DataOps+大模型促進數據工程創新
ChatGPT4 橫空出世,其強大的語義泛化能力以及針對 Zero-Shot、Few-Shot 等場景的特性讓 AI 的使用門檻進一步降低,也為各行各業帶來了更多想象空間。本文將分享海南數造科技對 DataOps 加大模型驅動數據創新的思考與實踐。
一、傳統數據管理面臨的挑戰

企業做數字化轉型會制定自己的數字戰略,在數字戰略與業務戰略對齊的過程中,企業也完成了數據從收集、管理到分析的流程,這個流程就是企業數字化轉型的體現。
企業數字化轉型呈現出三大戰略趨勢:
- 首先是數據分析民主化。數據分析不再只是少數人的工作,各個崗位都會去看報表,也會用一些統計算法,以實時支撐業務決策。
- 第二是數據技術多元化。現在信息系統多元化,數據開發同學面臨著各種多元異構的數據。在復雜的數據環境下,我們需要多元化的一些技術組件來支撐,比如 Flink、Spark 等計算組件和存儲組件。又比如在很多金融反欺詐場景中,會用到知識圖譜建模和分析的數據組件。整體上變成了一個很龐大的、復雜的系統化工程。
- 第三是業務價值精益化。對于業務部門來說,也希望數據能實現快速變現。

在上述趨勢下,我們面臨著供需不平衡的痛點。現在市場變化很快,業務同學需要快速響應市場變化,所以經常會有大量的、臨時的,且有高時效性要求的數據需求。開發在早期會面臨開發環境與測試環境不一致,部署和集成需要大量人工介入,系統之間存在數據孤島問題。導致調研數據口徑要耗費大量時間,數據開發從交付到上線往往超過一周,甚至更長時間。同時也存在數據語義缺失、業務用數困難等其它一些問題。

數據開發工作也像軟件工程一樣,不應該是瀑布式的流程,即所有事情都要先計劃好、設計好才去開發,而是要實現敏捷交付,能夠實時地響應需求。當前研發進度是落后于市場需求的。
二、DataOps 與大模型的結合驅動數據工程創新

在數字化轉型的趨勢下,也是在上述痛點的驅動下,企業亟需新的數據研發范式,需要滿足以下要求:
- 形成敏捷數據研發流水線。
- 構建高效的跨域協同機制。
- 打造自助的用數體驗。
- 建立精細化的運營體系。
這樣才能實現快速交付數據的目的。

在這樣的背景下,我們提出了 DataOps 的理念。DataOps 是在 DevOps 的基礎上發展而來的,其本質是數據工作流的編排、數據的開發、測試、部署上線、回歸這套機制需要達到持續集成的效果,有標準化的體系,實現自動化部署,同時優化整個數據發布的流程,優化資源達到敏捷開發交付的效果。

從 2018 年開始,DataOps 的理念度被 Gartner 列入了技術成熟度曲線,并有著逐年上升的趨勢。數造科技在 2022 年與信通院聯合成立了一個專家工作小組,制定了 DataOps 的能力標準。

介紹了 DataOps 的背景后,讓我們再回到 AI。從 AlphaGo 為代表的深度學習技術的發展,到去年 ChatGPT 大語言模型技術的出現,AI 使用門檻越來越低,我們的信息化系統越來越智能化。

僅僅一年時間里,出現了很多基于大語言模型的 AI 工具。我們團隊使用了一款名為 Bito 的代碼自動生成和檢查的開源插件,使得工作效率提升了 20% 以上。

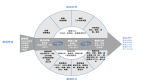
上圖展示了我們 DataOps 的標準化流程,在數據的開發、發布的過程中,使用大模型支持代碼生成、代碼解釋以及代碼審查的工作,讓整個流程更加智能化。

上圖中對比了傳統數據開發模式和“DataOps+大模型”模式。傳統數據開發模式,從數據建模、數據開發到測試、部署、回歸,步驟繁雜,需要大量的人力介入。在最早的時候,我們有開發環境、測試環境和準生產環境,不同的環境中會有不同的開發人員維系其參數配置文件。當部署的時候,就要手動改配置文件,往往會引入潛在的風險。
有了 DataOps 這一套敏捷數據開發發布的標準后,就能達到自動化的效果。這些配置文件會被統一、自動化地管理起來,達到一套數據開發,一套數據建模的腳本,能在多套環境里面去使用,配置參數會自動替換。同時還具備數據沙箱的功能,測試數據可能無法體現生產環境的情況,所以可以使用準生產環境的數據去驗證腳本。在這種自動化的體系下,加入了一些大模型的能力,可以幫助我們生成一些數據指令,比如自動生成 SQL 或者加入注釋,以及自動審查等等。所以“DataOps+大模型”就是在 DataOps 這套標準化流程的體系上,加入自動化和智能化,讓數據的開發和交付更加高效。
三、DataOps+大模型產品實踐探索
大模型有很多有趣的應用場景,例如文案生成、數字人、知識檢索增強等等。還有一個比較熱門的場景就是 Text2SQL,讓大模型去生成指令,接下來將介紹我們在這一方向上的探索與實踐。

Text2SQL 就是基于以自然語言描述的問題,結合表的元數據信息(包括表名、列名以及表之間的關聯關系),生成一個準確的 SQL 語句。2022 年,在大模型出現之前,Text2SQL 基于預訓練模型的準確率能夠做到 75-77% 左右。這一數據來自 Spider 的評測榜單,這是一個跨域的,在 Text2SQL 領域比較權威的榜單。大模型出現后,每兩個月榜單會更新一次,GPT4 做的 Text2SQL 任務,準確率也從原來的 78% 一路飆升到 91%。
而 Text2SQL 任務,產生正確的 SQL 只實現了其一半的價值,對于數據開發人員來說,另一半的價值是快速找到想要的數據。現實的生產環境中有大量的數據庫、表,要基于自然語言的提問,找到準確的表和列,也就是準確數據口徑。所以我們認為 Text2SQL 的定義還要包括在不同 schema 下面能產生正確 SQL 的任務。

在大模型出現之前的做法,是用 Seq2Seq 的模型。對于提問,表的元數據信息做嵌入,基于嵌入的向量信息,生成 SQL 語句,這里會有 mismatch problem in literature 的問題。我們做文本時,中文轉英文或者中文轉德文,詞語表述不一樣,語法結構不一樣,但可能語義是一樣的。而對于 Text2SQL 的任務來說,語義是不一樣的,問題用 SQL 是沒辦法準確表述的,比如 SQL 中的 group by、intersect、union 是不會在自然語言里面出現的,你不會說:“幫我查這個季度的總銷售額,用 group by 這個語句”,所以就會存在語義不對等的問題。

基于這個問題,在模型架構上,比如 Encoder Decoder 上做了很多優化策略。在大模型出來之前,我們常用的就是谷歌 T5-3B、Electra 或者 RoBERTa 這些預訓練模型作為模型底座,不斷優化其 Encoder,一開始只是簡單的 input representation,一個簡單的嵌入的任務,但是會發現有 schema-linking 不準確的問題。為了更好地將問題與需要用到的表或者列關聯起來,后面有了更復雜的 Structure Modeling 的建模,會對問題建模,對元數據采用更復雜建模的策略,以找到問題相關的表和列。
近幾年比較流行的一種方法是基于知識圖譜的建模方式,一開始大家會用 GNN 圖神經網絡的方法去做建模,但存在一個問題,模型更多的是對節點的建模,沒辦法泛化到兩度以上深度的信息。所以后面又提出了 RAT-SQL、RASAT 模型,本質是在知識圖譜上去定義 meta-path,把元數據的關聯關系定義出來,在 Encoder 會去做多頭注意力,把關系的向量信息嵌入到里面,加強問題跟本地元數據的關聯性。
Encoder 的優化策略解決完,就到 Decoder,怎么把 encoder 的編碼生成 SQL 語句,開始大家會用 Sketch-based 的方法,把生成 SQL 語句拆解成一個個的子部分,生成 select,生成 where,生成 from,基于小的語句去做詞槽,把之前 encoder 識別到的表名、列名填到這個詞槽里,但實際上效果并不好,會產生很多錯誤的、不符合語法的 SQL 語句,所以我們用 Generation-based method 的方法,最經典的就是 AST 語法樹的結構,讓它遵循一定的語法樹來生成 SQL,還有 PICARD,在 search 的時候不斷地去一個記憶空間檢查生成的 SQL 跟前面的 Encoder 的 schema-linking 內容是不是對等的、是不是合語法的,包括 RESDSQL,這樣的優化策略,讓它生成更加準確的 SQL。
但是仍然不夠準確,經過分析,還是存在語義不匹配的問題,于是我們又加入了 Intermediate representation 的架構,發明了基于自然語言跟 SQL 之間的中間語言,NatureSQL、SemQL,先生成中間語言,再基于中間語言生成 SQL,準確率又進一步得到了提升。

大模型出現后,其生成 SQL 的準確度,尤其是 GPT4 基于策略的生成,準確度越來越高。大模型目前主要使用有兩種方法,一種是提示工程,一個是基于指令的監督微調,讓大模型產生對應的 SQL。

今年這篇論文來自 SQL,也是大模型生成 SQL 任務的常用方法,即基于思維鏈的方法。在傳統 Seq2Seq 的方法中,輸入自然語言和 schema 信息,讓它去生成 SQL,結果發現這種端到端的方法效果很差,所以才有了 Encoder Decoder 的優化策略。大模型其實也一樣,一開始通過 prompt 把自然語言、schema 喂給它,讓它生成 SQL,發現準確率有問題,所以后面把大模型的任務拆解成一個個子任務,比如先用一個 schema-linking 的 prompt 的模板,找關聯的表、列,再基于表、列,根據問題的復雜性來進行分類,是簡單的一個單表查詢的 SQL,還是有一些 join 語句的 SQL,還是在 join 的基礎上有一些復雜子查詢的 SQL。為什么這樣分類呢?因為對于很簡單的單表查詢的 SQL,如果用復雜的 prompt 模板去生成,效果反而會下降,所以加了一個分類的 prompt。在這篇論文里,還加了 self-correction 的 prompt 的模板,告訴大模型再幫我優化一下 SQL。基于這一系列子任務,還有思維鏈的工程,最終才能讓 GPT4 生成比較準確的 SQL 語句。

實踐過程中發現,無論是傳統的預訓練模型還是大模型,都面臨著很多挑戰。傳統預訓練模型的語義泛化能力肯定比大模型弱,它的生成能力也不一定比大模型強,容易出現 missmatch 的問題,復雜查詢語句的生成能力也比較弱,加上 Encoder、Decoder 采用了大量復雜的優化策略,尤其是基于 graph based 方法,還要人工先生成 meta-path,維護這些 meta-path 也需要大量的工作,相比于大模型的 zero-shot、few-shot 能力,還要準備一些標注語料,工作量也是很大的。比如 T53B 模型用的顯卡資源并不比大模型少。
大模型也同樣面臨一些挑戰,最近發表的所有的 Text2SQL 論文全部集中在 GPT4 的研究,對于本地化、私有化的大模型研究偏少。Prompt 的良好實踐,比較依賴于思維鏈,還有 in-context learning,也就是要給大模型一些樣例數據去引導它生成更加準確的 SQL,但對于復雜的 schema,就會超出大模型的 token。所以有一種做法是先把表預處理成寬表,生成的 SQL 就沒那么復雜了,就變成了基于寬表去生成查詢語句,不用做 join 操作。但生成寬表的時候,面臨著 schema 非常大的問題,很容易超出它的 token。基于私有化大模型的微調也是非常少的。
我們認為傳統預訓練模型和大模型都面臨著一個共同的挑戰,用戶在實際使用過程中其實不知道數據是在哪一個數據庫中,怎么去從大量的庫、表、幾千行的 schema 中找到問題對應的列和表,高效的完成 schema-linking 是非常困難的。現在很多 Text2SQL 的評測任務是已經假定了要用哪個庫,這個庫中的表和列往往是非常少的,所以沒有遇到復雜的 schema 中找數的問題。

我們提出了一些實踐和方法,先構建一個元數據的語義圖譜,語義就是問題加上表名加列名,這就是生成 SQL 需要用到的所有語義。當我們去生成一個語義圖譜的時候,有更多的 label 信息,還有指標的描述,能補充到這個語義里,讓 prompt 生成的準確率更高。生成語義圖譜,需要一套完備的數據治理工具。我們在數據建模的時候,有一套自動化的數據標準工具,把這套數據標準落到數據模型中,稱為模型落標的過程。基于數據標準完成數據模型的時候,會把邏輯層、概念層的元數據,還有管理元數據共同落到元數據目錄上,再基于元數據目錄最終生成語義圖譜,這個是生成元數據血緣的過程。
另外有些客戶在搭建數倉的過程中,會抄一些事實表、維度表,這種數倉建模的形式,整個數倉建模直接做成從邏輯層開始建模,但是當建模完成后,數據開發人員不知道這個表對應到什么業務口徑,而業務口徑也不知道這個業務指標需要用到哪些表,有哪些工作流,這也導致了語義不對等的問題。更多業務口徑的語義在哪里?其實是在概念層上面,現在大家做概念層的語義其實全部是用知識圖譜去做的,所以這個血緣圖譜在 Text2SQL 的任務上是非常重要的。很多論文中的數據預處理的工作是在做語義轉換,比如表名叫 department,其實就用 DEPT 簡稱來縮寫,DEPT 是一個沒有任何意義的列名,SQL 模型怎么能識別得到呢?所以需要一些數據治理的前期準備工作。

現在業界都是基于 GPT4 去做 Text2SQL 任務,我們與一些國產大模型開展生態合作,接入了它們的一些接口去做測試。現在所有測試是基于特定場景、特定數據、特定私有化的大模型去做的,僅供參考,不一定是具有很高的代表性。我們發現私有化大模型的指令微調在 Text2SQL 任務上的效果是有限的,這個問題相信很快會得到解決。另外基于 schema-linking 所選取出來的元數據信息,再去生成 prompt,在私有化的大模型上,Text2SQL 任務有 5% 到 10% 的提升。先用一個 schema-linking 的模型,先找出和問題相關的表名、列名,再基于表名、列名去做prompt 模板,模型的準確率會有提升,而不是直接把所有元數據信息喂給大模型。基于預訓練模型 schema-linking 的效果是好于大模型的。In-context learning 對私有化大模型的提升效果是最明顯的,大概有 10% 的提升。我們之前 Text2SQL 經常用的 Intermediate Representation 的方法,生成自然語言和 SQL 語句的一種中間語言策略在部分大模型上沒有化學反應,甚至效果更差。Self-correction 對私有化大模型有小幅提升。相比于私有化大模型,目前 GPT4 的效果還是遙遙領先的。

這就是我們提出的方法,schema-linking 是基于預訓練模型去找到問題相關的表和列名,再基于 prompt 去做大模型,現在很多評測,尤其榜單的評測數據,用到的表名和列名非常少,所以在做 schema-linking 的時候,也加大了難度,給它更多不同的數據庫、不同的表、不同的列名,其 AUC 并沒有明顯的下降。

這是我們基于人大今年發表的一篇 RESDSQL 的論文所做的 schema-linking。其底層是 RoBERTa,基于 RoBERTa 做 Pooling Module,把切的詞對應到完整的表名或者列名上,在做多頭注意力的時候,對列名做多頭注意力,把一些列的信息嵌入到表名上來提升它對問題相關的表名、列名做排序。我們是基于這個模型做的 schema-linking。

我們也參考了阿里發表的 Dail SQL 這篇論文,其中提出了 prompt 模板的一個標準方法,基于 prompt 模板,再加上 GPT4,準確率能達到 85-86%。一開始用了 Code Representation 來表示 schema,然后用了 Intermediate Representation,同時最重要的是加入了 in-context learning。這篇論文中,同時使用了相似的問題和相似的 SQL 去組成 prompt 模板中的示例,提示大模型去生成正確的 SQL。其實這里缺失了 schema 結構的相似性,很多時候sql語句的結構不光取決于問題,還取決于對應的數據庫 schema 結構,如何在相似問題和相似 SQL 的基礎上引入相似 schema 的判斷,我們認為是大模型生成SQL下一個可以探索的方向。

上圖中列出了一些 Prompt 的成功實踐。比如分割符的應用和結構設計,可以讓大模型知道哪一個部分是在提問,哪一個部分是在講 schema,哪一部分是講 in-context learning。另外我們會加入一些輸出前綴,能讓大模型在生成答案的時候更加穩定。這就涉及到大模型的魯棒性,以及指定遵從性的問題,因為測試的過程中,我們會用大模型去嘗試做 schema-linking,讓它按 JSON 格式輸出問題相關的列名和表名,可能 10 次中會有 1 次報錯,比如 JSON 里有個反括號漏掉了,所以魯棒性還是有一定問題的。
接下來介紹數造科技的產品是如何實現 DataOps 與大模型融合的。

上圖是數造科技的產品體系架構。對 DataOps 的整個過程,包括數據集成、開發,提供了標準化的流程和方法,同時基于數據湖倉適配了不同的私有化大模型,基于私有化大模型去完成代碼生成、代碼解釋的工作,幫助 DataOps 提效。同時有統一元數據的服務,對于 Text2SQL 任務來說,語義就在表名、列名和問題上,因此要提供更多的語義信息,構建元數據血緣圖譜。

開發治理一體化的數據管道包括管理域、開發域、治理域。其中,治理域包括一套自動化的數據標準和工具,幫助我們在數據建模的時候落地數據標準,不允許生成毫無意義的表名、列名,這些會嚴重影響 Text2SQL 任務效果。開發域會基于大模型做代碼生成、代碼解析,還有注釋標注的工作。

最后,產品會有持續集成與發布的能力,包括一套代碼在多套環境運行的這種多環境創建和管理的能力。

上圖展示了我們產品的部分功能界面。有些企業采用 Altas 等開源的圖數據血緣工具,它有一個最大的問題是一張表可能有幾十個列,一展開就是爆炸式的、很多的點,讀起來非常困難。所以我們在數據血緣方面做了很多優化的工作,不光是把底層元數據的數據血緣管理起來,也做了一些可視化的優化,讓數據開發人員能真正的基于可視化的界面去探查整個數據血緣。

上圖展示的是數據自動落標、工作流編排等功能。

這是我們做的初版 Text2SQL 的智能小助手,基于輸入的問題可以找出相關的元數據信息,如果不準,還能根據之前的數據治理標準,手動修正相關的主題域,再去喂給大模型生成 SQL。

生成的 SQL 不單單只是看,有一個比較方便的富文本編輯器,直接在編輯器上選定 SQL 運行,可以查看報表。

最后是持續集成和持續發布的功能。
四、未來展望
最后分享一些對未來的展望。

我們構建元數據的語義圖譜,尤其是指標層,包含了更多的業務語義、業務口徑等。如何把每個數據標準自動化工具嵌入到模型中,這是我們未來要做的工作,基于更多的語義,看模型的提升效果怎么樣,現在需要一些人工去給 Spider 數據去做語義的補充。

知識圖譜有很多子圖檢索增強問答的方法,我們也在思考,把語義元素去圖譜后,能不能借鑒知識圖譜基于子圖檢索增強的方法去嵌入子圖的信息,基于子圖去提升 schema-linking 的效果,這也是我們未來想要探索的方向。
另外我們看到大模型,把整個 SQL 任務拆成不同的子任務,基于這些子任務的 Prompt 模板,引導模型生成正確的 SQL,那么能否基于大模型去做一個 agent,用不同的子模型去完成各個階段的 SQL 生成任務,這也是我們目前的一種設想。

近幾個月來我們看到了很多 long-context 大模型的出現,現在的大模型可能就是 2k、4k,有一些長文本的大模型已經輸入到了 200k。現在 Text2SQL 最大的問題就是怎么把大量的生產環境的元數據喂給模型,所以我們也在想 long-context 的大模型能不能直接把所有的元數據喂給它,不需要再做元數據分片的工作,讓它去生成 SQL。當然,關于 long-context 大模型的效果,大家也還在觀望中,這種大模型的注意力在于頭尾,中間的信息可能會缺失,所以這也是我們關注的一個點。

數造科技專注于數據治理、DataOps、數據開發,是新一代敏捷數據管理平臺的供應商,具有大數據賦能能力。

我們的產品是一站式的數據開發管控平臺,包括數據治理、血緣圖譜的構建,還有自動化標準數據治理的工具,以及行業大數據解決方案。