超強!深度學習中必知的 79 個重要概念
大家好,我是小寒。
今天給大家分享你必須知道的 79 個深度學習術語。
1.人工神經網絡(ANN)
人工神經網絡是一種模擬人腦神經元結構和功能的計算模型,用于處理復雜的計算和模式識別任務。
它由多個神經元(節點)組成,這些神經元通過連接權重相互連接,可以通過調整這些權重來學習和適應不同的任務。
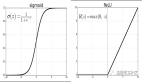
2.激活函數
激活函數是神經網絡中的一個函數,用于引入非線性,使得神經網絡可以表示復雜的模式和關系。
常見的激活函數包括ReLU(修正線性單元)、Sigmoid(S型函數)和Tanh(雙曲正切函數)。
3.反向傳播
反向傳播是一種用于訓練神經網絡的算法,通過計算損失函數的梯度并更新網絡中的權重,使得模型的預測結果更加準確。
反向傳播通常使用梯度下降法來優化權重。
4.卷積神經網絡(CNN)
卷積神經網絡是一種專門用于處理圖像數據的神經網絡結構,通過使用卷積層、池化層和全連接層來提取和學習圖像的特征。
它在圖像分類、目標檢測和圖像分割等任務中表現出色。
5.深度學習
深度學習是一種基于多層神經網絡的機器學習方法,通過構建和訓練深度模型來自動學習數據的復雜特征和模式。
深度學習在圖像處理、自然語言處理和語音識別等領域取得了顯著的成果。
6.epoch
一個epoch指的是神經網絡在訓練過程中遍歷整個訓練數據集一次。
多個epoch可以提高模型的準確性和穩定性,但過多的epoch可能導致過擬合。
7.特征提取
特征提取是從原始數據中提取有用特征的過程,這些特征可以幫助模型更好地理解和預測數據的模式。
特征提取可以是手工設計的,也可以是通過深度學習模型自動學習的。
8.梯度下降
梯度下降是一種優化算法,用于最小化損失函數。
通過計算損失函數相對于模型參數的梯度,并沿著梯度的反方向更新參數,使得損失函數逐漸減小。
9.損失函數
損失函數用于衡量模型預測值與真實值之間的差異。
常見的損失函數包括均方誤差(MSE)、交叉熵損失(cross-entropy loss)等。
10.循環神經網絡(RNN)
循環神經網絡是一種處理序列數據的神經網絡結構,它通過在網絡中引入循環連接,使得模型能夠記住之前的輸入信息,并用于后續的預測和決策。
11.遷移學習
遷移學習是一種將一個任務中學到的知識應用到另一個相關任務中的方法。
通過遷移學習,可以利用預訓練模型的權重和特征,減少新任務的訓練時間和數據需求。
12.權重
權重是神經網絡中連接各個神經元的參數,用于調節輸入信號的強度。
通過訓練過程,權重會不斷調整,以使得模型的預測結果更加準確。
13.偏置
偏置是神經網絡中的一個附加參數,它與權重一起用于調整模型的輸出。
偏置可以幫助模型在沒有輸入信號的情況下也能產生輸出,從而提高模型的靈活性和準確性。
14.過擬合
過擬合是指模型在訓練數據上表現良好,但在測試數據上表現不佳的情況。
過擬合通常是由于模型過于復雜,捕捉到了訓練數據中的噪聲和細節,導致其泛化能力下降。
15.欠擬合
欠擬合是指模型在訓練數據和測試數據上都表現不佳的情況。
這通常是由于模型過于簡單,無法捕捉數據中的重要模式和關系。
16.正則化
正則化是一種防止過擬合的方法,通過在損失函數中加入懲罰項,限制模型的復雜度,使得模型能夠更好地泛化到未見過的數據。
常見的正則化方法包括L1正則化和L2正則化。
17.Dropout
Dropout 是一種正則化技術,通過在訓練過程中隨機丟棄一部分神經元及其連接,使得模型更具魯棒性,防止過擬合。
18.批量標準化
批量標準化是一種加速神經網絡訓練并提高穩定性的方法,通過在每一層對輸入數據進行標準化,使得數據的均值為 0,方差為1,從而減少內層協變量偏移。
19.自動編碼器
自動編碼器是一種用于無監督學習的神經網絡,通過將輸入數據編碼為低維表示(編碼器)并從低維表示重建原始數據(解碼器),自動編碼器可以用于數據降維、特征提取和異常檢測。
20.生成對抗網絡(GAN)
生成對抗網絡是一種用于生成新數據的模型,由生成器和判別器兩個部分組成。
生成器生成偽造數據,判別器判斷數據的真假,兩者相互競爭,最終生成器可以生成逼真的數據。
21.注意力機制
注意力機制是一種提高模型處理長序列數據能力的方法,通過為每個輸入元素分配不同的權重,使得模型能夠更關注重要的信息,廣泛應用于自然語言處理和圖像處理任務。
22.嵌入層
嵌入層是一種將高維離散數據(如單詞)映射到低維連續向量空間的技術,用于捕捉數據之間的語義關系,常用于自然語言處理任務中的詞向量表示。
23.多層感知器(MLP)
多層感知器是一種基本的神經網絡結構,由輸入層、隱藏層和輸出層組成。
每層的神經元通過權重連接,MLP可以用于分類和回歸任務。
24.規范化
規范化是將數據按比例縮放到特定范圍的方法,常見的規范化方法包括最小-最大規范化和z-score規范化。
規范化有助于加速模型的訓練并提高模型的性能。
25.池化層
池化層是一種用于減少特征圖尺寸的層,通過取鄰近區域的最大值或平均值,減少參數數量和計算量,同時保留重要特征,常用于卷積神經網絡中。
26.序列到序列模型
序列到序列模型是一種用于處理序列數據的模型結構,通過編碼器將輸入序列編碼為固定長度的向量,再通過解碼器將向量解碼為輸出序列,廣泛應用于機器翻譯和文本生成等任務。
27.張量
張量是深度學習中用于表示數據的多維數組。
張量可以是標量、向量、矩陣或更高維度的數據結構,是構建和訓練神經網絡的基本數據單元。
28.骨干網絡
骨干網絡(Backbone)是深度學習中用于特征提取的主要網絡結構。它通常是一個預訓練的神經網絡模型,用于從輸入數據中提取高層次的特征表示。這些特征然后被用作下游任務(如分類、檢測、分割等)的輸入。
29.微調
微調是指在預訓練模型的基礎上,對特定任務進行進一步訓練和調整,使模型更適應新的任務。
微調可以減少訓練時間和數據需求,提高模型的性能。
30.超參數
超參數是模型訓練前設置的參數,不會在訓練過程中更新。
常見的超參數包括學習率、批次大小、網絡層數等。
超參數的選擇對模型的性能有重要影響。
31.學習率
學習率是梯度下降法中的一個重要參數,決定了每次更新權重的步長大小。
學習率過大會導致訓練不穩定,學習率過小會導致訓練速度慢。
32.Softmax 函數
Softmax 函數是一種歸一化函數,將輸入的實數向量轉換為概率分布,使得輸出的所有元素之和為1,常用于多分類任務的輸出層。
33.長短期記憶(LSTM)
長短期記憶是一種改進的循環神經網絡結構,通過引入記憶單元和門機制,解決了標準RNN的梯度消失和梯度爆炸問題,能夠更好地捕捉序列數據中的長依賴關系。
34.梯度消失問題
梯度消失問題是指在深度神經網絡中,隨著反向傳播過程中梯度逐層傳遞,梯度值會變得非常小,導致前幾層的權重幾乎無法更新,影響模型的訓練效果。
35.梯度爆炸問題
梯度爆炸問題是指在深度神經網絡中,隨著反向傳播過程中梯度逐層傳遞,梯度值會變得非常大,導致權重更新過度,影響模型的穩定性。
36.數據增強
數據增強是一種通過對原始數據進行隨機變換(如旋轉、翻轉、裁剪等)來生成更多訓練數據的方法,以提高模型的泛化能力和魯棒性。
37.批次大小
批次大小是指在一次迭代中用于訓練模型的數據樣本數量。
較大的批次大小可以加速訓練過程,但需要更多的內存;較小的批次大小則更具噪聲,可能導致訓練不穩定。
38.優化器
優化器是用于更新神經網絡權重的算法,根據損失函數的梯度計算權重的更新值。
常見的優化器包括SGD(隨機梯度下降)、Adam、RMSprop等。
39.F1-score
F1-score 是用于衡量分類模型性能的指標,是精準率和召回率的調和平均值。
F1-score 的值介于0和1之間,值越大表示模型性能越好。
40.精準
精準率是指在所有被預測為正類的樣本中,實際為正類的樣本所占的比例。
它衡量了模型預測結果的準確性。
41.召回
召回率是指在所有實際為正類的樣本中,被正確預測為正類的樣本所占的比例。
它衡量了模型對正類樣本的識別能力。
42.ROC 曲線
ROC曲線(接收者操作特征曲線)是一種用于評價分類模型性能的圖形,通過繪制真陽性率和假陽性率之間的關系來展示模型在不同閾值下的表現。
43.曲線下面積(AUC)
AUC是ROC曲線下的面積,用于衡量分類模型的整體性能。AUC值介于0和1之間,值越大表示模型性能越好。
44.提前停止
提前停止是一種正則化技術,通過在驗證集上監控模型的性能,如果性能不再提升或開始下降,提前停止訓練,以防止過擬合。
45.特征縮放
特征縮放是將特征數據按比例縮放到特定范圍的方法,常見的特征縮放方法包括標準化和歸一化。
特征縮放有助于加速模型的訓練并提高模型的性能。
46.生成模型
生成模型是指通過學習數據的分布來生成新數據的模型。
常見的生成模型包括GAN、變分自編碼器(VAE)等。
47.判別模型
判別模型是指通過學習數據的決策邊界來進行分類或回歸的模型。
常見的判別模型包括邏輯回歸、支持向量機(SVM)等。
48.數據不平衡
數據不平衡是指訓練數據中不同類別樣本數量差異較大的情況,可能導致模型偏向多數類樣本,影響分類性能。
49.降維
降維是將高維數據轉換為低維數據的過程,以減少數據的維度,降低計算復雜度,同時保留數據的主要特征。
常見的降維方法包括PCA、t-SNE等。
50.主成分分析(PCA)
主成分分析是一種線性降維方法,通過尋找數據中方差最大的方向,將數據投影到低維空間,以保留數據的主要特征。
51.非線性激活函數
非線性激活函數是神經網絡中的一種函數,用于引入非線性,使得神經網絡能夠表示復雜的模式和關系。
常見的非線性激活函數包括ReLU、Sigmoid、Tanh等。
52.批量訓練
批量訓練是指在訓練過程中將數據分成多個小批次,每次使用一個批次的數據來更新模型的參數。
這種方法可以加速訓練過程并提高模型的穩定性。
53.隨機梯度下降(SGD)
隨機梯度下降是一種優化算法,通過對每個樣本或小批次樣本計算梯度并更新模型參數,以最小化損失函數。
SGD 在大規模數據訓練中表現良好。
54.注意層
注意層是一種用于提高模型處理長序列數據能力的層,通過為每個輸入元素分配不同的權重,使得模型能夠更關注重要的信息,廣泛應用于自然語言處理和圖像處理任務。
55.跳過連接
跳過連接是指在深度神經網絡中通過增加跨層連接,使得輸入信號可以直接傳遞到后面的層,緩解梯度消失問題,提高模型的訓練效果。
ResNet是典型的應用跳過連接的模型。
56.自監督學習
自監督學習是一種通過生成和利用數據中的內在結構和關系進行訓練的方法,不需要大量的標注數據,常用于圖像、文本和音頻等領域。
57.交叉熵損失
交叉熵損失是一種用于分類任務的損失函數,通過衡量模型預測的概率分布與真實分布之間的差異,來指導模型參數的更新。
58.序列建模
序列建模是指通過模型來捕捉和預測序列數據中的模式和關系,常用于時間序列分析、自然語言處理和音頻信號處理等任務。
59.知識蒸餾
知識蒸餾是一種通過將大模型(教師模型)的知識傳遞給小模型(學生模型)的方法,使得小模型能夠在保持較高性能的同時減少參數數量和計算量。
60. 神經風格遷移
神經風格遷移是一種通過深度學習模型將一種圖像的風格應用到另一種圖像上的技術,常用于圖像生成和藝術創作。
61. 標簽平滑
標簽平滑是一種正則化技術,通過在訓練過程中將真實標簽分布進行平滑,使得模型的預測更加魯棒,減少過擬合的風險。
62.T-SNE
T-SNE 是一種用于數據可視化的降維方法,通過將高維數據嵌入到低維空間中,保留數據點之間的相對距離和結構,以便于觀察和分析。
63.梯度剪切
梯度剪切是一種防止梯度爆炸的方法,通過將超過閾值的梯度進行剪裁,使得梯度保持在合理范圍內,提高模型的訓練穩定性。
64.元學習
元學習是一種學習如何學習的技術,通過在多個任務上進行訓練,使得模型能夠更快地適應新任務和新數據,提高學習效率和泛化能力。
65.量化
量化是將神經網絡中的權重和激活值從浮點數表示轉換為低精度表示(如整數),以減少模型的計算量和存儲需求,提高模型的運行效率。
66.自注意力
自注意力是一種用于捕捉序列數據中各元素之間依賴關系的機制,通過計算序列中各元素對其他元素的注意力權重,使得模型能夠更好地理解和處理長序列數據。
67.Transformer 模型
Transformer 模型是一種基于自注意力機制的神經網絡結構,廣泛應用于自然語言處理任務,如機器翻譯、文本生成等。
Transformer 模型通過并行計算和全局依賴關系捕捉,顯著提高了模型的性能和訓練效率。
68.BERT
BERT(Bidirectional Encoder Representations from Transformers)是一種基于Transformer的預訓練語言模型,通過雙向編碼器捕捉句子中的上下文信息,廣泛應用于各種自然語言處理任務。
69.詞嵌入
詞嵌入是一種將詞語表示為連續向量的方法,通過捕捉詞語之間的語義關系,使得詞語能夠在低維向量空間中進行計算和比較。
常見的詞嵌入方法包括Word2Vec、GloVe等。
70.位置編碼
位置編碼是一種在 Transformer 模型中用于表示序列中每個元素位置的信息,使得模型能夠捕捉序列數據中的順序關系,常用的方式包括正弦和余弦函數編碼。
71.圖神經網絡(GNN)
圖神經網絡是一種用于處理圖結構數據的神經網絡,通過對圖中節點和邊的信息進行傳遞和聚合,使得模型能夠捕捉圖結構中的關系和模式,應用于社交網絡分析、推薦系統等任務。
72.強化學習
強化學習是一種通過與環境互動來學習最優策略的機器學習方法,通過獎勵和懲罰信號指導智能體的行為選擇,應用于游戲、機器人控制等領域。
73.模型修剪
模型修剪是一種減少神經網絡中冗余連接和參數的方法,通過刪除不重要的連接,使得模型更加緊湊、高效,同時保持或提高模型的性能。
74.偏差-方差權衡
偏差-方差權衡是指模型在擬合訓練數據和泛化到未見數據之間的平衡。
偏差表示模型對訓練數據的擬合能力,方差表示模型對訓練數據變化的敏感度。
合適的權衡可以提高模型的泛化能力。
75.多模式學習
多模式學習是指同時處理多種類型的數據(如圖像、文本、音頻等)并學習它們之間的關聯關系,使得模型能夠更全面地理解和處理復雜任務。
76.異常檢測
異常檢測是指識別和檢測數據中異常或異常模式的任務,廣泛應用于故障檢測、欺詐檢測和安全監控等領域。
77.卷積
卷積是一種用于提取數據局部特征的操作,通過在輸入數據上應用卷積核(濾波器),生成特征圖,使得模型能夠捕捉數據中的模式和結構,常用于圖像處理任務。
78.池化
池化是一種用于減少特征圖尺寸的操作,通過取鄰近區域的最大值或平均值,減少參數數量和計算量,同時保留重要特征,常用于卷積神經網絡中。
79.擴張卷積
擴張卷積是一種改進的卷積操作,通過在卷積核之間插入空洞,使得卷積核能夠覆蓋更大的感受野,從而提取更多的上下文信息,常用于圖像分割任務。