MySQL億級數據平滑遷移實戰

一、背景
預約業務是 vivo 游戲中心的重要業務之一。由于歷史原因,預約業務數據表與其他業務數據表存儲在同一個數據庫中。當其他業務出現慢 SQL 等異常情況時,可能會直接影響到預約業務,從而降低系統整體的可靠性和穩定性。為了盡可能提高系統的穩定性和數據隔離性,我們迫切需要將預約相關數據表從原來的數據庫中遷移出來,單獨建立一個預約業務的數據庫。
二、方案選型
常見的遷移方案大致可以分為以下幾類:

而預約業務有以下特點:
- 讀寫場景多,頻率高,在用戶預約/取消預約/福利發放等場景均涉及到大量的讀寫。
- 不可接受停機,停機不可避免的會造成經濟損失,在有其他方案的情況下不適合選擇此方案。
- 大部分的場景能接受秒級的數據不一致,少部分不能。
結合這些特點,我們再評估下上面的方案:

停機遷移方案需要停機,不適用于預約場景。預約場景存在不活躍的用戶數據,如果用漸進式遷移方案的話很難遷移干凈,可能還需要再寫一個遷移任務來輔助完成遷移。而雙寫方案最大的優勢在于每一步操作都可向上回滾,能盡可能的保證業務不出問題。
因此,最終選擇的是雙寫方案。預約業務涉及到的讀寫場景多,每一個場景單獨進行改造的成本大,采用 Mybatis 插件來實現遷移所需的雙寫等功能,可以有效降低改造成本。
三、前期準備
3.1 全量同步&增量同步&一致性校驗
這幾步使用了公司提供的數據同步工具。全量同步基于 MySQLDump 實現;增量同步基于 binlog 實現;一致性校驗通過在新老庫各選一個分塊,然后聚合列數據計算并對比其特征值實現。
3.2 代碼改造
引入了新庫,那自然就需要在項目里新建數據源,并創建表對應的 Mybatis Mapper 類。這里有一個小細節需要注意,Mybatis 默認的 BeanNameGenerator 是
AnnotationBeanNameGenerator,它會使用類名作為 BeanName 注冊到 Spring 的 ioc 容器中,Spring 啟動時如果發現有了兩個重名 Bean 就會啟動失敗,筆者這里給 Mybatis 設置了一個新的 BeanNameGenerator ,使用類的全路徑名作為 BeanName 解決了問題。
public class FullPathBeanNameGenerator implements BeanNameGenerator {
@Override
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {
return definition.getBeanClassName();
}
}還有一點是主鍵 id,本次預約遷移需要保證新老庫主鍵 id 一致,預約業務沒做分庫分表,id 都是直接用 MySQL 的自增 id,沒有用 id 生成器之類的中間件。因此插入新表時只需要使用插入老表后 Mybatis 自動設置好的 id 即可,這次遷移前先檢查了一遍業務代碼,確保插入語句都用了 Mybatis 的 useGeneratedKeys 功能來自動設置 id。
3.3 插件實現
Mybatis 插件可以攔截 SQL 語句執行過程中的某一點進行干預和處理,而 Executor 是 Mybatis 中負責執行 SQL 語句的核心組件。我們可以對 Executor 的 update 和 query 方法進行代理以實現遷移所需的功能。
插件需要為讀寫場景分別實現以下功能:

考慮到開關切換部分的代碼邏輯較為簡單,因此在下文中,筆者將不再過多介紹該部分的具體實現,而是著重介紹如何在插件中使用老庫的執行語句來訪問新的數據庫。此外,代碼里會涉及到 Mybatis 相關的一些概念,由于網上已經有較多詳盡的資料,這里就不再贅述。
遷移插件代理了 Executor 的 query 和 update 方法,首先在插件里獲取到當前執行的 SQL 語句所在的 Mapper 路徑。
@Intercepts(
{
@Signature(type = Executor.class, method = "update", args = {MappedStatement.class, Object.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}),
}
)
public class AppointMigrateInterceptor implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
Object[] args = invocation.getArgs();
// Mybatis插件代理的Executor的update或者query方法,第一個參數就是MappedStatement
MappedStatement ms = (MappedStatement) args[0];
SqlCommandType sqlCommandType = ms.getSqlCommandType();
String id = ms.getId();
// 從MappedStatement id中獲取對應的Mapper接口文件全路徑
String sourceMapper = id.substring(0, id.lastIndexOf("."));
// ...
}
// ...
}得到老庫 Mapper 路徑后,將其轉換為新庫 Mapper 路徑,再使用 Class.forName 獲取到新庫 Mapper 類,然后用新庫的 sqlSessionFactory 開啟 sqlSession,再獲取反射調用所需的方法、對象、參數,在新庫上執行語句。
protected Object invoke(Invocation invocation, TableConfiguration tableConfiguration) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
// 獲取 MappedStatement
MappedStatement ms = (MappedStatement) invocation.getArgs()[0];
// 獲取 Mybatis 封裝好的入參,封裝函數 MapperMethod.convertArgsToSqlCommandParam(Object[] args)
Object parameter = invocation.getArgs()[1];
// 使用 Class.forName 獲取到的新庫 Mapper
Class<?> targetMapperClass = tableConfiguration.getTargetMapperClazz();
// 使用新庫的 sqlSessionFactory 創建 sqlSession
SqlSession sqlSession = sqlSessionFactory.openSession();
Object result = null;
try{
// 使用新庫的 Mapper 路徑獲取對應的 MapperProxy 對象
Object mapper = sqlSession.getMapper(targetMapperClass);
// 將 Mybatis 封裝好的參數轉換為原始參數
Object[] paramValues = getParamValue(parameter);
// 使用 mappedStatement Id 從新庫對應的 Mapper 里獲取對應的方法
Method method = getMethod(ms.getId(), targetMapperClass, paramValues);
paramValues = fixNullParam(method, paramValues);
// 反射調用新庫 Mapper 的方法,本質上執行的是 MapperProxy.invoke
result = method.invoke(mapper, paramValues);
} finally {
sqlSession.close();
}
return result;
}
private Object[] fixNullParam(Method method, Object[] paramValues) {
if (method.getParameterTypes().length > 0 && paramValues.length == 0) {
return new Object[]{null};
}
return paramValues;
}上述代碼里,getMethod 方法負責從新庫 Mapper 類里找到對應的方法,以用于后續的反射調用。
private Method getMethod(String id, Class mapperClass) throws NoSuchMethodException {
//獲取參數對應的 class
String methodName = id.substring(id.lastIndexOf(".") + 1);
String key = id;
// methodCache 用來緩存 MappedStatement 和對應的 Method,避免每次都從 Mapper 里查找
Method method = methodCache.get(key);
if (method == null){
method = findMethodByMethodSignature(mapperClass, methodName);
if (method == null){
throw new NoSuchMethodException("No such method " + methodName + " in class " + mapperClass.getName());
}
methodCache.put(key,method);
}
return method;
}
private Method findMethodByMethodSignature(Class mapperClass,String methodName) throws NoSuchMethodException {
// mybatis 的 Mapper 內的方法不支持重載,所以這里只要方法名匹配到了就行,不用進行參數的匹配
Method method = null;
for (Method m : mapperClass.getMethods()) {
if (m.getName().equals(methodName)) {
method = m;
break;
}
}
return method;
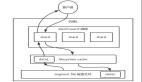
}得到方法后,還需要得到反射調用所需的參數。Mybatis 執行到 Executor.update/query 方法時,參數已經經過 MapperMethod.convertArgsToSqlCommandParam(Object[] args) 方法封裝,不能直接用來執行 MapperProxy.invoke ,需要轉換后才可用。下圖是MapperMethod.convertArgsToSqlCommandParam(Object[] args) 的封裝過程,而下面的 getParamValue 是這個函數的逆過程。

private Object[] getParamValue(Object parameter) {
List<Object> paramValues = new ArrayList<>();
if (parameter instanceof Map) {
Map<String, Object> paramMap = (Map<String, Object>) parameter;
if (paramMap.containsKey("collection")) {
paramValues.add(paramMap.get("collection"));
} else if (paramMap.containsKey("array")) {
paramValues.add(paramMap.get("array"));
} else {
int count = 1;
while (count <= paramMap.size() / 2){
try {
paramValues.add(paramMap.get("param"+(count++)));
}catch (BindingException e){
break;
}
}
}
} else if (parameter != null){
paramValues.add(parameter);
}
return paramValues.toArray();
}通過上述流程,我們就能使用 Mybatis 插件攔截老庫的執行過程,實現遷移所需的讀寫數據源切換/新老庫查詢結果對比/先寫老庫再異步寫新庫等功能。
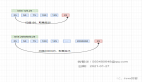
四、雙寫流程
4.1 上線雙寫改造后的業務代碼,上線時只讀寫老庫
- 讀開關:只讀老庫
- 寫開關:只寫老庫
- 新老庫查詢結果對比開關:關
此時業務仍只讀寫老庫。
4.2 使用公司中間件平臺提供的數據工具同步老庫數據到新庫
- 讀開關:只讀老庫
- 寫開關:只寫老庫
- 新老庫查詢結果對比開關:關
第1步和第2步并沒有嚴格的順序要求,只要在切換為雙寫前做完第1步和第2步就好。
條件允許的情況下,全量+增量同步時應選擇不對外提供服務的離線從庫作為數據源,避免主從延遲等問題對線上業務造成影響。
4.3 停止同步程序,然后開啟雙寫
- 讀開關:只讀老庫(開啟查詢結果對比開關)
- 寫開關:雙寫
- 新老庫查詢結果對比開關:開
老庫追上新庫后,對數據做一次全量校驗,避免出現數據不一致的情況。此外還需要開啟新老庫查詢結果對比開關,通過日志監控觀察新老庫的查詢結果是否一致。
停止數據同步和切換雙寫之間必然有時間差,如果先開啟雙寫再停止數據同步,則可能出現插入重復數據或數據被覆蓋的情況。因此需要對數據同步工具和遷移插件進行改造,以處理數據異常的情況,但是這樣改造需要處理的情況較多,改造成本較高。所以這里選擇先停止同步,再切換到雙寫,中間丟失的數據使用對比&補償任務恢復,由于此時仍然全量讀老庫,所以對業務不會有影響。需要注意的是,雙寫階段的時間不應太長,只要確保新老庫數據一致就應該前進到下一步。
這一步在實際操作過程中需要注意以下情況:
4.3.1 自增主鍵
預約業務新庫的主鍵 id 需要和老庫保持一致,因此在遷移前檢查了一遍業務代碼,確保插入語句都用了 Mybatis 的 useGeneratedKeys 功能來返回 id ,這樣插入新庫時可以直接用設置好 id 的對象。但是這里有一個問題,批量插入時 Mybatis 自動設置的 id 和數據庫生成的自增主鍵不一定完全一致,比如批量 insert ignore 和 on duplicate key update 語句。
這個問題和 useGeneratedKeys 的實現有關,代碼可參考
com.mysql.jdbc.StatementImpl#getGeneratedKeysInternal(long) 函數,以下是其執行邏輯:
- Mybatis 執行完插入語句后,MySQL 會返回這次插入影響的數據行數,注意,使用 insert ignore 插入時,忽略的那部分數據不會加到影響的行數上。
- Mybatis 使用 SELECT LAST_INSERT_ID() 查詢這次插入的最小 id 。
- Mybatis 循環遍歷插入時用的對象列表,循環的最大次數為第1步里獲取的這次插入影響的行數,使用 n 代表當前的循環次數,列表中的每個對象的 id 被賦值為 LAST_INSERT_ID() + n*AUTO_INCREMENT 。
舉例來說,假設老庫的某張表里有數據 b ,其 id=1,此時往該表使用 insert ignore 批量插入三條數據 a,b,c,其在表內的 id 為 a:2、b:1、c:3,返回的影響行數為2,SELECT LAST_INSERT_ID() 返回的是2,因此 Mybatis 往對象里設置的主鍵分別為 a:2、b:3、c:null,再使用這個設置好 id 的對象列表插入新庫時會導致新老庫 id 不一致。
解決方案:由于直接刪除 ignore 會改變這條 SQL 的語義,無法通過修改語句來解決問題。所以我們只能在遷移插件里跳過這條語句,使其固定寫入老庫。然后在業務層單獨對其進行遷移改造,將插入新庫的流程修改為先使用 id 以外的唯一鍵查詢一次老庫的數據,獲取到 id 以后設置到對象列表里,再插入新庫。
4.3.2 事務
預約業務有部分邏輯用到了事務,但這部分邏輯在雙寫期間均可以暫停功能,因此遷移插件沒有實現事務的支持。如果需要支持業務的話可以不依賴插件,在業務層單獨對那部分代碼進行改造。
4.3.3 異步寫入新庫引起的問題
雙寫過程中是異步寫新庫,需要重點關注是否會有線程安全問題。舉例來說,假設有個業務需要往表里插入一個列表,插入完列表后又對列表進行了修改,比如執行了 List.clear() 函數或者其中的對象發生了變更,由于是異步寫新庫,所以實際的執行流程可能如下:
- 老庫 insert(list)
- list.clear()
- 新庫 insert(list)
這會導致新庫執行操作時,傳入的對象和老庫執行操作時不一樣,導致新老庫數據不一致。建議在遷移前人為的確認業務邏輯,避免異步寫入導致新老庫數據不一致。
4.4 開啟對比和補償程序,補償切換開關的過程中遺失的數據
- 讀開關:只讀老庫(對比開關開啟)
- 寫開關:雙寫
- 新老庫查詢結果對比開關:開
- 對比&補償任務:開啟

該對比&補償任務有一個缺陷,其不能處理數據被刪除的情況,如果老庫里的數據被刪除但是新庫的數據刪除失敗,那使用更新時間區間就無法從老庫查出這條數據,自然也無法進行對比&補償。
雙寫期間,如果出現刪老庫成功但是刪新庫失敗的情況會有日志告警,所以不會有問題。但是停止數據同步工具 → 開啟雙寫開關這一過程中刪除的數據無法補償。不過大部分業務用的都是邏輯刪除,只有一處用了物理刪除,筆者在這一處添加了日志,如果切換過程中出現刪除數據的日志,就需要手動進行補償操作。實際操作過程中,開關的切換的耗時較短,只花了30秒左右,在這過程中沒有打印刪除數據的日志。
4.5 逐步切量請求到新庫上
- 讀開關:部分讀新庫 → 只讀新庫
- 寫開關:雙寫
- 新老庫查詢結果對比開關:開
- 對比&補償任務:開啟
雙寫時,由于數據先寫入老庫再異步寫入新庫,因此新庫的數據肯定會滯后于老庫。如果將一部分讀流量切換到新庫上,就可能會在一些對延遲要求較高的業務場景中出現問題。對于這種場景,我們不能采用逐步切量的策略,只能同時切換讀寫開關,將其修改為只寫老庫+只讀新庫。
4.6 停止對比補償程序,關閉雙寫,讀寫都切換到新庫,開啟反向補償任務
- 讀開關:只讀新庫
- 寫開關:只寫新庫
- 新老庫查詢結果對比開關:關
- 對比&補償任務:開啟反向補償
反向補償是從新庫補償數據到老庫,由于該任務是定時執行,開啟后,新庫和老庫的數據會有 1~2 分鐘的延遲,萬一寫新庫的邏輯有問題,可以切回老庫。至于為什么用反向補償任務而不是使用先寫新庫再異步寫老庫的策略,是因為雙寫是用 MyBatis 插件實現的,插件代理的是 excutor 的 update 和 query 方法,如果異步寫入老庫,有可能會發生以下情況:
- 假設有兩個線程,業務線程 A 需要寫入一條數據,遷移插件攔截后,先同步寫入新庫,寫完新庫后提交任務給線程 B 中異步寫入老庫,提交完任務后插件立刻返回。
- 由于插件已返回結果,executor 上層的 sqlsession 調用 close() 方法關閉 executor (見 org.mybatis.spring.SqlSessionTemplate.SqlSessionInterceptor#invoke ),此時線程 B 可能還沒執行完寫老庫的操作。
- 線程 B 執行過程中,由于 executor 已經關閉,導致其寫老庫失敗。
因此無法使用 Mybatis 插件來實現異步寫老庫。
4.7 停止反向補償任務,刪除表遷移相關代碼
停止反向補償前,需要關注是否還有業務在讀老庫。觀察一段時間,確認老庫沒有補償任務以外的讀寫流量后,可以關閉補償任務,清理遷移過程中產生的代碼,清理老庫數據。
五、總結
在進行數據表遷移的過程中,雖然遇到了一些問題,但是制定的方案中每一步都有回退措施,即使出現問題也不會影響業務的正常運行。此外,筆者在遷移過程中對各種異常情況進行了監控,能及時發現并解決問題。如果其他業務需要進行類似的遷移,需要關注以下幾個方面:
- 遷移插件實現:在對遷移過程進行反思后,筆者人為通過代理或重寫 MapperProxy 的方式來實現遷移插件可能是更加合理的方案。這種方案有兩個優點:一方面,可以避免處理 Mybatis 復雜的參數轉換流程,從而減少潛在的錯誤和異常;另一方面,可以實現先寫新庫再異步寫老庫的操作。但是這個方案沒有經過實踐,還不能確定是否有可行性。
- 自增主鍵:需要確定業務是否需要保證新老庫的 id 一致。
- 事務:雙寫過程中應該結合業務考慮是否需要實現事務支持。本次遷移過程中,我們暫停了部分需要事務支持的業務。
- 異步寫入:先寫老庫再異步寫入新庫的方式可能導致新老庫數據不一致,遷移插件自身無法解決這個問題,只能人工提前排查可能存在的隱患。