













一直爆料OpenAI「草莓」的賬號(hào),竟然是個(gè)智能體?斯坦福系創(chuàng)企「炒作」AgentQ
最近,OpenAI 的秘密項(xiàng)目「Q*」一直受到了圈內(nèi)人士的廣泛關(guān)注。上個(gè)月,以它為前身、代號(hào)為「草莓(Strawberry)」的項(xiàng)目又被曝光了。據(jù)推測(cè),該項(xiàng)目能夠提供高級(jí)推理能力。
最近幾天,關(guān)于這個(gè)項(xiàng)目,網(wǎng)絡(luò)上又來(lái)了幾波「鴿死人不償命」的傳播。尤其是一個(gè)「草莓哥」的賬號(hào),不間斷地宣傳,給人期望又讓人失望。
沒(méi)想到,這個(gè) Sam Altman 出現(xiàn)在哪里,它就在哪里跟帖的「營(yíng)銷(xiāo)號(hào)」,皮下竟然是個(gè)智能體?
今天,一家 AI 智能體初創(chuàng)公司「MultiOn」的創(chuàng)始人直接出來(lái)認(rèn)領(lǐng):雖然沒(méi)等來(lái) OpenAI 發(fā)布「Q*」,但我們發(fā)了操控「草莓哥」賬號(hào)的全新智能體 Agent Q,快來(lái)和我們?cè)诰€玩耍吧!
MultiOn 聯(lián)合創(chuàng)始人兼 CEO Div Garg,他在斯坦福讀計(jì)算機(jī)科學(xué)博士期間休學(xué)創(chuàng)業(yè)。
這波看起來(lái)讓 OpenAI 給自己做嫁衣的營(yíng)銷(xiāo)操作給大家都看懵了。畢竟,最近很多人徹夜未眠等待 OpenAI 的「大新聞」。這要追溯到 Sam Altman 和「草莓哥」的互動(dòng),在 Sam Altman 曬出的草莓照片下,他回復(fù)了「草莓哥」:驚喜馬上就來(lái)。

不過(guò),「MultiOn」的創(chuàng)始人 Div Garg 已經(jīng)把認(rèn)領(lǐng) Agent Q 就是「草莓哥」的帖子悄悄刪了。
此次,「MultiOn」宣稱,他們發(fā)布的 Agent Q 是一款突破性的 AI 智能體。它的訓(xùn)練方法結(jié)合了蒙特卡洛樹(shù)搜索(MCTS)和自我批評(píng),并且通過(guò)一種叫做直接偏好優(yōu)化(DPO)的算法來(lái)學(xué)習(xí)人類的反饋。
與此同時(shí),作為擁有規(guī)劃和 AI 自我修復(fù)功能的下一代 AI 智能體,Agent Q 的性能是 LLama 3 基線零樣本性能的 3.4 倍。同時(shí),在真實(shí)場(chǎng)景任務(wù)的評(píng)估中,Agent Q 的成功率達(dá)到了 95.4%。
Agent Q 能做什么呢?我們先來(lái)看一下官方 Demo。
它能夠?yàn)槟泐A(yù)定某個(gè)時(shí)間某家餐廳的座位。

然后為你執(zhí)行網(wǎng)頁(yè)操作,比如查詢空位情況。最終成功預(yù)定。

此外還能預(yù)定航班(比如本周六從紐約飛往舊金山,單程、靠窗和經(jīng)濟(jì)艙)。
不過(guò),網(wǎng)友似乎對(duì) Agent Q 并不買(mǎi)賬。大家關(guān)心更多的還是他們是否真的借「草莓哥」賬號(hào)炒作的事情,甚至有些人稱他們?yōu)闊o(wú)恥的騙子。

重要組件和方法概覽
目前,Agent Q 的相關(guān)論文已經(jīng)放出,由 MultiOn 和斯坦福大學(xué)的研究者聯(lián)合撰寫(xiě)。這項(xiàng)研究的成果將在今年晚些時(shí)候向開(kāi)發(fā)人員和使用 MultiOn 的普通用戶開(kāi)放。

- 論文地址:https://multion-research.s3.us-east-2.amazonaws.com/AgentQ.pdf
總結(jié)一波:Agent Q 能夠自主地在網(wǎng)頁(yè)上實(shí)施規(guī)劃并自我糾錯(cuò),從成功和失敗的經(jīng)驗(yàn)中學(xué)習(xí),提高它在復(fù)雜任務(wù)中的表現(xiàn)。最終,該智能體可以更好地規(guī)劃如何在互聯(lián)網(wǎng)上沖浪,以適應(yīng)現(xiàn)實(shí)世界的復(fù)雜情況。
在技術(shù)細(xì)節(jié)上, Agent Q 的主要組件包括如下:
使用 MCTS(Monte Carlo Tree Search,蒙特卡洛樹(shù)搜索)進(jìn)行引導(dǎo)式搜索:該技術(shù)通過(guò)探索不同的操作和網(wǎng)頁(yè)來(lái)自主生成數(shù)據(jù),以平衡探索和利用。MCTS 使用高采樣溫度和多樣化提示來(lái)擴(kuò)展操作空間,確保多樣化和最佳的軌跡集合。
AI 自我批評(píng):在每個(gè)步驟中,基于 AI 的自我批評(píng)都會(huì)提供有價(jià)值的反饋,從而完善智能體的決策過(guò)程。這一步驟級(jí)反饋對(duì)于長(zhǎng)期任務(wù)至關(guān)重要,因?yàn)橄∈栊盘?hào)通常會(huì)導(dǎo)致學(xué)習(xí)困難。
直接偏好優(yōu)化(DPO):該算法通過(guò)從 MCTS 生成的數(shù)據(jù)構(gòu)建偏好對(duì)以微調(diào)模型。這種離策略訓(xùn)練方法允許模型從聚合數(shù)據(jù)集(包括搜索過(guò)程中探索的次優(yōu)分支)中有效地學(xué)習(xí),從而提高復(fù)雜環(huán)境中的成功率。
下面重點(diǎn)講一下網(wǎng)頁(yè)(Web-Page)端的 MCTS 算法。研究者探索了如何通過(guò) MCTS 賦予智能體額外的搜索能力。
在以往的工作中,MCTS 算法通常由四個(gè)階段組成:選擇、擴(kuò)展、模擬和反向傳播,每個(gè)階段在平衡探索與利用、迭代細(xì)化策略方面都發(fā)揮著關(guān)鍵作用。
研究者將網(wǎng)頁(yè)智能體執(zhí)行公式化為網(wǎng)頁(yè)樹(shù)搜索,其中狀態(tài)由智能體歷史和當(dāng)前網(wǎng)頁(yè)的 DOM 樹(shù)組成。與國(guó)際象棋或圍棋等棋盤(pán)游戲不同,研究者使用的復(fù)雜網(wǎng)絡(luò)智能體操作空間是開(kāi)放格式且可變的。
研究者將基礎(chǔ)模型用作操作建議(action-proposal)分布,并在每個(gè)節(jié)點(diǎn)(網(wǎng)頁(yè))上采樣固定數(shù)量的可能操作。一旦在瀏覽器中選擇并執(zhí)行一個(gè)操作,則會(huì)遍歷下個(gè)網(wǎng)頁(yè),并且該網(wǎng)頁(yè)與更新的歷史記錄共同成為新節(jié)點(diǎn)。
研究者對(duì)反饋模型進(jìn)行多次迭代查詢,每次從列表中刪除從上一次迭代中選擇的最佳操作,直到對(duì)所有操作進(jìn)行完整排序。下圖 4 為完整的 AI 反饋過(guò)程。

擴(kuò)展和回溯。研究者在瀏覽器環(huán)境中選擇并執(zhí)行一個(gè)操作以到達(dá)一個(gè)新節(jié)點(diǎn)(頁(yè)面)。從選定的狀態(tài)節(jié)點(diǎn)軌跡開(kāi)始,他們使用當(dāng)前策略 ??_?? 展開(kāi)軌跡,直到到達(dá)終止?fàn)顟B(tài)。環(huán)境在軌跡結(jié)束時(shí)返回獎(jiǎng)勵(lì) ??,其中如果智能體成功則 ?? = 1,否則 ?? = 0。接下來(lái),通過(guò)從葉節(jié)點(diǎn)到根節(jié)點(diǎn)自下而上地更新每個(gè)節(jié)點(diǎn)的值來(lái)反向傳播此獎(jiǎng)勵(lì),如下所示:
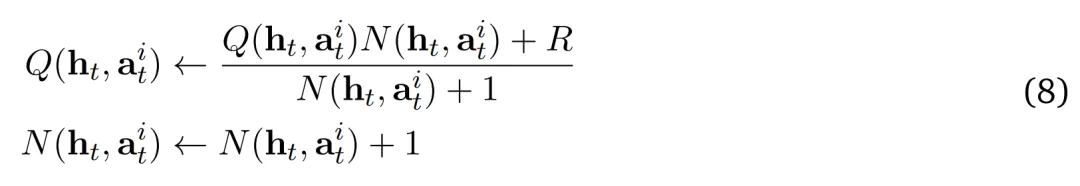
下圖 3 展示了所有結(jié)果和基線。當(dāng)讓智能體在測(cè)試時(shí)能夠搜索信息時(shí),即為基礎(chǔ) xLAM-v0.1-r 模型應(yīng)用 MCTS 時(shí),成功率從 28.6% 提升到了 48.4%,接近平均人類表現(xiàn)的 50.0%,并且顯著超過(guò)了僅通過(guò)結(jié)果監(jiān)督訓(xùn)練的零樣本 DPO 模型的性能。

研究者進(jìn)一步根據(jù)下圖中概述的算法對(duì)基礎(chǔ)模型進(jìn)行了微調(diào),結(jié)果比基礎(chǔ) DPO 模型提高了 0.9%。在精心訓(xùn)練的 Agent Q 模型上再應(yīng)用 MCTS,智能體的性能提升到了 50.5%,略微超過(guò)了人類的平均表現(xiàn)。

他們認(rèn)為,即使智能體經(jīng)過(guò)了大量的強(qiáng)化學(xué)習(xí)訓(xùn)練,在測(cè)試時(shí)具備搜索能力仍然是一個(gè)重要的范式轉(zhuǎn)變。與沒(méi)有經(jīng)過(guò)訓(xùn)練的零樣本智能體相比,這是一個(gè)顯著的進(jìn)步。
此外,盡管密集級(jí)監(jiān)督比純粹的基于結(jié)果的監(jiān)督有所改善,但在 WebShop 環(huán)境中,這種訓(xùn)練方法的提升效果并不大。這是因?yàn)樵谶@個(gè)環(huán)境里,智能體只需要做很短的決策路徑,可以通過(guò)結(jié)果來(lái)學(xué)習(xí)信用分配。
評(píng)估結(jié)果
研究者選擇了讓智能體在 OpenTable 官網(wǎng)上預(yù)訂餐廳的任務(wù)來(lái)測(cè)試 Agent Q 框架在真實(shí)世界的表現(xiàn)如何。要完成這個(gè)訂餐任務(wù),智能體必須在 OpenTable 網(wǎng)站上找到餐廳的頁(yè)面,選擇特定的日期和時(shí)間,并挑選符合用戶偏好的座位,最后提交用戶的聯(lián)系方式,才能預(yù)定成功。
最初,他們對(duì) xLAM-v0.1-r 模型進(jìn)行了實(shí)驗(yàn),但該模型表現(xiàn)不佳,初始成功率僅為 0.0%。因此,他們轉(zhuǎn)而使用 LLaMa 70B Instruct 模型,取得了一些初步的成功。
不過(guò)由于 OpenTable 是一個(gè)實(shí)時(shí)環(huán)境,很難通過(guò)編程或自動(dòng)化的方式進(jìn)行測(cè)量和評(píng)估。因此,研究者使用 GPT-4-V 根據(jù)以下指標(biāo)為每個(gè)軌跡收集獎(jiǎng)勵(lì):(1) 日期和時(shí)間設(shè)置正確,(2) 聚會(huì)規(guī)模設(shè)置正確,(3) 用戶信息輸入正確,以及 (4) 點(diǎn)擊完成預(yù)訂。如果滿足上述所有條件,則視為智能體完成了任務(wù)。結(jié)果監(jiān)督設(shè)置如下圖 5 所示。

而 Agent Q 將 LLaMa-3 模型的零樣本成功率從 18.6% 大幅提高到了 81.7%,這個(gè)結(jié)果僅在單日自主數(shù)據(jù)收集后便實(shí)現(xiàn)了,相當(dāng)于成功率激增了 340%。在引入在線搜索功能后,成功率更是攀升至 95.4%。

更多技術(shù)細(xì)節(jié)和評(píng)估結(jié)果請(qǐng)參閱原論文。
























