)驗(yàn)室成員,指導(dǎo)教師為劉思佳助理教授。OPtimization and Trustworthy Machine Learning (OPTML) 實(shí)驗(yàn)室的研究興趣涵蓋機(jī)器學(xué)習(xí)/深度學(xué)習(xí)、優(yōu)化、計(jì)算機(jī)視覺(jué)、安全、信號(hào)處理和數(shù)據(jù)科學(xué)領(lǐng)域,重點(diǎn)是開(kāi)發(fā)學(xué)習(xí)算法和理論,以及魯棒且可解釋的人工智能。
在人工智能領(lǐng)域,圖像生成技術(shù)一直是一個(gè)備受關(guān)注的話題。近年來(lái),擴(kuò)散模型(Diffusion Model)在生成逼真且復(fù)雜的圖像方面取得了令人矚目的進(jìn)展。然而,技術(shù)的發(fā)展也引發(fā)了潛在的安全隱患,比如生成有害內(nèi)容和侵犯數(shù)據(jù)版權(quán)。這不僅可能對(duì)用戶造成困擾,還可能涉及法律和倫理問(wèn)題。
盡管目前已有不少機(jī)器遺忘(Machine Unlearning, MU)方法 [1-3],希望讓擴(kuò)散模型在使用不適當(dāng)?shù)奈谋咎崾緯r(shí)避免生成不合時(shí)宜的圖片,但其有效性存疑。
只是我們好奇,經(jīng)過(guò)機(jī)器遺忘的擴(kuò)散模型,真的就一定安全了嗎?

為了應(yīng)對(duì)這一挑戰(zhàn),密歇根州立大學(xué) (Michigan State University) 和英特爾(Intel)的研究者們提出了一種高效且無(wú)需輔助模型的對(duì)抗性文本提示生成方法 UnlearnDiffAtk [4],并用優(yōu)化后得到的對(duì)抗性文本提示作為檢驗(yàn)遺忘后擴(kuò)散模型安全可靠性的工具,論文目前已被 ECCV 2024 接收。本文第一作者為密歇根州立大學(xué)計(jì)算機(jī)系博士生張益萌、賈景晗,兩人均為 OPTML 實(shí)驗(yàn)室成員,指導(dǎo)教師為劉思佳助理教授。

- 論文題目:To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy to Generate Unsafe Images ... For Now
- 論文地址:https://arxiv.org/abs/2310.11868
- 代碼地址:https://github.com/OPTML-Group/Diffusion-MU-Attack
- Unlearned Diffusion Model Benchmark: https://huggingface.co/spaces/Intel/UnlearnDiffAtk-Benchmark
Unlearned DM 可以從兩個(gè)角度評(píng)估模型:
- 安全可靠性:通過(guò)對(duì)抗性文本提示攻擊 (UnlearnDiffAtk) 來(lái)進(jìn)行評(píng)估;
- 圖片生成能力:通過(guò)一萬(wàn)張生成圖片平均 FID(Fréchet inception distance)和 CLIP score 進(jìn)行評(píng)估。

文章與代碼均已開(kāi)源,研究團(tuán)隊(duì)還在積極收納更多的方法到 Unlearned DM Benchmark。如有意向,歡迎郵件聯(lián)系作者(zhan1853@msu.edu)溝通模型測(cè)評(píng)相關(guān)事宜。
UnlearnDiffAtk 方法有什么獨(dú)特之處?
UnlearnDiffAtk 的目標(biāo)是通過(guò)尋找離散的對(duì)抗性文本來(lái)進(jìn)行攻擊,而與之不同的是,CCE [5] 側(cè)重于尋找連續(xù)的文本嵌入進(jìn)行攻擊。
然而,CCE 并不是一個(gè)理想的評(píng)估方式,因?yàn)槲谋痉崔D(zhuǎn) [6] 的初衷是通過(guò)優(yōu)化生成 “新” 的詞元(token),從而使擴(kuò)散模型能夠生成未見(jiàn)過(guò)的事物或風(fēng)格。
因此,即使擴(kuò)散模型已經(jīng)遺忘了某些特定內(nèi)容,仍然可以通過(guò)優(yōu)化生成新的詞元來(lái)使模型生成相應(yīng)的事物。而 UnlearnDiffAtk 與其他對(duì)抗式文本生成方法不同,UnlearnDiffAtk 無(wú)需依靠輔助模型或未經(jīng)機(jī)器遺忘的原模型提供優(yōu)化指導(dǎo)。它利用擴(kuò)散模型內(nèi)在的分類器辨別能力 [7],來(lái)指導(dǎo)對(duì)抗性文本的生成,使得攻擊更具可操作性。
優(yōu)化過(guò)程中僅需一張目標(biāo)圖片(Target Image, )提供指導(dǎo),大大降低了對(duì)硬件的要求并提高了攻擊效率。需要注意的是,目標(biāo)圖片不必與原有的不適當(dāng)文本提示描述完全吻合,僅需包含攻擊后期望得到的有害內(nèi)容即可。例如,若 UnlearnDiffAtk 希望強(qiáng)迫遺忘后的模型生成包含裸體的圖片,那么目標(biāo)圖片只需是網(wǎng)絡(luò)上的任何一張裸體照片即可。
)提供指導(dǎo),大大降低了對(duì)硬件的要求并提高了攻擊效率。需要注意的是,目標(biāo)圖片不必與原有的不適當(dāng)文本提示描述完全吻合,僅需包含攻擊后期望得到的有害內(nèi)容即可。例如,若 UnlearnDiffAtk 希望強(qiáng)迫遺忘后的模型生成包含裸體的圖片,那么目標(biāo)圖片只需是網(wǎng)絡(luò)上的任何一張裸體照片即可。
具體來(lái)說(shuō),根據(jù) Diffusion Classifier [7] 的概念,預(yù)測(cè)輸入圖片 x 為標(biāo)簽 c 的概率變?yōu)槿缦拢?/span>
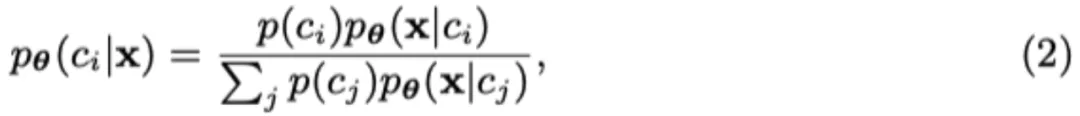
而在擴(kuò)散模型中, 的對(duì)數(shù)似然去噪誤差相關(guān),則可以得到:
的對(duì)數(shù)似然去噪誤差相關(guān),則可以得到:

通過(guò)擴(kuò)散分類器 (3) 的視角,創(chuàng)建對(duì)抗性提示詞 c’ 以規(guī)避目標(biāo)遺忘后擴(kuò)散模型的任務(wù)可以表述為:

然而分類只需要噪聲誤差之間的相對(duì)差異,不需要它們的絕對(duì)大小,所以公式(3)可以變形為

然后我們可以將攻擊生成問(wèn)題 (4) 變?yōu)?/span>

為了便于優(yōu)化,我們通過(guò)利用 exp (?) 的凸性來(lái)簡(jiǎn)化公式 (6)。使用 Jensen 不等式,對(duì)于凸函數(shù),公式 (6) 中的單個(gè)目標(biāo)函數(shù)(針對(duì)特定的 j)的上界為:

由于第二項(xiàng)與優(yōu)化變量 c’無(wú)關(guān),通過(guò)將公式 (7) 納入公式 (6) 并排除與 c’無(wú)關(guān)的項(xiàng),我們得到以下簡(jiǎn)化的攻擊生成優(yōu)化問(wèn)題:

任務(wù)類型
擴(kuò)散模型的機(jī)器遺忘任務(wù)可分為三大類,而 UnlearnDiffAtk 在這三類任務(wù)中均展現(xiàn)了較強(qiáng)的攻擊成功率:
- 有害內(nèi)容 (如:裸體,暴力,違法行為)
- 藝術(shù)風(fēng)格
- 物體

本文不僅深入了解了擴(kuò)散模型在生成安全性方面的挑戰(zhàn),還提出了有效的解決方案。希望這項(xiàng)研究能引起更多對(duì)圖像生成技術(shù)安全性的關(guān)注,并推動(dòng)相關(guān)技術(shù)的進(jìn)一步發(fā)展。
實(shí)驗(yàn)結(jié)果與可視化
下述表格和可視化結(jié)果分別展示了在遺忘有害內(nèi)容、遺忘藝術(shù)風(fēng)格以及遺忘物體這三類任務(wù)中的表現(xiàn)。通過(guò)這些結(jié)果可以看出,即使在沒(méi)有額外輔助模型提供優(yōu)化指導(dǎo)的情況下,僅僅依靠擴(kuò)散模型自身攜帶的分類器特性,UnlearnDiffAtk 依然表現(xiàn)出與同期工作 P4D 相當(dāng)甚至更高的攻擊成功率。此外,由于無(wú)需依賴額外的模型輔助,UnlearnDiffAtk 能夠顯著提高攻擊速度,平均節(jié)省約 30% 的攻擊時(shí)間。
































