為什么AI數不清Strawberry里有幾個 r?Karpathy:我用表情包給你解釋一下
還記得這些天大模型被揪出來的低級錯誤嗎?
不知道 9.11 和 9.9 哪個大,數不清 Strawberry 單詞里面有多少個 r…… 每每被發現一個弱點,大模型都只能接受人們的無情嘲笑。

嘲笑之后,大家也冷靜了下來,開始思考:低級錯誤背后的本質是什么?
大家普遍認為,是 Token 化(Tokenization)的鍋。
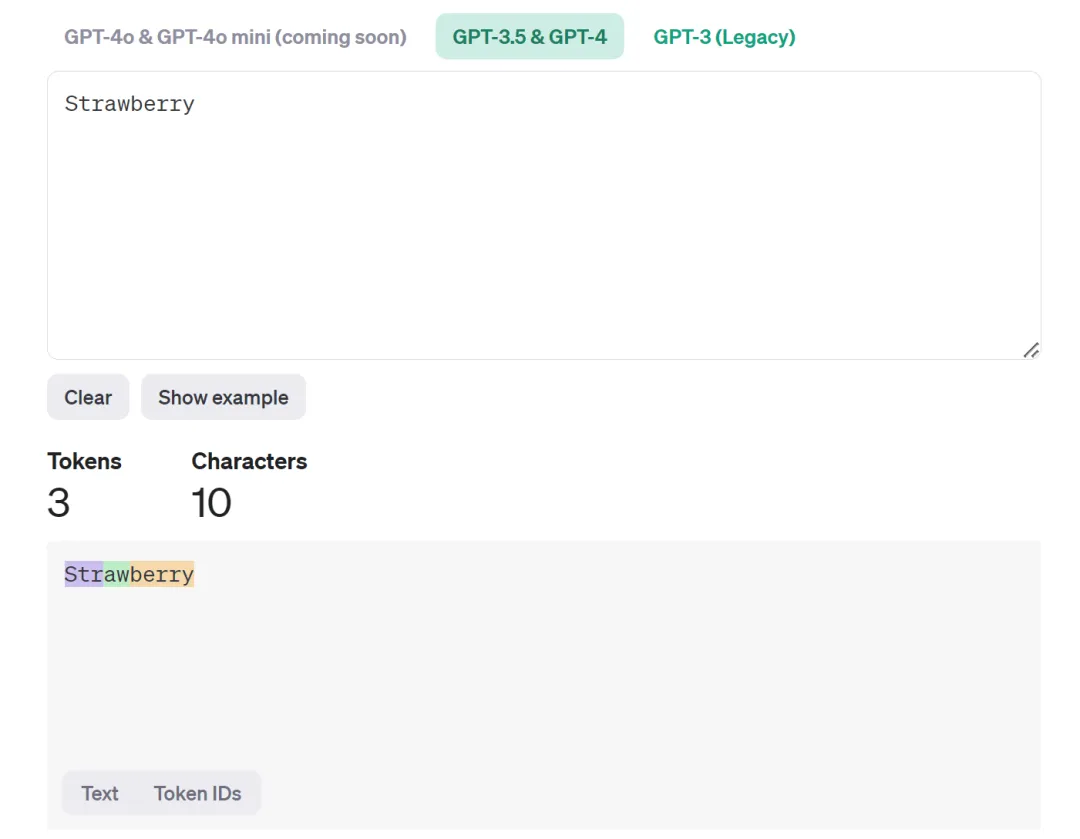
在國內,Tokenization 經常被翻譯成「分詞」。這個翻譯有一定的誤導性,因為 Tokenization 里的 token 指的未必是詞,也可以是標點符號、數字或者某個單詞的一部分。比如,在 OpenAI 提供的一個工具中,我們可以看到,Strawberry 這個單詞就被分為了 Str-aw-berry 三個 token。在這種情況下,你讓 AI 大模型數單詞里有幾個 r,屬實是為難它。
除了草莓 (Strawberry) 之外,還有一個很好的例子就是「Schoolbooks」這個詞,AI 模型會把它分為 school 和 books 兩個 token。


這個問題也吸引了剛剛投身 AI + 教育行業的 Karpathy 的注意。為了讓大家直觀地看到大模型眼里的文字世界,他特地寫了一個小程序,用表情符號(emoji)來表示 token。

按照小程序被設計的表示方法,「How many letters 'r' in the word'strawberry'?」在 LLM 看來是這樣的:

一段文本在 LLM 看來會是這樣:

但這種解釋也引起了另一種疑問:如果你讓大模型把 Strawberry 這個詞的每個字母都列出來,然后刪掉 r 以外的字母,大模型就能數對了,那大模型為什么自己不這么做呢?它好像不太會利用自己的能力。


對此,Karpathy 給出的回復是「因為沒有人教它這么做」。

其實,如果你在 Prompt 里加上「think step by step」等思維鏈相關「咒語」,大模型是可以分步驟解決問題的,而且很有可能數對「r」的數量。那它之前不假思索就給出答案,是不是因為過度自信?

對此,有人猜測說,大模型公司給 LLM 的設定可能就是讓它在一個問題上花費盡可能少的時間,因此,除非你明確要求,不然它不會主動去深入思考。

對于這種說法,我們也測試了一下。結果發現,如果明確要求深入思考,模型確實立馬就會數了:

這就類似于它有兩套系統:快速、依靠直覺的系統 1 和較慢、較具計劃性且更仰賴邏輯的系統 2,平時默認使用系統 1。

當然,這些只是猜測。
綜合最近的新聞來看,我們會發現一個有意思的現象:一方面,大模型都能在人類奧數中拿銀牌了;而另一方面,它們又在數數、比大小方面集體翻車。類似的例子還有不會玩幾歲小孩都會玩的井字棋,不會判斷兩個圓是否重疊等。

Karpathy 給這種現象取了個名字 ——Jagged Intelligence(Jagged 的意思是參差不齊的)。這種參差不齊的智能表現和人類是不一樣的,人類的知識體系和解決問題的能力在成長過程中是高度相關的,并且是同步線性發展的,而不是在某些領域突然大幅度提升,而在其他領域卻停滯不前。
Karpathy 認為,這一問題的核心在于目前的大模型缺乏「認知自我知識(cognitive self-knowledge)」( 模型自身對其知識和能力的自我認知 )。如果模型具備這種能力,它可能會在面對「數字母」這樣的問題時回答說,「我不太擅長數字母,讓我使用代碼解釋器來解決這個問題」。

這一問題的解決方案可能包括但不限于擴大規模,可能需要在整個技術棧的各個方面都做一些工作,比如在后訓練階段采用更復雜的方法。
對此,Karpathy 推薦閱讀 Llama 3 論文的 4.3.6 章節。在此章節中,Meta 的研究者提出了一些方法來讓模型「只回答它知道的問題」。

該章節寫到:
我們遵循的原則是,后訓練應使模型「知道它知道什么」,而不是增加知識。我們的主要方法是生成數據,使模型生成與預訓練數據中的事實數據子集保持一致。為此,我們開發了一種知識探測技術,利用 Llama 3 的 in-context 能力。數據生成過程包括以下步驟:
1、從預訓練數據中提取數據片段。
2、通過提示 Llama 3 生成一個關于這些片段(上下文)的事實問題。
3、采樣 Llama 3 關于該問題的回答。
4、以原始上下文為參照,以 Llama 3 為裁判,評估生成的回答的正確性。
5、以 Llama 3 為裁判,評估生成回答的信息量。
6、對于 Llama 3 模型在多個生成過程中提供的信息雖多但內容不正確的回答,使用 Llama 3 生成拒絕回答的內容。
我們使用知識探測生成的數據來鼓勵模型只回答它知道的問題,而拒絕回答它不確定的問題。此外,預訓練數據并不總是與事實一致或正確。因此,我們還收集了一組有限的標注事實性數據,這些數據涉及與事實相矛盾或不正確的陳述。
最后,Karpathy 表示,這種參差不齊的智能問題值得注意,尤其是在生產環境中。我們應該致力于讓模型只完成他們擅長的任務,不擅長的任務由人類及時接手。