分布式鏈路追蹤,一文幫你掌握它!
隨著互聯網的快速發展,諸如云計算、微服務、開源工具和基于容器交付等技術,使得應用程序在日益復雜的環境中更加分散,因此,追蹤請求在分布式系統中鏈路變得至關重要。
那么,什么是分布式追蹤?它又是如何工作的呢?本文我們將深入進行分析。

什么是分布式追蹤?
分布式追蹤(Distributed Tracing)是一種用于監控和診斷分布式應用程序性能的技術。在分布式系統中,服務通常會被拆分成多個微服務,它們可能運行在不同的服務器或容器中,并通過網絡相互通信。分布式追蹤通過跟蹤和記錄請求在整個系統中的傳播路徑和性能數據,幫助開發人員和運維團隊分析服務之間的調用關系、排查性能瓶頸和故障。
通常,分布式追蹤系統會生成唯一標識每個請求的 TraceId,并記錄每個服務處理請求的時間、耗時、調用鏈路等信息。這些數據可以用于生成可視化的調用圖,幫助開發者理解系統內部各個服務之間的依賴關系和性能狀況。如下圖為一個簡要的分布式系統追蹤網:

為什么需要分布式追蹤?
在單體應用程序時代,掌握系統中發生的情況相對簡單,然而,分布式系統通常由多個獨立的微服務組成,這些服務之間通過網絡進行通信,服務的數量和相互依賴關系的增加使得問題的定位和解決變得更加復雜,這些復雜性給內部協作帶來了巨大的挑戰,同時也大大增加了問題排查的難度和成本。
因此,急需一種手段,能夠在分布式系統中進行全鏈路追蹤,所以分布式追蹤就誕生了。
分布式追蹤對于監視、調試和優化分布式軟件架構(如微服務)至關重要,尤其是在動態微服務架構中,它通過收集和分析與請求觸及的每個服務的每次交互的數據來追蹤單個請求。
分布式追蹤還可以幫助團隊更快地了解每個微服務的執行情況,這種理解有助于他們快速解決問題,提高客戶滿意度,確保穩定的收入,并為團隊保留創新時間。通過這種方式,企業可以充分利用現代應用程序環境提供的優勢,同時最大限度地減少其固有的復雜性也可能帶來的挑戰。
分布式追蹤有哪些類型?
分布式追蹤系統主要有以下幾種類型:
(1) 基于采樣的追蹤
采樣方式又可以細分三種,其詳情如下:
- 全量采樣(Full Tracing):對所有請求進行追蹤記錄。這種方式可以提供最全面的數據,但可能會帶來較高的性能開銷和存儲需求。
- 隨機采樣(Random Sampling):隨機選擇部分請求進行追蹤。可以通過設置采樣率(如10%)來控制追蹤的請求比例,減少開銷。
- 基于策略的采樣(Policy-based Sampling):根據特定的規則或策略進行采樣,如對特定類型的請求、特定用戶或特定時間段的請求進行追蹤。
(2) 基于調用鏈的追蹤
基于調用鏈也可以分為兩種方式,其詳情如下:
- 端到端追蹤(End-to-End Tracing):從請求的入口到最終響應的整個過程中,對所有涉及的服務和組件進行追蹤。
- 局部追蹤(Local Tracing):只對某個服務或組件的內部調用進行追蹤,適用于關注特定服務性能的場景。
(3) 基于日志的追蹤
- 日志增強型追蹤(Log-enhanced Tracing):在現有的日志系統中添加追蹤信息,通過日志來還原請求的調用鏈路和性能數據。
- 獨立追蹤系統(Standalone Tracing System):使用專門的追蹤系統和工具來收集和分析追蹤數據,如Jaeger、Zipkin等。
(4) 基于事件的追蹤
- 同步事件追蹤(Synchronous Event Tracing):對同步調用鏈進行追蹤,適用于傳統的同步HTTP請求場景。
- 異步事件追蹤(Asynchronous Event Tracing):對異步調用鏈進行追蹤,適用于基于消息隊列、異步任務等場景。
分布式追蹤的原理
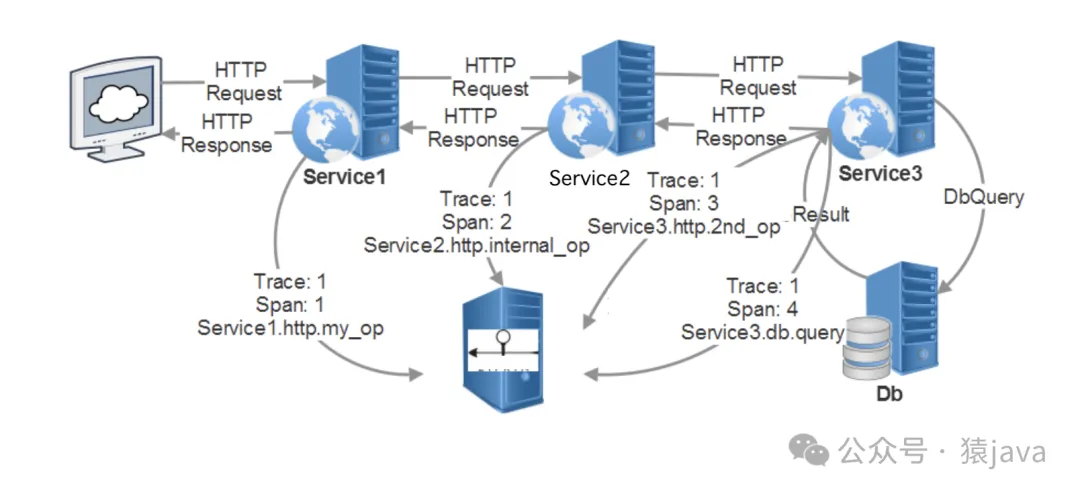
分布式追蹤的工作原理涉及多個組件和步驟,我們通過以下 7個主要流程進行分析:
(1) 唯一標識
在分布式追蹤中,一般都會存在兩個重要的唯一標識:Trace ID 和 Span ID。
- Trace ID:每個請求被分配一個唯一的 Trace ID,用于標識整個請求的生命周期。
- Span ID:每個服務在處理請求時,會生成一個 Span ID,用于標識該服務的處理單元,一個 Trace ID下可以包含多個 Span。
(2) 追蹤上下文傳遞
當一個請求從一個服務傳遞到另一個服務時,Trace ID 和 Span ID 會放置在請求頭中傳遞,以確保追蹤上下文在整個調用鏈中保持一致。
例如,在 HTTP請求中,追蹤信息可以通過特定的 HTTP頭(如 X-B3-TraceId, X-B3-SpanId 等)傳遞。
(3) 生成和記錄Span
每個服務在接收到請求時,會生成一個 Span,記錄該請求的開始時間、結束時間、處理時長、調用的下游服務等信息。Span 還可以包含標簽(tags)和日志(logs),用于記錄額外的上下文信息,如請求參數、錯誤信息等。
(4) 數據收集和傳輸
每個服務會將生成的 Span 數據發送到集中式追蹤收集器(Collector),可以通過多種方式傳輸數據,如 HTTP、gRPC 等。數據收集器接收到 Span 數據后,會對其進行處理、存儲和聚合。
(5) 數據存儲
收集到的追蹤數據通常會存儲在分布式存儲系統中,如 Elasticsearch、Cassandra、Jaeger內置存儲等,以支持高效的查詢和分析。
(66) 數據分析和可視化
通過追蹤系統的用戶界面或可視化工具,用戶可以查詢和分析追蹤數據,生成調用圖、時間線圖等,直觀地展示請求的路徑和各個服務的性能。常見的可視化工具包括 Jaeger UI、Zipkin UI 等,它們提供了豐富的過濾、搜索和分析功能。
(7) 集成和擴展
分布式追蹤系統通常提供多種 SDK 和集成工具,支持在不同的編程語言和框架中嵌入追蹤代碼。還可以與其他監控和日志系統集成,形成統一的可觀測性平臺,如與 Prometheus、Grafana、ELK 等工具集成。
通過上述步驟,分布式追蹤系統能夠全面地跟蹤和分析請求在分布式系統中的傳播路徑和性能,幫助開發者和運維人員深入理解系統的行為和性能,以下為一張簡要的追蹤原理圖:
分布式追蹤的挑戰
盡管分布式追蹤為企業提供了許多優勢,但在實現和維護過程中面臨一些挑戰,包括技術復雜性、性能開銷、數據管理等方面,以下是一些主要的挑戰:
(1) 性能開銷
追蹤數據的收集、傳輸和存儲會帶來額外的性能開銷,特別是在高并發和大規模系統中,這種開銷可能會影響系統的整體性能。
(2) 數據量大
分布式系統中的每個請求可能涉及多個服務,每個服務都會生成追蹤數據,導致數據量非常龐大。有效地存儲、管理和查詢這些數據是一項重大挑戰。
(3) 全鏈路追蹤的難度
確保追蹤上下文在整個調用鏈中傳遞一致性是一個復雜的問題,尤其是在跨語言、跨平臺和跨團隊的系統中。任何一個環節出現問題,都會導致追蹤數據的不完整或不準確。
(4) 采樣策略的選擇
在高流量系統中,不可能對每個請求都進行追蹤,需要選擇合適的采樣策略來平衡追蹤數據的代表性和系統的性能開銷。制定和調整采樣策略需要對系統有深入的了解。
(5) 可視化和分析
大量的追蹤數據需要有效的可視化和分析工具來幫助開發者和運維人員理解系統的行為和性能。設計和實現高效的可視化工具是一個挑戰。
(6) 數據一致性和可靠性
確保追蹤數據的準確性和一致性,避免數據丟失或錯誤,尤其是在系統發生故障或網絡不穩定的情況下。
(7) 跨團隊協作
實現和維護分布式追蹤需要開發、運維、安全等多個團隊的協作。不同團隊之間的溝通和協調是一個重要的挑戰。
(8) 隱私和安全
追蹤數據可能包含敏感信息,確保數據的隱私和安全是必須的。需要采取適當的措施來保護數據不被未經授權的訪問和泄露。
(9) 適應多樣化技術棧
現代分布式系統通常使用多種編程語言、框架和平臺。需要支持多樣化技術棧的追蹤工具和標準,以確保在不同環境中的一致性和兼容性。
(10) 成本管理
存儲和處理大量追蹤數據可能帶來高昂的成本。需要有效的成本管理策略,如數據壓縮、歸檔和自動刪除過期數據等。通過識別和應對這些挑戰,可以更好地實現和維護分布式追蹤系統,從而充分發揮其在性能監控和故障診斷中的優勢。
分布式追蹤工具
對于分布式追蹤工具,市面上主要有三類:自研,開源,商業版。以下是一些常用的分布式追蹤工具:
(1) Zipkin
Zipkin是 Twitter基于 Java語言開發的開源分布式追蹤系統,支持多種語言和框架,易于集成。Zipkin提供簡單的用戶界面,用于查看和分析追蹤數據,支持多種存儲后端,如 MySQL、Elasticsearch等。
(2) SkyWalking
SkyWalking 是一個開源的應用性能監控和分布式追蹤系統,由國內 Apache基金會成員吳晟創立。它支持多種語言,包括Java、C#、Go等,能夠監控和追蹤分布式系統中的調用鏈路。
(3) Pinpoint
Pinpoint是由韓國 Naver開源的分布式追蹤系統,專注于 Java和 PHP應用的監控和追蹤,它能夠詳細記錄服務的調用鏈路和性能數據,幫助開發者優化系統性能。
Pinpoint 提供直觀的界面,方便用戶分析和定位問題,支持自定義插件,方便集成到不同的系統中。適用于需要詳細調用鏈路和性能數據的 Java和 PHP應用。
(4) CAT
CAT(Central Application Tracking)是由國內知名互聯網公司美團點評開源的分布式追蹤和監控系統,專注于應用性能監控和故障排查,它能夠實時收集和分析系統中的調用鏈路和性能數據。
CAT能夠實時收集和分析系統中的調用鏈路和性能數據,支持Java、C++、Node.js等多種語言,提供強大的可視化界面,幫助用戶深入分析系統性能。適用于需要實時監控和故障排查的分布式系統。
(5) 其他
另外還有一些國外比較流行(可能在國內不常用)的追蹤工具,比如:Jaeger,OpenTelemetry,AWS X-Ray,Azure Application Insights,Google Cloud Trace,Elastic APM等。
總結
本文分析了什么是分布式追蹤?為什么需要分布式追蹤以及分布式追蹤如何工作的,其實,分布式追蹤就是讓錯綜復雜的分布式系統調用變得透明化和可視化。
有了分布式追蹤,我們才能更好的掌握服務之間的調用關系,及時監控服務器的各項指標,當出現故障時可以快死定位,因此,分布式追蹤是分布式系統中不可或缺的一項技術,在國內的中大型互聯網公司,都有一個專門的部門在維護著這樣的服務,足以可見其重要性。